Make Your Oil and Gas Assets Smarter by Implementing Predictive Maintenance with Databricks - The Databricks Blogの翻訳です。2018年の記事のため、一部加筆修正しています。
Databricks Delta LakeとSparkストリーミングによるエンドツーエンドの予測データパイプラインの構築
サンプルノートブックをDatabricksでトライしてみてください。
コンプレッサーのようなアセットのメンテナンスは、非常に複雑な努力を必要とするものです。小さなドリルのリグから深海の土台まであらゆるところで使用されており、地域的には世界中に広がっており、日々テラバイトのデータが生成されています。これらのコンプレッサーの一つが故障したりすると、日々の生産が停止してしまい、巨額のコストが発生することになります。時間、コストを削減するために重要なことは、機械学習を活用して故障が起きる前に故障を予測し、メンテナンスの指示を出すと言うことです。
最終的には、アセットのパーツとセンサーマッピングを管理するリアルタイムデータベースを提供し、膨大なテレメトリー情報を処理する継続アプリケーションをサポートし、これらのデータセットをに対してコンプレッサーの故障を予測するエンドツーエンドの予測データパイプラインを構築する必要があります。
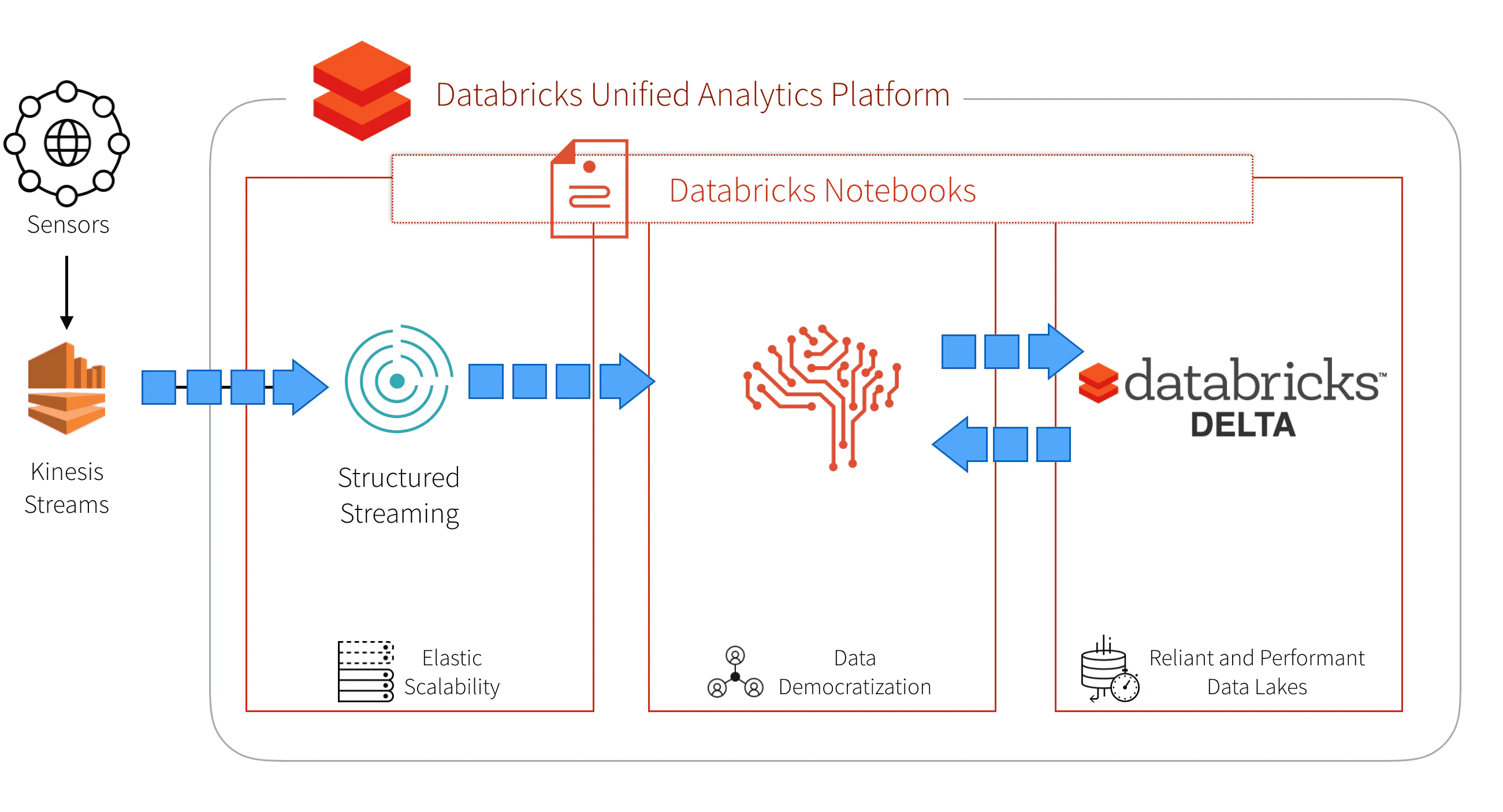
これらの問題に対応するために、上述の機能を提供する統合プラットフォームを選択しました。Databricksを活用することで、組織の異なるペルソナの人々が単体のワークスペースで一緒にコラボレーションできるようになります。Databricksのレイクハウスプラットフォームには以下の企業を提供しています。
- データサイエンティスト、データエンジニア、データアナリストがデータを活用できるように必要なリソースを起動することができます。
- Azure、AWS、GCPにおいて、同じワークスペースを活用できるマルチクラウド戦略を活用できます。
- ワークロードの実行を最適化するために様々なタイプのインスタンスを起動できます。
- コマンド(REST APIコマンドを含む)のスケジューリングにより、クラスターの自動起動、自動停止が可能です。
- アクセス権を容易に設定できるアクセスコントロールが可能です。また、実運用の際に、セキュアなREST API呼び出しを行うためのアクセストークンが利用可能です。
本記事においては、以下の取り組みによって、いかにオイル&ガスの資産管理をスマートにしたのかを説明します。
- 膨大なセンサーテレメトリーを処理するために、DatabricksのSparkストリーミングを活用。
- 事前に障害を予測する機械学習モデルの構築、配備。
- センサー、資産データを蓄積、ストリーミングするリアルタイムデータベースを作成するためにDatabrikcsのDelta Lakeを活用。
Kinesisストリームの確立
破滅的な故障を予測するために、Kinesisから来るセンサーのストリームデータ、Sparkストリーミング、ストリーミングのK-Meansモデルを組み合わせる必要があります。以下のコードスニペットを用いてKinesisを設定するところから始めましょう。より詳細に関しては、DatabricksのAmazon Kinesisインテグレーションを参照ください。
Scala
// === Configurations for Kinesis streams ===
val awsAccessKeyId = "YOUR ACCESS KEY ID"
val awsSecretKey = "YOUR SECRET KEY"
val kinesisStreamName = "YOUR STREAM NAME"
val kinesisRegion = "YOUR REGION" // e.g., "us-west-2"
import com.amazonaws.services.kinesis.model.PutRecordRequest
import com.amazonaws.services.kinesis.AmazonKinesisClientBuilder
