コスト、とても大事です。
公式マニュアルでもベストプラクティスを公開しています。
ただ、実践しようとなると色々悩む部分が出てくるのかと思いますので、上のドキュメントに対して個人的解釈をしていきます。理解の助けになれば幸いです。
コストの考え方
費用に関してはこちらのページに詳細が記載されています。
Databricksの費用は、Databricksのサービス費用であるDBU(Databricks Unit)の消費による費用と、クラウドサービスプロバイダーの費用から構成されます。
Databricks Unit (DBU)
Databricks Unit (DBU)は、計測と課金の目的で使用される正規化されたDatabricksプラットフォームにおける処理能力の単位です。ワークロードが消費するDBUの数は、使用される計算リソースや処理されるデータ量を含む場合のある処理メトリクスによって計算されます。
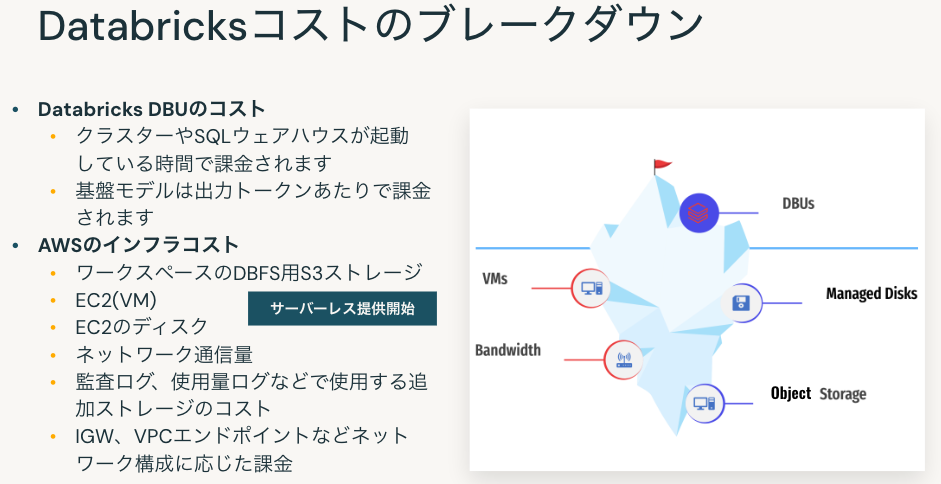
- Databricks DBUのコスト
- DatabricksクラスターやSQLウェアハウスが起動している時間で課金されます。
- 基盤モデルは出力トークンあたりで課金が発生します。
- AWSのインフラコスト
- ワークスペースのDBFS用S3ストレージ
- EC2(VM)
- EC2のディスク
- ネットワーク通信量
- 監査ログ、使用量ログなどで使用する追加ストレージのコスト
- IGW、VPCエンドポイントなどネットワーク構成に応じた課金
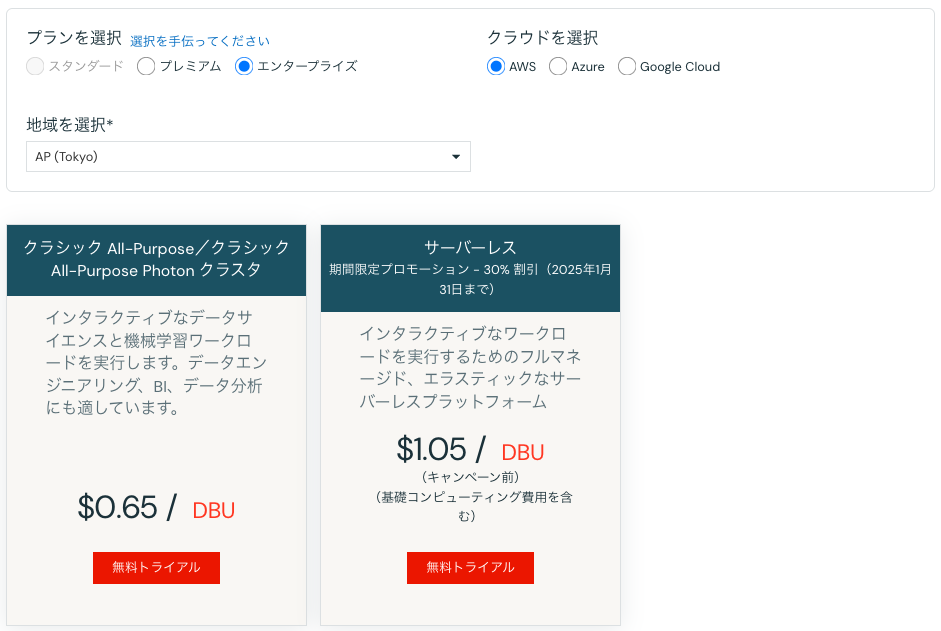
例えば、ノートブックで使用するクラスターは汎用コンピュートで、エンタープライズプランの場合は$0.65/DBUなので、1DBUを消費するたびに$0.65の課金が発生します。
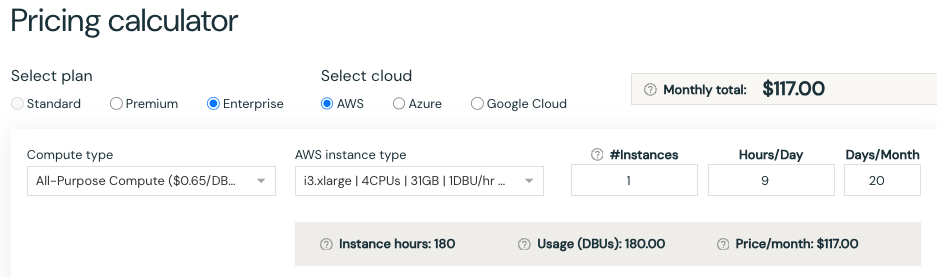
DBUの消費量はクラスターのスペックで決定されます。こちらで、インスタンスタイプを含むクラスターのスペックを指定してDBU消費量を計算することができます。
例えば、汎用コンピュートのクラスターのスペックがi3.xlarge(4CPU/31GB)の1台構成、1DBU/hrを消費します。
このクラスターが1日9時間/20日稼働する場合、1ヶ月のDBU消費量は
1 x 9 x 20 = 180 DBU
となります。
DBU単価が$0.65/DBUなので、月額の費用は
180 DBU x 0.65 = $117
となります。
つまり、合目的性のある範囲でDBU消費を抑えることができればコスト最適化に近づくことになります。
それでは、ベストプラクティスを見ていきましょう。
1. 最適なリソースを選択する
同じワークロードを同じ処理能力を持つリソースを使って処理するのであれば、単価の安いリソースを用いて、短い時間で処理を終了して計算リソースを停止した方がコストが安く済みます。
パフォーマンスが最適化されたデータ形式を使用する
DatabricksではDelta Lakeに格納されているデータの処理に様々な最適化が行われています。ですので、データはDelta Lake形式で保存しましょう。Databricksではデフォルトのファイル形式はDelta Lakeなので、普通に使用していれば全てがDeltaで保存されます。
ジョブコンピュートを使用する
以降のセクションで述べているのは、ワークロードに適したコンピュート(計算リソース)を使いましょうということです。コスト、性能の両面でメリットを享受することができます。Databricksでは数種類のコンピュートがありますので、こちらで理解を深めることを強くお勧めします。
