How to Monitor Your Databricks Lakehouse Platform With Audit Logs - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
お使いのDatabricksレイクハウスプラットフォームにおける重要なイベントに対する完全な可視性の確保
この記事は、Databricksの環境の管理、維持を行う人によって重要なトピックにフォーカスする管理者向け基礎シリーズのパート2です。このシリーズでは、ワークスペース管理、データガバナンス、ops&自動化、コスト追跡&チャージバックなどのトピックにおけるベストプラクティスを共有します。他の記事も楽しみにしてください!
2020年6月に我々が監査ログに関するブログを書いて以来、Databricksのレイクハウスプラットフォームは長い道のりを歩んできました。世界記録を打ち立て、企業を買収し、データアナリスト、シチズンデータサイエンティストのような新たなユーザー全体にレイクハウスアーキテクチャのメリットをもたらす新製品を立ち上げました。世界もまた劇的に変化しました。我々の多くは時間の大部分をリモートで働いており、リモートワークは適切な利用ポリシー、そして、それらが遵守されているのかをどう計測するのかに対するプレッシャーを増加させました。
このような状況を受け、お使いのDatabricksレイクハウスプラットフォームにおける監査ログのトピックを再訪するには良いタインミングだと我々は考えました。この記事では、利用できる最新の機能によるベストプラクティスを提案します。これによって、お使いのレイクハウスで起きている重要なイベントに対して、レトロスペクティブな分析からプロアクティブなモニタリング、アラートにダイヤルを切り替えることができます。
アカウントレベルの監査ログ
コンプライアンスからコストコントロールに至るいくつかの理由から監査ログは非常に重要です。これらはお使いのレイクハウスで何が起きているのかを示す信頼できる記録です。しかし、これまではプラットフォーム管理者は、ワークスペースごとに監査ログの設定を行わなくてはならず、オーバーヘッドの増加や監査ログが有効化されないワークスペースによる企業の盲点を引き起こしていました。
今では、お客さまは全てのユーザー、グループ、ワークスペース、そして、そうあなたの予想通り監査ログも一つの場所で管理するために単一のDatabricksアカウントを活用することができます。これによって、プラットフォームの管理者の生活は劇的にシンプルなものとなり、セキュリティ観点からのリスクを大幅に削減することができます。お客様がアカウントレベルの監査ログを設定すれば、お使いのレイクハウス、すなわち、アカウント配下に作成された既存ワークスペース、新規ワークスペースで起きている全ての重要なイベントの低レーテンシーのストリームがデリバリーされ続けるということを知りながら安眠することができます。
お使いのDatabricksレイクハウスプラットフォームにおけるアカウントレベルの監査ログのセットアップに関してはドキュメント(AWS, GCP)をチェックしてください。
Unity Catalogによるガバナンスの集中管理
Unity Catalog(UC)は、クラウド横断でお使いのデータ、AIの全てに対して動作する世界初の高粒度かつ集中管理のガバナンスレイヤーです。包括的な監査ログと集中管理されたガバナンスレイヤーを組み合わせることで、以下のような質問に答えられるようになります。
- 自分の組織で最も人気のあるデータ資産は何か?
- 自分のデータプロダクトに対して認証されないアクセスを試みているのは誰か、どのようなクエリーを実行しようとしているのか?
- 私が使用しているDelta Shareは信頼されたネットワークのみに限定されているか?
- 私のDelta Shareはどの国からアクセスされているのか?
- 私のDelta Shareはアメリカのどの州からアクセスされているのか?
- 私のDelta Shareはどこからアクセスされているのか?
UCのプレビューにすでに参加しているお客さまは、events WHERE serviceName == "unityCatalog"に対する監査ログを検索するか、提供されているrepoのサンプルクエリーをチェックすることで、これがどのようなものかを確認することができます。ご自身のレイクハウスでこれらの機能がどのように見えるのかを確認したいのであれば、こちらからサインアップしてください!
