Databricks MLflowのモデルサービングは、モデルのテスト目的でクイックにモデルの動作確認するという目的には適していますが、大量の同時アクセスが予期される、モデルで使用するデータをS3から取得するなど複雑な前処理を組み込みたいといった要件があるプロダクション目的でモデルをサービングする際にはSageMakerのエンドポイントなどを使用することをお勧めしています。
特に、機械学習モデルの推論処理の前処理として「モデルを呼び出す際、IDを指定し推論に用いるデータをS3から取得する」という要件がある場合、PyFuncとしてモデルを実装・トレーニングし、モデルをSageMakerのエンドポイントにデプロイするアプローチを取る必要があります。
注意
- 要件が
モデルを呼び出す際に前処理を追加したいのみであり、S3へのアクセスが不要であれば、PyFuncによる実装のみで十分です。トレーニングしたモデルをMLflowのモデルサービングで運用することが可能です。
- 上記要件に
S3へのアクセスが追加される場合、SageMakerのエンドポイントにモデルのデプロイを行う必要があります。S3へのアクセスを必要とするモデルをMLflowのモデルサービングでデプロイしても、モデルを呼び出す際にエラーとなります。
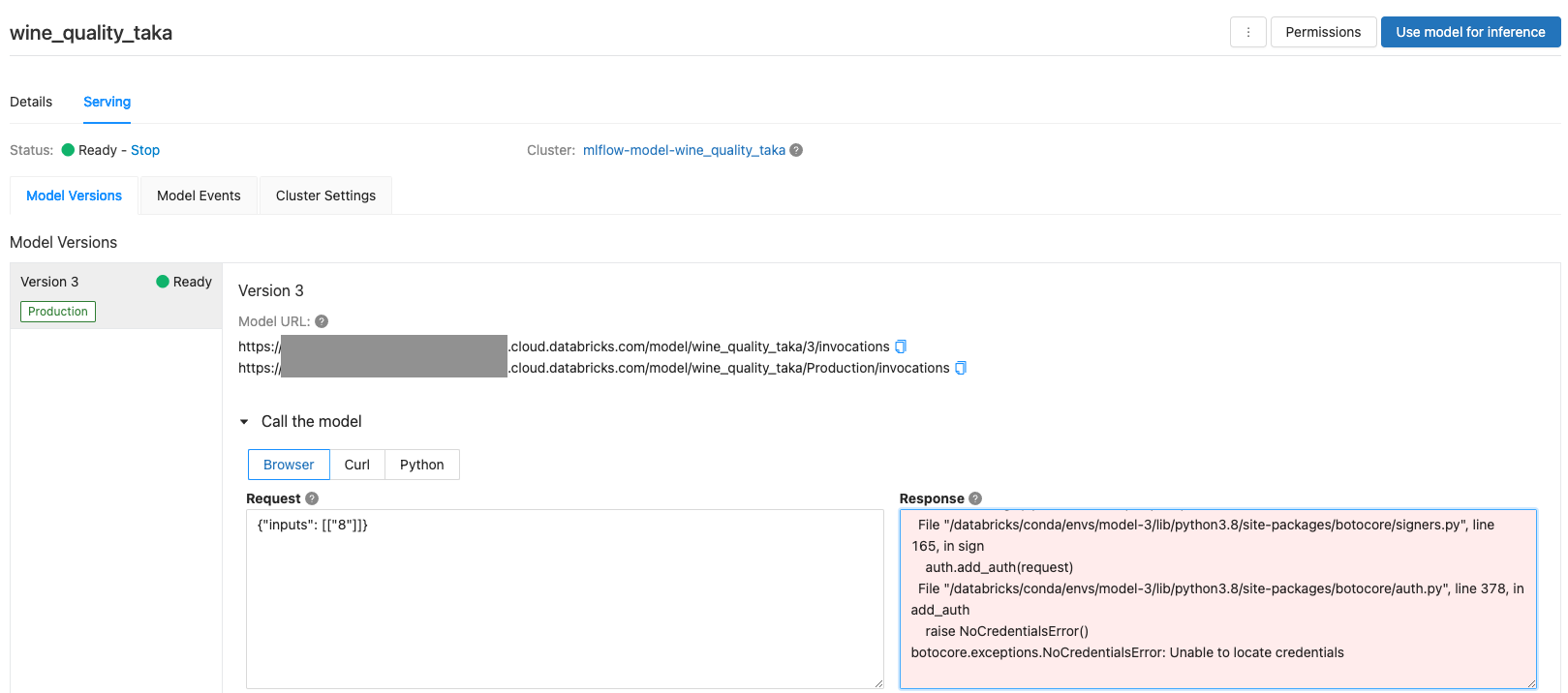
本ノートブックでは、ワインの品質を予測するモデルを構築しますが、前処理を追加したカスタムモデルをSageMakerのエンドポイントにデプロイし、推論に用いるデータのIDを指定して推論を実行します。
推論に用いるデータはdatabricks-datasetsのワインデータにlot_idという連番の列を追加したものとします。このlot_idを指定して推論を行います。
要件
- 本書の処理を行うクラスターには、SageMakerおよびS3にアクセスできるインスタンスプロファイルをアタッチします。
- クラスターライブラリとしてPyPIから以下をインストールします。
- s3fs
- sagemaker
- botocore
AWSの設定
以下の手順に従ってSageMakerにアクセスするためのロールを作成します。
機械学習モデルをSageMakerにデプロイするのためのAWS認証設定のセットアップ - Qiita
モデルがアクセスするデータが格納されているS3にアクセスするためのインラインポリシーを追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<S3バケット名>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::<S3バケット名>/*"
]
}
]
}
以下の手順に従って、上記SageMaker用ロールのインスタンスプロファイルARNを用いてDatabricksでインスタンスプロファイルを作成します。
Databricksにおけるインスタンスプロファイルを用いたS3バケットへのセキュアなアクセス - Qiita
Databricksのデプロイに使用したロールに以下のポリシーを追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"iam:PassRole"
],
"Resource": [
"arn:aws:iam::<AWSアカウントID>:role/<上で作成したSageMaker用ロール>"
],
"Effect": "Allow"
}
]
}
モデルのトレーニング & ロギング
トレーニング、テストデータセットの準備
databrikcs-datasetsのワインデータを用いてトレーニングデータを準備します。
import pandas as pd
white_wine = pd.read_csv("/dbfs/databricks-datasets/wine-quality/winequality-white.csv", sep=";")
