テーブルの読み書きはやったことがあったのですが、よく考えたらボリュームの読み書きの実装をしたことがありませんでした。
ノートブックで読み書きするノリでやるとハマるので注意点をまとめます。私が遭遇したエラーは:
FileNotFoundError: [Errno 2] No such file or directory: '/Volumes/workspace/de_handson/data_files'

もちろん、ボリュームのパスは存在しています。
注意点
- アプリからボリュームにアクセスする際には、ボリュームのパス
/Volumes/...に直接アクセスするのではなく、Databricks SDKを経由する - アプリのサービスプリンシパルにボリュームのアクセス権を付与する
特に1点目に注意です。ノートブックの場合、/Volumes/...のパスで直接読み書きできますが、Appの動作しているコンテナ環境にはUnity Catalogボリュームがマウントされていないので、ノートブックのノリで pd.read_csv("/Volumes/...")などとやると冒頭のエラーになります。
こちらのクックブックに説明があります。
Unlike notebooks, Databricks Apps does not support mounting Unity Catalog volumes and directly reading and writing files. As this code snippet demonstrates, each file needs to be downloaded to the app compute before being able to manipulate it.
ノートブックとは異なり、Databricks AppsではUnity Catalogボリュームのマウントや、ファイルの直接の読み書きはサポートしていません。このコードスニペットで示しているように、それぞれのファイルは操作する前にアプリのコンピュートにダウンロードする必要があります。
こちらのコミュニティのやり取りでも言及されています。
2点目のアクセス権はアプリのリソースとしてボリュームを追加することで自動で設定されます。手動で設定しても構いませんが、わかりやすさの観点でもリソースとして設定することをお勧めします。
実践
カスタムアプリを作成します。
名前と説明文。
リソースを追加をクリック。
UCボリュームを選択。
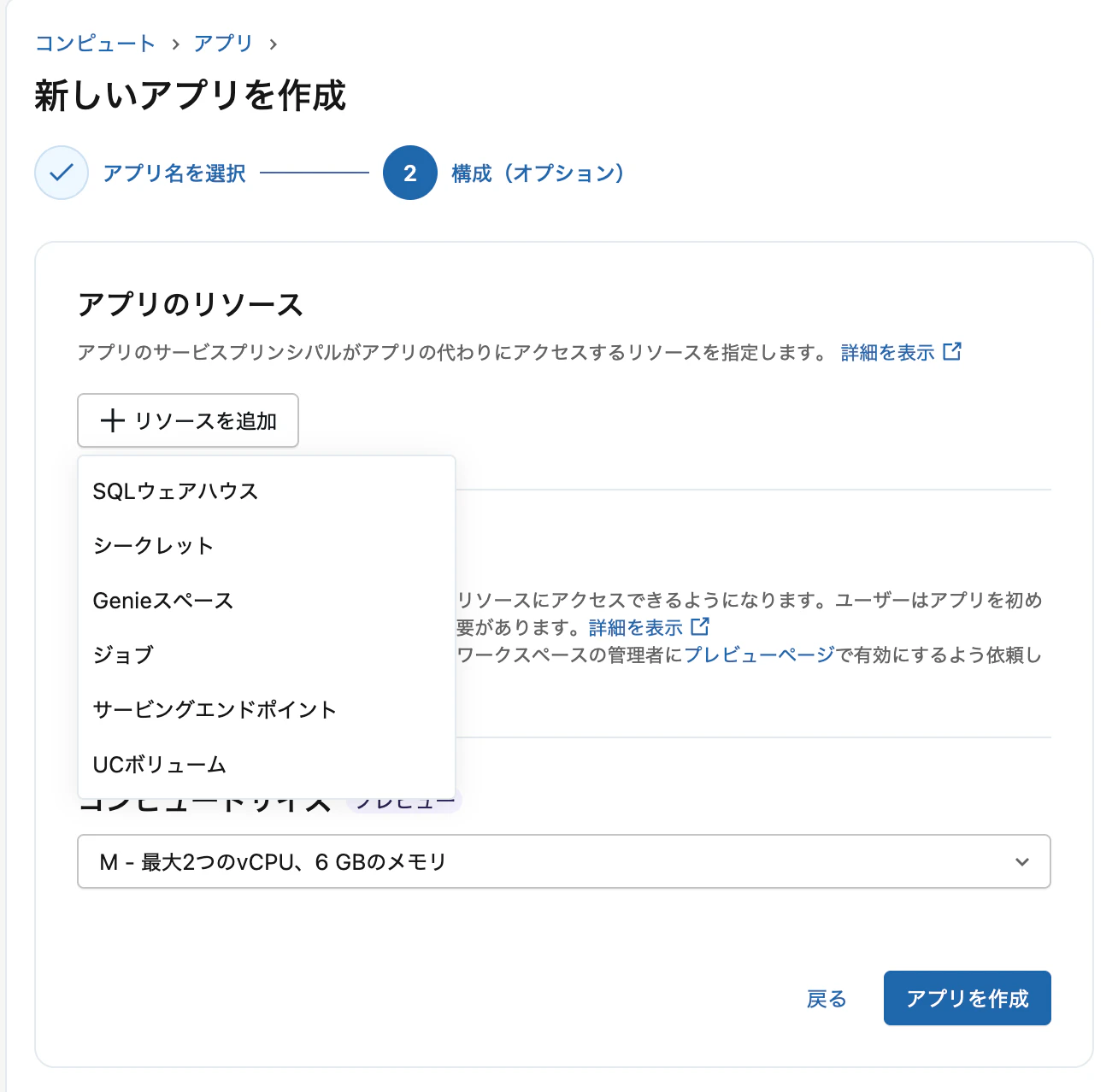
