はじめに
AIエージェントの話題が盛り上がる中で、「自律型エージェント」ばかりが注目されがちです。Computer Use、Claude Code、Cursor Agent... 確かに派手で目を引きます。
しかし、Anthropicが2024年12月に公開した Building effective agents を読むと、彼らが繰り返し強調しているのは別のメッセージです。
Consistently, the most successful implementations weren't using complex frameworks or specialized libraries. Instead, they were building with simple, composable patterns.
「成功している実装の多くは、複雑なフレームワークではなくシンプルで合成可能なパターンを使っている」と。その「パターン」の中心にあるのが、ワークフロー型 です。
この記事では、
- Anthropicの整理に沿ったワークフロー型と自律型の違い
- ワークフロー型を選ぶべき場面
- Databricks Free Editionで動くサンプルノートブック (Anthropic Cookbookの移植版)
- MLflow Tracingでワークフロー構造をGraphビュー可視化する勘所
を扱います。サンプルノートブックは GitHubリポジトリ に上げています。
Anthropicによるワークフローとエージェントの定義
Anthropicは「エージェント的システム (agentic systems)」を、まずアーキテクチャの観点で2つに分けています。
Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
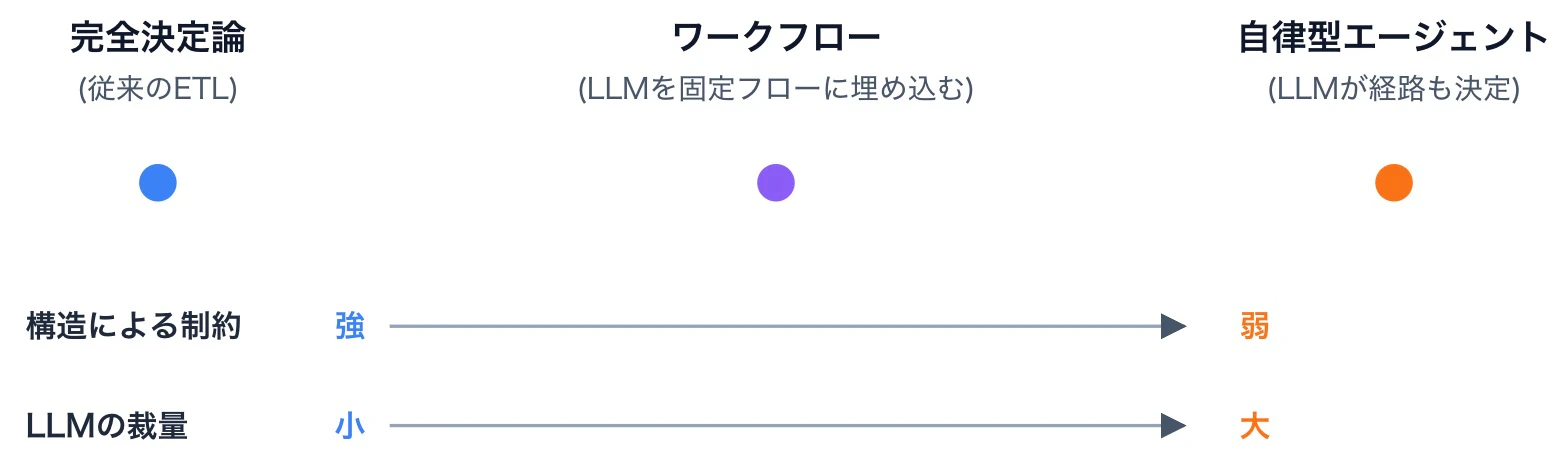
要点は「経路を誰が決めるか」です。
- ワークフロー型: 開発者がコードでフローを規定する。各ステップの中身はLLMなので非決定論的だが、経路は固定。
- 自律型: LLM自身が経路 (どのツールを呼ぶか、いつ終わるか) を実行時に決める。
ここで誤解しやすいのは、「ワークフロー」という言葉が従来のETLやAirflowのジョブ定義のような完全決定論的なものを連想させる点です。Anthropicの言うワークフローは違います。構造は決定論的だが、各ステップの中身はLLMなので非決定論的 という、ハイブリッドな位置付けです。
スペクトラムで描くとこんな感じです。
ワークフロー型を選ぶべき理由
実務でAI機能を組むなら、まずワークフロー型から検討するのが筋が良いです。理由は4つあります。
1. 予測可能性とデバッグ容易性
自律型は「なぜこのツールを呼んだのか」「なぜこの順序で動いたのか」が実行ごとに変わります。本番運用では、
- 同じ入力に対して挙動がブレる
- 失敗時の原因特定が難しい
- リグレッションテストが書きづらい
という問題に直面します。ワークフローならフローが固定なので、各ステップ単位で評価・テスト・改善ができます。
2. コストとレイテンシの予測可能性
自律型は「考えてツール呼んで、また考えて...」のループが何ターンも回るので、トークン消費とレイテンシが読めません。ワークフローはLLM呼び出し回数が事前にわかるので、コスト試算もSLO設計もしやすい。
3. 多くの実用タスクは自律性を必要としない
「ドキュメントを要約 → 構造化抽出 → DB登録」みたいな業務タスクは、フローがすでに明確です。ここで自律型を使うのは、決まった道順を歩けばいいのにGPSに毎回ルート計算させるようなもので、過剰設計です。
4. 自律性は失敗のコストを跳ね上げる
エージェントが勝手に判断して動く範囲が広いほど、間違ったときの被害も大きくなります (誤ったメール送信、誤ったDB更新など)。ワークフローは人間が経路を設計しているので、ガードレールを効かせやすい。
Anthropic自身も明確に言っています。
When more complexity is warranted, workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale.