Delta Live Tablesによる簡単かつ信頼性のある監査ログ処理
これまでに我々が繰り返し目撃した成功するお客様の特徴は、最優先事項としてデータ品質にフォーカスし、フォーカスしていない企業よりも迅速にレイクハウスを成長させているということです。歴史的に見て、これは口で言うほどやさしくはないことです。インフラストラクチャのサイジング、管理、スケーリングといったことを検討するために膨大な時間を費やしてきたエンジニアは、今ではオープンソースあるいはサードパーティのデータ品質、テストフレームワークを用いて自身のコードをインテグレーションすることに費やす時間を見つけ出さなくてはならなくなっています。さらに、これらのフレームワークは多くお場合、大規模データにスケールすることが困難であり、これらは個々のインテグレーションテストでは有用ですが、代表的な性能試験の結果を検証したい際には新たな頭痛のタネを抱えることになってしまいます。
Delta Live Tables (DLT)にようこそ。DLTを用いることで、エンジニアは自身のデータをコードとして取り扱うことができ、ビルトインのデータ品質コントロールを活用できるので、上述したタスクに費やさなくてはいけなかった時間と労力を、品質の悪いデータが決してビジネスプロセスの重要な意思決定に影響を及ぼさないようにするなど、より生産的な活動に差し向けることが可能となります。
そして、監査ログを処理するETLパイプラインは、DLTの提供する信頼性、スケーラビリティ、データ品質コントロールのメリットを享受できるので、我々が以前のブログ記事で共有したETLパイプラインをDLTに移植しました。
このDLTパイプラインは、オートローダーを用いて監査ログを構成するJSONファイルを読み込み、お使いのレイクハウスにデータを取り込むシンプルかつ容易にスケールするソリューションとなります。アカウントとワークスペースレベルのアクションに対応するそれぞれのブロンズ、シルバーテーブルを作成し、それぞれのステップでの利用が簡単になるようにデータを変換します。最後に、Databricksのサービスごとのゴールドテーブルを作成します(AWS、Azure、GCPのドキュメントをご覧ください)。
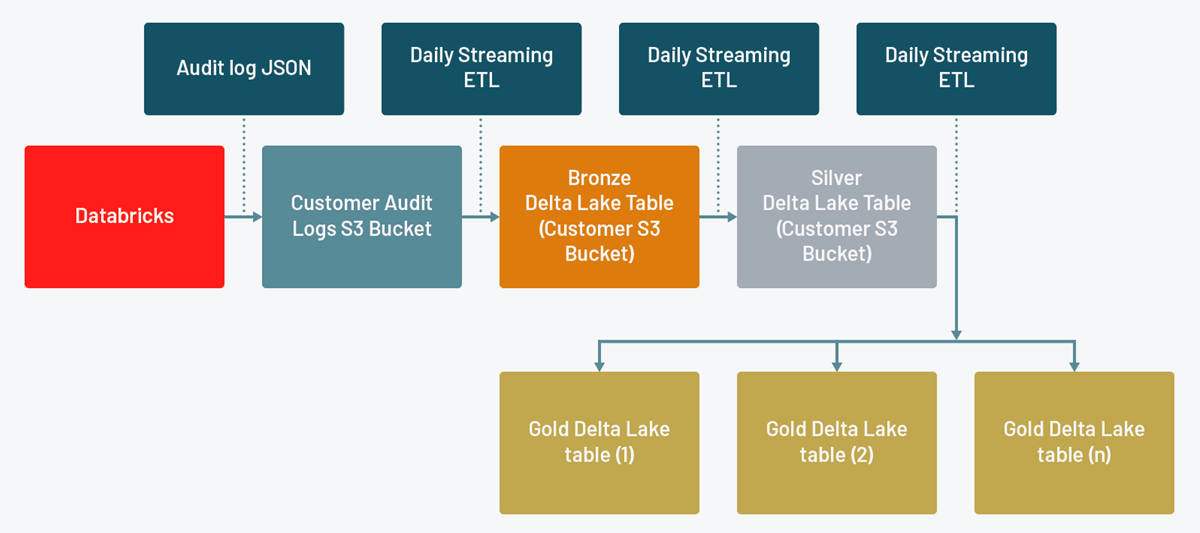
シルバーテイブルを用いることで、Databricksレイクハウスプラットフォームにおける特定ユーザーのアクションを調査するといったシナリオのように、全てのDatabricksサービスに対する詳細分析が可能となります。また、ゴールドテーブルによって特定サービスに関連する高速クエリーが可能となります。これは特に特定のアクションに関連するアラートの設定を行いたい場合には有用です。
