Accelerate Feature Engineering With Photon | Databricks Blogの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Databricks機械学習ランタイムクラスターでPhotonが利用できるように
高品質な機械学習モデルのトレーニングには、注意深いデータと特徴量の準備が必要となります。Databricksでテーブルとして保存されている生データを完全に活用するために、生データを有用な特徴量テーブルに変換するためのETLパイプラインや特徴量エンジニアリングの実行が必要となることがあります。お使いのテーブルが大規模な場合、このステップは非常に長い時間を必要とするものとなります。Sparkジョブや特徴量エンジニアリングのワークロードを2倍以上高速にできるPhotonエンジンを、Databricks機械学習ランタイムで有効化できるようになったことを発表できることに興奮しています。

「Photonを有効化し、新たなPIT(Point In Time)joinを用いることで、Feature Storeを用いてトレーニングデータセットを生成するのに必要とする時間は20倍以上削減されました」- Sem Sinchenko, Advanced Analytics Expert Data Engineer, Raiffeisen Bank International AG
Photonとは?
Photonエンジンは、Spark SQLやSparkデータフレームをより高速に実行し、ワークロードごとの合計コストを削減する高性能なクエリーエンジンです。内部では、PhotonはC++で実装されており、特定のSpark実行ユニットは、Photonのネイティブなエンジン実装で置き換えられます。
Photonはどのように機械学習ワークロードで役立つのか?
Databricks機械学習ランタイムでPhotonを有効化できるようになりましたが、機械学習の開発ワークフローにいつPhoton有効化クラスターを取り込むのが合理的なのでしょうか?いくつかの検討事項を以下に示します:
- より高速なETL: Photonはデータ準備におけるSpark SQLやSparkデータフレームのワークロードを高速にします。Photonの早くからの利用者は、彼らのSQLクエリーが平均2倍から4倍高速になったことを観測しています。
- より高速な特徴量エンジニアリング: 時系列特徴量テーブルに対してDatabricksのFeature Engineering Python APIを用いる際、Photonを有効化することでpoint-in-time joinがより高速になります。
Photonによる特徴量エンジニアリングの高速化
DatabricksのFeature Engineeringライブラリでは、時系列データに対するpoint-in-time joinの新バージョンを実装しました。Databricksの顧客であるRaiffeisen Bank InternationalのSemyon Sinchenkoにインスパイアされた新たな実装では、TempoライブラリではなくネイティブSparkを用いており、以前のバージョンよりもよりスケーラブルでロバストになっています。さらに、ネイティブなSpark実装によって、Photonエンジンのメリットを非常位に享受しています。テーブルが大きいほど、Photonによる改善の度合いが大きくなります。
- 10M行の特徴量テーブル(10kのユニークID、IDごとの1000のタイムスタンプ)とラベルテーブル(100kのユニークID、IDごとの100のタイムスタンプ)をjoinする際、Photonはpoint-in-time joinを2倍高速にします。
- 100M行の特徴量テーブル(100kのユニークID)をjoinする際、Photonはpoint-in-time joinを2.1倍高速にします。
- 1B行の特徴量テーブル(1MのユニークID)をjoinする際、Photonはpoint-in-time joinを2.4倍高速にします。

上の図では、同じラベルテーブルに対して3つのサイズの異なる特徴量テーブルをjoinする際の実行時間を比較しています。それぞれの実験は1ワーカーノード、r6id.xlargeインスタンスタンプのDatabricks AWSクラスターで実行されました。平均実行時間を計算するために5回繰り返しました。
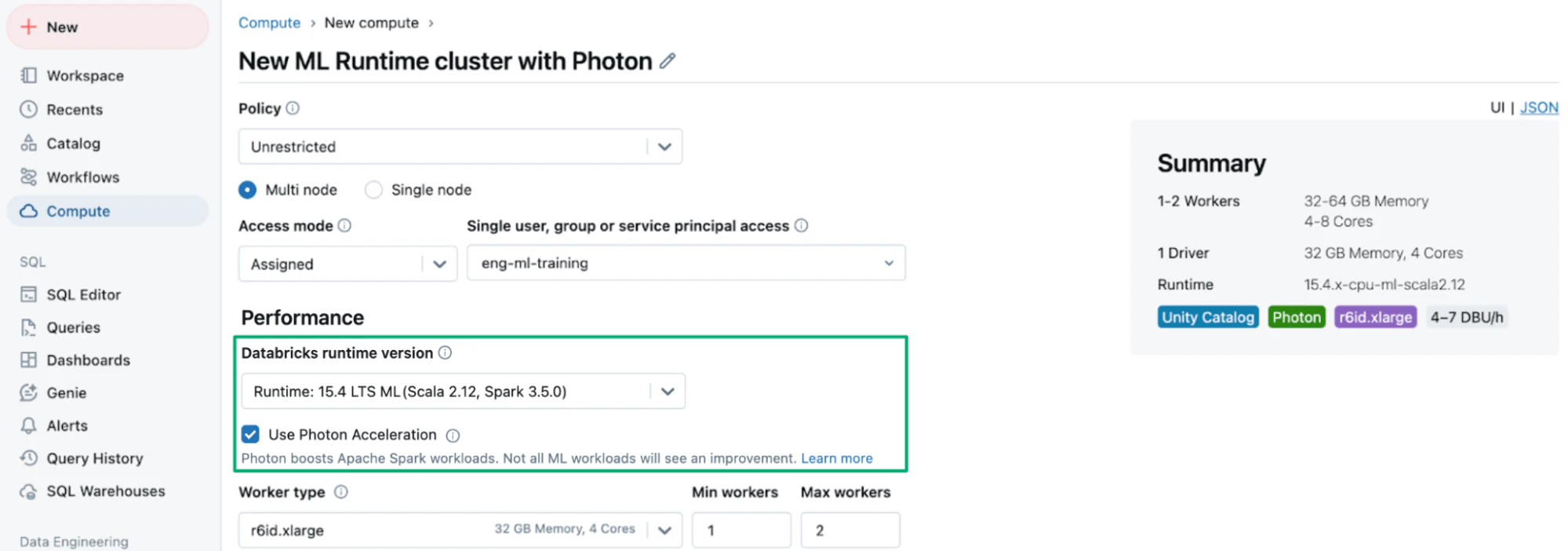
Databricks機械学習ランタイムクラスターでPhotonを選択
Photonのクエリーパフォーマンスと、Databricks MLランタイムの構築済みのAIインフラストラクチャによって、機械学習モデルの開発がより高速、より簡単になります。Databricks機械学習ランタイム15.2以降では、“Use Photon Acceleration”を選択することで、Photonが有効化されたMLランタイムクラスターを作成することができます。また、MLランタイム15.3 LTS以降では、ネイティブSparkバージョンのpoint-in-time joinが提供されます。
PhotonやDatabricksにおける特徴量エンジニアリングの詳細に関しては、以下のドキュメントページをご覧ください。