こちらすごく勉強になりました。
サンプルノートブックがありましたのでウォークスルーします。
翻訳版はこちらです。
ライブラリのインストールとインポート
%pip install rouge-score -q
%pip install -U mlflow[genai] -q
%pip install databricks-agents -q
dbutils.library.restartPython()
import pandas as pd
import pyspark.sql.functions as F
import mlflow
from mlflow.metrics.genai import make_genai_metric, EvaluationExample
import json
DAISのアブストラクトからランダムに選んだサンプルデータセットを作成
eval_sessions = pd.Series([
"""Bruceのサイバー戦争と企業サイバーセキュリティのキャリアで、彼は史上最も注目されたボットネットや国家による摘発に関わりました。また、世界で最も先進的なSOCの技術構築にも携わりました。
Bruceはその経験から得た教訓と、なぜ早期退職をやめて愛車を売却し、ziggizを共同設立したのかを説明します。
データが増え続けていることは周知の事実です。サイバーセキュリティに関わる人なら、SIEMが企業サイバーセキュリティ運用の中心でありながら、政府やFortune 100企業でもコストが高すぎることを知っています。""",
"""DLTのホームページには「宣言型ETLフレームワーク(...)で、データチームがストリーミングとバッチETLをコスト効率よく簡素化できる」とあります。データに対して行う変換を定義するだけで、DLTパイプラインがタスクのオーケストレーション、クラスタ管理、監視、データ品質、エラー処理を自動で管理します。
この講演では、DLTが納期厳守の中でどれだけ助けになったかを紹介します。DLTのキャッチコピーが正しい理由を示し、次のETLプロジェクトでDLTを検討する価値があることを納得してもらいたいです。
DLTに投資すべき理由を10以上見つけました。
基礎概念(Spark SQLとStructured Streaming、Delta Lake)と、それがDLTの道をどう切り開いたかを説明します。
最近の2つの成功プロジェクトを基に、DLTの有用性と楽しさを語ります。""",
"""JosueはデータとAIの現場での実践的な視点で知られています。市場で見ていること、製品機能のアップデートへの見解、そしてユーモアも交えて語ります。""",
"""SMBC(日本の大手多国籍金融機関)は、Azure/Databricks上でGenAIを活用した最新かつガバナンスの効いたクラウドデータ基盤の構築に着手しました。ローン、預金、証券、デリバティブなどのデータ領域を網羅する企業データ基盤を目指しています。
主な目的:
- レガシーデータ基盤の廃止とデータスプロールの削減(20以上の基幹銀行システムをAzure Databricksのマルチテナントアーキテクチャへ移行)
- Databricksのdelta-share機能でSMBCのグローバルなデータ共有ニーズに対応
- Unity Catalogによる設計段階からのデータガバナンス
- EMEA地域での同様の導入を支援するフレームワーク・アーキテクチャ・ツール群のグローバル展開
DeloitteとSMBCは「Data as a Service for Banking」資産を活用し、戦略的な変革を加速しました。""",
"""AIの本番運用はますます複雑化しています。モデルタイプの多様化、納期短縮、インフラ要求の増加などが背景です。本セッションでは、Mosaic AI Model Servingが従来型MLと生成AIモデルの両方を効率的にデプロイ・スケールし、監視・ガバナンスも内蔵していることを解説します。SkyscannerがAIを製品に統合し、100以上の本番エンドポイントをスケールし、AI運用体制を構築した事例も紹介します。
主なポイント:
- SkyscannerがAIを実製品に導入・運用する方法
- 低レイテンシ・最小オーバーヘッドで多様なモデルをデプロイ・スケールする方法
- モデル・特徴量ストア・ベクトル検索を組み合わせた複合AIシステムの構築
- 本番ワークロードの監視・デバッグ・ガバナンス""",
"""AT&T AutoClassifyは、AT&TのCDOとDatabricksプロフェッショナルサービスが共同開発した、ラベルなしテキストデータから自動で複数の二値分類を行う新しいエンドツーエンドシステムです。ラベル付きデータセット作成と多ヘッド二値分類器のトレーニングを最小限の人手で自動化します。
未ラベルのテキストコーパスと希望ラベルリストのみから、先進的な自然言語処理技術で生データから関連例を自動抽出し、埋め込みモデルをファインチューニング、複数の分類ヘッドをトレーニングします。これによりLLM分類コストを1000分の1に削減し、運用コスト効率の高いソリューションとなります。
最終的に、生テキストから複数の二値分類を出力できる最適化・低コストモデルをDatabricks上で提供します。コール記録を使ったユースケースも紹介します。""",
"""企業はサポートチケット、PDF、メール、商品画像など大量の非構造データを生成しています。そこから洞察を得るには、壊れやすいパイプラインや複雑なツールが必要でした。
Databricks AI Functionsでこれが簡単になります。本セッションでは、SQLやETLワークフロー内で強力な言語・画像モデルを直接活用する方法を紹介します。エンドポイント不要、インフラ不要、書き換え不要です。
実践的なユースケースやベストプラクティス(複雑文書の分析、課題分類、コンテンツ翻訳、画像検査など)を、スケーラブル・宣言型・セキュアな方法で解説します。
学べること:
- GPT-4、Claude Sonnet 4、Llama 4など最先端LLMをデータ上で実行する方法
- テキスト・画像のスケーラブルなマルチモーダルETLワークフロー構築
- プロンプト・コスト・エラー処理のベストプラクティス
- AI FunctionsによるGenAIユースケースの実例"""
])
