こちらの記事で紹介されている新機能です。
マニュアルはこちら。
これまでは、Sparkのソースやシンクはこちらに定義されているものしか使用できませんでした。このため、REST APIから読み込んだデータをSparkで処理する際には、追加のロジックの実装が必要でした。
こちらのData Source APIを用いることで、任意のデータソースをSparkのデータソースとしてラッピングすることができるので、シームレスな連携が可能となります。
早速、マニュアルのサンプルを試してみます。クラスターはDatabricksランタイム15.2以降を使います。
バッチクエリ用の PySpark データソースを作成する
fakerを使ってダミーデータを生成するデータソースを作成します。
%pip install faker
ステップ1: サンプルデータソースを定義する
from pyspark.sql.datasource import DataSource, DataSourceReader
from pyspark.sql.types import StructType
class FakeDataSource(DataSource):
"""
`faker`ライブラリを使用したバッチクエリのためのサンプルのデータソース
"""
@classmethod
def name(cls):
return "fake"
def schema(self):
return "name string, date string, zipcode string, state string"
def reader(self, schema: StructType):
return FakeDataSourceReader(schema, self.options)
ステップ2: バッチクエリのリーダーを実装する
class FakeDataSourceReader(DataSourceReader):
def __init__(self, schema, options):
self.schema: StructType = schema
self.options = options
def read(self, partition):
# ライブラリのインポートはメソッド内で行う必要があります。
from faker import Faker
fake = Faker()
# この `self.options` 辞書のすべての値は文字列です。
num_rows = int(self.options.get("numRows", 3))
for _ in range(num_rows):
row = []
for field in self.schema.fields:
value = getattr(fake, field.name)()
row.append(value)
yield tuple(row)
ステップ3: 登録してサンプルデータソースを使用する
spark.dataSource.register(FakeDataSource)
spark.read.format("fake").load().show()
+--------------+----------+-------+----------+
| name| date|zipcode| state|
+--------------+----------+-------+----------+
| Danielle Wang|2015-10-29| 53553| Montana|
| James Harris|1988-01-26| 95094| Alabama|
|Dustin Roberts|2007-03-29| 49834|New Mexico|
+--------------+----------+-------+----------+
おおー、動いた。
フィールドを変えてみます。
spark.read.format("fake").schema("name string, company string").load().show()
+---------------+--------------------+
| name| company|
+---------------+--------------------+
| Diane Lopez| Wong-Tucker|
| Emily Flynn|Mcgrath, Martinez...|
|Zachary Cochran| Conner-Webb|
+---------------+--------------------+
しかし、fakerライブラリは便利ですね。
行数も変更してみます。
spark.read.format("fake").option("numRows", 5).load().show()
+---------------+----------+-------+----------+
| name| date|zipcode| state|
+---------------+----------+-------+----------+
