こちらの記事で紹介されていたデータが興味深かったので、説明されている内容に沿ってストリーミング処理を組み、Databricks SQLでダッシュボードに表示するところまでやってみました。
ソースデータ
上の記事で言及しているデータはこちら。シアトルの911への通報をリアルタイムでJSONファイルとして公開しています。まさにオープンデータ。5分周期で更新されます。
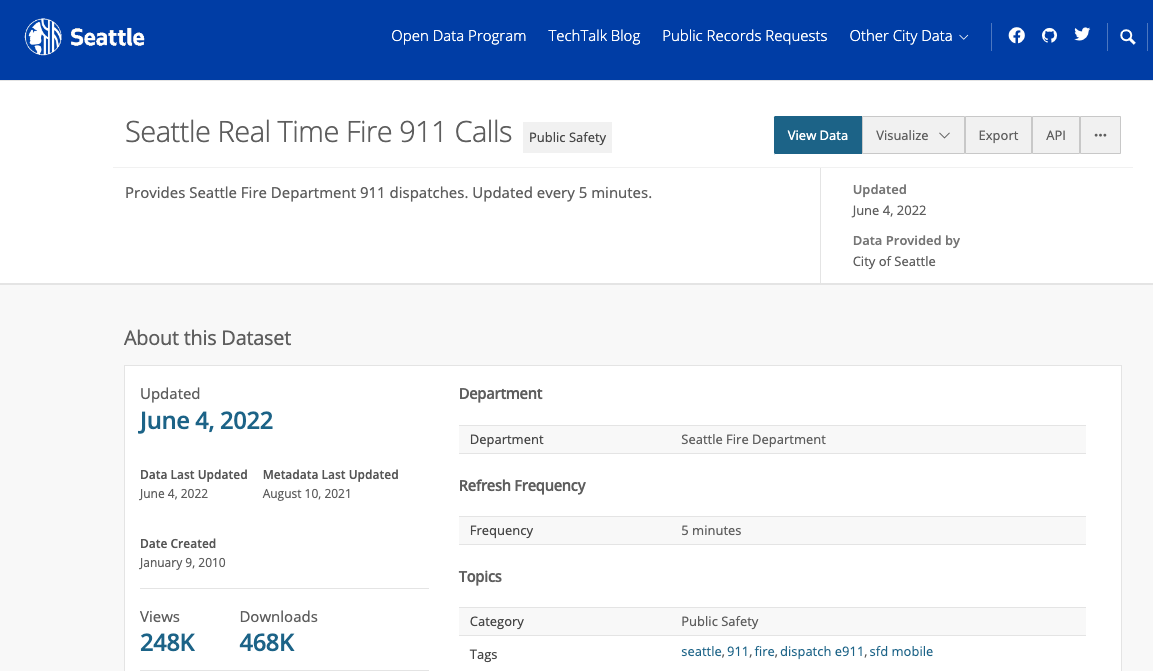
- 右上のAPIをクリックしJSONをクリックするとURLが表示されるのでこれをコピーしておきます。

- ブラウザで表示すると内容を確認することができます。

- これを定期的にJSONファイルとして保存して、ストリーミングのデータソースとします。
JSONファイルに保存する
Databricksノートブックを作成して、以下のロジックを記述していきます。
# APIのパス
url = "<上のステップで取得したURL>"
# ファイル保存場所
path = "/tmp/takaaki.yayoi@databricks.com/sfd/json"
file = "sfd-"
extension = ".json"
def save_json_to_file(api, path, file, extension):
import urllib.request as request
import json
import time
# ファイル保存場所の作成
dbutils.fs.mkdirs(path)
# APIからデータを取得
with request.urlopen(api) as response:
if response.getcode() == 200:
source = response.read()
data = json.loads(source)
else:
print("APIからデータを取得しようとした際にエラーが発生しました。")
time_str = time.strftime("%Y%m%d-%H%M%S")
filename = f"/dbfs{path}/{file}{time_str}{extension}"
if filename:
# JSONデータの書き込み
with open(filename, "w") as f:
json.dump(data, f)
return filename
以下を実行することで、JSONファイルが保存されることを確認しておきます。このノートブックは後でジョブとして実行することになります。
jsonfile = save_json_to_file(url, path, file, extension)
print(jsonfile)
ノートブックをジョブとして実行
上で作成したノートブック用いてジョブを作成し、ジョブを定期的に実行することで、ストリーミングの入力とします。
注意
- ここでは5分周期で実行していますが、アクセス先の負荷を考慮した設定にするようにしてください。
- それぞれのJSONファイルではレコードの重複がありますが、ここではそのままとします。
- ノートブックの右上にあるスケジュールをクリックします。
- 間隔5分、from: 00とし、5分間隔でノートブックが実行されるようにします。
- アラートの設定などは必要に応じて追加してください。
-
作成をクリックします。