eval_sessions_df = pd.DataFrame({"session_desc" : eval_sessions})
サンプルデータを使って一時ビューを作成します。
(
spark
.createDataFrame(eval_sessions_df)
.createOrReplaceTempView("dais_sessions")
)
ユースケース1: DAISアブストラクトの要約
なぜ? これらは自動化されたSNSプロモーション投稿に利用します。
%sql
CREATE OR REPLACE TEMPORARY VIEW session_summaries AS
SELECT
session_desc,
ai_summarize(session_desc) as summary
FROM dais_sessions
# 要約を表示
display(spark.sql("SELECT summary FROM session_summaries"))
| summary |
|---|
| Bruceはサイバー戦争と企業サイバーセキュリティの経験からziggizを共同設立し、SIEMの高コスト問題を解決します。 |
| DLTは、宣言型ETLフレームワークでデータチームがストリーミングとバッチETLを簡素化できる。 |
| JosueはデータとAIの実践的な視点で知られ、市場の動向や製品機能のアップデートについて語る |
| SMBC builds a cloud data platform using GenAI on Azure/Databricks, aiming for a unified enterprise data foundation and improved data governance. |
| AIの本番運用を効率的にデプロイ・スケールする方法と事例が紹介される |
| AT&T AutoClassifyは、ラベルなしテキストデータから自動で二値分類を行うシステムで、自然言語処理技術を使用してコストを削減します。 |
| Databricks AI Functions simplifies insights from unstructured data with powerful language and image models. |
要約は良さそうです!要約評価指標(RougeL)を試してみましょう。 ROUGEは要約の一部を評価する指標ですが、n-gramの重複のみを評価します。抽出的要約を好み、言い換えには弱いです。今回はRougeLが適していると仮定します。 サンプルデータをpandasデータフレームに読み込み、mlflowで評価・集計指標を生成します。
evaluation_set = spark.sql("SELECT * FROM session_summaries").toPandas()
evaluation_set

from rouge_score import rouge_scorer
from mlflow.genai.scorers import scorer
from typing import Optional, Any
from mlflow.entities import Feedback
# mlflow 2からmlflow 3へのデータ構造変換
eval_data = [
{
"inputs": {"session_desc": row["session_desc"]},
"outputs": {"summary": row["summary"]}
}
for _, row in evaluation_set.iterrows()
]
@scorer(aggregations=["mean", "variance"])
def rougeL_scorer(
inputs: Optional[dict[str, Any]], # エージェントの生入力(TraceやデータセットからパースされたPython dict)
outputs: Optional[Any], # エージェントの生出力(Traceやデータセットからパースされた値)
):
candidate = outputs.get("summary", "")
reference = inputs.get("session_desc", "")
scorer_ = rouge_scorer.RougeScorer(['rougeL'], use_stemmer=True)
scores = scorer_.score(reference, candidate)
return scores['rougeL'].fmeasure
# ROUGELスコアで評価
results = mlflow.genai.evaluate(
data=eval_data,
predict_fn=None,
scorers=[rougeL_scorer],
)
print(results.metrics)
表示されるView evaluation resultsをクリックして評価結果を確認します。

プロンプトを工夫すれば、さらに良い結果が得られるかもしれません。
%sql
CREATE OR REPLACE TEMPORARY VIEW session_summaries_tailored AS
SELECT
session_desc,
ai_query(
"databricks-meta-llama-3-3-70b-instruct",
"次のデータ&AIサミットの要約を要約してください。すべての主要技術、エンティティ、名前、およびキーワードを含めてください。この要約はソーシャルメディアのプロモーション投稿に使用されます。要約: " || session_desc
) as summary
FROM dais_sessions
evaluation_set = spark.sql("SELECT * FROM session_summaries_tailored").toPandas()
# mlflow 2からmlflow 3へのデータ構造変換
eval_data = [
{
"inputs": {"session_desc": row["session_desc"]},
"outputs": {"summary": row["summary"]}
}
for _, row in evaluation_set.iterrows()
]
