Sparkでは、グラフ構造を容易に取り扱うことができるGraphFramesという機能を利用できます。こちらのソリューションアクセラレータでもBoM(部品表)をデータ分析で活用しています。
2年前にこちらの記事を書いた際には、Scalaのサンプルしかなかったのですが、Pythonのサンプルができていました。嬉しいので、翻訳しつつウォークスルーします。
サンプルノートブックはこちらにあります。
翻訳版はこちら。
GraphFramesユーザーガイド (Python)
このノートブックでは、GraphFrames User Guideの例をデモンストレーションします。
要件
このノートブックでは、機械学習ランタイムが必要となります。
from functools import reduce
from pyspark.sql import functions as F
from graphframes import GraphFrame
グラフを可視化した方がわかりやすいので、以下を参考にさせていただきました。
python - PYSPARK: how to visualize a GraphFrame? - Stack Overflow
import networkx as nx
import matplotlib.pyplot as plt
def PlotGraph(edge_list):
Gplot = nx.Graph()
for row in edge_list.select("src", "dst").take(1000):
Gplot.add_edge(row["src"], row["dst"])
plt.subplot(121)
nx.draw(Gplot, with_labels=True, font_weight="bold")
GraphFramesの作成
ユーザーは頂点(vertex)とエッジ(edge)のデータフレームからGraphFramesを作成できます。
- Vertexデータフレーム: Vertexデータフレームには、グラフにおけるそれぞれの頂点に対するユニークなIDを示す"id"という名前の特殊なカラムを含める必要があります。
- Edgeデータフレーム: Edgeデータフレームには、2つの特殊なカラムが必要です: "src" (エッジのソースとなる頂点のID) と "dst" (エッジのディスティネーションとなる頂点のID)です。
両方のデータフレームには、任意のその他のカラムを含めることができます。これらのカラムでは、頂点やエッジの属性を表現することができます。
はじめに頂点を作成します:
vertices = spark.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
("d", "David", 29),
("e", "Esther", 32),
("f", "Fanny", 36),
("g", "Gabby", 60)],
["id", "name", "age"])
次に幾つかのエッジを作成します:
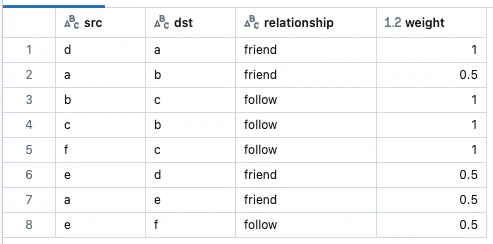
edges = spark.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
("f", "c", "follow"),
("e", "f", "follow"),
("e", "d", "friend"),
("d", "a", "friend"),
("a", "e", "friend")],
["src", "dst", "relationship"])
これらの頂点とエッジからグラフを作成します:
g = GraphFrame(vertices, edges)
print(g)
GraphFrame(v:[id: string, name: string ... 1 more field], e:[src: string, dst: string ... 1 more field])
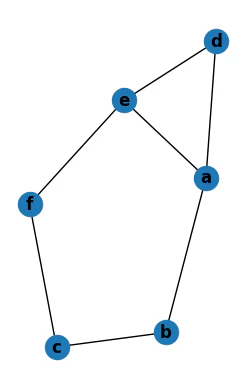
可視化します。以降はこちらを見ながらコードを実行するとわかりやすいかと思います。
PlotGraph(g.edges)
# このサンプルnのグラフはGraphFramesパッケージでも提供されています。
from graphframes.examples import Graphs
same_g = Graphs(spark).friends()
print(same_g)
基本的なグラフとデータフレームのクエリー
GraphFramesでは、ノードの度数のようないくつかのシンプルなグラフクエリーを提供します。
また、GraphFramesはグラフを頂点とエッジデータフレームのペアとして表現するので、頂点とエッジのデータフレームに対して直接パワフルなクエリーを容易に実行することができます。これらのデータフレームは、GraphFrameのverticesやedgesフィールドから利用できます。
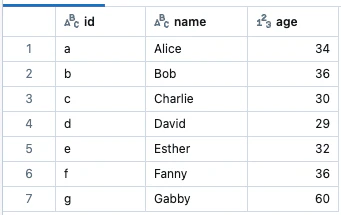
display(g.vertices)
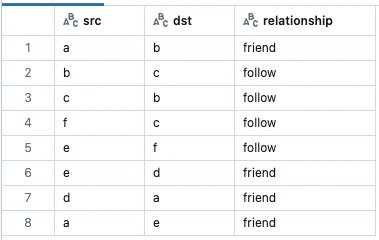
display(g.edges)
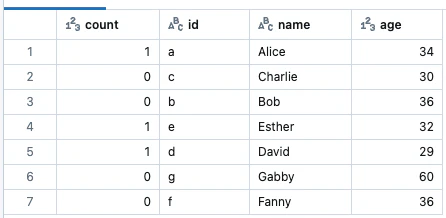
頂点の内向きの度数:
display(g.inDegrees)