import com.amazonaws.auth.{DefaultAWSCredentialsProviderChain, BasicAWSCredentials}
import java.nio.ByteBuffer
import scala.util.Random
認証が確立することで、以下のコードスニペットを用いることで、Kinesisから文字列を読み込んでカウントを行うことができます。
Scala
// Establish Kinesis Stream
val kinesis = spark.readStream
.format("kinesis")
.option("streamName", kinesisStreamName)
.option("region", kinesisRegion)
.option("initialPosition", "TRIM_HORIZON")
.option("awsAccessKey", awsAccessKeyId)
.option("awsSecretKey", awsSecretKey)
.load()
// Execute DataFrame query agaijnst the Kinesis Stream
val result = kinesis.selectExpr("lcase(CAST(data as STRING)) as word")
.groupBy($"word")
.count()
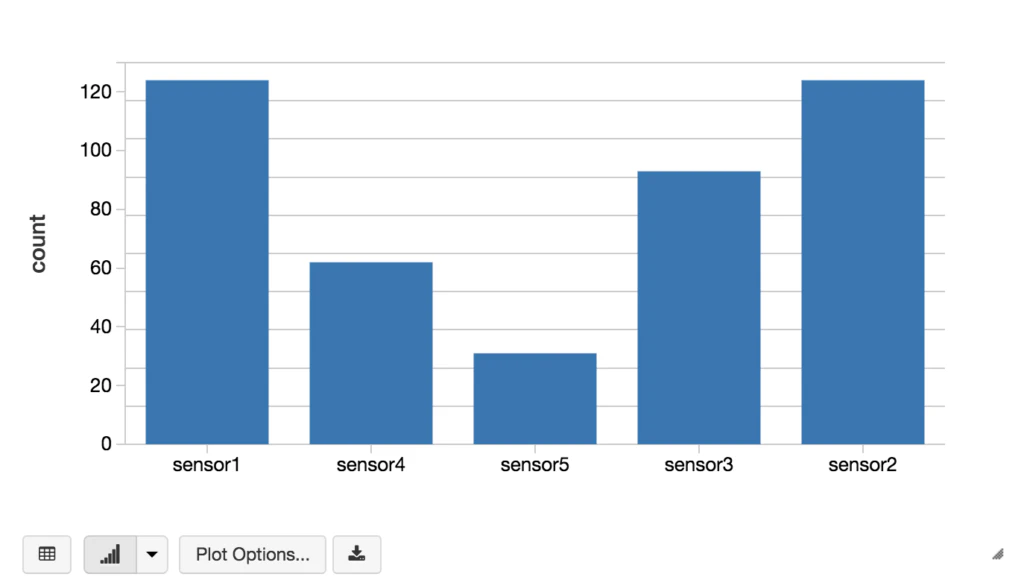
// Display the output as a bar chart
display(result)
Kinesisストリームを設定するためには、以下のコードスニペットのように5秒間隔で処理をループする低レベルKinesisクライアントを作成することで、これらの文字列をKinesisストリーミングに書き込みます。
Scala
// Create the low-level Kinesis Client from the AWS Java SDK.
val kinesisClient = AmazonKinesisClientBuilder.standard()
.withRegion(kinesisRegion)
.withCredentials(new AWSStaticCredentialsProvider(new BasicAWSCredentials(awsAccessKeyId, awsSecretKey)))
.build()
println(s"Putting words onto stream $kinesisStreamName")
var lastSequenceNumber: String = null
for (i <- 0 to 10) {
val time = System.currentTimeMillis
// Generate words: fox in sox
for (word <- Seq("Sensor1", "Sensor2", "Sensor3", "Sensor4", "Sensor1", "Sensor3", "Sensor4", "Sensor5", "Sensor2", "Sensor3","Sensor1", "Sensor2","Sensor1", "Sensor2")) {
val data = s"$word"
val partitionKey = s"$word"
val request = new PutRecordRequest()
.withStreamName(kinesisStreamName)
.withPartitionKey(partitionKey)
.withData(ByteBuffer.wrap(data.getBytes()))
if (lastSequenceNumber != null) {
request.setSequenceNumberForOrdering(lastSequenceNumber)
}
val result = kinesisClient.putRecord(request)
lastSequenceNumber = result.getSequenceNumber()
}