ボリュームのパスを選択し、権限には読み取りと書き込みを指定。
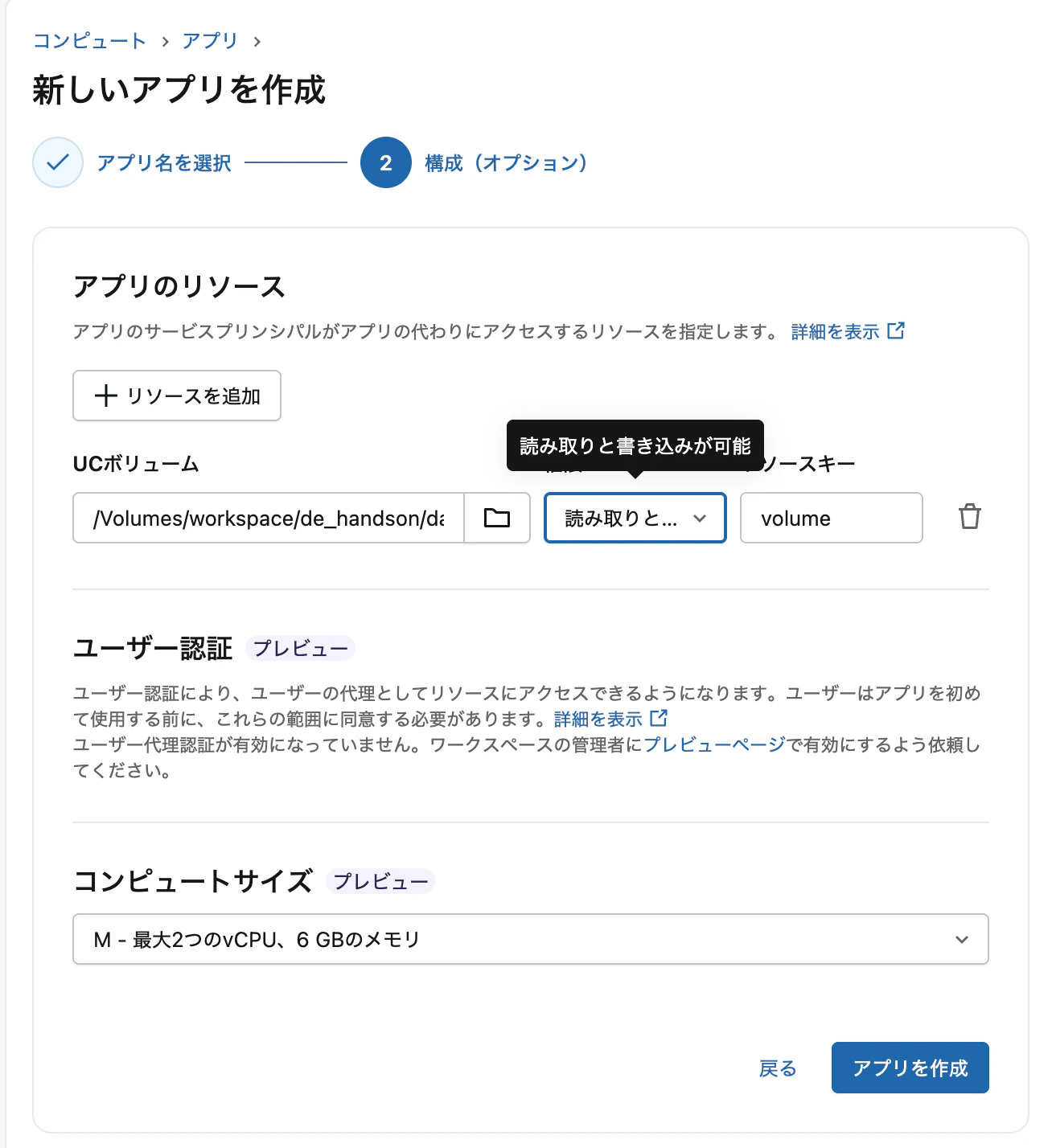
これで、アクセスするボリュームにアプリのサービスプリンシパルの権限が設定されます。これで、権限の問題はクリアしましたが、マウントポイントの問題が残っています。

まず、app.yamlではstreamlitが動くようにしておき、リソースで定義したボリュームパスを環境変数で参照できるようにしておきます。requirements.txtは依存関係がなければ空で大丈夫です。
command: [
"streamlit",
"run",
"app.py"
]
env:
- name: VOLUME_PATH
valueFrom: volume
そして、マウントポイントの問題を回避するために、app.pyで以下のように実装します。ここでのポイントは、アプリから直接ボリュームパスを参照するのではなく、Databricks SDKでファイルをアプリが動いているコンピュートのローカルにダウンロードしてからアクセスしているという点です。w.files...などと記載されている部分でSDKを使っています。
import os
import streamlit as st
