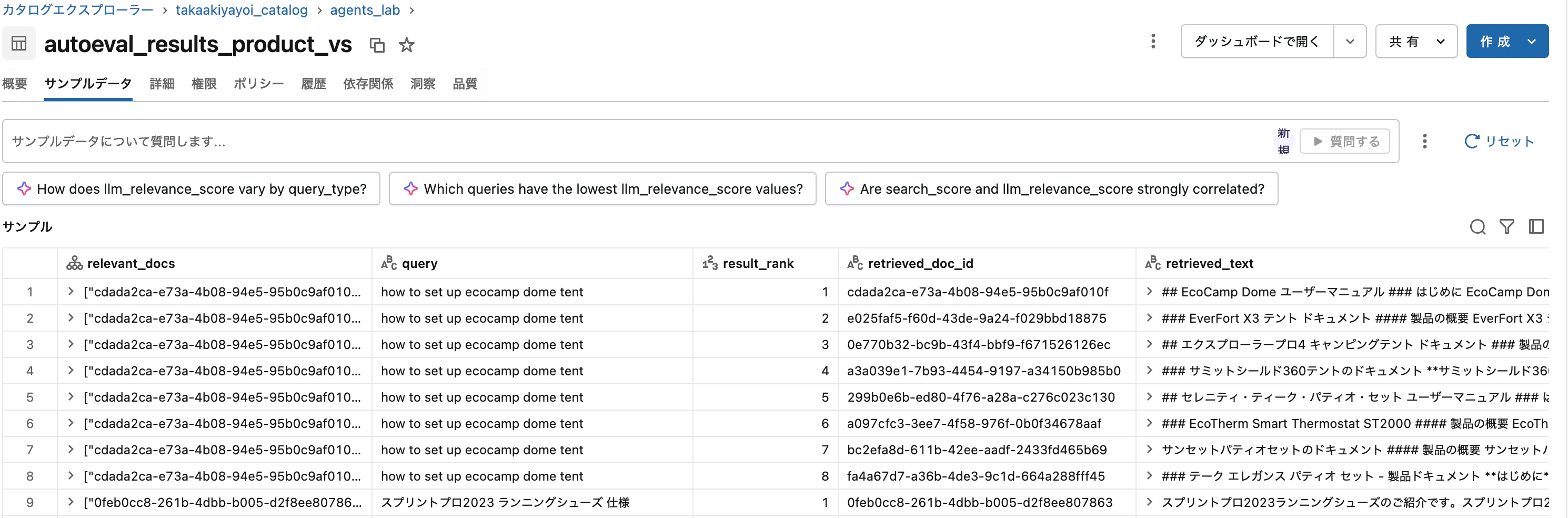
こちらのアップデートです。
ベクトル検索の取得品質(ベータ版)
Mosaic AI Vector Searchは、データに対するさまざまな検索戦略の関連性を測定・比較する、組み込みの検索品質評価機能を提供します。詳細については、ベクトル検索の取得品質を評価するを参照してください。
はじめに
Mosaic AI Vector Searchには、検索インデックスの取得品質を自動的に評価する機能(AutoEval)がベータ版として提供されています。この機能を使うと、ソーステーブルのドキュメントから評価クエリを自動生成し、ANN、全文検索、ハイブリッドの各検索戦略をリランカーの有無を含めて横断的に比較し、どの戦略が最も高い検索品質をもたらすかをワンクリックで把握できます。
本記事では、実際にAutoEvalを実行した結果をもとに、機能の概要、評価パイプラインの仕組み、結果ダッシュボードの読み方、および検索メトリクスの意味を解説します。
要件と権限
AutoEvalを利用するには、管理されたDelta Sync検索インデックスが必要です。検索インデックスの作成方法についてはベクトル検索のエンドポイントとインデックスの作成を参照してください。
また、この機能はベータ版であるため、ワークスペース管理者がプレビューページからアクセスを有効にする必要があります。詳細はDatabricksプレビューの管理を参照してください。

権限については、検索インデックスへのクエリアクセス権を持つユーザーであれば、評価の実行開始と結果ダッシュボードの表示が可能です。評価実行を開始したユーザーがジョブの所有者となります。
評価パイプラインの仕組み
AutoEvalは4段階のパイプラインで構成されています。
1. クエリの生成