ジョブコンピュートは、名前が示す通りジョブの実行に最適化された計算リソースです。ジョブの開始とともに起動し、ジョブの完了と共に停止します。
以下のように、インタラクティブなワークロード向け計算リソース(All purposeコンピュート)よりもワークロード向けリソース(Jobsコンピュート)の方がDBUの単価は半分以下です。
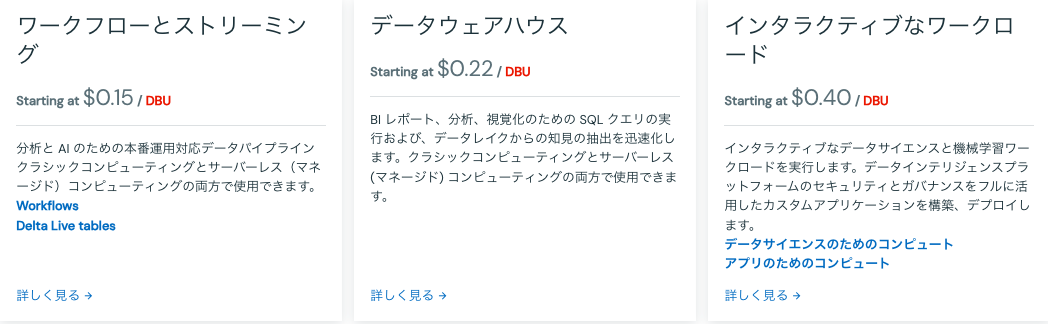
開発段階ではall purposeコンピュートを使用し、ロジックが固まったらジョブを作成し、jobコンピュートを使うようにしましょう。ジョブでAll purposeコンピュートを使うのは完全にコストの無駄です。
SQL ワークロードに SQLウェアハウスを使用する
SQLウェアハウスはSQLのみを用いるワークロードに最適な計算リソースです。BIやDWHのワークロードではSQLウェアハウスを使いましょう。All purposeコンピュートより単価が安いです。
ワークロードに最新のランタイムを使用する
All purposeコンピュートやJobsコンピュートにはDatabricksランタイムとしてソフトウェアがプレインストールされます。ランタイムは定期的にバージョンアップされ、バージョンアップの度に様々な最適化が行われます。特段の理由がない限り、最新のランタイムを使いましょう。
適切なワークロードにのみGPUを使用する
Databricksでは簡単にGPUを利用することができます。ただし、GPUが不要なワークロードではCPUを使うべきです。GPUクラスターの方が高価です。
ワークロードにサーバーレス サービスを使用する
ここ数年でDatabricksでのサーバレス化が進んでいます。サーバレスを利用する場合、クラウドインフラのコストが発生しないので全体的にコストを圧縮できる可能性が高まります。ただし、DBU単価自体は非サーバレスよりも高いので、ワークロードによっては必ずしも安価にならない場合があります。コスト以外のメリット(管理工数削減、高速な起動など)も勘案してサーバレスを活用しましょう。

適切なインスタンスタイプを使用する
この辺りに来るとパフォーマンスチューニングの領域に入ってきます。インスタンスタイプが何に最適化(メモリー、ストレージなど)されているのか、インスタンスコストを踏まえてインスタンスタイプを選択しましょう。基本的に最新のインスタンスタイプの方が優れたコストパフォーマンスを達成しています。
最も効率的なコンピュートサイズを選択する
コンピュートのサイズは個々のインスタンスのサイズとノード数から決定されます。意外と多い落とし穴は、Sparkを使用していないワークロードでマルチノードクラスターを使用しているということです。Sparkを使って初めて複数ノードのリソースを活用して並列処理を行うことができます。Pandasしか使っていないのにマルチノードクラスターを使った場合、ワーカーノードが1台あったとしてもそれらは全く活用されず、ドライバーノード1台のみが処理を行うことになり、ワーカーノードのコストは全くの無駄になります。Pandasしか使わないなどマルチノードを必要としないワークロードでは、シングルノードクラスターを使いましょう。
マルチノードクラスターでコストを最適化するには、メトリクスやSpark UIを用いたパフォーマンスチューニングが必要となります。
Spark UIを用いたパフォーマンスチューニングに興味のある方は、上記マニュアルやこちらをご覧ください。