import pandas as pd
import plotly.express as px
from databricks.sdk import WorkspaceClient
st.set_page_config(layout="wide")
# Unity Catalogボリュームのパスを指定(例: /Volumes/my_catalog/my_schema/my_volume)
# app.yaml経由で渡される環境変数を参照
VOLUME_PATH = os.getenv("VOLUME_PATH")
# WorkspaceClientの初期化
w = WorkspaceClient()
# ボリューム内のCSVファイル一覧を取得
def list_csv_files_in_volume():
files = w.files.list_directory_contents(VOLUME_PATH)
csv_files = [f.path for f in files if f.path.endswith('.csv')]
return csv_files
# Volumeからファイルをダウンロードしてローカルパスを返す
# https://apps-cookbook.dev/docs/streamlit/volumes/volumes_download/
def download_csv_file(volume_path: str) -> str:
# files.download() を使う(workspace.download() ではない)
response = w.files.download(volume_path)
file_content = response.contents.read()
# ローカルに保存
local_path = f"/tmp/{os.path.basename(volume_path)}"
with open(local_path, 'wb') as f:
f.write(file_content)
return local_path
# ローカルパスからCSVをロード
def load_csv(local_path):
return pd.read_csv(local_path)
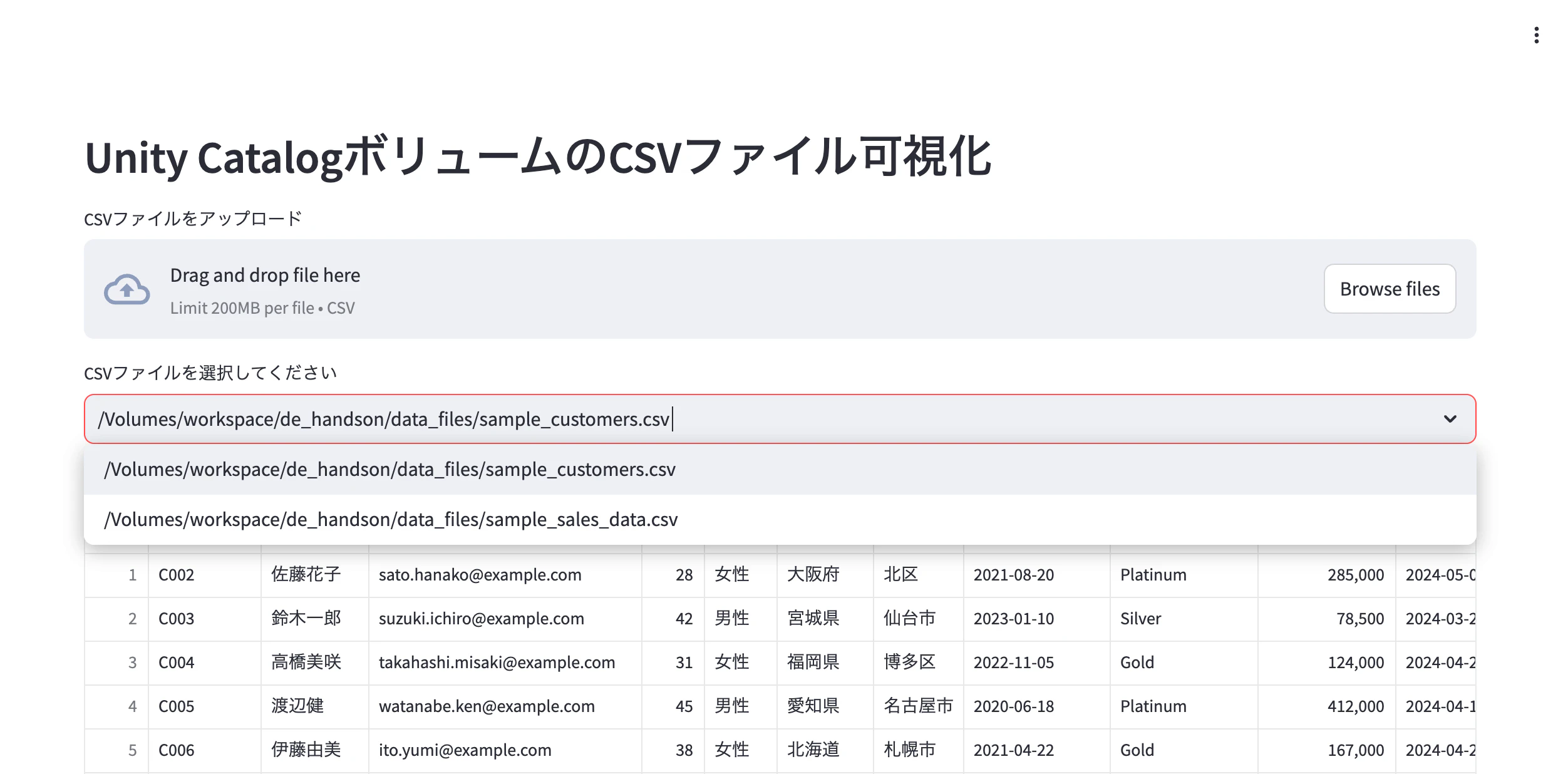
st.header("Unity CatalogボリュームのCSVファイル可視化")
# ファイルアップロード機能
uploaded_file = st.file_uploader("CSVファイルをアップロード", type=["csv"])