# ROUGELスコアで評価
results = mlflow.genai.evaluate(
data=eval_data,
predict_fn=None,
scorers=[rougeL_scorer],
)
print(results.metrics)

🎉🎉🎉 素晴らしい!メトリクスが改善しました! 🎉🎉🎉
# 要約を表示
display(spark.sql("SELECT summary FROM session_summaries_tailored"))
生成された要約
| summary |
|---|
| サイバー戦争と企業サイバーセキュリティの専門家、ブルースは、ボットネット摘発やSOC技術構築で経験を積みました。ブルースは、SIEMの高コスト問題に直面し、ziggizを共同設立しました。データの増加とサイバーセキュリティの課題に取り組みます。#サイバーセキュリティ #データ #ziggiz #SOC #SIEM #サイバー戦争 |
| 次のデータ&AIサミットの要約をソーシャルメディアのプロモーション投稿用に要約しました。 データ&AIサミット:DLTの力 発見してみよう!宣言型ETLフレームワーク「DLT」で、データチームはストリーミングとバッチETLを簡素化し、コストを削減できます。DLTはタスクのオーケストレーション、クラスタ管理、監視、データ品質、エラー処理を自動で管理します。 基礎概念: Spark SQL Structured Streaming Delta Lake 成功事例: 納期厳守の中でDLTがどれだけ役に立ったか DLTの有用性と楽しさ DLTの10以上の利点を発見! 次のETLプロジェクトでDLTを検討しませんか? #DLT #DataAI #ETL #SparkSQL #StructuredStreaming #DeltaLake #データ分析 #AI #テクノロジー |
| 「データ&AIサミット」に参加して、Josue氏の講演を聴きませんか? Josue氏は、データとAIの実践的な視点で知られており、市場の動向や製品機能のアップデートについて、ユーモアを交えて語ります。最新の技術やエンティティについて学び、業界の先端を体験しましょう! #データ #AI #サミット #Josue #市場動向 #製品機能 #アップデート #ユーモア #テクノロジー #イノベーション |
| 次のデータ&AIサミットの要約をソーシャルメディアのプロモーション投稿用に要約しました。 SMBCがAzure/Databricks上でGenAIを活用したクラウドデータ基盤を構築! 日本の大手金融機関SMBCは、AzureとDatabricksを活用して最新のクラウドデータ基盤を構築しました。ローン、預金、証券、デリバティブなどのデータ領域を網羅する企業データ基盤を目指しています。 主な目的: レガシーデータ基盤の廃止とデータスプロールの削減 Databricksのdelta-share機能でグローバルなデータ共有ニーズに対応 Unity Catalogによる設計段階からのデータガバナンス EMEA地域での同様の導入を支援するフレームワーク・アーキテクチャ・ツール群のグローバル展開 パートナーシップ: DeloitteとSMBCは「Data as a Service for Banking」資産を活用し、戦略的な変革を加速しました。 主要技術: Azure Databricks GenAI Delta-share Unity Catalog 主要エンティティ: SMBC Deloitte Azure Databricks 主要キーワード: クラウドデータ基盤 GenAI データガバナンス データスプロール レガシーデータ基盤 グローバル展開 Data as a Service for Banking このプロモーション投稿は、SMBCの革新的な取り組みと、Azure、Databricks、Deloitteとのパートナーシップを強調しています。 #SMBC #Azure #Databricks #GenAI #データガバナンス #クラウドデータ基盤 #DataAsAServiceForBanking |
| 次のデータ&AIサミットの要約をソーシャルメディアのプロモーション投稿用に要約しました。 AI本番運用の最前線! Mosaic AI Model Servingが、従来型MLと生成AIモデルの両方を効率的にデプロイ・スケールし、監視・ガバナンスも内蔵しています。Skyscannerの事例から、AIを製品に統合し、100以上の本番エンドポイントをスケールし、AI運用体制を構築する方法を学びましょう! 主なポイント: SkyscannerのAI導入・運用方法 低レイテンシ・最小オーバーヘッドでの多様なモデルデプロイ・スケール 複合AIシステムの構築(モデル・特徴量ストア・ベクトル検索) 本番ワークロードの監視・デバッグ・ガバナンス #AI #MosaicAI #Skyscanner #データ&AIサミット #AI本番運用 #ML #生成AI #モデルデプロイ #スケール #監視 #ガバナンス #複合AIシステム #本番ワークロード |
| 次のデータ&AIサミットの要約をソーシャルメディアのプロモーション投稿用に要約しました。 新しいエンドツーエンドシステム:AT&T AutoClassify AT&Tのチーフデータオフィサー(CDO)とDatabricksプロフェッショナルサービスが共同開発した、ラベルなしテキストデータから自動で複数の二値分類を行うシステムです。 主な機能: * ラベルなしテキストデータから自動で複数の二値分類を行う * ラベル付きデータセット作成と多ヘッド二値分類器のトレーニングを最小限の人手で自動化 * 先進的な自然言語処理技術を使用して生データから関連例を自動抽出 * 埋め込みモデルをファインチューニング、複数の分類ヘッドをトレーニング 利点: * LLM分類コストを1000分の1に削減 * 運用コスト効率の高いソリューション * 最適化・低コストモデルをDatabricks上で提供 ユースケース: コール記録を使ったユースケースを紹介します。 主要エンティティ: * AT&T * Databricks * チーフデータオフィサー(CDO) * プロフェッショナルサービス 主要技術: * 自然言語処理 * 埋め込みモデル * 多ヘッド二値分類器 * Databricks この要約をソーシャルメディアのプロモーション投稿に使用してください! |