「タスクの形が事前に書けるかどうか」が分岐点です。書けるならワークフロー、書けないなら自律型。
5つの基本ワークフローパターン
Anthropicの整理では、ワークフロー型は以下の5パターンに分類されます。
| パターン | 概要 | 用途例 |
|---|---|---|
| Prompt Chaining | タスクを順序付けたステップに分解 | アウトライン → 本文、抽出 → 整形 → 出力 |
| Routing | 入力を分類して専門ハンドラに振り分け | サポートチケット振り分け、難易度別モデル選択 |
| Parallelization | 独立サブタスクを並列実行 | 多観点評価、複数候補同時生成、ガードレール |
| Orchestrator-Workers | 動的にサブタスクを分解 → 並列実行 → 集約 | 複雑なリサーチ、多ファイル編集 |
| Evaluator-Optimizer | 生成LLMと評価LLMをループ | 文芸翻訳、複雑な検索、品質改善 |
この記事では基本の3つ (Chaining, Parallelization, Routing) をDatabricks上で動かしながら見ていきます。
Databricks Free Editionで動かす
Anthropic Cookbookの該当ノートブック は anthropic SDKを直接使っているので、そのままでは動きません。Databricks Free Edition向けに以下を変更しています。
-
anthropicSDK → Databricks Model Serving (OpenAI互換クライアント) -
ANTHROPIC_API_KEY不要 → Databricksの認証情報を利用 -
util.pyの依存を排除 → ヘルパー関数をノートブック内に直接定義 - ClaudeはFree Editionで使えないので、Free Editionで利用可能なオープンモデルを使用
モデル選定
Free Editionの Serving ページを開くと、利用可能なエンドポイントが確認できます。
このサンプルでは以下を使い分けます。
| 用途 | モデル | 理由 |