ソーステーブルからドキュメントをサンプリングし、LLMを使って現実的な検索クエリを自動生成します。自然言語クエリとキーワードクエリを組み合わせたものが生成されます。
2. 複数の検索戦略を横断的に実行
生成されたクエリを、以下の検索戦略で実行します。それぞれリランカーあり/なしの2パターンで評価されるため、合計6種類の検索が比較対象となります。
| 検索戦略 | 説明 |
|---|---|
| ANN (Approximate Nearest Neighbor) | エンベディングベクトルによる近似最近傍探索 |
| FULL_TEXT | キーワードベースの全文検索 |
| HYBRID | ANNと全文検索の組み合わせ |
3. 関連性スコアリング
LLM審査員(今回の実行ではdatabricks-gemini-3-flash)が、すべてのクエリと取得ドキュメントのペアを4段階の関連性スケールで評価します。
| スコア | ラベル | 説明 |
|---|---|---|
| 3 | 非常に関連性が高い | クエリに直接回答する、または求められている情報を正確に提供する |
| 2 | 関連性あり | 関連しており有用だが、完全な回答ではない可能性がある |
| 1 | 部分的に関連性あり | トピックへの言及はあるが、クエリに役立つ情報を提供していない |
| 0 | 関係ない | クエリと無関係、またはクエリの言語と文書の言語が不一致 |
二値(関連/非関連)ではなく段階的なスケールを用いることで、直接回答している文書(スコア3)と話題に触れているだけの文書(スコア1)を区別でき、DCGなどのメトリクスにもこのきめ細かさが反映されます。
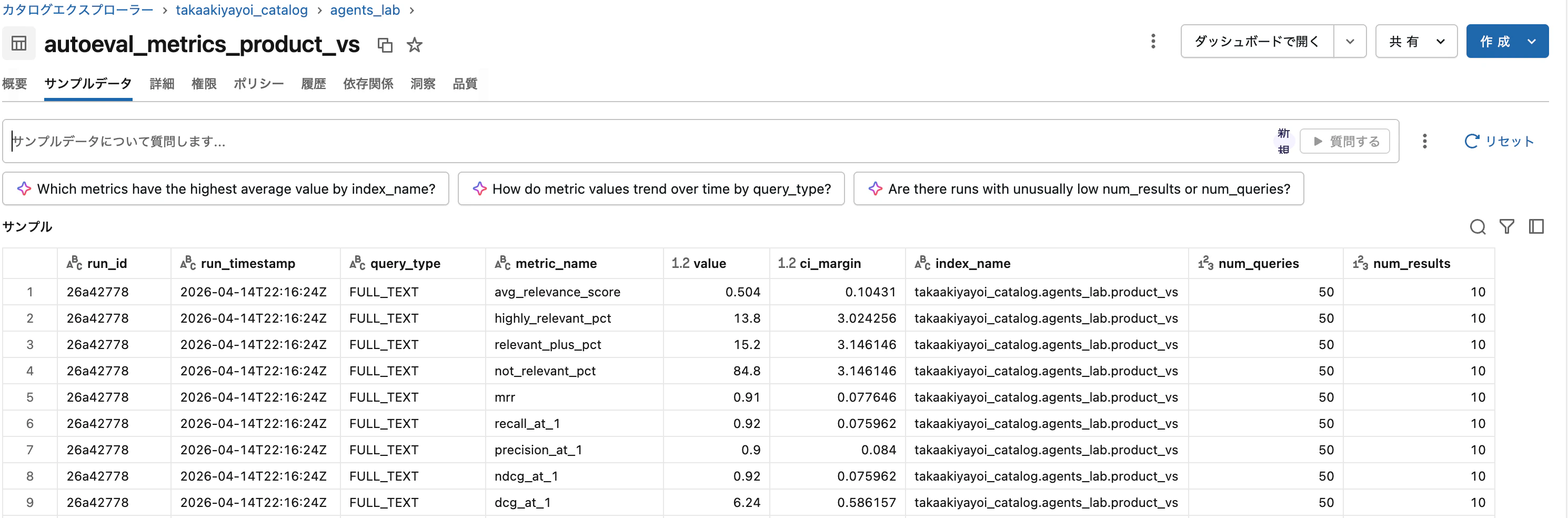
4. メトリクスの計算と分析
品質メトリクスを信頼区間付きで算出し、結果をDeltaテーブルに保存します。保存された結果は後から確認でき、複数の評価実行を時系列で比較することも可能です。