これでジョブが設定されました。
ストリーミング処理の実装
これで定期的にオブジェクトストレージにJSONファイルが到着するようになりました。

これが自動でストリーミング処理に入力されるようにAuto Loaderを使用します。これによって、未処理のファイルのみがストリーミングで処理されるようになります。
そして、ここではDeltaアーキテクチャ(メダリオンアーキテクチャ)に従って、ストリーミング処理のパイプラインを構築していきます。Deltaアーキテクチャの詳細は、デルタ vs ラムダ: なぜデータパイプラインのシンプルさは複雑さに勝るのかをご覧ください。
ブロンズテーブル
生データの保管場所になるのがブロンズテーブルです。
次のステップでJSONのスキーマを指定する必要があるので、上のステップで取得したJSONファイルを退避しておき、そのファイルからスキーマを取得するようにします。
# JSONスキーマのパーシング
jsonFile = spark.read.json("/tmp/takaaki.yayoi@databricks.com/sfd/sfd-20220604-073941.json")
jsonFile.schema
以下の例では、上のジョブによってJSONファイルはDBFSの/tmp/takaaki.yayoi@databricks.com/sfd/json/に到着するものとします。
homeDir = "/tmp/takaaki.yayoi@databricks.com/sfd/json/"
bronzeCkpt = homeDir + "bronze.checkpoint"
silverCkpt = homeDir + "silver.checkpoint"
goldCkpt = homeDir + "gold.checkpoint"
# 保存先をリセット
print(homeDir)
dbutils.fs.rm(bronzeCkpt , True)
dbutils.fs.rm(silverCkpt , True)
dbutils.fs.rm(goldCkpt , True)
以下を実行することで保存されたJSONが順次処理されるストリームが起動します。formatをcloudFilesと指定することでAuto Loaderを利用することができます。結果をDeltaテーブル20210712_demo_takaakiyayoi.sfd_bronze_tableに保持しています。
from pyspark.sql.types import *
# upload_pathに投入されるファイルを読み込むストリームをセットアップ
(spark.readStream.format('cloudFiles')
.option('cloudFiles.format', 'json')
.schema(jsonFile.schema)
.load(homeDir)
.writeStream.format('delta')
.outputMode("append")
.option('checkpointLocation', bronzeCkpt)
.queryName('Bronze Stream')
.toTable("20210712_demo_takaakiyayoi.sfd_bronze_table")
)
ストリーム処理はバッチ処理と異なり、明示的に停止するまで処理を継続します。ストリーム処理のダッシュボードを表示することもできます。