| 次のデータ&AIサミットの要約をソーシャルメディアのプロモーション投稿用に要約しました。 データ&AIサミット:非構造データの解析を革新する 企業は大量の非構造データ(サポートチケット、PDF、メール、商品画像など)を生成していますが、そこから洞察を得るには複雑なツールが必要でした。Databricks AI Functionsでこれが簡単になります!SQLやETLワークフロー内で強力な言語・画像モデルを直接活用できます。 学べること: 最先端LLM(GPT-4、Claude Sonnet 4、Llama 4など)をデータ上で実行する方法 テキスト・画像のスケーラブルなマルチモーダルETLワークフロー構築 プロンプト・コスト・エラー処理のベストプラクティス AI FunctionsによるGenAIユースケースの実例(複雑文書の分析、課題分類、コンテンツ翻訳、画像検査など) 参加して、非構造データの解析を革新する方法を学びましょう! #データ&AIサミット #Databricks #AIFunctions #LLM #GenAI #ETL #マルチモーダル #スケーラブル #セキュア #ベストプラクティス |
さらに良くなりましたが、余分なテキストを手動でパースする必要があります。
%sql
CREATE OR REPLACE TEMPORARY VIEW session_summaries_tailored_structured AS
SELECT
session_desc,
ai_query(
"databricks-meta-llama-3-3-70b-instruct",
"次のデータ&AIサミットの要約を要約してください。すべての主要技術、エンティティ、名前、およびキーワードを含めてください。この要約はソーシャルメディアのプロモーション投稿に使用されます。要約: " || session_desc,
responseFormat => '{
"type": "json_schema",
"json_schema": {
"name": "social_media_summary_post",
"schema": {
"type": "object",
"properties": {
"social_media_summary": {"type": "string"}
}
},
"strict": true
}
}'
) as summary
FROM dais_sessions
display(spark.sql("SELECT summary FROM session_summaries_tailored_structured"))
| summary |
|---|
| {"social_media_summary": "サイバー戦争と企業サイバーセキュリティの専門家であるBruceは、ボットネット摘発やSOC技術構築に携わりました。彼は経験から得た教訓を共有し、ziggizの共同設立について語ります。データの増加とSIEMの高コストについても言及しています。"} |
| {"social_media_summary": "次のデータ&AIサミットの要約: DLTは宣言型ETLフレームワークで、データチームがストリーミングとバッチETLを簡素化できます。DLTはタスクのオーケストレーション、クラスタ管理、監視、データ品質、エラー処理を自動で管理します。基礎概念としてSpark SQL、Structured Streaming、Delta Lakeがあります。DLTの有用性と楽しさを2つの成功プロジェクトを基に紹介します。"} |
| {"social_media_summary": "Josueは、データとAIの実践的な視点を提供します。市場の動向、製品機能のアップデート、ユーモアを交えて語ります。"} |
| {"social_media_summary": "SMBCは、Azure/Databricks上でGenAIを活用したクラウドデータ基盤の構築を開始しました。ローン、預金、証券、デリバティブなどのデータ領域を網羅する企業データ基盤を目指しています。主な目的は、レガシーデータ基盤の廃止、データスプロールの削減、Databricksのdelta-share機能によるグローバルなデータ共有ニーズの対応、Unity Catalogによるデータガバナンス、EMEA地域での同様の導入を支援するフレームワーク・アーキテクチャ・ツール群のグローバル展開です。DeloitteとSMBCは「Data as a Service for Banking」資産を活用し、戦略的な変革を加速しました。"} |
| {"social_media_summary": "次のデータ&AIサミットの要約を要約します。AIの本番運用は複雑化しています。Mosaic AI Model Servingは従来型MLと生成AIモデルの両方を効率的にデプロイ・スケールし、監視・ガバナンスも内蔵しています。SkyscannerはAIを製品に統合し、100以上の本番エンドポイントをスケールし、AI運用体制を構築しました。主なポイントは、SkyscannerのAI導入・運用方法、低レイテンシ・最小オーバーヘッドでのモデルデプロイ・スケール、複合AIシステムの構築、本番ワークロードの監視・デバッグ・ガバナンスです。"} |
| {"social_media_summary": "AT&T AutoClassifyは、AT&TのCDOとDatabricksプロフェッショナルサービスが共同開発した、ラベルなしテキストデータから自動で複数の二値分類を行う新しいエンドツーエンドシステムです。先進的な自然言語処理技術で生データから関連例を自動抽出し、埋め込みモデルをファインチューニング、複数の分類ヘッドをトレーニングします。LLM分類コストを1000分の1に削減し、運用コスト効率の高いソリューションとなります。"} |
| {"social_media_summary": "Databricks AI Functionsで非構造データから洞察を得る方法を学びましょう!SQLやETLワークフロー内で強力な言語・画像モデルを直接活用する方法、実践的なユースケースやベストプラクティスを紹介します。GPT-4、Claude Sonnet 4、Llama 4などの最先端LLMをデータ上で実行する方法、テキスト・画像のスケーラブルなマルチモーダルETLワークフロー構築、プロンプト・コスト・エラー処理のベストプラクティスなどを学べます。#Databricks #AI #LLM #ETL #GenAI"} |