実行してみる
検索インデックスのページで検索品質の評価ボタンをクリックするだけで評価を開始できます。インデックスのメタデータに基づいてデフォルト値が事前設定されているため、特別な設定は不要です。
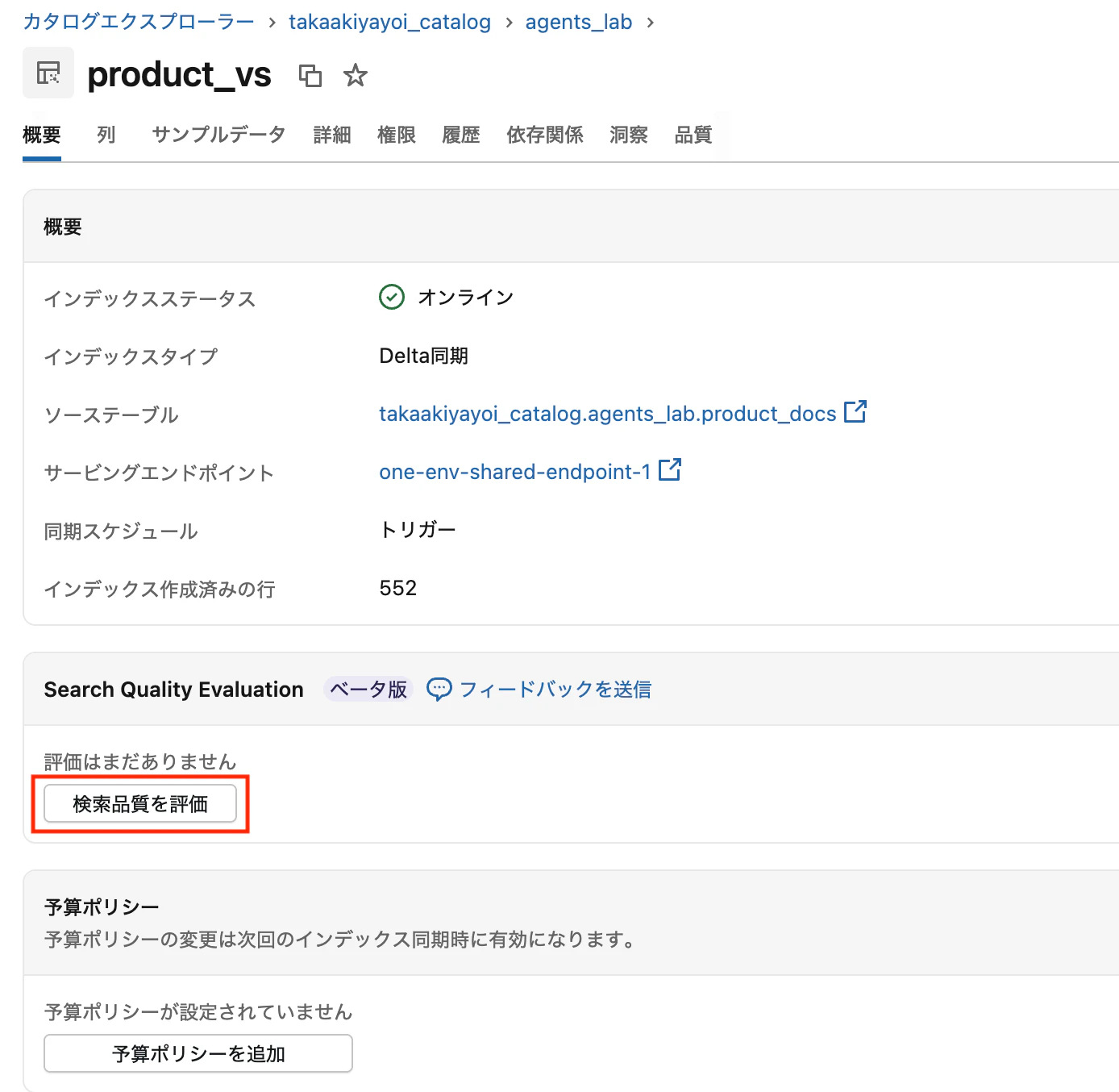
今回は以下の構成で実行しました。
| 項目 | 値 |
|---|---|
| インデックス | takaakiyayoi_catalog.agents_lab.product_vs |
| エンベディングモデル | databricks-qwen3-embedding-0-6b |
| コーパステーブル | takaakiyayoi_catalog.agents_lab.product_docs |
| プライマリキー | product_id |
| クエリ列 | product_doc |
| 検索戦略 | FULL_TEXT, ANN, HYBRID (それぞれリランカーあり/なし) |
評価が開始されると、ジョブとしてバックグラウンドで実行されます。
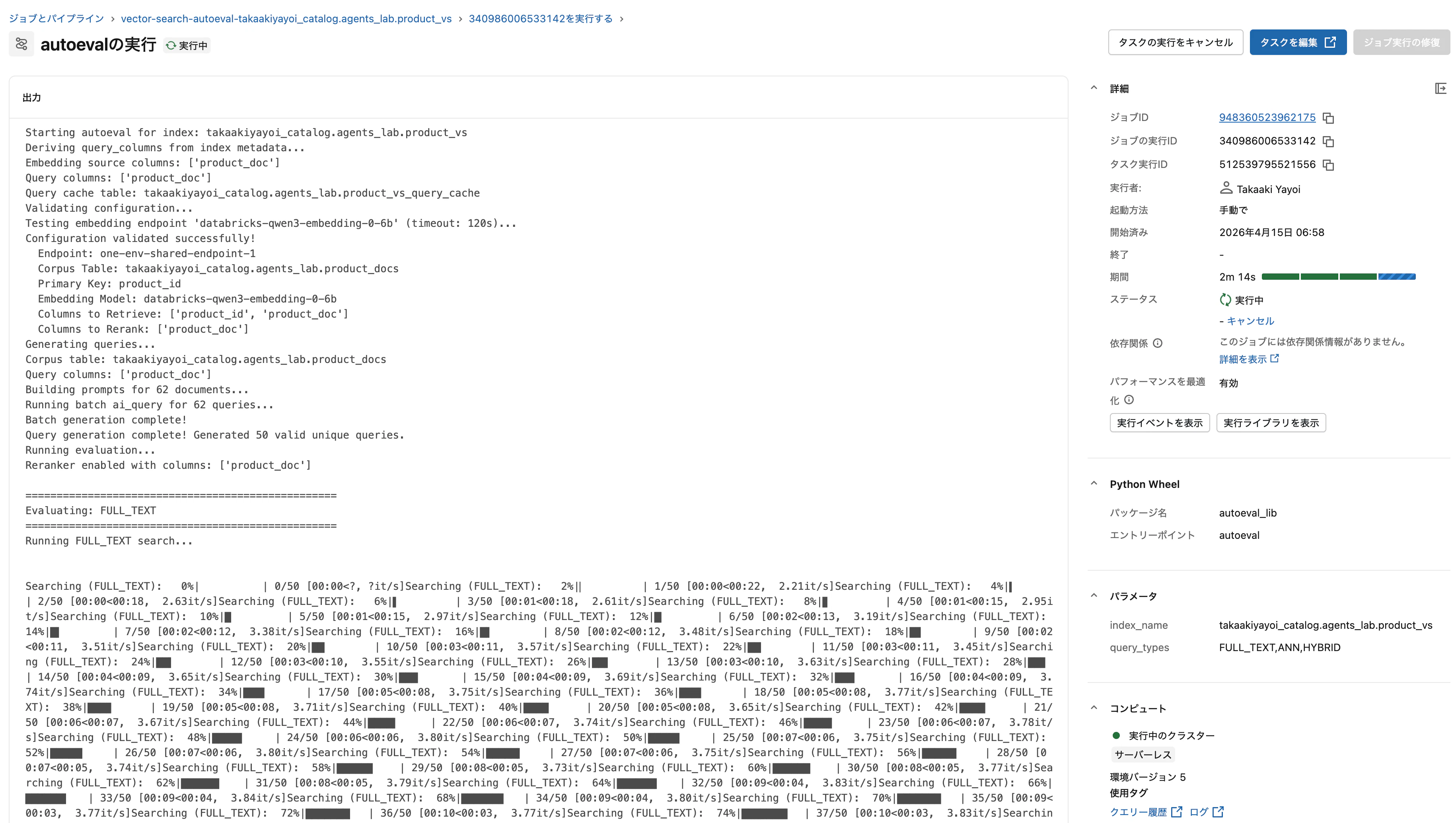
62件のドキュメントから50件のユニークなクエリが自動生成され、まずFULL_TEXT検索の評価から開始されました。
FULL_TEXT検索が50クエリすべて完了すると、LLMジャッジ(databricks-gemini-3-flash)によるスコアリングが行われます。続いてANN検索の評価に移ります。
ANN検索ではエンベディングモデルdatabricks-qwen3-embedding-0-6bを使用してベクトル検索を実行します。
6種類の検索戦略すべての評価が完了し、ジョブが成功しました。全体の実行時間は約18分52秒でした。結果はDeltaテーブルに保存されます。