|---|---|---|
| デフォルト | databricks-llama-4-maverick |
MoEでバランスが良い |
| 並列worker | databricks-meta-llama-3-1-8b-instruct |
軽量で同時実行のコスト・レイテンシを抑える |
gpt-oss 系の推論モデルは戻り値がリスト形式 (reasoningと最終回答が分離) になるため、シンプルなXMLタグ抽出と相性が悪いです。動作確認用途であればinstruct系で十分です。
サンプルノートブックウォークスルー
リポジトリ: ai_agent_workflow
セットアップ
%pip install -q -U "mlflow>=3.12" openai databricks-sdk
dbutils.library.restartPython()
import contextvars
import re
from concurrent.futures import ThreadPoolExecutor
import mlflow
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
client = w.serving_endpoints.get_open_ai_client()
MODEL = "databricks-llama-4-maverick"
SMALL_MODEL = "databricks-meta-llama-3-1-8b-instruct"
mlflow.openai.autolog()
mlflow.openai.autolog() で、OpenAI互換クライアントを通る全LLM呼び出しが自動的にトレースされます。
ヘルパー関数
@mlflow.trace
def llm_call(prompt: str, system_prompt: str = "", model: str = MODEL) -> str:
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
max_tokens=4096,
messages=messages,
)
return response.choices[0].message.content
def extract_xml(text: str, tag: str) -> str:
match = re.search(f"<{tag}>(.*?)</{tag}>", text, re.DOTALL)
return match.group(1).strip() if match else ""
Pattern 1: Prompt Chaining
タスクを順序付けたステップに分解し、前ステップの出力を次ステップの入力にします。
def chain_step(step_no: int, prompt: str, prev_result: str) -> str:
with mlflow.start_span(name=f"step_{step_no}") as span:
span.set_inputs({"prompt": prompt, "prev_result": prev_result})
result = llm_call(f"{prompt}\n\n入力:\n{prev_result}")
span.set_outputs(result)
return result
@mlflow.trace
def chain(input_text: str, prompts: list[str]) -> str:
result = input_text
for i, prompt in enumerate(prompts, 1):
result = chain_step(i, prompt, result)
return result
例として、レポートテキストから数値を抽出 → 並べ替え → マークダウン表に整形、という3ステップを実行します。
data_processing_steps = [
"以下のテキストから数値とそのコンテキストだけを抽出してください...",
"すべての数値を降順に並び替えてください...",
"並び替えたデータをマークダウンの表に整形してください...",
]
report = """
Q3パフォーマンスサマリー:
顧客満足度は92%に上昇しました。