Thread.sleep(math.max(5000 - (System.currentTimeMillis - time), 0)) // loop around every ~5 seconds
}
センサーデータの探索
正常なコンプレッサー、損傷したコンプレッサーを予測するモデルを構築する前に、ちょっとしたデータ探索を行いましょう。初めに正常なコンプレッサー、損傷したコンプレッサーのデータをインポートします。以下のコードスニペットは、CSVフォーマットの正常なコンプレッサーのデータをインポートしてSpark SQLデータフレームに読み込みます。
Scala
// Read healthy compressor readings (represented by `H1` prefix)
val healthyCompressorsReadings = sqlContext.read.format("com.databricks.spark.csv")
.schema(StructType(
StructField("AN10", DoubleType, false) ::
StructField("AN3", DoubleType, false) ::
StructField("AN4", DoubleType, false) ::
StructField("AN5", DoubleType, false) ::
StructField("AN6", DoubleType, false) ::
StructField("AN7", DoubleType, false) ::
StructField("AN8", DoubleType, false) ::
StructField("AN9", DoubleType, false) ::
StructField("SPEED", DoubleType, false) :: Nil)
).load("/compressors/csv/H1*")
// Create Healthy Compressor Spark SQL Table
healthyCompressorsReadings.write.mode(SaveMode.Overwrite).saveAsTable("compressor_healthy")
// Read table from Parquet
val compressor_healthy = table("compressor_healthy")
また、Spark SQLを用いてクエリーを行えるように、Spark SQLテーブルにデータを保存します。
display(compressor_damaged.describe())

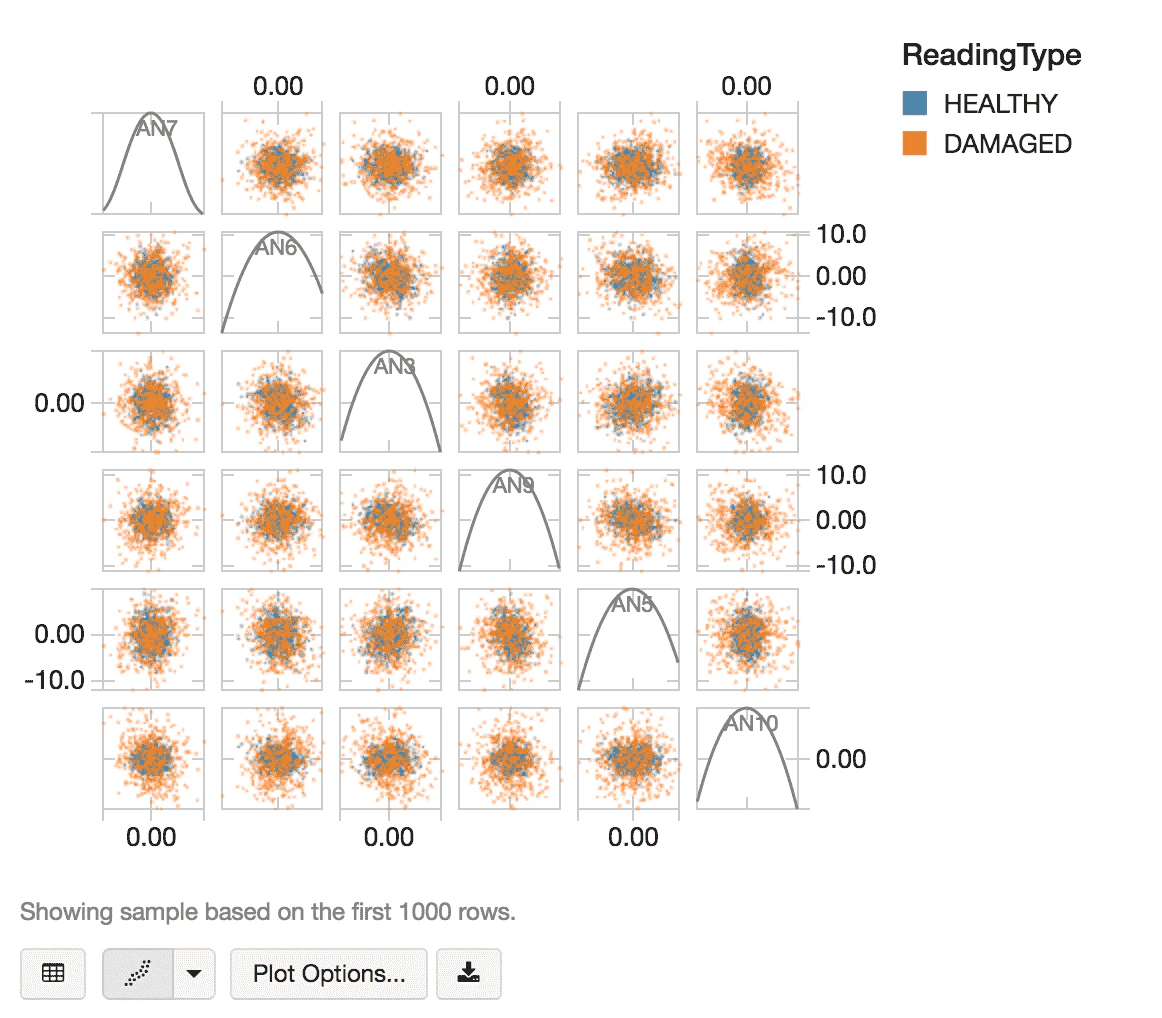
以下のコードスニペットで、正常なコンプレッサーのデータ、損傷したコンプレッサーのデータからランダムにサンプリングを行います。
Scala
// Obtain a random sample of healthy and damaged compressors
val randomSample = compressor_healthy.withColumn("ReadingType", lit("HEALTHY")).sample(false, 500/4800000.0)
.union(compressor_damaged.withColumn("ReadingType", lit("DAMAGED")).sample(false, 500/4800000.0))
Databricksのdisplayコマンドを用いて、散布図でランダムサンプルを可視化します。
Scala
// View scatter plot of healthy vs. damaged compressor readings
display(randomSample)
モデルの構築
予兆メンテナンスモデル実装の次のステップは、正常なコンプレッサーと損傷したコンプレッサーのデータをクラスタリングするK-Meansモデルの作成です。K-Meansは人気があることに加えて、広く知れ渡っているクラスタリングアルゴリズムです。また、ストリーミングK-Meansモデルを用いることで、バッチでもストリーミングでも容易に同じモデルを実行できるメリットがあります。