パフォーマンスが最適化されたクエリ エンジンを評価する
SQLメインのワークロードではPhotonを使いましょう。SQLウェアハウスではデフォルトでオンになっています。
2. リソースを動的に割り当てる
自動スケーリングコンピュートを使用する
Databricksの計算リソースではオートスケールを活用することができます。負荷の変動が激しいワークロードでは、オートスケールを活用してコストを圧縮しましょう。
自動終了を使用する
コストの考え方で触れたように、計算リソースのコストは計算リソースが起動している時間に基づいて発生します。使っていない時には停止するというのが鉄則となります。夜間や週末にクラスターを立ち上げっぱなしにしておくことは、Databricksにおける究極のコストの無駄となります。
クラスターを作成する際には、必ず自動終了を設定しましょう。しかし、あまり短い時間で自動終了するように設定すると、昼休みから帰ってきたらクラスターが止まっていて、途中の結果が全て失われてしまった、ということにもなりかねないので、2時間など合理性のある範囲で設定してください。
コンピュートポリシーを使用してコストを管理する
ユーザーが任意のスペックのクラスターを作成できてしまうと、予期しないコスト増のリスクを抱えることになります。コンピュートポリシーを活用することで、ユーザーが指定可能なクラスターのスペックに制限をかけることができます。本格運用する際にはポリシーを設計して適用するようにしましょう。ただし、ユーザーの自由度を損なうことになるので、ユーザーの要件などを踏まえて自由度とガバナンスのバランスを取るようにしてください。
3.コストの監視と管理
ある意味、一番重要なセクションです。監視・計測なしには最適化は不可能です。
コストの監視
アカウントコンソールでは、予算の設定や監視用のダッシュボードをセットアップできます。運用を開始する際には、必ず予算の設定とダッシュボードのセットアップを行い、定常的に監視する体制を整えてください。
予算の設定に関してはこちらをご覧ください。
コスト配賦のためのクラスターへのタグ付け
クラスターにはタグを付けることができます。これによって、どの部門、どのプロジェクトがどのクラスターを使用しているのかを追跡できるので、後ほど予算を部門にチャージバックすることができます。
コストを追跡してチャージバックするためのオブザーバビリティを実装する
コストだけではなく、コストが妥当かどうかを判断するために利用パターンを分析したいという要件もあると思います。システムテーブルのデータを分析することで、ユーザーがどのようにDatabricksを利用しているのかに関するオブザーバビリティ(観測可能性)を確立することができます。
4. コスト効率の高いワークロードを設計する
常時オンとトリガーストリーミングのバランスをとる
ストリーミング処理を行う際には、常時オンの処理も可能ですがコストへのインパクトが大きくなります。定期的にジョブを起動し、それまでに処理されていないデータを処理するインクリメンタルな実装も可能なので、レイテンシーとコストを考慮して実装を検討してください。
オンデマンドインスタンスと容量超過インスタンスのバランス
スポットインスタンスを使えるところでは使いましょう。ただし、途中で召し上げられるリスクを考慮してクラスターやワークロードを設計しましょう。ただし、ドライバーノードでスポットインスタンスは使わないでください。ドライバーノードのインスタンスが召し上げられるとジョブが失敗します。