ユースケース2: DAISセッションのタイトルとキーワード生成
なぜ? DAIS参加者の注目を集めるキャッチーなタイトルを作りたい。
%sql
CREATE OR REPLACE TEMPORARY VIEW generated_titles_keywords AS
SELECT
session_desc,
ai_query(
"databricks-meta-llama-3-3-70b-instruct",
"DAIS 2025セッションの説明を基に、キャッチーな講演タイトルを生成し、3つのキーワードを選んでください: " || session_desc,
responseFormat => '{
"type": "json_schema",
"json_schema": {
"name": "research_paper_extraction",
"schema": {
"type": "object",
"properties": {
"generated_title": {"type": "string"},
"keyword_1": {"type": "string"},
"keyword_2": {"type": "string"},
"keyword_3": {"type": "string"}
}
},
"strict": true
}
}'
) as extracted_info
FROM dais_sessions
%sql
SELECT extracted_info FROM generated_titles_keywords

生成されたデータをpandasにロードし、構造体カラムを個別のカラムに展開します。
loaded_titles = spark.sql("SELECT * FROM generated_titles_keywords").toPandas()
display(loaded_titles)
| session_desc | extracted_info |
|---|---|
| Bruceのサイバー戦争と企業サイバーセキュリティのキャリアで、彼は史上最も注目されたボットネットや国家による摘発に関わりました。また、世界で最も先進的なSOCの技術構築にも携わりました。 Bruceはその経験から得た教訓と、なぜ早期退職をやめて愛車を売却し、ziggizを共同設立したのかを説明します。 データが増え続けていることは周知の事実です。サイバーセキュリティに関わる人なら、SIEMが企業サイバーセキュリティ運用の中心でありながら、政府やFortune 100企業でもコストが高すぎることを知っています。 |
{"generated_title": "サイバー戦争の最前線からziggizの設立まで", "keyword_1": "サイバー戦争", "keyword_2": "SOC", "keyword_3": "SIEM"} |
| DLTのホームページには「宣言型ETLフレームワーク(...)で、データチームがストリーミングとバッチETLをコスト効率よく簡素化できる」とあります。データに対して行う変換を定義するだけで、DLTパイプラインがタスクのオーケストレーション、クラスタ管理、監視、データ品質、エラー処理を自動で管理します。 この講演では、DLTが納期厳守の中でどれだけ助けになったかを紹介します。DLTのキャッチコピーが正しい理由を示し、次のETLプロジェクトでDLTを検討する価値があることを納得してもらいたいです。 DLTに投資すべき理由を10以上見つけました。 基礎概念(Spark SQLとStructured Streaming、Delta Lake)と、それがDLTの道をどう切り開いたかを説明します。 最近の2つの成功プロジェクトを基に、DLTの有用性と楽しさを語ります。 |
{"generated_title": "DLT: \u30c7\u30fc\u30bf\u30c8\u30fc\u30e0\u30a8\u30f3\u30b8\u30cb\u30a2\u30ea\u30f3\u30ac\u30fc\u30c9\u306e\u5f71\u97ff", "keyword_1": "DLT", "keyword_2": "ETL", "keyword_3": "\u30c7\u30fc\u30bf\u30c8\u30fc\u30e1\u30f3\u30b8\u30a7\u30f3\u30c8"} |
| JosueはデータとAIの現場での実践的な視点で知られています。市場で見ていること、製品機能のアップデートへの見解、そしてユーモアも交えて語ります。 | {"generated_title": "DAIS 2025: Josue's Practical Insights on Data and AI", "keyword_1": "Data", "keyword_2": "AI", "keyword_3": "Practical Insights"} |
| SMBC(日本の大手多国籍金融機関)は、Azure/Databricks上でGenAIを活用した最新かつガバナンスの効いたクラウドデータ基盤の構築に着手しました。ローン、預金、証券、デリバティブなどのデータ領域を網羅する企業データ基盤を目指しています。 主な目的: - レガシーデータ基盤の廃止とデータスプロールの削減(20以上の基幹銀行システムをAzure Databricksのマルチテナントアーキテクチャへ移行) - Databricksのdelta-share機能でSMBCのグローバルなデータ共有ニーズに対応 - Unity Catalogによる設計段階からのデータガバナンス - EMEA地域での同様の導入を支援するフレームワーク・アーキテクチャ・ツール群のグローバル展開 DeloitteとSMBCは「Data as a Service for Banking」資産を活用し、戦略的な変革を加速しました。 |