if uploaded_file is not None:
# ボリュームへのアップロード
save_path = os.path.join(VOLUME_PATH, uploaded_file.name)
w.files.upload(
save_path,
uploaded_file
)
st.success(f"{uploaded_file.name} をアップロードしました。")
# ファイルポインタを先頭に戻す
uploaded_file.seek(0)
# アップロード直後に内容表示
df_uploaded = pd.read_csv(uploaded_file)
st.subheader("アップロードしたファイルの内容")
st.dataframe(df_uploaded, height=400, use_container_width=True)
csv_files = list_csv_files_in_volume()
selected_file = st.selectbox("CSVファイルを選択してください", csv_files)
if selected_file:
local_path = download_csv_file(selected_file)
data = load_csv(local_path)
st.dataframe(data, height=600, use_container_width=True)
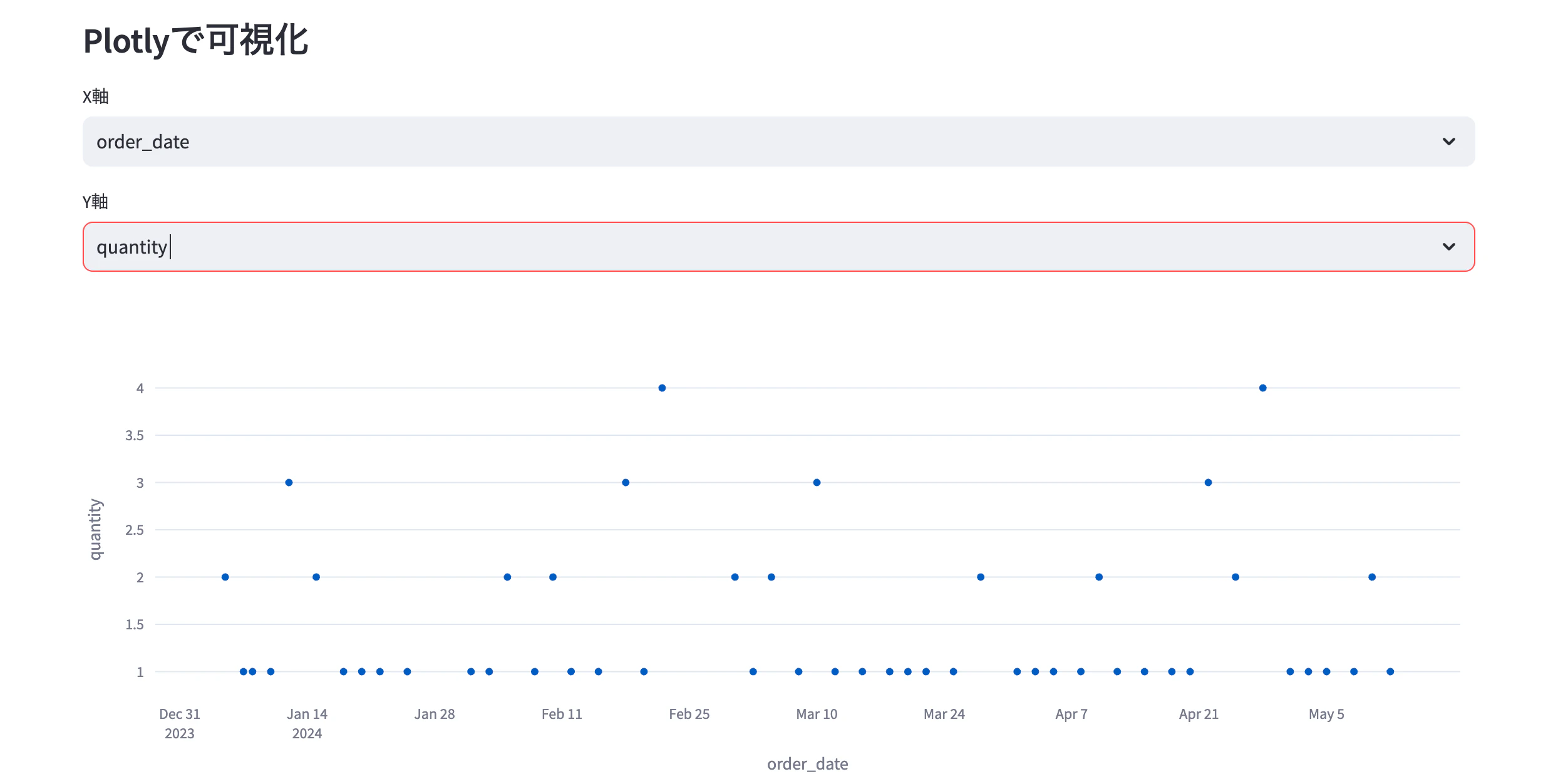
st.subheader("Plotlyで可視化")
columns = data.columns.tolist()
x_col = st.selectbox("X軸", columns)
y_col = st.selectbox("Y軸", columns)
fig = px.scatter(data, x=x_col, y=y_col, height=400, width=700)
st.plotly_chart(fig, use_container_width=True)
アプリにアクセスすると以下のような画面になります。

ファイルをアップロードします。
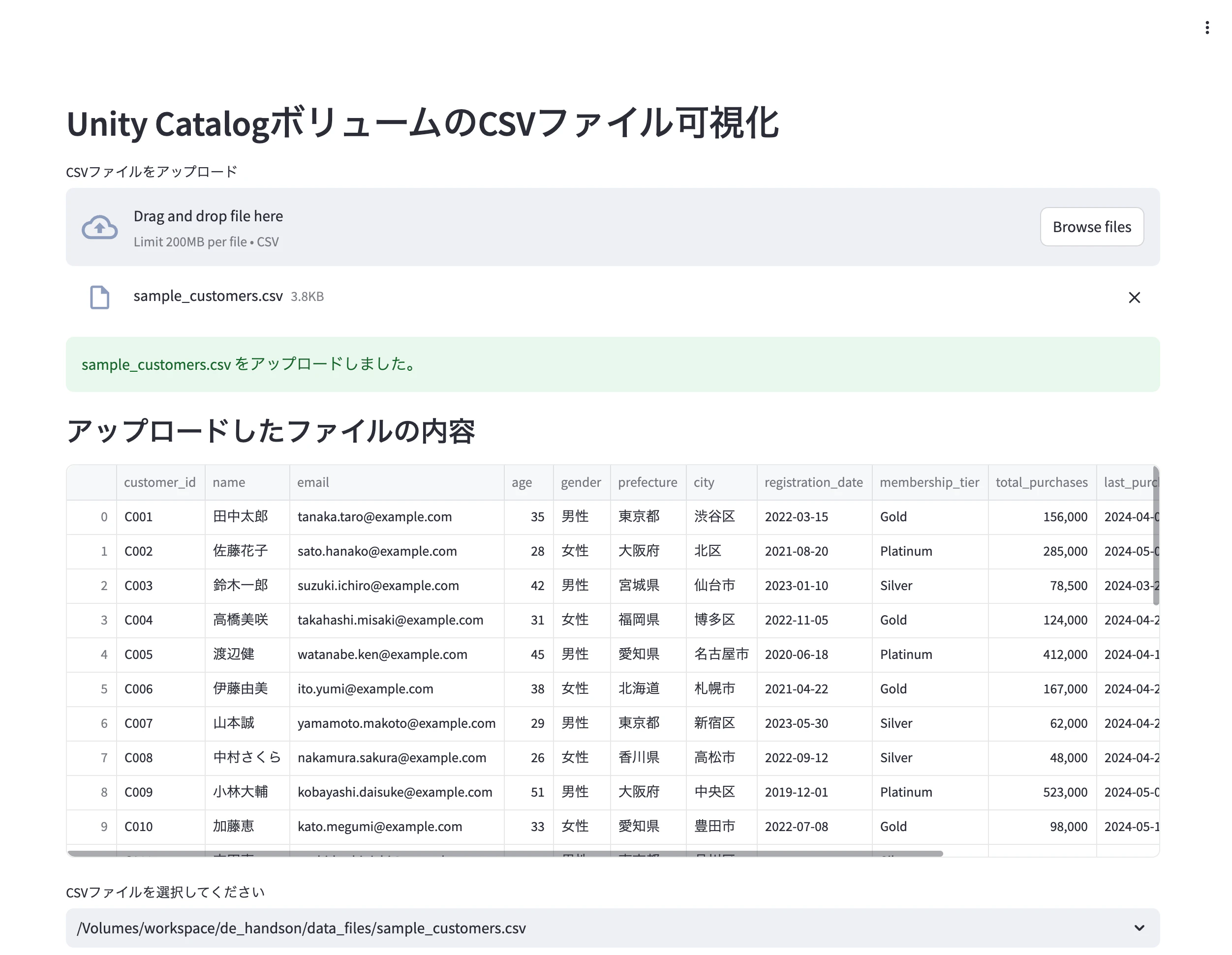
ボリュームにもアップロードされています。
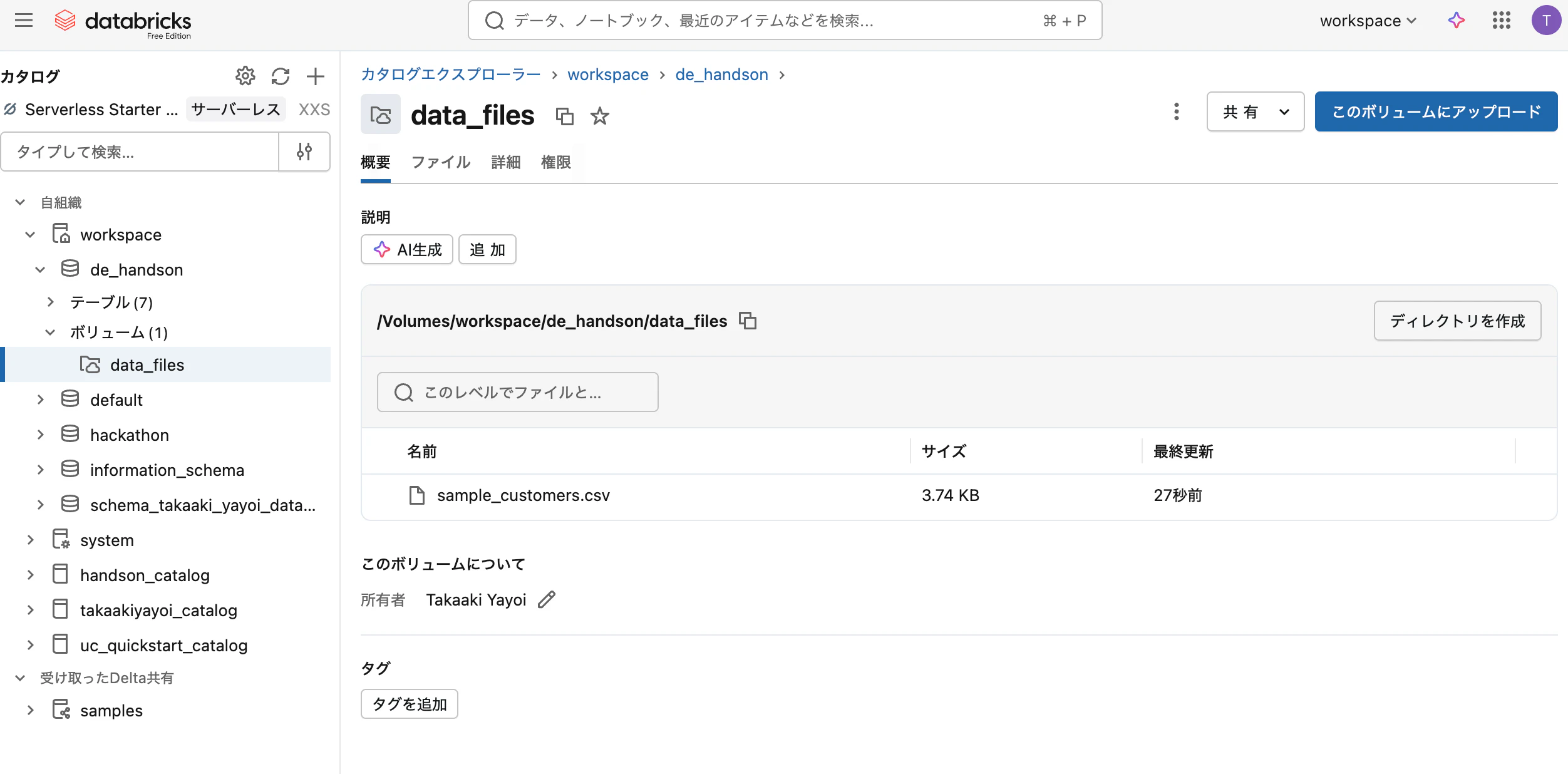
ボリューム内のファイルを選択して表示することもできます。
簡単な可視化もできます。