Databricks Sets Official Data Warehousing Performance Record - The Databricks Blogの翻訳です。
本日、データウェアハウスの標準パフォーマンスベンチマークである100TBのTPC-DSで、我々のDatabricks SQLが新たな世界記録を達成したことを発表できることを嬉しく思います。Databricks SQLは前回の記録の2.2倍の記録を達成しました。 多くの他のベンチマークのニュースとは異なり、この結果は正式にTPCの評議会で監査、検証されたものとなります。
この結果は、頻繁に著名なデータウェアハウスに対してTPC-DSを実行しているBarcelona Supercomputing Centerによる研究によって裏付けられています。彼らの最新の研究では、DatabricksとSnowflakeに対するベンチマークが行われ、Databrikcsの性能が2.7倍、コストパフォーマンスにおいては12倍優れていることが報告されました。 この結果は、実運用で用いるデータサイズが増加するに従って、Snowflakeのようなデータウェアハウスは法外に高くなるという仮説を裏付けたものとなっています。
Databricksは、データレイクの上に直接、本格的なデータウェアハウス機能を構築し、データレイクハウスと呼ばれる単一のデータアーキテクチャにおいて、データウェアハウス、データレイク両方のメリットを提供しています。我々は2020年11月に、データウェアハウスのフルスイート、Databricks SQLを発表しています。これ以来のオープンな疑問は、レイクハウスに基づくオープンアーキテクチャは、クラシックなデータウェアハウスのパフォーマンス、スピード、コストを提供できるのかどうかというものでした。
単に結果を共有するのではなく、ここでは我々がどのようにして、このレベルのパフォーマンスを達成したのか、どの様な努力があったのかのストーリーをシェアさせていただければと考えています。しかし、まずは結果から共有させてください。
TPC-DS世界記録
Databricks SQLは、32,941,245 QphDS @ 100TBを達成しました。これは、以前の世界記録である、14,861,137 QphDS @ 100TBを達成したAlibaba(Alibabaは世界最大のeコマースプラットフォームを支える驚異のシステムを持っていました)のカスタムビルトのシステムによる記録の2.2倍となっています。Databricks SQLは以前の記録を大幅に上回っただけでなく、全体的なコストを10%削減しつつ、この記録を成し遂げました(公開されているディスカウントなしの価格情報に基づく)。