頂点の外向きの度数:
display(g.outDegrees)

頂点の度数:
display(g.degrees)
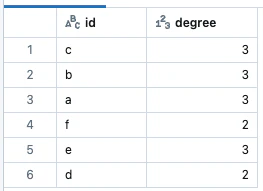
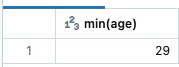
verticesデータフレームに直接クエリーを実行できます。例えば、グラフにおいて最も若い人物の年齢を特定できます:
youngest = g.vertices.groupBy().min("age")
display(youngest)
また、edgesデータフレームにクエリーを行うことができます。例えば、グラフにおける follow リレーションシップの数をカウントします:
numFollows = g.edges.filter("relationship = 'follow'").count()
print("The number of follow edges is", numFollows)
The number of follow edges is 4
モチーフの特定
モチーフを用いることで、エッジと頂点を含むより複雑なリレーションシップを構築できます。以下のセルでは、両方向で接続されている頂点とエッジのペアを特定しています。結果は、モチーフのキーによって指定されるカラム名を持つデータフレームとなります。
APIの詳細に関しては、GraphFrame User Guideをご覧ください。
# 両方向で接続されている頂点とエッジのペアを検索します。
motifs = g.find("(a)-[e]->(b); (b)-[e2]->(a)")
display(motifs)

結果はデータフレームとなるので、モチーフをベースにしてより複雑なクエリーを構築することができます。以下のセルでは、どちらかが30歳を上回っているすべての相互リレーションシップを検索します:
filtered = motifs.filter("b.age > 30 or a.age > 30")
display(filtered)

ステートフルなクエリー
上の例のように、ほとんどのモチーフクエリーはステートレスで表現が容易です。次の例では、モチーフのパスを通じて状態を運ぶより複雑なクエリーをデモンストレーションします。このようなクエリーは、GraphFrameモチーフの検索と、検索結果のデータフレームのカラムに対して適用される後続のオペレーションのフィルターを組み合わせることで表現できます。
例えば、一連の関数によって定義されるいくつかのプロパティを持つ、4つの頂点のチェーンを特定したいものとします。すなわち、4つの頂点のチェーンa->b->c->dにおいて、このような複雑なフィルターにマッチするチェーンのサブセットを特定します:
- パスの状態の初期化
- 頂点aに基づいて状態を更新
- 頂点bに基づいて状態を更新
- cやdも同様
最終的な状態が何かしらの条件に合致したら、フィルターはチェーンを受け入れます。
以下のコードスニペットではこのプロセスを説明しています。このコードでは、3つのエッジのうち少なくとも2つが"friend"リレーションシップである、4つの頂点のチェーンを特定します。この例では、状態は現時点での"friend"エッジのカウントとなります。通常、これはデータフレームのカラムとなります。
# 4つの頂点を持つチェーンを特定します。
chain4 = g.find("(a)-[ab]->(b); (b)-[bc]->(c); (c)-[cd]->(d)")
# 状態(cnt)とともにシーケンスをクエリー
# (a) モチーフの次の要素に基づいて状態を更新するメソッドを定義します。
def cumFriends(cnt, edge):
relationship = F.col(edge)["relationship"]
return F.when(relationship == "friend", cnt + 1).otherwise(cnt)
# (b) モチーフの要素のシーケンスに対してメソッドを適用するためにシーケンスオペレーションを活用します。
# この場合、要素は3つのエッジとなります。
edges = ["ab", "bc", "cd"]
numFriends = reduce(cumFriends, edges, F.lit(0))
chainWith2Friends2 = chain4.withColumn("num_friends", numFriends).where(numFriends >= 2)
display(chainWith2Friends2)

サブグラフ
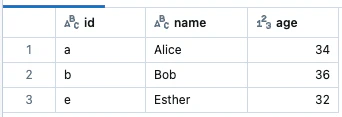
GraphFramesはエッジや頂点に基づいたフィルタリングによってサブグラフを構築するAPIを提供します。これらのフィルターは、以下のような30歳を超える人、かつ、友達も30歳を超えている人のみを含むサブグラフのように、組み合わせることが可能です。
g2 = g.filterEdges("relationship = 'friend'").filterVertices("age > 30").dropIsolatedVertices()
display(g2.vertices)
display(g2.edges)

標準的なグラフアルゴリズム
GraphFramesでは、数多くの標準的なグラフアルゴリズムがビルトインされています:
- Breadth-first search (BFS)
- Connected components
- Strongly connected components
- Label Propagation Algorithm (LPA)
- PageRank (regular and personalized)
- Shortest paths
- Triangle count
Breadth-first search (BFS)
age < 32のユーザーから"Esther"を検索します。
paths = g.bfs("name = 'Esther'", "age < 32")
display(paths)