以下の例は、AWSとGCPをご利用のお客様ではすぐに活用することができます。診断ログがAzureストレージアカウントにデリバリーされるようにセットアップしたAzure Databricksをお使いのお客様は、若干の修正が必要となります。これは、Azureにおける診断ログのスキーマがAWSやGCPのものと若干異なるためです。
お使いの環境で新たなDLTパイプラインを動作するようにするためには、以下のステップを踏んでください。
- Git連携のためのreposを用いてGithubのリポジトリをクローンします(AWS、Azure、GCPのドキュメントをご覧ください)。
-
dlt_audit_logs.pyノートブックをリンクして新規のDLTパイプラインを作成します(AWS、Azure、GCPのドキュメントをご覧ください)。以下の設定オプションを入力する必要があります。
-
INPUT_PATH: 監査ログデリバリーを設定したクラウドストレージのパス。通常これは保護されたストレージアカウントであり、皆様のDatabricksユーザーには公開されません。 -
OUTPUT_PATH: 監査ログのDelta Lakeのために使用したいクラウドストレージのパス。通常これは保護されたストレージアカウントであり、皆様のDatabricksユーザーには公開されません。 -
CONFIG_FILE: お使いのrepoにチェックアウトしたaudit_logs.jsonへのパス。
-
- 注意: UI経由で設定可能な設定を変更した場合、
INPUT_PATHとOUTPUT_PATHへのクラスターオブジェクトの認証を行うための設定を追加するようにJSONも編集する必要があります。- AWSでは、
aws_attributesオブジェクトにinstance_profile_arnを追加します。 - Azureでは、
spark_confオブジェクトにサービスプリンシパルのシークレットを追加します。 - GCPでは、
gcp_attributesオブジェクトにgoogle_service_accountを追加します。
- AWSでは、
- これで、適切なスケジュールあるいはトリガーに基づいてパイプラインを実行するせってができたことなります。実行に成功すると以下のように表示されます。

注意すべき点がいくつかあります。
- 上述したCONFIG_FILEに基づいて、設定可能なログレベルとサービス名のリストに基づいてパイプラインはデータを処理します。
- デフォルトでは、ログレベルは
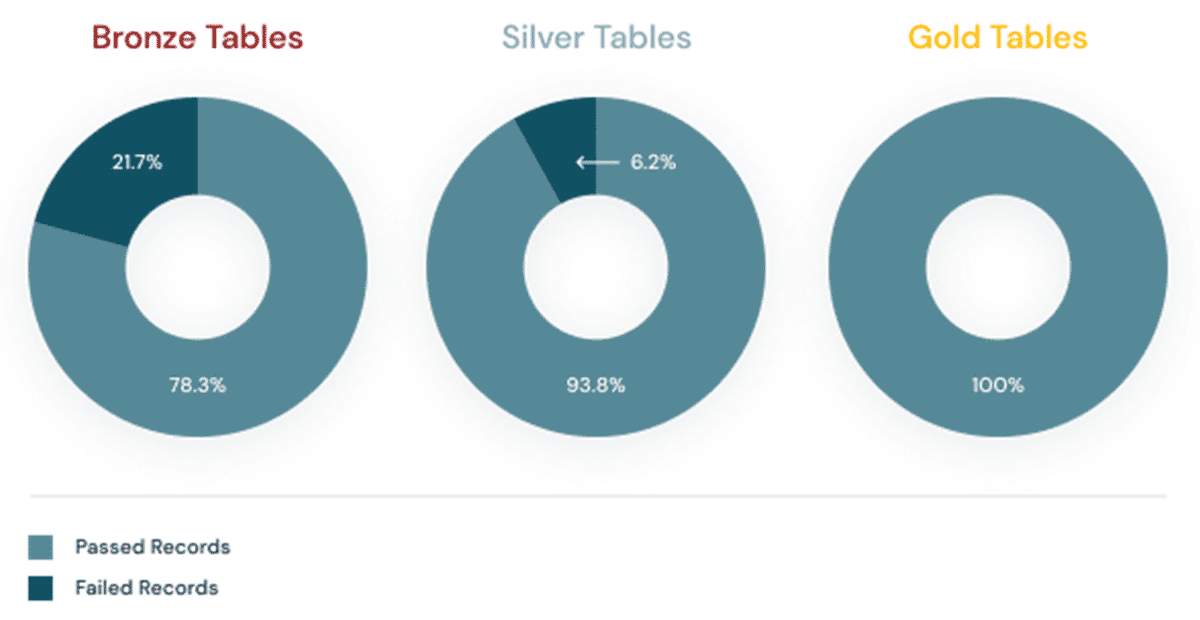