結果ダッシュボード
ジョブ完了後、View resultsをクリックすると、評価結果の詳細なダッシュボードが表示されます。

サマリーメトリクス
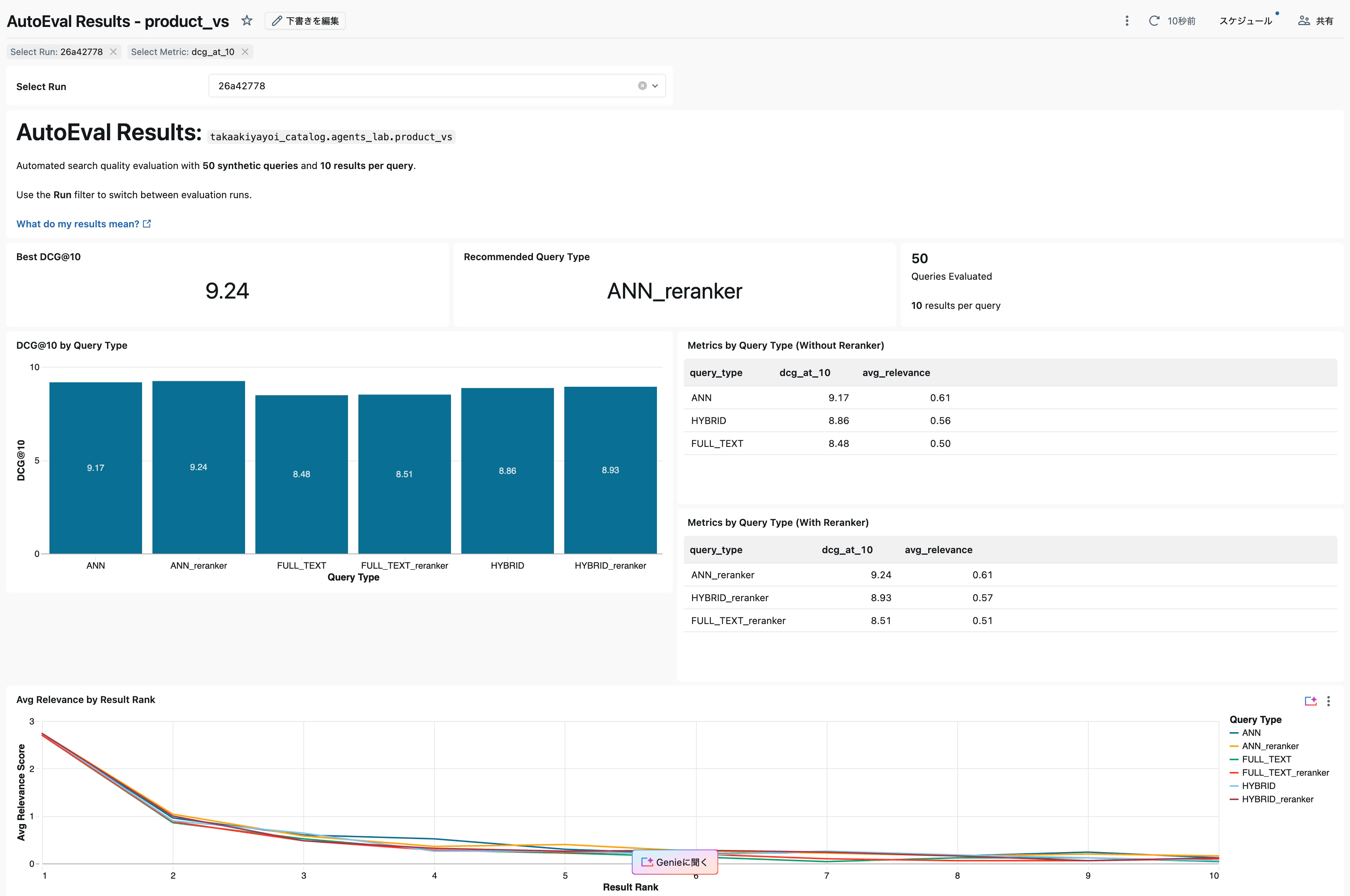
ダッシュボード上部に3つの要約指標が表示されます。
| 指標 | 結果 |
|---|---|
| Best DCG@10 | 9.24 |
| Recommended Query Type | ANN_reranker |
| Queries Evaluated | 50 (10 results per query) |
今回の評価では、ANN_reranker(ANN検索 + リランカー)が最も高いDCG@10スコア(9.24)を記録し、推奨検索戦略として選出されました。
クエリタイプ別DCG@10比較
棒グラフでは、6種類の検索戦略のDCG@10スコアが並べて比較されています。
リランカーなし(Without Reranker)
| query_type | dcg_at_10 | avg_relevance |
|---|---|---|
| ANN | 9.17 | 0.61 |
| HYBRID | 8.86 | 0.56 |
| FULL_TEXT | 8.48 | 0.50 |
リランカーあり(With Reranker)
| query_type | dcg_at_10 | avg_relevance |
|---|---|---|
| ANN_reranker | 9.24 | 0.61 |
| HYBRID_reranker | 8.93 | 0.57 |
| FULL_TEXT_reranker | 8.51 | 0.51 |
今回のデータセットでは、ANN検索が全体的に最も高いスコアを記録しました。リランカーの追加により、すべての検索戦略でDCG@10がわずかに向上しています。