最初に決めなくてはいけないのは、最適なkの値(最適なクラスターの数)です。ここでは、正常あるいは損傷を識別しているので、直感的にはkは2となりますが検証してみましょう。以下のコードスニペットにあるように、新たなデータセット(例えば、ストリーミングデータセット)に容易に再利用できるようにMLパイプラインを構築します。このMLパイプラインは、VectorAssemblerを用いて、Air、Noiseカラム(ANで始まるカラム)を含む特徴量を定義し、MinMaxScalerを用いてスケーリングを行う比較的分かりやすいものです。
Scala
import org.apache.spark.ml._
import org.apache.spark.ml.feature._
import org.apache.spark.ml.clustering._
import org.apache.spark.mllib.linalg.Vectors
// Using KMeansModel
val models : Array[org.apache.spark.mllib.clustering.KMeansModel] = new Array[org.apache.spark.mllib.clustering.KMeansModel](10)
// Use VectorAssembler to define our features based on the Air + Noise columns (and scale it)
val vectorAssembler = new VectorAssembler().setInputCols(compressor_healthy.columns.filter(_.startsWith("AN"))).setOutputCol("features")
val mmScaler = new MinMaxScaler().setInputCol("features").setOutputCol("scaled")
// Build our ML Pipeline
val pipeline = new Pipeline()
.setStages(Array(vectorAssembler, mmScaler))
// Build our model based on healthy compressor data
val prepModel = pipeline.fit(compressor_healthy)
val prepData = prepModel.transform(compressor_healthy).cache()
// Iterate to find the best K values
val maxIter = 20
val maxK = 5
val findBestK = for (k <- 2 to maxK) yield {
val kmeans = new KMeans().setK(k).setSeed(1L).setMaxIter(maxIter).setFeaturesCol("scaled")
val model = kmeans.fit(prepData)
val wssse = model.computeCost(prepData)
(k, wssse)
}
ベストなkの値を決定するために何回も処理を繰り返しますが、ここではデモの目的のために、k値の範囲を[2…5]とし、繰り返し数を20とします。ここでのゴールは、様々なk値とWSSSE(Within Set Sum of Squared Error)繰り返すというものです。最適なk値(理想的なクラスター数)はWSSSEのグラフで「ひじ」が存在する箇所となります。以下のコードスニペットで、最も高いデリバティブを計算します。
Scala
// Calculate Derivative of WSSSE
val previousDf = kWssseDf.withColumn("k", $"k"-1).withColumnRenamed("wssse", "previousWssse")
val derivativeOfWssse = previousDf.join(kWssseDf, "k").selectExpr("k", "previousWssse - wssse derivative").orderBy($"k")