ACCOUNT_LEVELとWORKSPACE_LEVELです。現時点では、Databricksで使用できる監査レベルはこの2つのみですが、将来にわたってログレベルを追加しないことを保証するわけではありません。新たなログレベルが追加された際にいかなるログも見落とさないように、定期的に監査ログのスキーマをチェックすることをお勧めします(AWS、Azure、GCPのドキュメントをご覧ください)。 - 新機能が追加され、プラットフォームにサービスが追加されるとserviceNamesが変更される場合があります。PCI-DSS compliance controlsやEnhanced Security Modeのような機能を利用しているかどうかによってserviceNamesが変化する場合があります。公開ドキュメント(AWS、Azure、GCP)でサービス名の一覧を定期的にチェックすることができますが、こちらの可能性の方が高いので、我々はログの中に新たなサービス名が出てきたことを検知できるようにし、予期しないサービス名をレイクハウスに取り込まないようにするための検知モードをDLTパイプラインに組み込みました。このような潜在的データ品質問題を検知するためにDelta Live Tablesにおけるエクスペクテーションの使用方法の詳細に関しては、以下を読み進めてください。
エクスペクテーションは検証と一貫性チェックを通じて、不正なデータがテーブルに流入することを防ぎ、事前定義ずみのエラーポリシー(失敗、削除、警告、データの検疫)を用いてデータ品質のエラーを回避します。
dlt_audit_logs.pyノートブックでは、テーブルごとに以下のようなデコレーターがあることに気づくでしょう。
@dlt.expect_all({})
これがDelta Live Tablesにおけるデータエクスペクテーションの設定方法です。また、serviceNameカラムに含まれる入力値と設定リストを比較をおこなっているunexpected_service_namesというエクスペクテーションがブロンズテーブルに設定されていることに気づくでしょう。データの中に我々が追跡していない新たなserviceNamesがある場合、このエクスペクテーションの失敗を確認することができ、新規あるいは追跡していないserviceNameを設定に追加するかどうかを検討することができます。
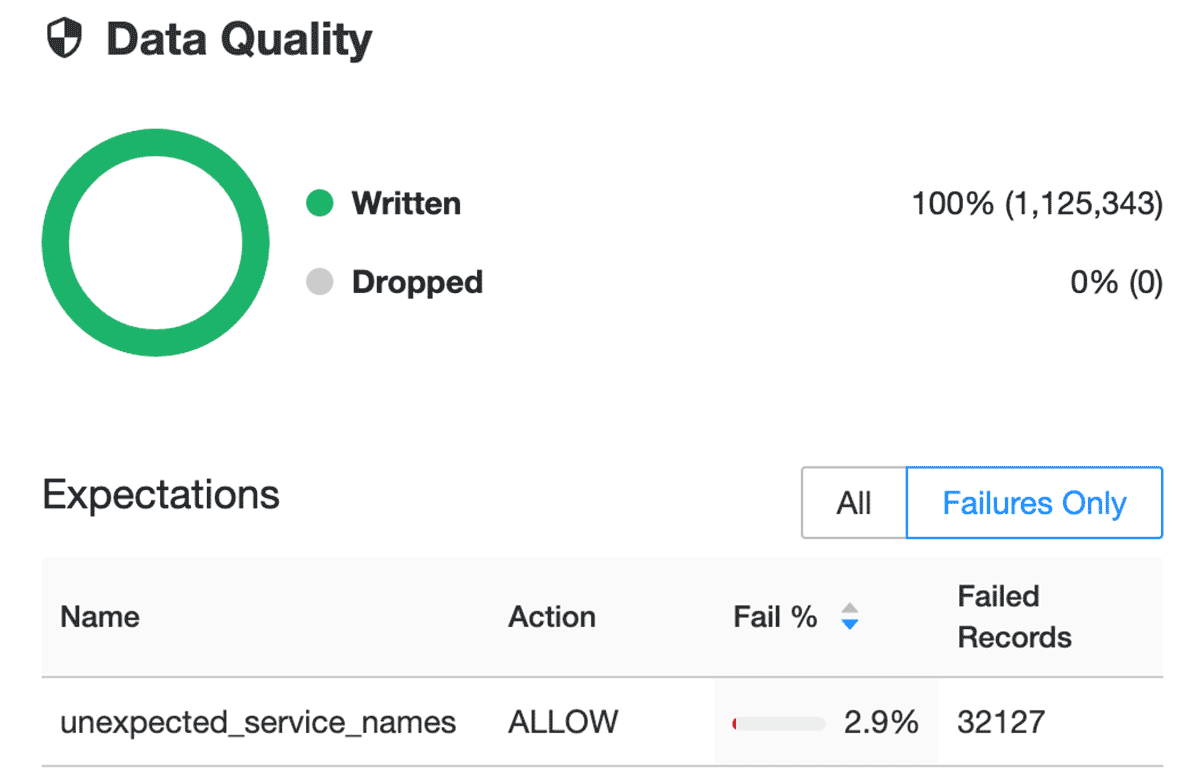
エクスペクテーションの詳細に関しては、AWS、Azure、GCPのドキュメントをご覧ください。
Databricksにおいては、Delta Live TablesがETLの未来を形作るものだと信じています。ここまでで見てきたことを気に入って、より詳細を知りたいのでしたら、こちらのスタートガイドをご覧ください!