売上は前期比で45%増加。
新規ユーザー数は2,900%伸長。
解約率は8%まで低下。
"""
final_table = chain(report, data_processing_steps)
MLflow UIのGraphビューで見ると、chain をルートに step_1, step_2, step_3 がsiblings (兄弟) として並ぶ構造が表示されます。
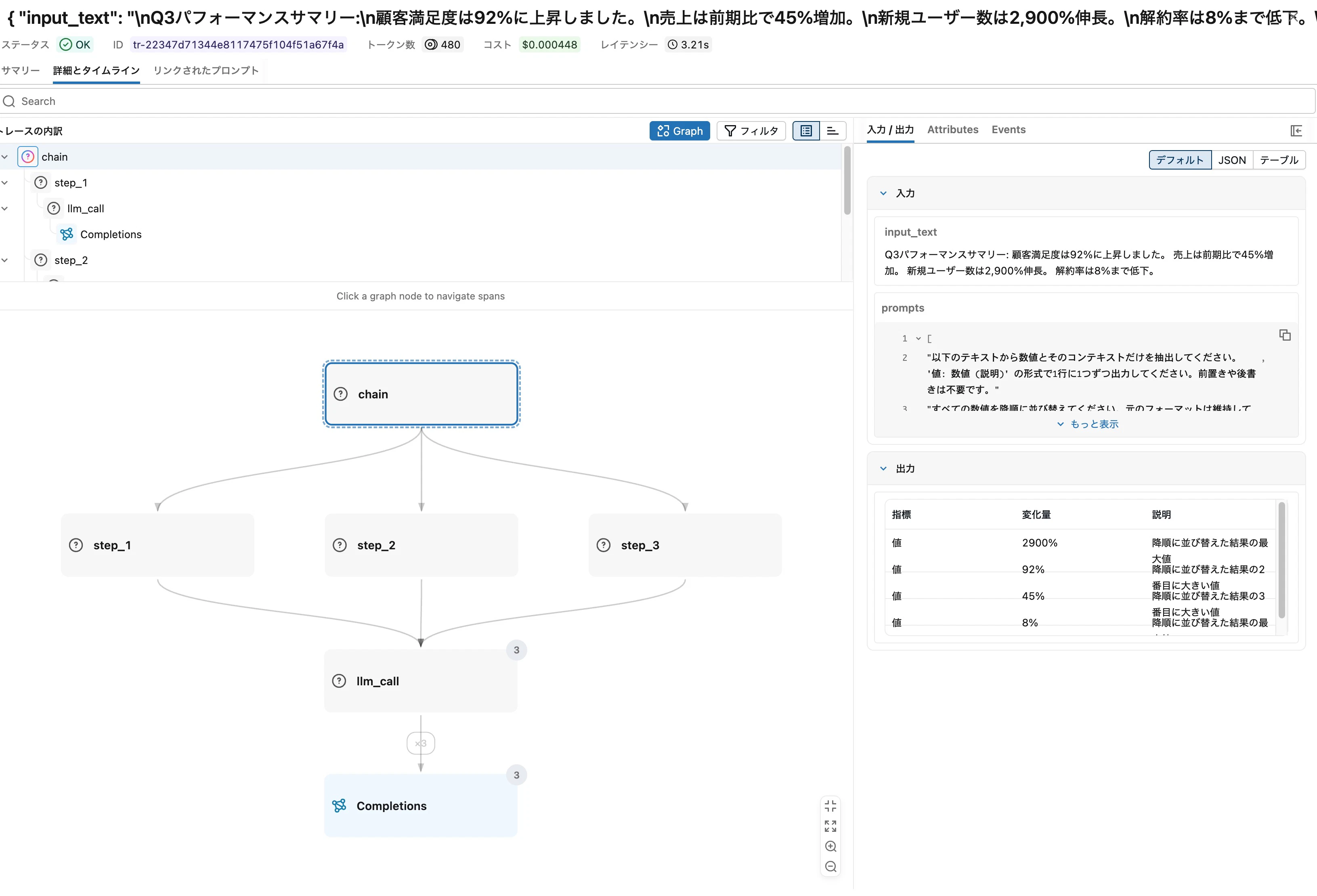
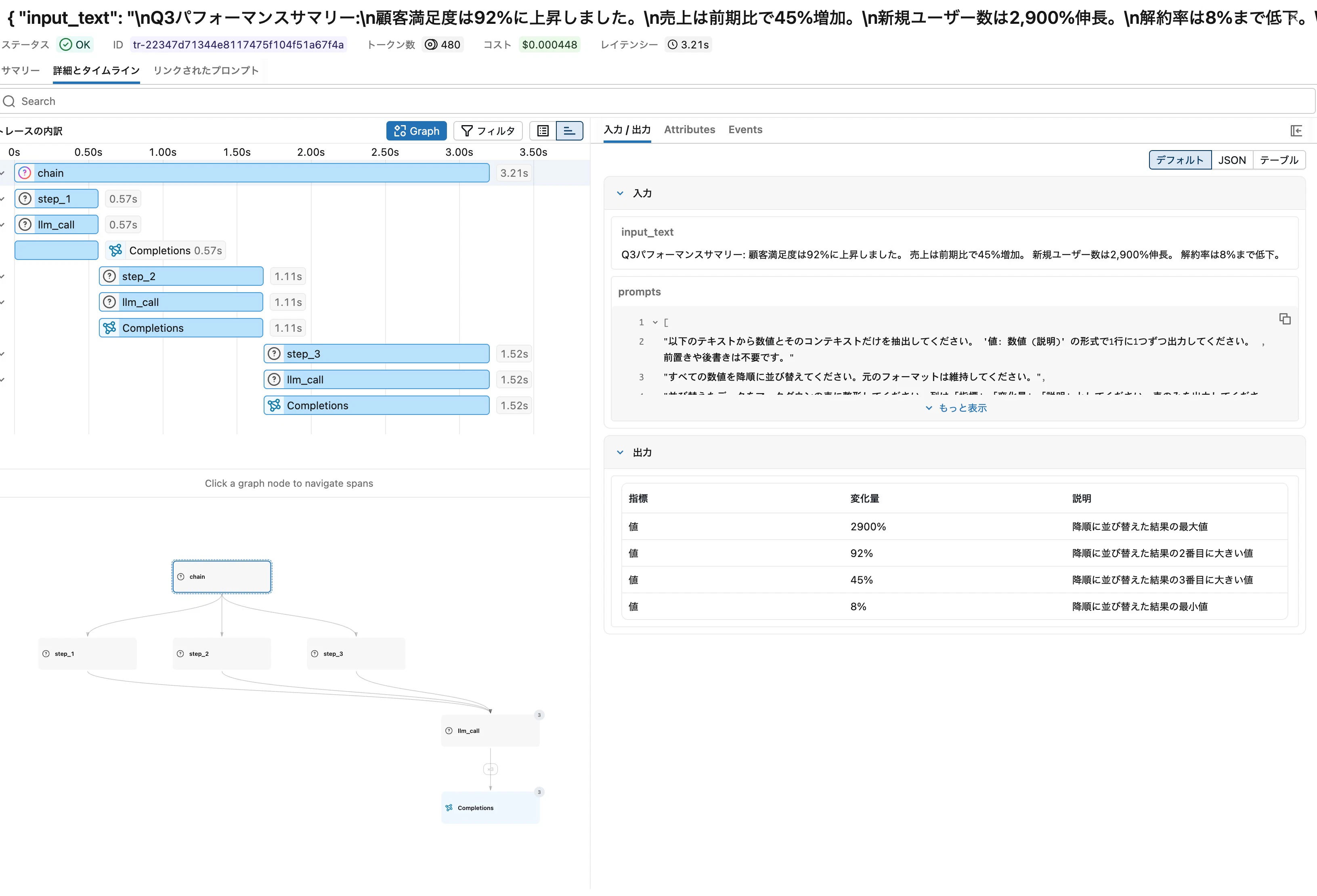
Graphビューは親子関係を表示するもので、実行順序は表現しません。Chainの「前ステップの出力を次ステップが受け取る」という順次実行の様子は、Timelineビューに切り替えると階段状に確認できます。
Pattern 2: Parallelization
独立した複数のサブタスクを並列実行します。注意点はスレッド境界を超えるトレースの伝搬です。
def parallel_worker(prompt: str, input_item: str, model: str, worker_id: int) -> str:
with mlflow.start_span(name=f"worker_{worker_id}") as span:
span.set_inputs({"prompt": prompt, "input": input_item, "model": model})
result = llm_call(f"{prompt}\n\n入力:\n{input_item}", "", model)
span.set_outputs(result)
return result
@mlflow.trace
def parallel(prompt: str, inputs: list[str], n_workers: int = 4, model: str = SMALL_MODEL) -> list[str]:
with ThreadPoolExecutor(max_workers=n_workers) as executor:
futures = []
for i, x in enumerate(inputs):
# 親spanコンテキストをworkerスレッドに伝搬
ctx = contextvars.copy_context()
futures.append(executor.submit(ctx.run, parallel_worker, prompt, x, model, i))
return [f.result() for f in futures]
ステークホルダー4種に対して並列に影響分析を実行する例です。
stakeholders = [
"顧客: 価格に敏感、UX重視、利便性を求める",
"従業員: 雇用の安定、福利厚生、職場環境",
"投資家: ROI、市場ポジション、成長性",
"サプライヤー: 取引の安定性、支払い条件",
]
impact_prompt = "新しいAI製品ローンチがこのステークホルダーに与える影響を、ポジティブ面・ネガティブ面の両方から3点ずつ簡潔に分析してください。"
impact_results = parallel(impact_prompt, stakeholders)
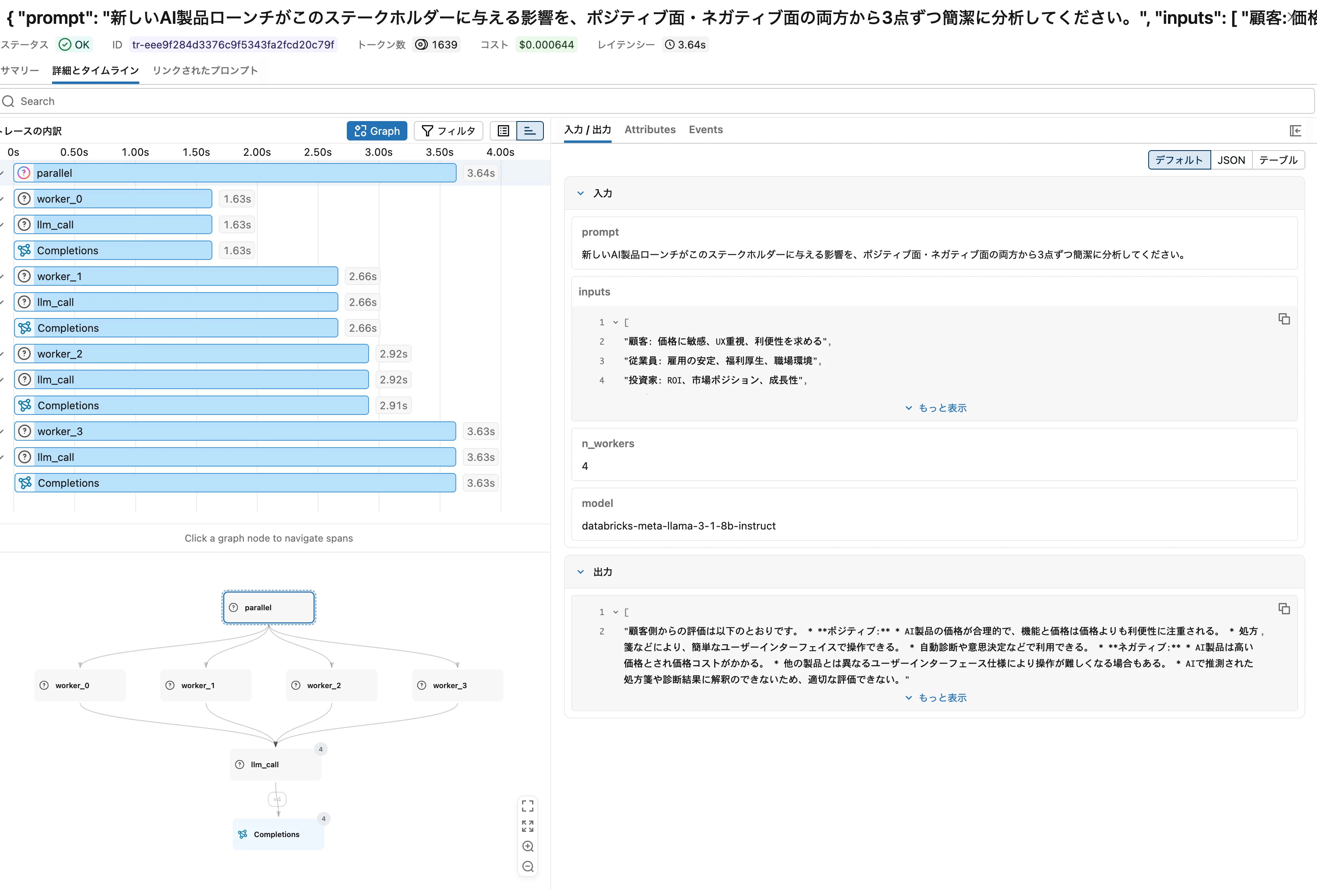
Graphビューでは parallel から worker_0 ~ worker_3 が4本扇状に広がる構造が表示されます。
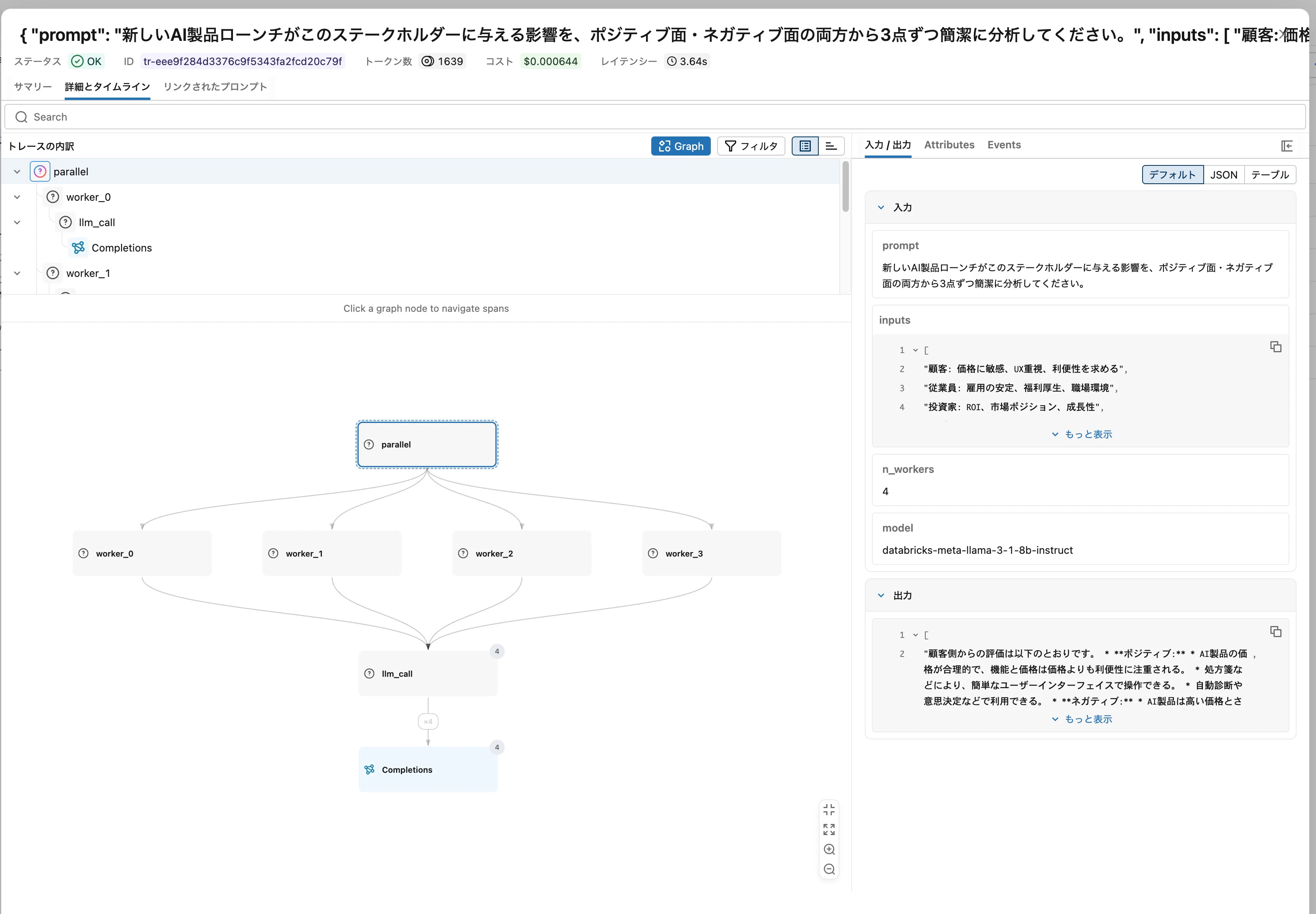
Timelineビューに切り替えると、4つのworkerが同時刻に並走している様子が確認でき、これがParallelizationの本質です。
Pattern 3: Routing
入力をまずLLMで分類し、結果に応じて専門プロンプトに振り分けます。
@mlflow.trace
def classify(input_text: str, routes: dict[str, str], model: str) -> str:
selector_prompt = f"""以下の入力を分析し、最適なルートを選択してください。
ルート候補: {list(routes.keys())}
...