// find the point with the "highest" derivative
// i.e. optimal number of clusters is bestK = 2
val bestK = derivativeOfWssse
.select(
(lead("derivative", 1).over(Window.orderBy("k")) - $"derivative").as("nextDerivative") ,$"k").orderBy($"nextDerivative".desc).rdd.map(_(1)).first.asInstanceOf[Int]
最適なk値を特定できたので、2つのクラスターでモデルを構築します。以下のコードスニペットは、正常なコンプレッサーデータ(prepData)に対するKMeansモデル(bestModel)を構築し、WSSSE(wssse)を計算します。
Scala
// Create our `kmeans` model
val kmeans = new KMeans()
.setK(bestK)
.setSeed(1L)
.setMaxIter(100)
.setFeaturesCol("scaled")
val bestModel = kmeans.fit(prepData)
val wssse = bestModel.computeCost(prepData)
// Output
kmeans: org.apache.spark.ml.clustering.KMeans = kmeans_aeafe51274c3
bestModel: org.apache.spark.ml.clustering.KMeansModel = kmeans_aeafe51274c3
wssse: Double = 329263.3539615829
同じMLパイプラインとモデルに損傷したコンプレッサーデータを与えてWSSSEを計算することで、正常なコンプレッサーと損傷したコンプレッサーの違いを観察することができます。
Scala
// Calculate WSSSE of damaged compressors
val prepDamagedModel = pipeline.fit(compressor_damaged)
val prepDamagedData = prepModel.transform(compressor_damaged).cache()
val bestDamagedModel = kmeans.fit(prepDamagedData)
val wssse = bestDamagedModel.computeCost(prepDamagedData)
// Output
prepDamagedModel: org.apache.spark.ml.PipelineModel = pipeline_70af6bee9dad
prepDamagedData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [AN10: double, AN3: double ... 9 more fields]
bestDamagedModel: org.apache.spark.ml.clustering.KMeansModel = kmeans_aeafe51274c3
wssse: Double = 1440111.9276810554
ストリーミングK-Meansを用いたモデルのデプロイ
これで、コンプレッサーの障害を予測できそうなモデルを手に入れましたが、このモデルをバッチではなくリアルタイムで実行することで、定常的にアセットのセンサーストリームを受信する継続的アプリケーションを構築することが可能になります。破滅的な障害が起きる前にコンプレッサーを修理、交換できる時間が取れるようにより早いタイミングでコンプレッサーの障害を予測することが可能になります。
以下のコードスニペットは同様のsetKプロパティにbestKの値(2)を設定することで、ストリーミングKMeansモデルを構築します。ストリーミングK-Meansアルゴリズムの詳細に関しては、MLlib Programming Guide > MLlib Clustering > Streaming K-Meansを参照ください。