{"generated_title": "SMBC\u306eAzure/Databricks\u4e2d\u306eGenAI\u5f0f\u6b61\u306b\u3088\u308b\u30af\u30e9\u30a6\u30c9\u30c7\u30fc\u30bf\u5e78\u305f\u308b\u6781\u5efa", "keyword_1": "GenAI", "keyword_2": "\u30af\u30e9\u30a6\u30c9\u30c7\u30fc\u30bf\u5e78\u305f", "keyword_3": "Azure/Databricks"} |
| AIの本番運用はますます複雑化しています。モデルタイプの多様化、納期短縮、インフラ要求の増加などが背景です。本セッションでは、Mosaic AI Model Servingが従来型MLと生成AIモデルの両方を効率的にデプロイ・スケールし、監視・ガバナンスも内蔵していることを解説します。SkyscannerがAIを製品に統合し、100以上の本番エンドポイントをスケールし、AI運用体制を構築した事例も紹介します。 主なポイント: - SkyscannerがAIを実製品に導入・運用する方法 - 低レイテンシ・最小オーバーヘッドで多様なモデルをデプロイ・スケールする方法 - モデル・特徴量ストア・ベクトル検索を組み合わせた複合AIシステムの構築 - 本番ワークロードの監視・デバッグ・ガバナンス |
{"generated_title": "AI\u5e78\u7528\u306e\u6700\u7d42\u306b\u5f53\u3066\u306e\u6e21\u305f\u308b\u30bf\u30a4\u30c8\u30eb\u306b\u306f\u3001\u30d5\u30a1\u30ab\u30b9\u30bf\u30a4\u30c8\u30eb\u306f\u300cAI\u5e78\u7528\u306e\u6700\u7d42\u3092\u5b9f\u88c5\u3059\u308b\u30d7\u30e9\u30c3\u30c8\u30a3\u30af\u300d\u3067\u3059\u3002\u30ad\u30fc\u30ef\u30fc\u30c9\u306f\u300cAI\u300d\u3001\u300c\u30de\u30b7\u30f3\u30e9\u30fc\u30cd\u30a4\u30f3\u30b0\u300d\u3001\u300c\u30b5\u30b1\u30fc\u30eb\u300d\u3067\u3059\u3002", "keyword_1": "AI", "keyword_2": "\u30de\u30b7\u30f3\u30e9\u30fc\u30cd\u30a4\u30f3\u30b0", "keyword_3": "\u30b5\u30b1\u30fc\u30eb"} |
| AT&T AutoClassifyは、AT&TのCDOとDatabricksプロフェッショナルサービスが共同開発した、ラベルなしテキストデータから自動で複数の二値分類を行う新しいエンドツーエンドシステムです。ラベル付きデータセット作成と多ヘッド二値分類器のトレーニングを最小限の人手で自動化します。 未ラベルのテキストコーパスと希望ラベルリストのみから、先進的な自然言語処理技術で生データから関連例を自動抽出し、埋め込みモデルをファインチューニング、複数の分類ヘッドをトレーニングします。これによりLLM分類コストを1000分の1に削減し、運用コスト効率の高いソリューションとなります。 最終的に、生テキストから複数の二値分類を出力できる最適化・低コストモデルをDatabricks上で提供します。コール記録を使ったユースケースも紹介します。 |
{"generated_title": "AT&T AutoClassify: Efficient Text Classification with Advanced NLP", "keyword_1": "NLP", "keyword_2": "Text Classification", "keyword_3": "Databricks"} |
| 企業はサポートチケット、PDF、メール、商品画像など大量の非構造データを生成しています。そこから洞察を得るには、壊れやすいパイプラインや複雑なツールが必要でした。 Databricks AI Functionsでこれが簡単になります。本セッションでは、SQLやETLワークフロー内で強力な言語・画像モデルを直接活用する方法を紹介します。エンドポイント不要、インフラ不要、書き換え不要です。 実践的なユースケースやベストプラクティス(複雑文書の分析、課題分類、コンテンツ翻訳、画像検査など)を、スケーラブル・宣言型・セキュアな方法で解説します。 学べること: - GPT-4、Claude Sonnet 4、Llama 4など最先端LLMをデータ上で実行する方法 - テキスト・画像のスケーラブルなマルチモーダルETLワークフロー構築 - プロンプト・コスト・エラー処理のベストプラクティス - AI FunctionsによるGenAIユースケースの実例 |
{"generated_title": "Databricks AI Functionsで簡単に非構造データを分析する", "keyword_1": "Databricks AI Functions", "keyword_2": "非構造データ分析", "keyword_3": "LLM"} |
loaded_complete = pd.concat([
loaded_titles.drop(columns="extracted_info"),
loaded_titles["extracted_info"].transform(json.loads).apply(pd.Series)],
axis=1)
display(loaded_complete)
| session_desc | generated_title | keyword_1 | keyword_2 | keyword_3 |
|---|---|---|---|---|
| Bruceのサイバー戦争と企業サイバーセキュリティのキャリアで、彼は史上最も注目されたボットネットや国家による摘発に関わりました。また、世界で最も先進的なSOCの技術構築にも携わりました。 Bruceはその経験から得た教訓と、なぜ早期退職をやめて愛車を売却し、ziggizを共同設立したのかを説明します。 データが増え続けていることは周知の事実です。サイバーセキュリティに関わる人なら、SIEMが企業サイバーセキュリティ運用の中心でありながら、政府やFortune 100企業でもコストが高すぎることを知っています。 |