テーブルをクエリーすることで中身を確認することができます。

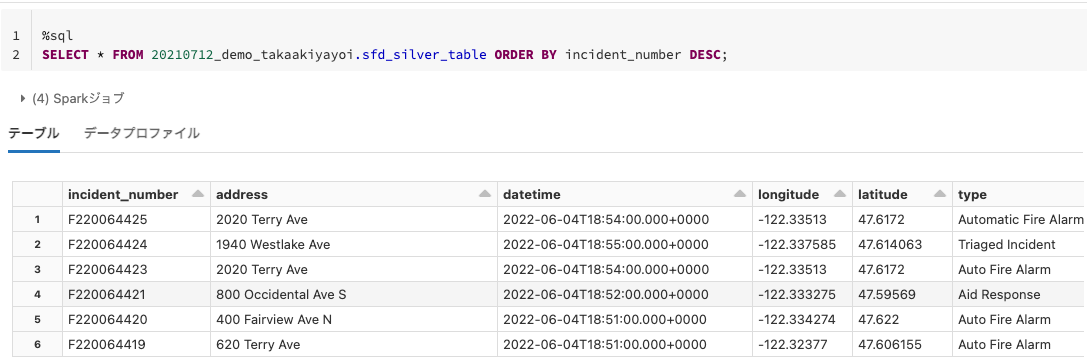
シルバーテーブル
ブロンズテーブルはデータ型が文字列型だったり、不要な列が含まれているので、以降の処理がしやすいようにクレンジング、型変換を行います。この結果がシルバーテーブルに流れ込む形になります。
from pyspark.sql.functions import unix_timestamp, col
(spark
.readStream
.format("delta")
.table("20210712_demo_takaakiyayoi.sfd_bronze_table")
.withColumn("datetime", unix_timestamp(col("datetime"), "yyyy-MM-dd'T'HH:mm:ss.SSS").cast("timestamp"))
.withColumn("latitude", col("latitude").cast("float"))
.withColumn("longitude", col("longitude").cast("float"))
.select(col("incident_number"), col("address"), col("datetime"), col("longitude"), col("latitude"), col("type"))
.writeStream.format('delta')
.outputMode("append")
.option('checkpointLocation', silverCkpt)
.queryName('Silver Stream')
.toTable("20210712_demo_takaakiyayoi.sfd_silver_table")
)
ブロンズテーブルよりシンプルな形になりました。
ゴールドテーブル
BIや機械学習の特徴量としてデータを用いるには、何かしらの集計処理が必要となるケースがほとんどです。そういった集計結果を保持するのがゴールドテーブルです。
以下の例では5分の時間間隔ごとに通報タイプ別の件数をカウントしています。
from pyspark.sql.functions import count, window
( # 上記セルと同様の処理ロジックにWatermarkingを付け加える
spark
.readStream
.format("delta")
.table("20210712_demo_takaakiyayoi.sfd_silver_table")
.withWatermark('datetime','5 minutes') # withWatermark()でWindowの有効期間を設ける
# 即ち一定時間以上遅れて到着したイベントは無視される
.groupBy(col("type"), window('datetime', '5 minutes')) # 時間ウィンドウとタイプで集計
.count()
.selectExpr('type',
'window.start as Start',
'window.end as End',
'count as Total')
.writeStream # Windowの集計結果をGoldテーブルに保存
.format('delta')
.option('checkpointLocation', goldCkpt)
.outputMode('append')
.queryName('Gold Stream')
.toTable("20210712_demo_takaakiyayoi.sfd_gold_table")
)
上で使用しているwithWatermarkのウォーターマークに関しては、以下の記事が勉強になりました。
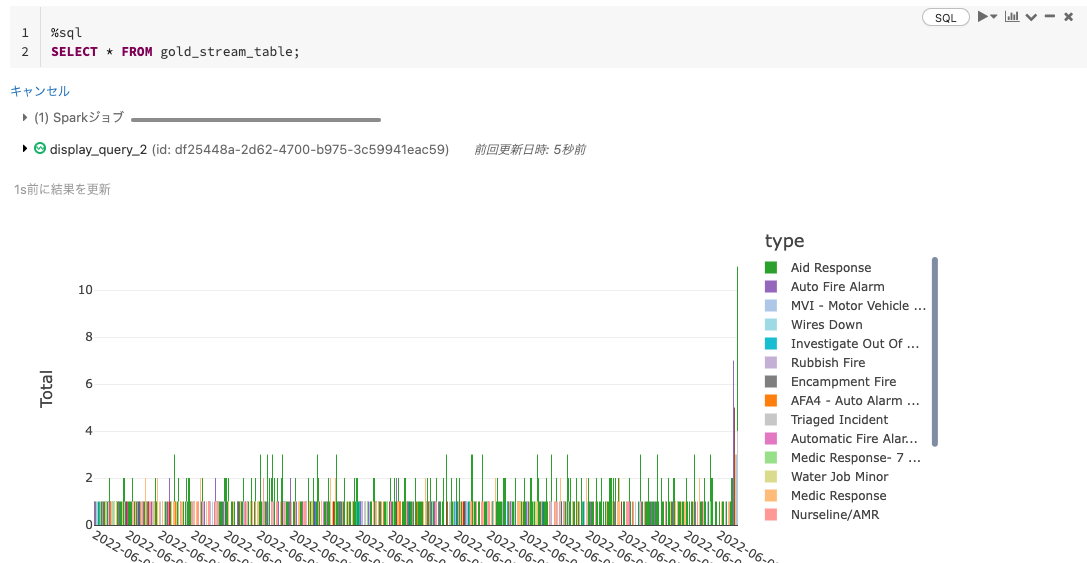
さらにここからストリームを伸ばして、一時テーブルとすることでリアルタイムで更新される一覧やグラフをノートブック上で表示することができます。
# GoldテーブルからREADストリームを作成
gold_stream = spark.readStream.format("delta").table("20210712_demo_takaakiyayoi.sfd_gold_table")
# READストリームからTEMPテーブルを作成
gold_stream.createOrReplaceTempView("gold_stream_table")