Scala
// Create StreamingKMeans() model
val kMeansModel = new StreamingKMeans()
.setDecayFactor(0.5)
.setK(2)
.setRandomCenters(8, 0.1)
次に、それぞれのミニバッチでWSSSEを計算するためにStreamingContext を用いたストリーミング関数を作成します。
Scala
// Function to create a new StreamingContext and set it up
def creatingFunc(): StreamingContext = {
// Create a StreamingContext
val ssc = new StreamingContext(sc, Seconds(batchIntervalSeconds))
val batchInterval = Seconds(batchIntervalSeconds)
ssc.remember(Seconds(300))
val dstream = ssc.queueStream(queue)
// As the DStream receives data, we calculate the WSSSE for each mini-batch
// and save this data out to DBFS
kMeansModel.trainOn(dstream)
dstream.foreachRDD {
rdd =>
val wssse = kMeansModel.latestModel().computeCost(rdd)
val timestamp = System.currentTimeMillis / 1000
sc.parallelize(
Seq(
WsseTimestamps(timestamp, wssse)
)
).toDF().write.mode(SaveMode.Append).json("/tmp/compressors")
}
println("Creating function called to create new StreamingContext for Compressor Failure Predictions")
newContextCreated = true
ssc
}
ストリーミングK-Meansモデルと、作成したSparkストリーミング関数を用いて、以下の関数ではSparkストリーミングコンテキストを開始します。
Scala
// Execute the Spark Streaming Context
val ssc = StreamingContext.getActiveOrCreate(creatingFunc)
if (newContextCreated) {
println("New context created from currently defined creating function")
} else {
println("Existing context running or recovered from checkpoint, may not be running currently defined creating function")
}
// Start Spark Streaming Context
ssc.start()
データを永続化するためには、Sparkストリーミング関数で記述しているように、田インプスタンプとWSSSEの値をDBFS上(この例では、/tmp/compressors)にJSONファイルとして保存します。DBFSのファイルはblobストレージに永続化されるので、クラスターを停止した後もデータを失うことはありません。以下のコードスニペットでは、センサーデータが到着するたびに故障率を予測し、タイムスタンプごとに計算されたWSSSEのストリームを参照することができます。
Scala
// Read the StreamingKMeans() results from DBFS
val compressorsResults = sqlContext.read.json("/tmp/compressors")