Databricks SQLによる簡単なクエリー
これで、監査ログをブロンズ、シルバー、ゴールドテーブルにキュレーションすることができましたので、優れたコストパフォーマンスを提供するDatabricks SQLを用いてクエリーを行います。データエクスプローラーに移動すると、上述したDLT設定で指定したターゲットデータベース内にブロンズ、シルバー、ゴールドテーブルを確認することができます。
ここでのユースケースには、アドホックな調査から潜在的な誤用、予算を超える大規模GPUクラスター使用者の発見など多岐にわたります。
利用をスタートできるように、皆様が特に関心を持っているであろうサービスとシナリオをカバーしているサンプルのアカウントレベル、ワークスペースレベルのSQLクエリーを提供しています。Repoをクローンする際にはSQLノートブックとしてチェックアウトすることになりますが、Databricks SQLで実行する際にはSQLをコピーアンドペーストするだけで大丈夫です。これらのクエリーではデータベース名がaudit_logsであることを前提としています。上のDLT設定で別の名前を指定した場合には、audit_logsをお使いのデータベース名で置換してください。
Databricks SQLによる簡単な可視化
ファーストクラスのSQL体験と超高速なクエリーエンジンを通じたデータに対するクエリーに加えて、Databricks SQLでは直感的なドラッグアンドドロップのインタフェースを用いてクイックにダッシュボードを構築することができ、キーとなるステークホルダーと共有うすることができます。さらには、自動更新を設定することもできるので、意思決定者が常に最新のデータにアクセスすることを保証することができます。
ここで皆様のキーとなるステークホルダーに見せたいであろう全てのことをカバーするのは難しいのですが、これらのSQLクエリーと以下でお見せする関連のビジュアライゼーションによって何ができるのかを皆様にお伝えできれば幸いです。
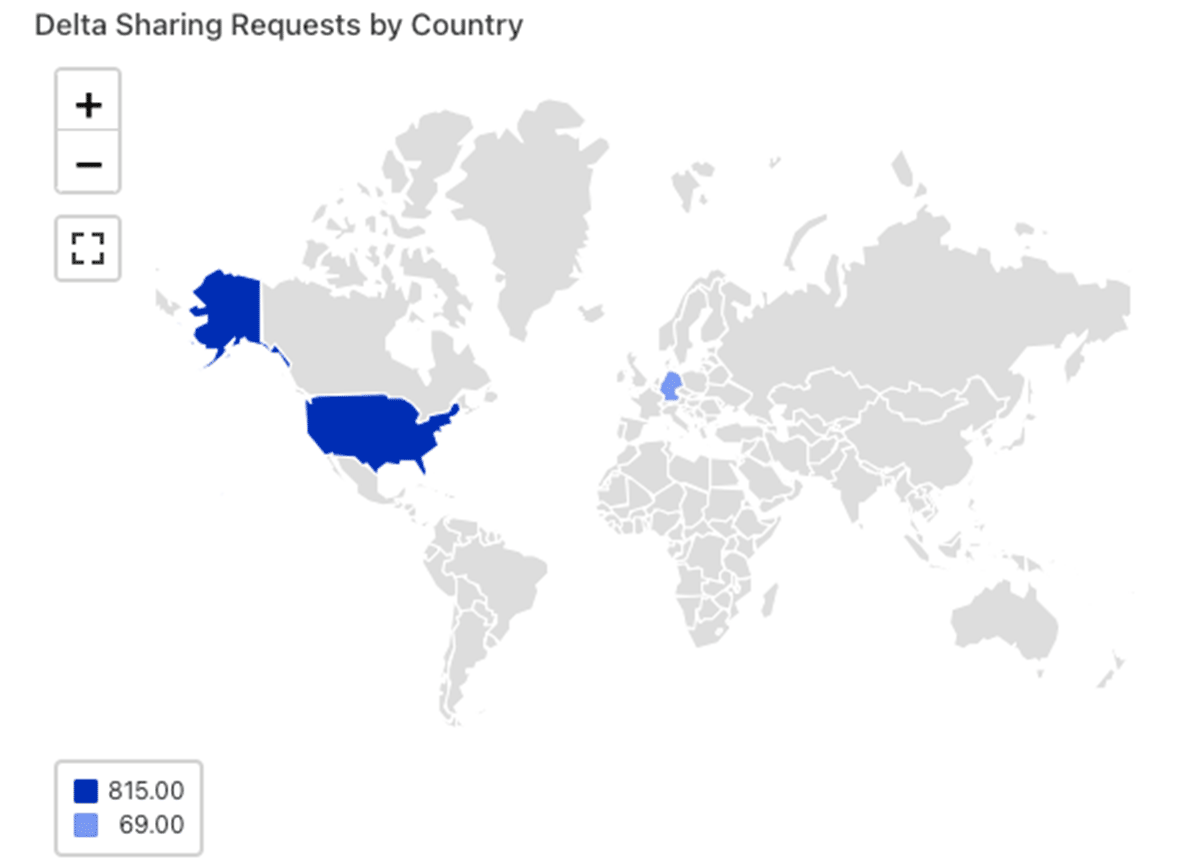
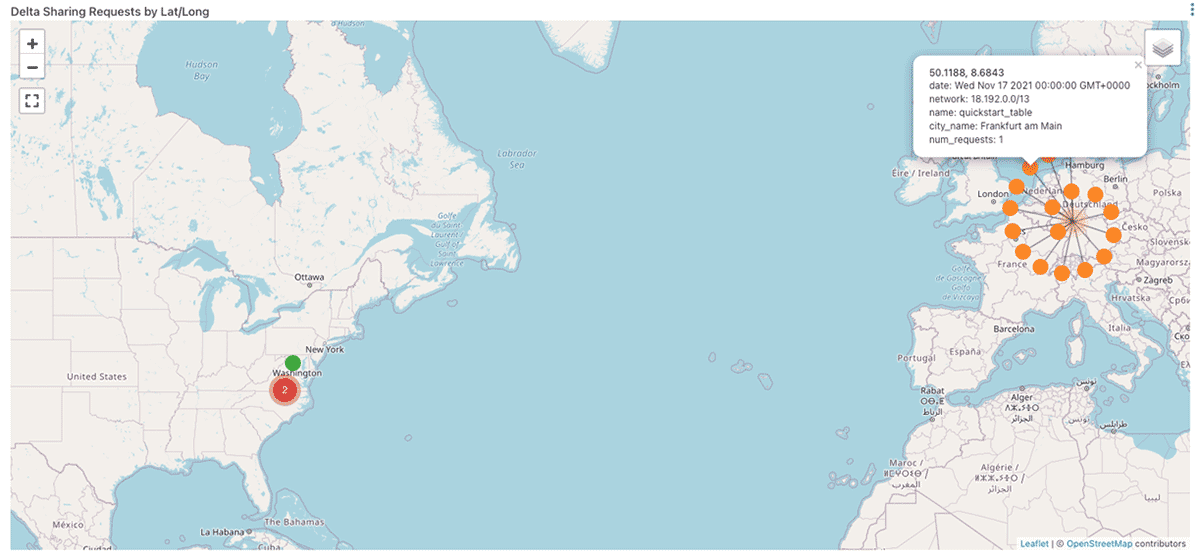
自分のDelta Shareはどの国からアクセスされているのか?
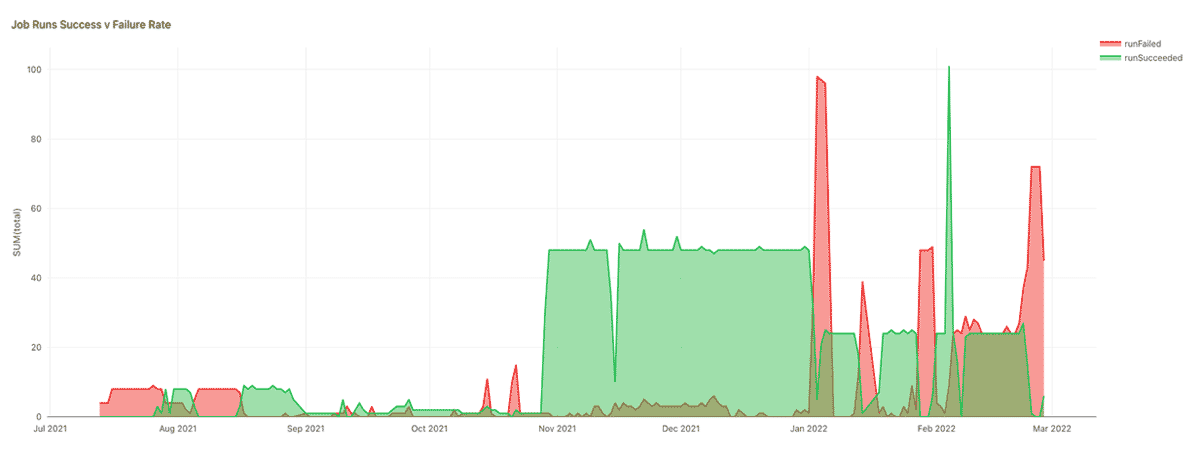
我々のジョブはどれだけ信頼できるのか?