red_wine = pd.read_csv("/dbfs/databricks-datasets/wine-quality/winequality-red.csv", sep=";")
red_wine['is_red'] = 1
white_wine['is_red'] = 0
data = pd.concat([red_wine, white_wine], axis=0)
# カラム名から空白を削除
data.rename(columns=lambda x: x.replace(' ', '_'), inplace=True)
# qualityを2値に変換します
high_quality = (data.quality >= 7).astype(int)
data.quality = high_quality
display(data)
# トレーニング、テストデータセットに分割します
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, random_state=123)
X_train = train.drop(["quality"], axis=1)
X_test = test.drop(["quality"], axis=1)
y_train = train.quality
y_test = test.quality
PyFuncカスタムモデルの定義
import mlflow
import mlflow.pyfunc
import mlflow.sklearn
import numpy as np
import sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
from mlflow.models.signature import infer_signature
from mlflow.utils.environment import _mlflow_conda_env
import cloudpickle
import time
# カスタムモデルに必要なライブラリ
import boto3
import fsspec
import s3fs
# PyFuncのカスタムモデルとして定義
class SklearnModelWrapper(mlflow.pyfunc.PythonModel):
"""
sklearnのモデルをトレーニング、使用するクラス
"""
def __init__(self, model):
self.model = model
def predict(self, context, model_input):
"""これは抽象化関数です。sklearnモデルを取り出すためにメソッドをカスタマイズします。
Args:
context ([type]): モデルのアーティファクトが格納されるMLflowコンテキスト
model_input ([type]): データを検索するキー
Returns:
[type]: ロードされたモデルアーティファクト
"""
import csv
import pandas as pd
import boto3
import s3fs
# S3バケット名
bucket_name = '<前処理で読み込むデータを格納しているS3バケット>'
# ファイルパス
savepath = 'wine_quality_w_id.csv'
# S3からのデータ取得
# 本処理を実行するクラスターにS3にアクセス可能なインスタンスプロファイルをアタッチすること
s3_client = boto3.client('s3')
response = s3_client.get_object(Bucket=bucket_name, Key=savepath)
file = response["Body"]
df = pd.read_csv(file, header=0, delimiter=",", low_memory=False)
#print(df)