"""
route_response = llm_call(selector_prompt, model=model)
selected_route = extract_xml(route_response, "selection")
# フォールバック処理省略
return selected_route
@mlflow.trace
def handle(selected_route: str, input_text: str, routes: dict[str, str]) -> str:
selected_prompt = routes[selected_route]
return llm_call(f"{selected_prompt}\n\n問い合わせ内容:\n{input_text}")
@mlflow.trace
def route(input_text: str, routes: dict[str, str], classifier_model: str = MODEL) -> str:
selected_route = classify(input_text, routes, classifier_model)
return handle(selected_route, input_text, routes)
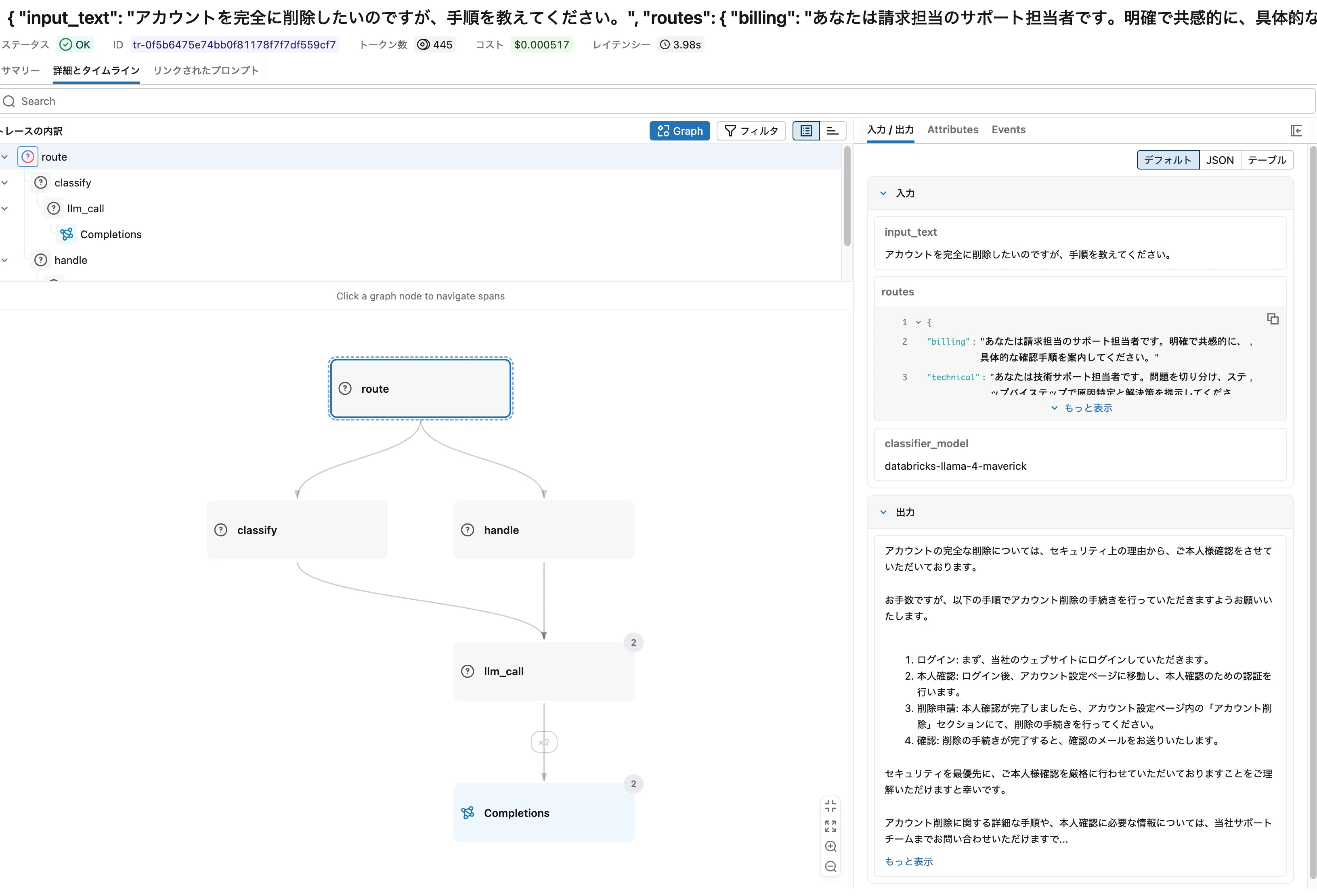
カスタマーサポートのチケット振り分けが典型例です。
support_routes = {
"billing": "あなたは請求担当のサポート担当者です...",
"technical": "あなたは技術サポート担当者です...",
"account": "あなたはアカウント管理担当者です...",
}
Graphビューでは route → classify + handle の2段構造が見えます。
MLflow Tracing活用の勘所
ワークフロー型は「ステップが見えること」が価値です。MLflow Tracingと相性が良く、Graphビューで構造を直感的に把握できます。とはいえ、実装でハマりやすいポイントがいくつかあるのでまとめます。
1. autologだけでは構造が見えない
mlflow.openai.autolog() は単発のOpenAI API呼び出しを拾うだけで、ワークフローの親子関係は記録されません。各ワークフロー関数に @mlflow.trace を付けるか、mlflow.start_span で囲むことで階層構造ができます。
2. @mlflow.trace と start_span の使い分け
| 方法 | 特徴 | 用途 |
|---|---|---|
@mlflow.trace |
関数名がspan名になる | 名前が固定で良い場合 |
mlflow.start_span(name=...) |
span名を動的指定 |
worker_0, worker_1 のように番号を振りたい場合 |
これは見た目以上に重要です。MLflowのGraphビューは、同じ親の下にある同名のsibling spanを ×N と集約表示 します。@mlflow.trace def parallel_worker(...): で4回呼ぶと、Graph上では1ノードに ×4 と表示され、4本並列の構造が見えなくなります。動的命名にすることで4ノードが横並びで描画されます。
3. Graphビューは構造、Timelineビューは時間
MLflowのGraphビューは「親子関係」を表示し、実行順序は表現しません。たとえば Chain と Parallelization は、Graph上ではどちらも「親 → 複数子」の同じ形に見えます。違いはTimelineビューで明確になります。