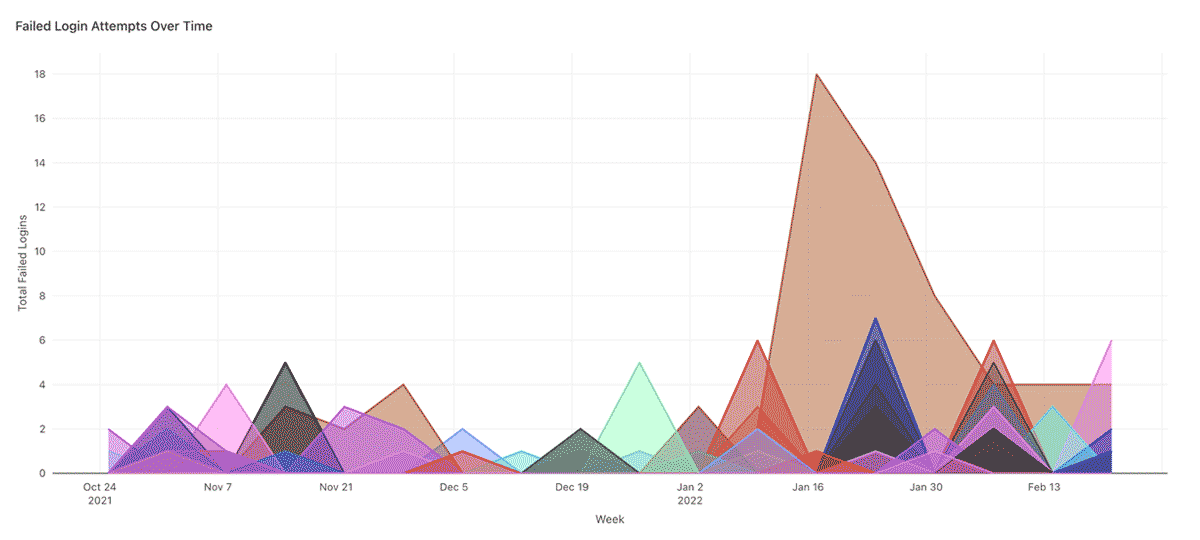
ログイン失敗の繰り返し
ログイン失敗のスパイクはブルートフォース攻撃の可能性があり、トレンドを監視すべきです。例えば、以下のチャートでは、定期的な月ごとのスパイクは30日間のパスワードローテーションポリシーの影響かもしれませんが、1月の特定ユーザーの大きなスパイクは疑わしいものに見えます。
これらのビジュアライゼーションの構築に使用している全てのサンプルSQLクエリーやその他の参考情報はリポジトリで公開されています。
Databricks SQLによるアラートの自動化
いかなるプラットフォームと同様に、他よりも注視すべきいくつかのイベントが存在し、それらに関しては、発生と同時にプロアクティブに通知してほしいと考えるでしょう。はい、良いニュースはこれらのイベントを検知するSQLクエリーをスケジュールした際に、容易にDatabricks SQLでアラートを設定できるということです。上でお見せしたサンプルSQLクエリーにシンプルな変更を加えることも可能です。
- 時間期限を設けるようにクエリーを更新します(
timestamp >= current_date() – 1の追加)。 - 予期しないイベントの数を返却するクエリーを更新します(
COUNT(*)と適切なWHERE句の追加)。 - アラートを日次で実行するように設定し、イベント数が
> 0となった場合にトリガーを起動するように設定します。 - 条件ロジックに基づくより複雑なアラートに関してはCASE文の使用を検討します(AWSやAzureのドキュメントをご覧ください)。
例えば、以下のSQLクエリーをアラートに使用することができます。
-
前日更新されたワークスペース設定が存在する。
SQLSELECT requestParams.workspaceConfKeys, requestParams.workspaceConfValues, email, COUNT(*) AS total FROM audit_logs.gold_workspace_workspace WHERE actionName = 'workspaceConfEdit' AND timestamp >= current_date() - 1 GROUP BY 1, 2, 3 ORDER BY total DESC -
前日ワークスペースからデータを含むアーティファクトのダウンロードがあった。
WITH downloads_last_day AS (
SELECT
timestamp,
email,
serviceName,
actionName
FROM
audit_logs.gold_workspace_notebook
WHERE
actionName IN ("downloadPreviewResults", "downloadLargeResults")
UNION ALL
SELECT
timestamp,
email,
serviceName,
actionName
FROM
audit_logs.gold_workspace_databrickssql
WHERE
actionName IN ("downloadQueryResult")
UNION ALL
SELECT
timestamp,
email,
serviceName,
actionName
FROM
audit_logs.gold_workspace_workspace
WHERE
actionName IN ("workspaceExport")
AND requestParams.workspaceExportFormat != "SOURCE"
ORDER BY
timestamp DESC
)
SELECT
DATE(timestamp) AS date,
email,
serviceName,
actionName,
count(*) AS total
FROM
downloads_last_day
WHERE timestamp >= current_date() - 1
GROUP BY
1,
2,
3,
4
これらは、プラットフォーム管理者がユーザーポリシーの違反があったのかどうかを調査するために十分な情報を提供するために、以下のようなカスタムアラートのテンプレートと組み合わせることができます。