エッジのフィルターや最大パス長で検索を制限することもできます。
filteredPaths = g.bfs(
fromExpr = "name = 'Esther'",
toExpr = "age < 32",
edgeFilter = "relationship != 'friend'",
maxPathLength = 3)
display(filteredPaths)

接続されたコンポーネント(Connected components)
それぞれの頂点で接続されたコンポーネントのメンバーシップを計算し、コンポーネントIDが割り当てられたそれぞれの頂点を持つデータフレームを返却します。GraphFramesのConnected componentsの実装では、パフォーマンスを改善するためにチェックポイントを活用することができます。
sc.setCheckpointDir("/tmp/graphframes-example-connected-components")
result = g.connectedComponents()
display(result)
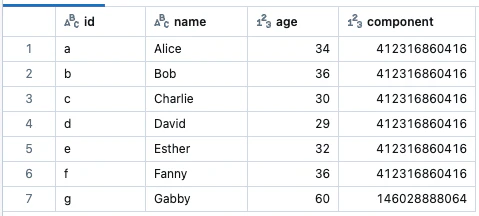
強く接続されたコンポーネント(Strongly connected component)
それぞれの頂点のstrongly connected component (SCC)を計算し、当該の頂点を含むSCCに割り当てられたそれぞれの頂点を持つデータフレームを返却します。
result = g.stronglyConnectedComponents(maxIter=10)
display(result.select("id", "component"))
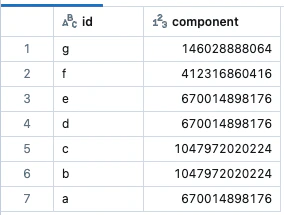
ラベルの伝播
ネットワークにおけるコミュニティを検知するために、静的なラベル伝播アルゴリズムを実行します。
ネットワークにおけるそれぞれのノードは、最初に自身のコミュニティに割り当てられます。すべてのスーパーステップにおいて、ノードは全ての隣人にコミュニティへの協力関係を依頼し、到着するメッセージから最も高頻度なコミュニティの協力依頼に自身の状態を更新します。
LPAは、グラフにおける標準的なコミュニティ検知アルゴリズムです。これは、以下の点に考慮する必要がありますが、計算量的には安価なものとなっています。
- 収束が保証されません
- つまらない回答になる場合があります(全てのノードが単独なコミュニティとして識別される)
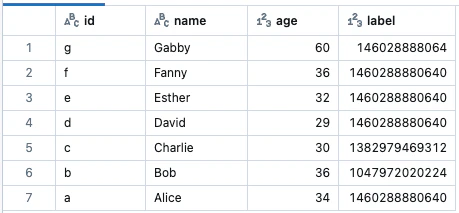
result = g.labelPropagation(maxIter=5)
display(result)
PageRank
接続性に基づいてグラフにおいて重要な頂点を特定します。
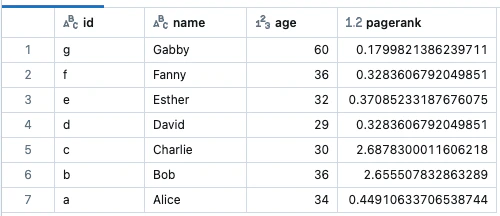
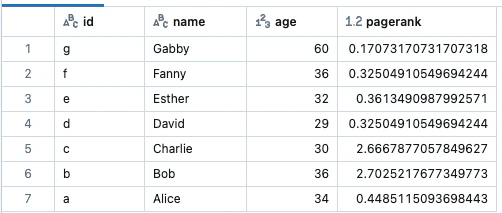
results = g.pageRank(resetProbability=0.15, tol=0.01)
display(results.vertices)
display(results.edges)
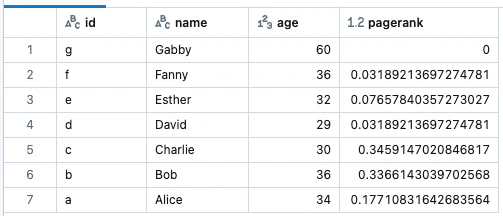
# 固定回数のイテレーションでPageRankを実行します。
results = g.pageRank(resetProbability=0.15, maxIter=10)
display(results.vertices)
# 頂点"a"にパーソナライズしたPageRankの実行
results = g.pageRank(resetProbability=0.15, maxIter=10, sourceId="a")
display(results.vertices)
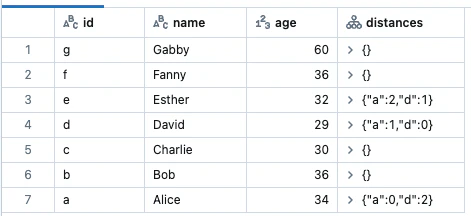
最短パス
頂点IDで指定されるランドマークの頂点のセットへの最短パスを計算します。
results = g.shortestPaths(landmarks=["a", "d"])
display(results)
三角形のカウント
それぞれの頂点を通過する三角形の数を計算します。
results = g.triangleCount()
display(results)