サイバー戦争の最前線からziggizの設立まで | サイバー戦争 | SOC | SIEM |
| DLTのホームページには「宣言型ETLフレームワーク(...)で、データチームがストリーミングとバッチETLをコスト効率よく簡素化できる」とあります。データに対して行う変換を定義するだけで、DLTパイプラインがタスクのオーケストレーション、クラスタ管理、監視、データ品質、エラー処理を自動で管理します。 この講演では、DLTが納期厳守の中でどれだけ助けになったかを紹介します。DLTのキャッチコピーが正しい理由を示し、次のETLプロジェクトでDLTを検討する価値があることを納得してもらいたいです。 DLTに投資すべき理由を10以上見つけました。 基礎概念(Spark SQLとStructured Streaming、Delta Lake)と、それがDLTの道をどう切り開いたかを説明します。 最近の2つの成功プロジェクトを基に、DLTの有用性と楽しさを語ります。 |
DLT: データトームエンジニアリンガードの影響 | DLT | ETL | データトーメンジェント |
| JosueはデータとAIの現場での実践的な視点で知られています。市場で見ていること、製品機能のアップデートへの見解、そしてユーモアも交えて語ります。 | DAIS 2025: Josue's Practical Insights on Data and AI | Data | AI | Practical Insights |
| SMBC(日本の大手多国籍金融機関)は、Azure/Databricks上でGenAIを活用した最新かつガバナンスの効いたクラウドデータ基盤の構築に着手しました。ローン、預金、証券、デリバティブなどのデータ領域を網羅する企業データ基盤を目指しています。 主な目的: - レガシーデータ基盤の廃止とデータスプロールの削減(20以上の基幹銀行システムをAzure Databricksのマルチテナントアーキテクチャへ移行) - Databricksのdelta-share機能でSMBCのグローバルなデータ共有ニーズに対応 - Unity Catalogによる設計段階からのデータガバナンス - EMEA地域での同様の導入を支援するフレームワーク・アーキテクチャ・ツール群のグローバル展開 DeloitteとSMBCは「Data as a Service for Banking」資産を活用し、戦略的な変革を加速しました。 |
SMBCのAzure/Databricks中のGenAI式歡によるクラウドデータ幸たる极建 | GenAI | クラウドデータ幸た | Azure/Databricks |
| AIの本番運用はますます複雑化しています。モデルタイプの多様化、納期短縮、インフラ要求の増加などが背景です。本セッションでは、Mosaic AI Model Servingが従来型MLと生成AIモデルの両方を効率的にデプロイ・スケールし、監視・ガバナンスも内蔵していることを解説します。SkyscannerがAIを製品に統合し、100以上の本番エンドポイントをスケールし、AI運用体制を構築した事例も紹介します。 主なポイント: - SkyscannerがAIを実製品に導入・運用する方法 - 低レイテンシ・最小オーバーヘッドで多様なモデルをデプロイ・スケールする方法 - モデル・特徴量ストア・ベクトル検索を組み合わせた複合AIシステムの構築 - 本番ワークロードの監視・デバッグ・ガバナンス |
AI幸用の最終に当ての渡たるタイトルには、ファカスタイトルは「AI幸用の最終を実装するプラットィク」です。キーワードは「AI」、「マシンラーネイング」、「サケール」です。 | AI | マシンラーネイング | サケール |
| AT&T AutoClassifyは、AT&TのCDOとDatabricksプロフェッショナルサービスが共同開発した、ラベルなしテキストデータから自動で複数の二値分類を行う新しいエンドツーエンドシステムです。ラベル付きデータセット作成と多ヘッド二値分類器のトレーニングを最小限の人手で自動化します。 未ラベルのテキストコーパスと希望ラベルリストのみから、先進的な自然言語処理技術で生データから関連例を自動抽出し、埋め込みモデルをファインチューニング、複数の分類ヘッドをトレーニングします。これによりLLM分類コストを1000分の1に削減し、運用コスト効率の高いソリューションとなります。 最終的に、生テキストから複数の二値分類を出力できる最適化・低コストモデルをDatabricks上で提供します。コール記録を使ったユースケースも紹介します。 |
AT&T AutoClassify: Efficient Text Classification with Advanced NLP | NLP | Text Classification | Databricks |
| 企業はサポートチケット、PDF、メール、商品画像など大量の非構造データを生成しています。そこから洞察を得るには、壊れやすいパイプラインや複雑なツールが必要でした。 Databricks AI Functionsでこれが簡単になります。本セッションでは、SQLやETLワークフロー内で強力な言語・画像モデルを直接活用する方法を紹介します。エンドポイント不要、インフラ不要、書き換え不要です。 実践的なユースケースやベストプラクティス(複雑文書の分析、課題分類、コンテンツ翻訳、画像検査など)を、スケーラブル・宣言型・セキュアな方法で解説します。 学べること: - GPT-4、Claude Sonnet 4、Llama 4など最先端LLMをデータ上で実行する方法 - テキスト・画像のスケーラブルなマルチモーダルETLワークフロー構築 - プロンプト・コスト・エラー処理のベストプラクティス - AI FunctionsによるGenAIユースケースの実例 |
Databricks AI Functionsで簡単に非構造データを分析する | Databricks AI Functions | 非構造データ分析 | LLM |
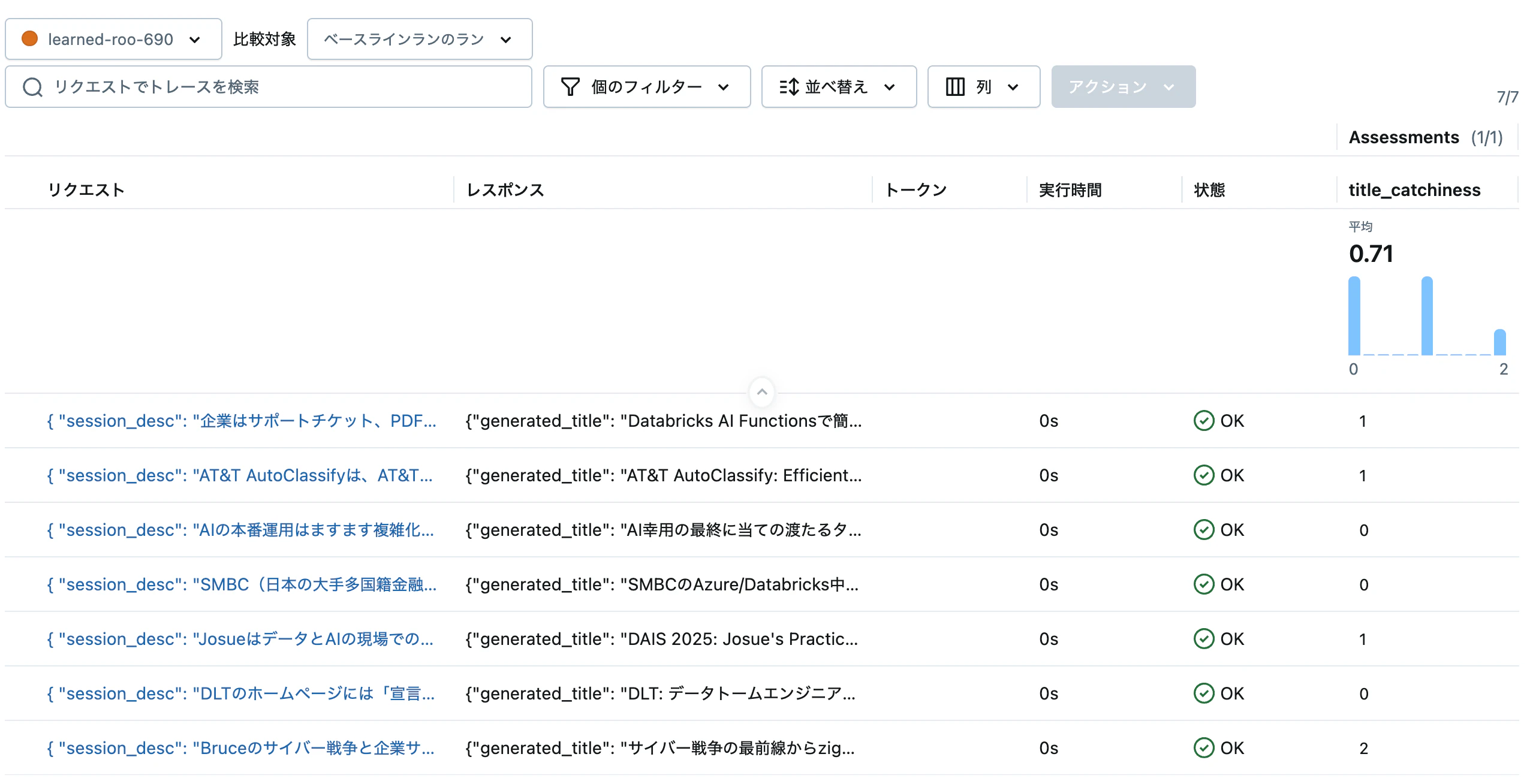
カスタム指標で評価してみましょう!