# SageMakerエンドポイント経由の場合、引数はDataFrameとして渡されるのでDataFrameから値を取り出す
if isinstance(model_input, pd.DataFrame):
row_id = int(model_input['data'].iloc[0])
else:
row_id = int(model_input)
print("model_input:", model_input)
target_data = df.drop("quality", axis=1)
target_data = target_data[target_data['lot_id'] == row_id].drop("lot_id", axis=1)
print("target_data:", target_data)
return self.model.predict_proba(target_data)[:,1]
モデルのトレーニング
シグネチャの実装はTODOです。
# mlflow.start_runは、このモデルのパフォーマンスを追跡するための新規MLflowランを生成します。
# コンテキスト内で、使用されたパラメーターを追跡するためにmlflow.log_param、精度のようなメトリクスを追跡するために
# mlflow.log_metricを呼び出します。
with mlflow.start_run(run_name='untuned_random_forest') as run:
n_estimators = 10
model = RandomForestClassifier(n_estimators=n_estimators, random_state=np.random.RandomState(123))
model.fit(X_train, y_train)
# predict_probaは[prob_negative, prob_positive]を返却するので、出力を[:, 1]でスライスします。
predictions_test = model.predict_proba(X_test)[:,1]
auc_score = roc_auc_score(y_test, predictions_test)
mlflow.log_param('n_estimators', n_estimators)
# メトリックとしてROC曲線のAUCを使用します。
mlflow.log_metric('auc', auc_score)
wrappedModel = SklearnModelWrapper(model)
# モデルの入出力スキーマを定義するシグネチャをモデルとともに記録します。
# モデルがデプロイされた際に、入力を検証するためにシグネチャが用いられます。
# TODO:シグネチャの定義
#signature = infer_signature(np.array([0]), wrappedModel.predict(None, np.array([0])))
#signature = infer_signature(0, wrappedModel.predict(None, 0))
#print(signature)
# MLflowにはモデルをサービングする際に用いられるconda環境を作成するユーティリティが含まれています。
# 必要な依存関係がconda.yamlに保存され、モデルとともに記録されます。
conda_env = _mlflow_conda_env(
additional_conda_deps=None,
additional_pip_deps=["cloudpickle=={}".format(cloudpickle.__version__),
"scikit-learn=={}".format(sklearn.__version__),
"boto3==1.20.1",
"fsspec=={}".format(fsspec.__version__),
"s3fs=={}".format(s3fs.__version__),