Databricks SQLで可視化を行う
これまでのステップで(ニア)リアルタイムに処理を行うデータパイプラインを構築できたわけですが、準備したデータには緯度経度情報も含まれているので、これを活用して可視化を行います。
-
Databricksワークスペースの左にあるサイドメニュー上部のペルソナスイッチャーからSQLを選択します。
-
Databricks SQLに移動します。
-
サイドメニューからSQLエディタを選択します。

-
こちらの画面で上のステップで作成したDeltaテーブルに対するクエリーを定義します。

-
以下のようなクエリーを記述してシルバーテーブルから最新のレコードを取得します。
SQLSELECT DISTINCT * FROM `20210712_demo_takaakiyayoi`.sfd_silver_table ORDER BY datetime DESC LIMIT 500 -
右上の実行をクリックしてクエリーの結果を確認します。
-
+ ビジュアライゼーションを追加をクリックします。
-
Visualization typeからMap (Markers) を選択します。
-
Latitude columnには
latitude、Longitude columnにはlongitudeを指定します。 -
地図上にマーカーがプレビュー表示されるので、見やすいように表示範囲を調整します。

-
Formatタブをクリックし、Show popupにチェックを入れ、Popup templateに
{{ type }} @ {{ address }}と入力します。これで、地図上のマーカーをクリックすると情報が表示されるようになります。保存をクリックします。

-
他にも表示したい情報があれば、クエリーとビジュアライゼーションを定義していきます。
-
これらビジュアライゼーションの部品が出来上がったらサイドメニューからダッシュボードを選択し、ダッシュボードを作成をクリックします。
-
ダッシュボードに名前をつけます。
-
ダッシュボードのキャンバスが表示されるので、ここに上で作成したビジュアライゼーションを追加していきます。
-
右上のAdd > Visualizationを選択します。

-
上で作成したビジュアライゼーションを選択し、ダッシュボードに追加をクリックします。
-
追加したいビジュアライゼーションに対して上の操作を繰り返します。
-
編集完了をクリックします。
-
これで以下のようなダッシュボードが出来上がります。

-
さらにこのダッシュボードを自動で更新されるようにするために、スケジュール処理を設定します。右上のスケジュールをクリックします。

-
5分間隔などを指定して保存をクリックします。 -
これで自動で更新されるダッシュボードの完成です!
重要!
処理の実行が不要になったら明示的にストリーミング処理のノートブックやジョブを停止してください。ノートブックで使用したクラスターも停止してください。
このように、Databrikcsのジョブ、Sparkの構造化ストリーミング、Databricks SQLを組み合わせることで、最新の情報を提供することができるデータパイプライン、ダッシュボードを容易に構築することができます。是非試してみてください。
参考資料