|Darius Gray Jr.|2015-07-02| 18357| Oregon|
| Alex Galloway|1972-09-15| 80736|Washington|
|Jennifer Barker|1975-12-17| 91660|California|
|Chad Harris DVM|1984-07-06| 49041| Louisiana|
| Michael Lucas|2018-10-15| 65993| Kansas|
+---------------+----------+-------+----------+
次はストリーミングソースを。
ストリーミング読み取りおよび書き込み用の PySpark DataSource を作成
ステップ1: サンプルデータソースを定義する
from pyspark.sql.datasource import DataSource, DataSourceStreamReader, SimpleDataSourceStreamReader, DataSourceStreamWriter, InputPartition, Iterator, Tuple, WriterCommitMessage
from pyspark.sql.types import StructType
class FakeStreamDataSource(DataSource):
"""
`faker`ライブラリを使用したストリーミング読み書きのためのデータソースの例。
"""
@classmethod
def name(cls):
return "fakestream"
def schema(self):
return "name string, state string"
def streamReader(self, schema: StructType):
return FakeStreamReader(schema, self.options)
# パーティショニングが不要な場合は、streamReaderの代わりにsimpleStreamReaderメソッドを実装できます。
# def simpleStreamReader(self, schema: StructType):
# return SimpleStreamReader()
def streamWriter(self, schema: StructType, overwrite: bool):
return FakeStreamWriter(self.options)
ステップ2: ストリームリーダーを実装する
DataSourceStreamReader、あるいは、データソースのスループットが低くて、パーティション分割が不要な場合は、SimpleDataSourceStreamReaderを実装できるそうです。
DataSourceStreamReader の実装
class RangePartition(InputPartition):
def __init__(self, start, end):
self.start = start
self.end = end
class FakeStreamReader(DataSourceStreamReader):
def __init__(self, schema, options):
self.current = 0
def initialOffset(self) -> dict:
"""
リーダーの初期開始オフセットを返します。
"""
return {"offset": 0}
def latestOffset(self) -> dict:
"""
次のマイクロバッチが読み取る最新のオフセットを返します。
"""
self.current += 2
return {"offset": self.current}
def partitions(self, start: dict, end: dict):
"""
開始および終了オフセットで定義された現在のマイクロバッチのパーティショニングを計画します。
:class:`InputPartition`オブジェクトのシーケンスを返す必要があります。
"""
return [RangePartition(start["offset"], end["offset"])]
def commit(self, end: dict):
"""
クエリが終了オフセット前のデータの処理を終了したときに呼び出されます。
これを使用してリソースをクリーンアップできます。
"""
pass
def read(self, partition) -> Iterator[Tuple]:
"""
パーティションを入力として受け取り、データソースからタプルのイテレータを読み取ります。
"""
start, end = partition.start, partition.end
for i in range(start, end):
yield (i, str(i))
SimpleDataSourceStreamReader の実装
class SimpleStreamReader(SimpleDataSourceStreamReader):