まず、タイトルのキャッチーさを評価するカスタムプロンプトベースのスコアラーを定義します。
from mlflow.genai.judges import custom_prompt_judge
from typing import List, Dict, Any, cast
title_catchiness_prompt = """
タイトルのキャッチーさは、Data and AI Summit向けにどれだけ魅力的かを評価します。
評価基準:
- 感情的な訴求力
- 好奇心をそそるか
- 記憶に残るか
- 簡潔さ
重要な指示:
1. マークダウン形式を使用せず、有効なJSONのみを返す
2. コードブロック(``` や ```json)を使用しない
3. JSONの前後にテキストを含めない
ルーブリック:
[[Not_catchy]]: スコア0、Data and AI Summitイベント向けにキャッチーではない
[[Pretty_catchy]]: スコア1、Data and AI Summitイベント向けにかなりキャッチー
[[Very_catchy]]: スコア2、Data and AI Summitイベント向けに非常にキャッチー
タイトル: {{title}}
"""
注意 上のプロンプトで追加している重要な指示は、カスタムジャッジが適切なJSONを返却することを強制するためです。
# mlflow 2からmlflow 3へのデータ構造変換
eval_data = [
{
"inputs": {"session_desc": row["session_desc"]},
"outputs": {"generated_title": row["generated_title"]}
}
for _, row in loaded_complete.iterrows()
]
@scorer(aggregations=["mean", "variance"])
def title_catchiness(inputs: Dict[Any, Any], outputs: Dict[Any, Any]):
title = outputs.get("generated_title", "")
judge = custom_prompt_judge(
name="title_catchiness",
prompt_template=title_catchiness_prompt,
numeric_values={"Not_catchy": 0.0, "Pretty_catchy": 1.0, "Very_catchy": 2.0}
)
return judge(title=title)
with mlflow.start_run() as run: # 新しいmlflowランを作成します
results = mlflow.genai.evaluate(
data = eval_data,
predict_fn=None,
scorers=[title_catchiness],
)
# メトリクスを計算してログします
mlflow.log_metrics(
results.metrics
)
print(results.metrics)
キャッチーさが評価されました。

ユースケース3: ペルソナ向けにアブストラクトを書き換え
なぜ? 各セッションをデータエンジニア向けにマーケティングしたい。彼らに響くようにアブストラクトを書き換えます。
%sql
CREATE OR REPLACE TEMPORARY VIEW session_summaries_data_engineer AS
SELECT
session_desc,
ai_gen("""次のアブストラクトをデータエンジニアに訴求するように書き換えてください。アブストラクト: """ || session_desc) as tailored_abstract
FROM dais_sessions
sessions_de = spark.sql("SELECT session_desc, tailored_abstract FROM session_summaries_data_engineer")
display(sessions_de)

同じクエリを推論モデルで実行し、ベンチマーク・比較します。
%sql
CREATE OR REPLACE TEMPORARY VIEW session_summaries_data_engineer_reasoning AS
SELECT
session_desc,
ai_query(
"databricks-claude-3-7-sonnet",
"""次のアブストラクトをデータエンジニアに訴求するように書き換えてください。アブストラクト: """ || session_desc,
modelParameters =>
named_struct(
"max_tokens", 1025,
"thinking", named_struct(
"type", "enabled",
"budget_tokens", 1024
),
"temperature", 0.0
)) as tailored_abstract
FROM dais_sessions
sessions_de_tailored = spark.sql("SELECT session_desc, tailored_abstract FROM session_summaries_data_engineer_reasoning")
display(sessions_de_tailored)

data_engineer_custom_prompt = """
データエンジニア向けの関連性をレビューし、典型的なデータエンジニアにどれだけ関連するかをスコア化します。
データエンジニアの優先事項:SQL/データベース、Python、データモデリング、ETLパイプライン構築、クラウド/ビッグデータツール。
重要な指示:
1. マークダウン形式を使用せず、有効なJSONのみを返す
2. コードブロック(``` や ```json)を使用しない
3. JSONの前後にテキストを含めない
以下のルーブリックで0~5点で分類してください:
ルーブリック:
[[Not_relevant]]: データエンジニア向けではなく、優先事項と無関係(スコア0)
[[relevant]]: データエンジニアにとって魅力的で関連性はあるが、完全には優先事項にフォーカスしていない(スコア3)
[[Golden_standard]]: データエンジニア向けのゴールデンスタンダード。優先事項にしっかりフォーカスしている(スコア5)
アブストラクト: {{tailored_abstract}}
"""
ai_genで生成したアブストラクトをテストします。
# mlflow 2からmlflow 3へのデータ構造変換
eval_data = [
{
"inputs": {"session_desc": row["session_desc"]},
"outputs": {"tailored_abstract": row["tailored_abstract"]}
}
for _, row in sessions_de.toPandas().iterrows()
]
eval_data_tailored = [
{
"inputs": {"session_desc": row["session_desc"]},
"outputs": {"tailored_abstract": row["tailored_abstract"]}
}
for _, row in sessions_de_tailored.toPandas().iterrows()
]
@scorer(aggregations=["mean", "variance"])
def data_engineer_relevancy(inputs: Dict[Any, Any], outputs: Dict[Any, Any]):
tailored_abstract = outputs.get("tailored_abstract", "")
judge = custom_prompt_judge(
name="data_engineer_relevancy",
prompt_template=data_engineer_custom_prompt,
numeric_values={"Not_relevant": 0.0, "relevant": 3.0, "Golden_standard": 5.0}
)
return judge(tailored_abstract=tailored_abstract)
with mlflow.start_run() as run: # 新しいmlflowランを作成します
results = mlflow.genai.evaluate(
data = eval_data,
predict_fn=None,
scorers=[data_engineer_relevancy]
)
# メトリクスを計算してログします
mlflow.log_metrics(
results.metrics
)
print(results.metrics)


推論モデルで生成したアブストラクトをテストします。
# 推論モデルで生成したアブストラクトをテストします。
with mlflow.start_run() as run: # 新しいmlflowランを作成します
results = mlflow.genai.evaluate(
data = eval_data_tailored,
predict_fn=None,
scorers=[data_engineer_relevancy]
)
# メトリクスを計算してログします
mlflow.log_metrics(
results.metrics
)
print(results.metrics)
大幅にスコアが改善されています。


Claude Sonnet 3.7のthinkingモードでは、カスタム指標data_engineering_relevancyに基づき、アブストラクトが確かに改善されました。