Avg Relevance by Result Rank
結果の順位(1〜10位)ごとの平均関連性スコアを示す折れ線グラフも表示されます。上位の結果ほど関連性が高く、順位が下がるにつれて関連性スコアが低下する傾向が確認できます。
Top/Bottomクエリとリランカー効果
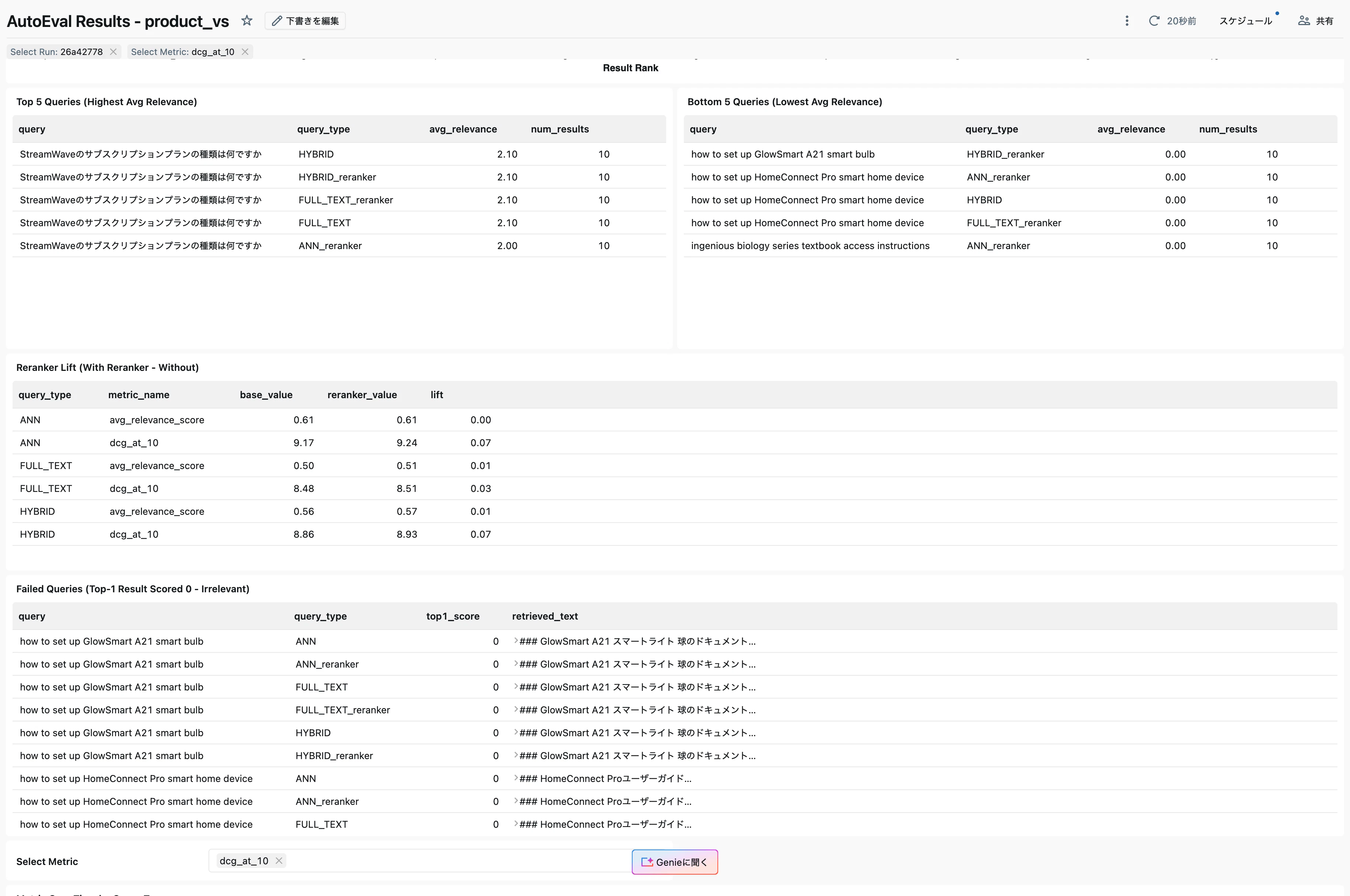
ダッシュボードの下部には、さらに詳細な分析が表示されます。
Top 5クエリ(最も高い平均関連性)では、「StreamWaveのサブスクリプションプランの種類は何ですか」というクエリがHYBRID、HYBRID_reranker、FULL_TEXT、FULL_TEXT_rerankerのいずれでも平均関連性2.10を記録しています。
Bottom 5クエリ(最も低い平均関連性)では、英語のクエリ(「how to set up GlowSmart A21 smart bulb」「how to set up HomeConnect Pro smart home device」)が関連性0.00となっています。これはコーパスが日本語であることに起因しており、クエリ言語とドキュメント言語の不一致が関連性スコアに影響することがわかります。
**Reranker Lift(リランカーによる改善度)**の表は以下の通りです。
| query_type | metric_name | base_value | reranker_value | lift |
|---|---|---|---|---|
| ANN | avg_relevance_score | 0.61 | 0.61 | 0.00 |
| ANN | dcg_at_10 | 9.17 | 9.24 | 0.07 |