def initialOffset(self):
"""
リーダーの初期開始オフセットを返します。
"""
return {"offset": 0}
def read(self, start: dict) -> (Iterator[Tuple], dict):
"""
開始オフセットを入力として受け取り、タプルのイテレータと次の読み取りの開始オフセットを返します。
"""
start_idx = start["offset"]
it = iter([(i,) for i in range(start_idx, start_idx + 2)])
return (it, {"offset": start_idx + 2})
def readBetweenOffsets(self, start: dict, end: dict) -> Iterator[Tuple]:
"""
開始および終了オフセットを入力として受け取り、データを決定論的に読み取るイテレータを返します。
これは、クエリが再起動や障害後にバッチを再生する際に呼び出されます。
"""
start_idx = start["offset"]
end_idx = end["offset"]
return iter([(i,) for i in range(start_idx, end_idx)])
def commit(self, end):
"""
クエリが終了オフセット前のデータの処理を終了したときに呼び出されます。これを使用してリソースをクリーンアップできます。
"""
pass
ステップ3: ストリームライターを実装する
class SimpleCommitMessage(WriterCommitMessage):
partition_id: int
count: int
class FakeStreamWriter(DataSourceStreamWriter):
def __init__(self, options):
self.options = options
self.path = self.options.get("path")
assert self.path is not None
def write(self, iterator):
"""
データを書き込み、その後そのパーティションのコミットメッセージを返します。ライブラリのインポートはメソッド内で行う必要があります。
"""
from pyspark import TaskContext
context = TaskContext.get()
partition_id = context.partitionId()
cnt = 0
for row in iterator:
cnt += 1
return SimpleCommitMessage(partition_id=partition_id, count=cnt)
def commit(self, messages, batchId) -> None:
"""
すべての書き込みタスクが成功したときに:class:`WriterCommitMessage`のシーケンスを受け取り、その後の処理を決定します。
このFakeStreamWriterでは、マイクロバッチのメタデータ(行数とパーティション数)がcommit()内でJSONファイルに書き込まれます。
"""
status = dict(num_partitions=len(messages), rows=sum(m.count for m in messages))
with open(os.path.join(self.path, f"{batchId}.json"), "a") as file:
file.write(json.dumps(status) + "\n")
def abort(self, messages, batchId) -> None:
"""
他のタスクが失敗したときに成功したタスクからの:class:`WriterCommitMessage`のシーケンスを受け取り、その後の処理を決定します。
このFakeStreamWriterでは、失敗メッセージがabort()内でテキストファイルに書き込まれます。
"""
with open(os.path.join(self.path, f"{batchId}.txt"), "w") as file:
file.write(f"failed in batch {batchId}")
ステップ4: 登録してサンプルデータソースを使用する
spark.dataSource.register(FakeStreamDataSource)
query = spark.readStream.format("fakestream").load().writeStream.format("console").start()
確かにストリーミング処理が実行されます。
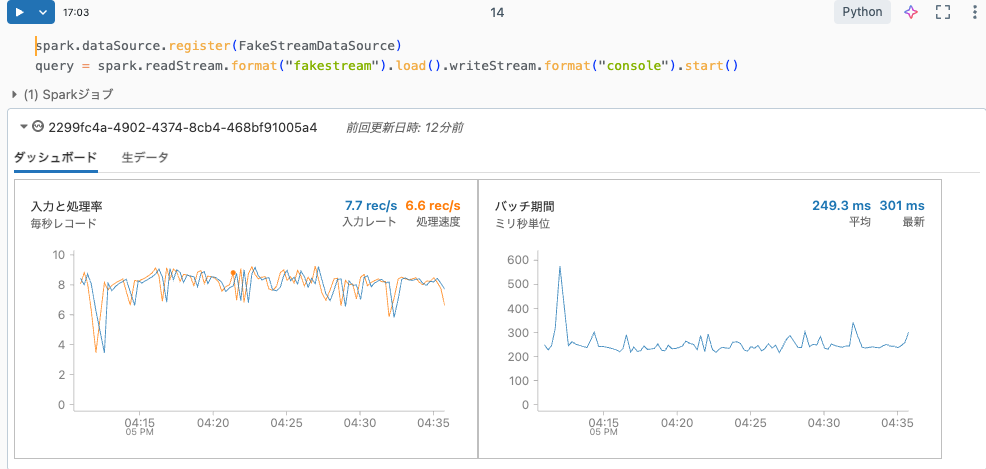
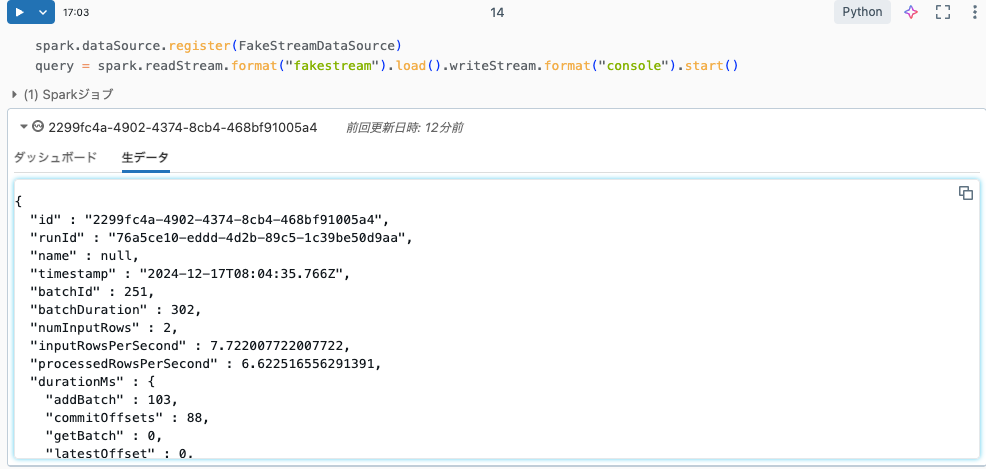
実装の自由度が広がっていい感じです。