// View the model in action
display(compressorsResults.orderBy("ts"))

全てのアセットのテレメトリを処理する際には、システムの安定稼働を保証するApache Sparkのストリーミングを活用することができます。どのような時でも、アプリケーションのアウトプットは、バッチジョブで実行した際と同一になります。この一貫性のルールは過去のストリーミングの課題を解決します。DatabricksのSparkストリーミングは、継続的アプリケーションを容易に作成でき、ストリーミングアプリケーションのメンテナンスをシンプルにします。加えて、Databricksの統合されたワークスペースを活用できます。
Databricks Delta Lakeによるリアルタイムデータベースを用いたモデルの再学習
これで有効なストリーミングK-Meansモデルを手に入れましたが、新たな属性のデータ、新たなレコードが追加された際に再学習を行うことは一般的です。流れ込んでくる新たなトランザクションデータと過去のデータ(正常なコンプレッサーのデータ、損傷したコンプレッサーのデータ)を、一貫性が保たれた状態で格納できるリアルタイムデータベースを構築するということが、強力な選択肢になるかもしれません。このためには、データウェアハウスの性能、信頼性と、(アセットのテレメトリに対する)リアルタイムのデータ更新を可能にするDatabricksのDelta Lakeを活用します。
前の章では、saveAsTableを用いてテーブルを作成しましたが、ここでは以下のコードスニペットにあるようにUSIGN DELTAを用いてテーブルを作成します。
SQL
// Create Healthy Compressor Databricks Delta Table
CREATE TABLE compressor_healthy (
AN10 double,
AN3 double,
AN4 double,
AN5 double,
AN6 double,
AN7 double,
AN8 double,
AN9 double,
SPEED double
)
USING DELTA
OPTIONS (PATH "/compressors/delta/healthy/")
このSpark SQL文は、モデルのトレーニング、再トレーニングを行うためのDatabricks Deltaテーブルを作成します。このテーブルは以下の機能も提供します。
- トランザクション保証によるデータの整合性の保証
- ストリーミングの書き込みに対する一貫性のある参照
- インデクスとキャッシュによるクエリーの高速化
まとめ
この記事では、Sparkストリーミングと機械学習、Databricks Delta Lakeを組み合わせたDatabricksのレイクハウスプラットフォームを用いて、どのように予兆メンテナンスを実装するのかをデモしました。Kinesisストリミーングに対する読み書き、MLパイプラインにおけるK-Meansモデルの構築、データを受信する都度コンプレッサーの障害を予測できるようにSparkストリーミングに対するモデルの適用を一つのノートブックで実行しました。Databricksのレイクハウスプラットフォームを活用することで、データパイプラインが引き起こすデータエンジニアリングの複雑性を排除し、アセットの障害を予測するために、ストリーミング、SQL、機械学習という異なるデータパラダイムを容易に活用できます。
参考資料
DatabricksのDelta Lakeと構造化ストリーミングに関しては以下を参照ください。
- Predictive Compressor Failures using Streaming K-Means
- Case Study: Shell Improves Maintenance with Machine Learning on Databricks
- Databricks Guide: Structured Streaming
- An Anthology of Technical Assets on Apache Spark’s Structured Streaming
- Databricks Delta Guide