| FULL_TEXT | avg_relevance_score | 0.50 | 0.51 | 0.01 |
| FULL_TEXT | dcg_at_10 | 8.48 | 8.51 | 0.03 |
| HYBRID | avg_relevance_score | 0.56 | 0.57 | 0.01 |
| HYBRID | dcg_at_10 | 8.86 | 8.93 | 0.07 |
リランカーによるDCG@10の改善幅は0.03〜0.07ポイントであり、今回のデータセットではリランカーの効果はそれほど大きくないことがわかります。
Failed Queries
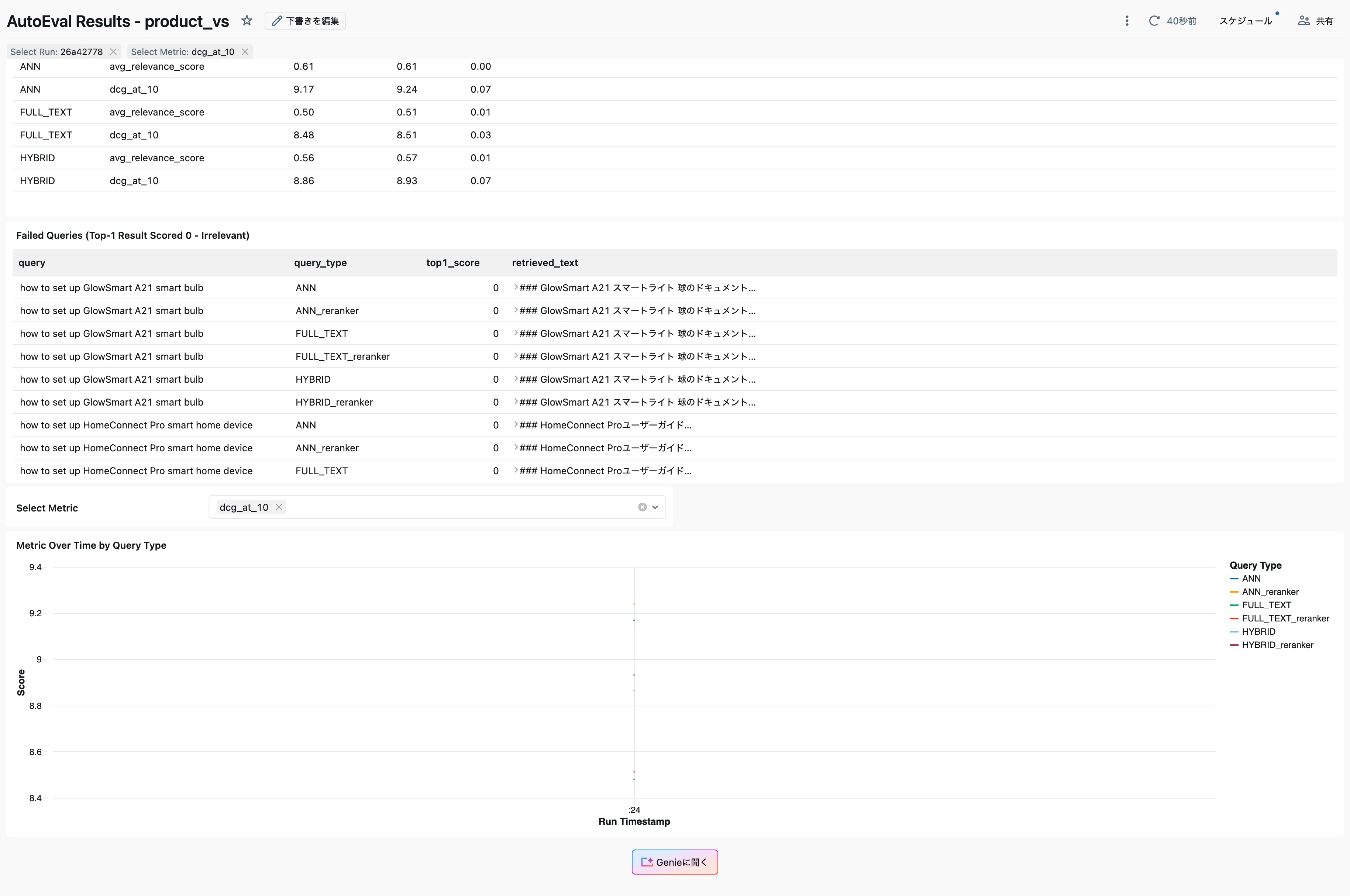
Failed Queries(Top-1の結果がスコア0=無関係と判定されたクエリ)のセクションでは、失敗したクエリとその取得テキストが一覧表示されます。
今回の失敗例では、「how to set up GlowSmart A21 smart bulb」や「how to set up HomeConnect Pro smart home device」のように、英語のクエリに対して日本語のドキュメントが返されたケースが確認できます。これは、全文検索やANNなど検索戦略を問わず発生しており、言語の不一致が主な原因です。
Metric Over Time
ダッシュボード最下部のMetric Over Timeチャートでは、評価実行を複数回行った場合に、クエリタイプ別のメトリクスの推移を時系列で確認できます。インデックスの設定変更やデータ更新後に再評価を行うことで、改善効果を定量的に追跡できます。
検索メトリクス解説
AutoEvalで使用される主要メトリクスについて説明します。
DCG@10(割引累積利益) — プライマリメトリクス