| ビュー | 見えるもの | 向いているパターン |
|---|---|---|
| Graph | 構造 (親子関係、分岐) | Routing、Orchestrator-Workers |
| Timeline | 時間軸 (順次/並列、レイテンシ) | Chain、Parallelization |
両方を切り替えながら見るのが基本です。
4. ThreadPoolExecutorではcontextvarsを伝搬する
Pythonのcontextvarsはスレッド境界を超えないため、ThreadPoolExecutor.submit で呼ばれたworkerでは親span情報が失われ、各workerが独立したトレースになってしまいます。
MLflow公式FAQ で示されている対処はシンプルです。
# NG: workerが独立トレースになる
executor.submit(parallel_worker, prompt, x, model, i)
# OK: 親コンテキストを伝搬
ctx = contextvars.copy_context()
executor.submit(ctx.run, parallel_worker, prompt, x, model, i)
ctx.run でラップするだけなので、覚えておけば手間ではありません。
5. Graphビュー (MLflow 3.11.1+)
MLflow 3.11.1で追加されたGraphビュー は、ワークフロー型と自律型の構造の違いを示すのに最適です。トレース詳細画面の上部で Graph に切り替えるだけで使えます。
ワークフローの形そのものが視覚化されるので、ハンズオン教材や設計レビューで価値を発揮します。
6. 実用上のTips
- autolog + decorator併用: autologで内側 (LLM呼び出し) を、decoratorで外側 (ワークフロー) を取る、の二層構成が基本
- 入出力が大きいときはset_inputs/set_outputsで明示: 自動キャプチャだと冗長なときに有用
-
トレース検索:
name = 'parallel'のようなSQLライクなフィルタで特定パターンだけ抽出可能
まとめ
- AIエージェント = 自律型ではない。Anthropicの整理ではエージェント的システムには ワークフロー型 と 自律型 がある。
- ワークフロー型は 構造は決定論的、各ステップの中身は非決定論的 というハイブリッド。実用システムの大多数はこちらで十分。
- 「タスクの形が事前に書けるか」が選定基準。書けるならワークフロー、書けないなら自律型。
- MLflow Tracing (3.11.1+) のGraphビューはワークフロー構造の可視化に強力。
@mlflow.traceとstart_spanを使い分け、ThreadPoolExecutor利用時はcontextvars.copy_context()で親コンテキストを伝搬。
派手な自律型エージェントの裏で、堅実な業務システムを支えているのはワークフロー型です。Anthropicが言う通り「シンプルで合成可能なパターン」から始めて、必要な部分だけ自律性を増やしていくのが、現実的なアプローチだと思います。
参考リンク
- Building effective agents | Anthropic
- Anthropic Cookbook: patterns/agents
- MLflow Tracing FAQ
- Databricks Mosaic AI Model Serving のドキュメント
- サンプルノートブックリポジトリ