"botocore==1.23.24"
],
additional_conda_channels=None,
)
#mlflow.pyfunc.log_model("random_forest_model", python_model=wrappedModel, conda_env=conda_env, signature=signature)
mlflow.pyfunc.log_model("random_forest_model", python_model=wrappedModel, conda_env=conda_env)
モデルの動作確認
# ラン(トレーニング)のIDを取得
previous_run_id = run.info.run_id
# トラッキングされたモデルのロード
loaded_model = mlflow.pyfunc.load_model(f"runs:/{previous_run_id}/random_forest_model")
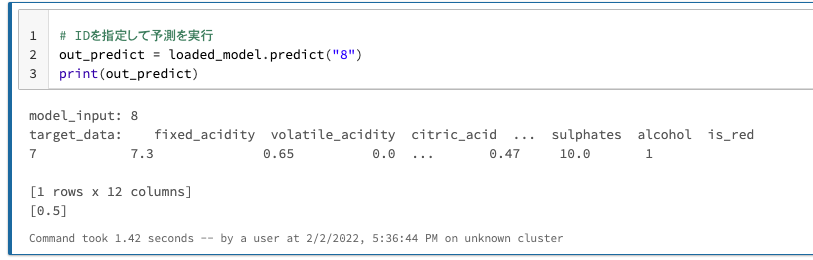
# IDを指定して予測を実行
out_predict = loaded_model.predict("8")
print(out_predict)
カスタムモデルのサービング
MLflowで記録されたモデルをSageMakerのエンドポイントにデプロイします。
モデルのデプロイ
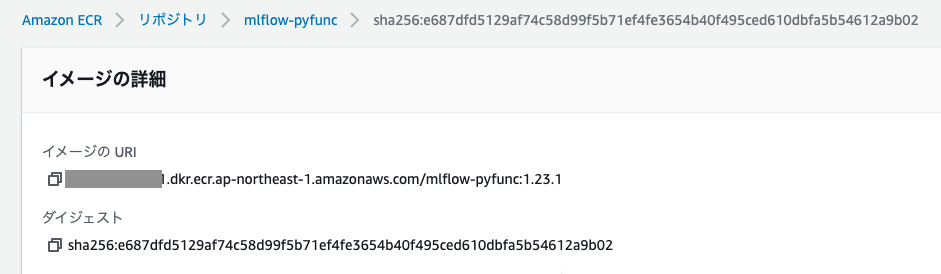
SageMakerエンドポイントにモデルをデプロイする際には、AmazonのElastic Container Registry (ECR)のDockerイメージを指定します。SageMakerはモデルをサービングする際にこのイメージを使用します。
ローカルマシンでMLflow CLI:mlflow sagemaker build-and-push-containerを実行し、mlflow-pyfuncイメージをビルドし、イメージをECRのリポジトリにアップロードします。ECRリポジトリにmlflow-pyfuncイメージが作成されます。アップロード完了後、DockerイメージのURLを取得することができます。
上記CLIコマンドを実行する前に以下の設定を行なっていることを確認してください。
- ローカルマシンでAWS CLIのインストール、設定を行います。
- ローカルマシンでPyPIを使って
mlflow、boto3をインストールしておきます。
region = "ap-northeast-1"
run_id1 = previous_run_id
model_uri = "runs:/" + run_id1 + "/random_forest_model"
# 以下のECR Dockerイメージに対するURLを<ECR-URL>で置き換えてください。
# ECR URLは以下のフォーマットである必要があります: {account_id}.dkr.ecr.{region}.amazonaws.com/{repo_name}:{tag}
image_ecr_url = "<AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/mlflow-pyfunc:1.23.1"
import mlflow.sagemaker as mfs
app_name = "wine-quality" # SageMakerエンドポイント名
以下のAPIを用いてSageMakerエンドポイントにモデルをデプロイします。
# 4-5分かかります
mfs.deploy(app_name=app_name, model_uri=model_uri, image_url=image_ecr_url, region_name=region, mode="replace") # mode create/replace
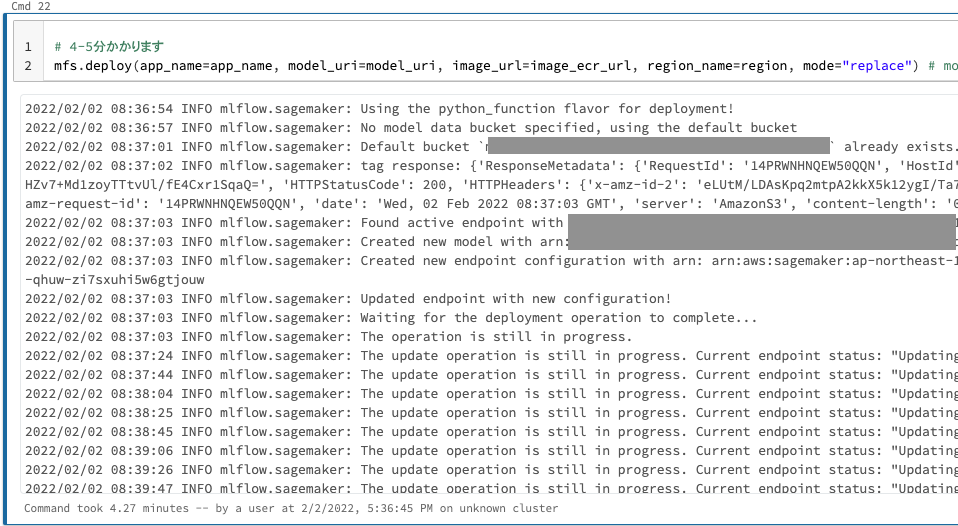