DCG@10は、関連性の度合いとランキングにおける表示位置の両方を捉えるメトリクスです。Databricksが検索品質を評価するためのプライマリメトリクスとして推奨しています。
上位の結果は下位の結果よりも貢献度が高くなるよう対数割引が適用されます。例えば、1位の結果は関連性スコアがそのまま反映されますが、10位の結果はlog2(11) ≈ 3.46で割った値になります。
10個の結果すべてが関連性2(0〜3のスケール)だった場合のDCG@10は約13.6です。このスケールでは、DCG@10が1ポイント向上することは相対的に約7%の改善を意味し、ページ上の検索結果のうち1つが明らかに改善され上位に表示されるようになるイメージです。
なぜNDCGではなくDCGが推奨されるのか
NDCG(正規化DCG)は結果が理想的な順序にどれだけ近いかを測定しますが、「全体としてユーザーがどれだけ有用な情報を得られたか」は反映しません。
例えば、「良い結果2件 + 無関係な結果3件が完璧な順序」も「良い結果5件が完璧な順序」も、NDCGはどちらも1.00になります。DCGなら前者は4.26、後者は8.02と、実際のユーティリティの差を明確に捉えられます。
その他のメトリクス
| メトリクス | 測定内容 | 範囲 |
|---|---|---|
| NDCG@k | 理想的な順序と比較したランキングの適切さ | 0〜1 |
| Recall@k | 既知の関連文書のうち上位k件に含まれる割合 | 0〜1 |
| Precision@k | 上位k件のうち関連性のある結果(スコア≧2)の割合 | 0〜1 |
| MRR | 最初の関連結果がどれだけ早く見つかるか | 0〜1 |
| MAP@k | 関連するすべての結果におけるランキング品質 | 0〜1 |
| 平均関連性スコア | 全ペアの関連性スコアの平均値 | 0〜3 |
よくあるシナリオと対処法
評価結果から読み取れるパターンと推奨アクションを以下にまとめます。