Alert "{{ALERT_NAME}}" changed status to {{ALERT_STATUS}}
前日に予期しないイベントが存在した。
{{QUERY_RESULT_ROWS}}
アラートの設定方法に関してはドキュメントをチェックしてみてください(AWS、Azure)。また、SlackやPagerDutyのような追加のアラートの宛先に関してもチェックしてみてください(AWS、Azure)。
レイクハウスに対する360度の可視性による信頼および検証
Databricksの監査ログは、お使いのレイクハウスにおけるアクションの包括的な記録を提供します。しかし、Unity Catalogを使用していない場合(信じてください。使っていなばい場合には使うべきです)は、皆様が最も関心のあるインタラクションのいくつかは、背後のクラウドプロバイダーのログでのみ捕捉されるかもしれません。例としては、クラウドネイティブのアクセスコントロールを使用している場合、データへのアクセスはストレージアクセスログで許可される粗いレベルでのみ捕捉されることになります。
このテーマに関する以前のブログ記事に書いたように、この理由(そしてその他の理由)のため、背後のクラウドプロバイダーによって捕捉される様々なロギングとモニタリングの出力とともにDatabricksの監査ログを使用したいと考えるかもしれません。そして、以前の記事における推奨事項は依然として真実であり、これらのワークロード向けのDLTパイプラインを含む将来的なバージョンも楽しみにしていてください!
ベストプラクティスのまとめ
まとめると、本書を通じて説明した管理者向けの5つのロギングのベストプラクティスとモニタリングのベストプラクティスは以下の通りとなります。
- アカウントレベルでの監査ログを有効化します。皆様のレイクハウスのジャーニーの最初の時点から監査可能性を確保することで、履歴上のベースラインを手に入れることができます。多くの場合、あなたが本当に本当に監査ログを必要した時にどれだけ監査ログを必要としていたのかを理解します。過ちから学ぶよりも履歴的なベースラインを持つ方がベターです。信じてください。
- Unity Catalogを導入します。クラウド横断、ワークスペース横断の分析によって、レイクハウスのガバナンスとコントロールを新たなレベルに引き上げることができます。
- 理想的にはDLTを用いてロギングのパイプラインを自動化します。これによって、複雑な大量のコードを必要とすることなしにデータの衛生状況と鮮度を保証することができ、誰かが(いつ)壊したり変更した際にアラートを出せるように簡単にセットアップすることも可能です。
- ログデータに対してメダリオンアーキテクチャを適用します。これによって、パイプラインから高品質、高鮮度のデータが提供されることを保証し、誰も見つけ出せないデータベースに埋もれることがなくなります。そして、Databricks SQLによるクエリーが非常に簡単になります!
- あなたが本当に関心を持つイベントに対して自動アラートをセットアップするためにDatabricks SQLを使います。
- お使いのDatabricks監査ログをより広範なロギングエコシステムに組み込みます。これにはクラウドプロバイダーのログや、お使いのアイデンティティプロバイダーのログ、その他のサードパーティアプリケーションのログが含まれるかもしれません。お使いのレイクハウスで何が起きているのかを表す360度のビューを作成することは、現在の変動の激しいセキュリティランドスケープでは特に適切なことだと言えます。
結論
監査ログに関する前回の記事から2年が経過しており、Databricksレイクハウスプラットフォームと世界の両方は劇的に変化しました。我々の多くはこの期間リモートで働いていますが、リモートワーキングは適切な利用ポリシー、遵守状況に対する圧力と監視を高めることになりました。幸運なことに、Databricksレイクハウスプラットフォームはデータチームがこれらの問題をより容易に管理できるように大きな一歩を踏み出しました(そして今後も継続していきます)。
本記事の著者として、これらのトピックに関するこれまでの記事の著者に感謝の意を表します。
- Miklos Christine
- Craig Ng
- Anna Shrestinian
- Abhinav Garg
- Sajith Appukuttan
我々は巨人の肩の上に立っています。