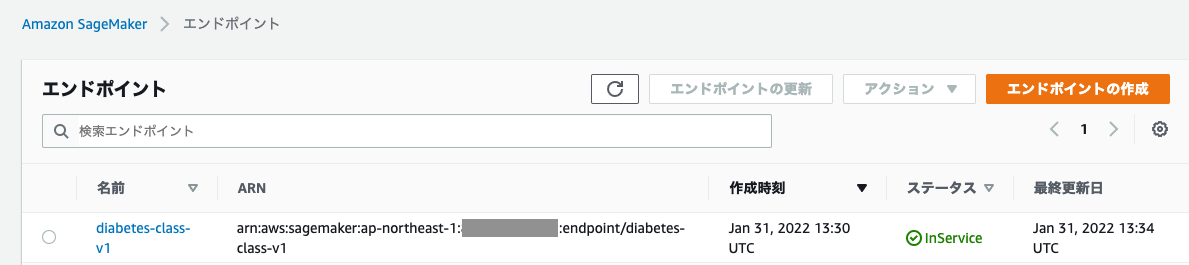
以下のセルを実行することで新規SageMakerエンドポイントのステータスを確認することができます。
注意: アプリケーションのステータスはCreatingであるべきです。ステータスがInServiceになるまで待ってください。それまではクエリーのリクエストは失敗します。
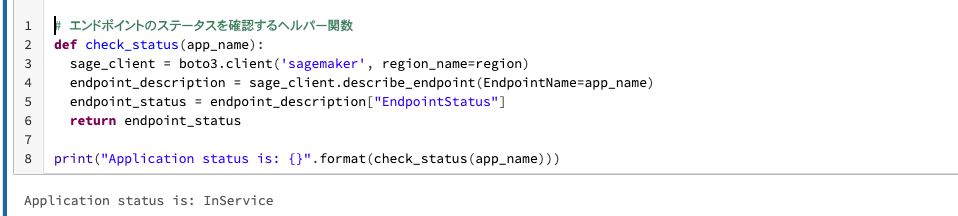
# エンドポイントのステータスを確認するヘルパー関数
def check_status(app_name):
sage_client = boto3.client('sagemaker', region_name=region)
endpoint_description = sage_client.describe_endpoint(EndpointName=app_name)
endpoint_status = endpoint_description["EndpointStatus"]
return endpoint_status
print("Application status is: {}".format(check_status(app_name)))
エンドポイントからモデルの呼び出し
HTTPリクエストを送信してサンプルインプットを評価します。
boto3で提供されるsagemaker-runtime APIを用いてSageMakerエンドポイントREST APIにクエリーを実行します。
import json
import numpy as np
# パラメータ指定
data = [{"data": "8"}] # 推論に用いるデータのIDを指定します
input_json = json.dumps(data)
print(input_json)
def query_endpoint(app_name, input_json):
client = boto3.session.Session().client("sagemaker-runtime", region)
response = client.invoke_endpoint(
EndpointName=app_name,
Body=input_json,
ContentType='application/json',
)
preds = response['Body'].read().decode("ascii")
preds = json.loads(preds)
print("Received response: {}".format(preds))
return preds
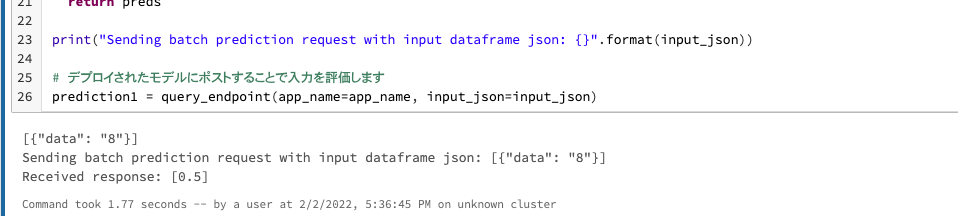
print("Sending batch prediction request with input dataframe json: {}".format(input_json))
# デプロイされたモデルにポストすることで入力を評価します
prediction1 = query_endpoint(app_name=app_name, input_json=input_json)
サンプルノートブック
ノートブックで参照しているCSVファイルも格納されています。
参考資料
- 機械学習モデルをSageMakerにデプロイするのためのAWS認証設定のセットアップ - Qiita
- SageMakerへのscikit-learnモデルのデプロイメント - Qiita
- Databricksにおけるインスタンスプロファイルを用いたS3バケットへのセキュアなアクセス - Qiita
- Preprocess input data before making predictions using Amazon SageMaker inference pipelines and Scikit-learn | AWS Machine Learning Blog