| パターン | 意味 | 推奨アクション |
|---|---|---|
| HYBRIDがANNよりも大幅に優れている | キーワードマッチングが検索精度を向上させている | 本番でハイブリッド検索を使用 |
| ANNがHYBRIDとほぼ同等 | キーワードがデータに付加価値を与えていない | どちらでも可。ANNの方がシンプル |
| FULL_TEXTがANNよりはるかに優れている | エンベディングがドメインを適切に反映できていない | エンベディングモデルの微調整を検討 |
| リランカーでメトリクスが大幅改善 | クロスエンコーダーが品質を向上させている | レイテンシ許容範囲があればリランカーを有効化 |
| 広い信頼区間 | クエリ数が不足 | 評価クエリ数を増やす |
| すべての戦略でスコアが低い | データ品質または関連性の問題 | 検索品質ガイドを参照 |
まとめ
Databricks Vector SearchのAutoEval機能を使うことで、検索インデックスの品質評価をワンクリックで実行でき、6種類の検索戦略(ANN/FULL_TEXT/HYBRID × リランカーあり/なし)を自動的に比較できます。
今回の実行結果からは以下のことがわかりました。
- ANN_rerankerが最も高いDCG@10(9.24)を記録し、推奨検索戦略として選出された
- リランカーの効果は今回のデータセットでは軽微(+0.03〜0.07ポイント)だった
- 英語クエリに対して日本語ドキュメントが返されるケースでは、検索戦略を問わず関連性スコアが0となり、言語の一致が重要であることが確認された
評価結果はDeltaテーブルに保存されるため、インデックス設定の変更やデータ更新のたびに再評価を行い、改善効果を時系列で追跡できます。RAGアプリケーションや検索システムの品質管理に活用してみてください。