単位であるQphDSが何を意味するのかを知らないことは全く持って普通のことです。(我々も数式を見ない限り理解できません。)QphDSは以下のワークロードの組み合わせにおけるパフォーマンスを表現するTPC-DSにおける主要なメトリックとなります。
- データセットのロード
- 一連のクエリーの処理(パワーテスト)
- 複数の同時実行クエリーストリームの処理(スループットテスト)
- データのinsert/deleteを行うデータメンテナンス関数の実行
上述した結論はさらに、Barcelona Supercomputing Center (BSC)によって最近実施されたDatabricks SQLとSnowflakeを比較する別のベンチマークでもサポートされており、同じサイズのセットアップのSnowflakeと比較して、2.7倍高速であることが確認されています。彼らは、Databricksを2つのモードでベンチマークしました。オンデマンドとスポットです(スポットインスタンスを構成するマシンは低い信頼性となりますがコストも低くなります)。オンデマンドモードでは、DatabricksはSnowflakeより7.4倍安く、スポットモードでは12倍安くなります。
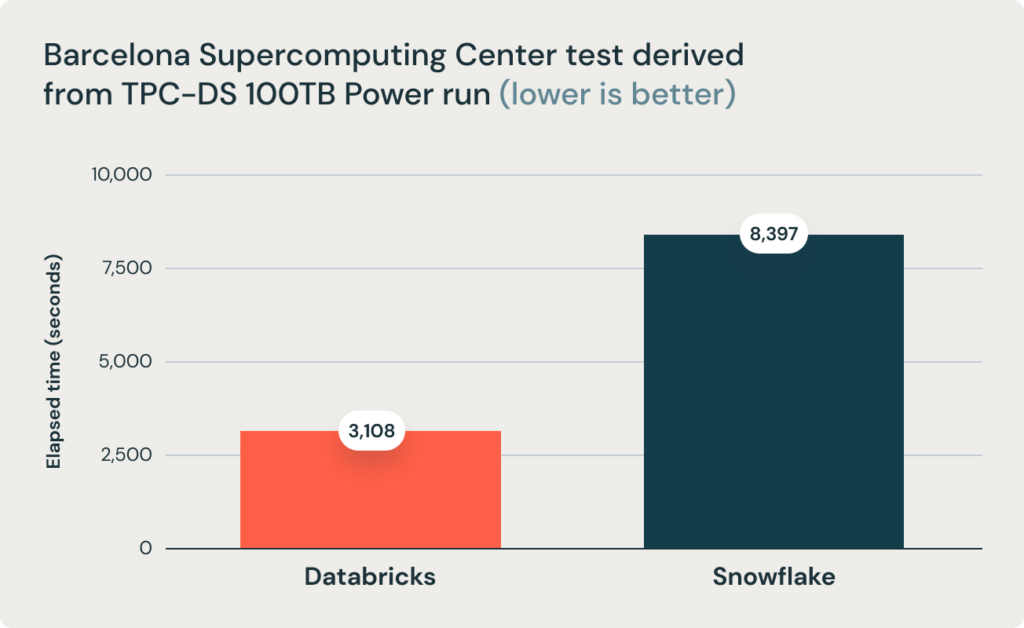
図1: TPC-DS 100TBのパワーランから得られたテスト実行時間、Barcelona Supercomputing Centerによる
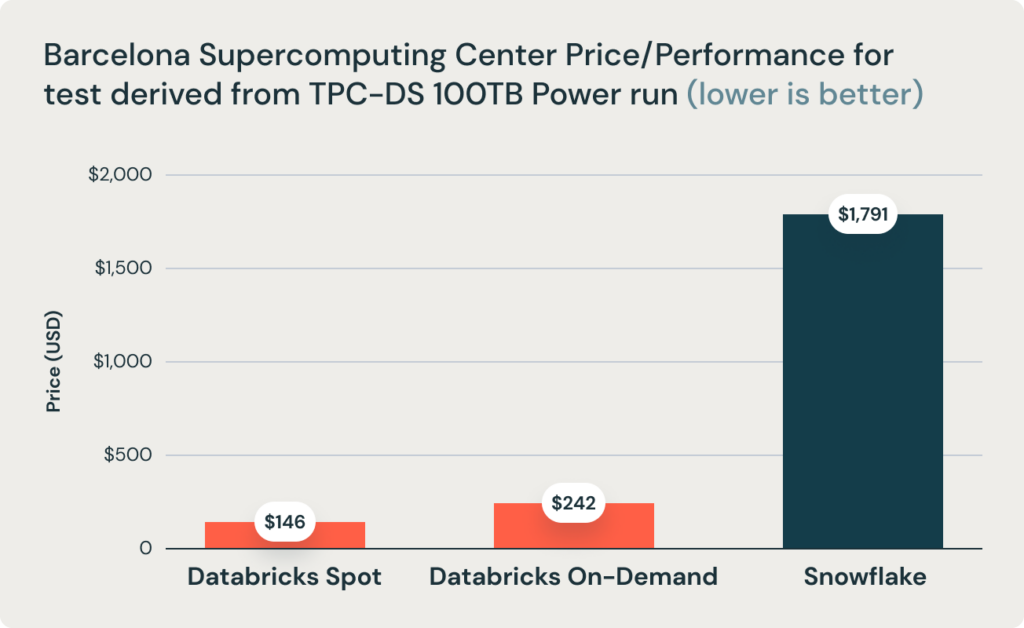
図2: TPC-DS 100TBのパワーランから得られたテストにおけるコストパフォーマンス、Barcelona Supercomputing Centerによる
TPC-DSとは何か?
TPC-DSは、Transaction Processing Performance Council (TPC)によって定義されるデータウェアハウスのベンチマークです。TPCは、80年代後半にデータベースコミュニティで立ち上がった非営利組織であり、実世界のシナリオを模したベンチマークを作成することにフォーカスしています。このため、これはデータベースシステムのパフォーマンスを計測する目的で使用されています。データベース業界を推し進めたOracle、Microsoft、IBMのようなベンダー間の数十年に渡る「ベンチマーク戦争」を通じて、TPCはデータベース業界に大きなインパクトを持つ様になりました。
TPC-DSの「DS」は、「意思決定(Decision Support)」を意味します。これには、非常にシンプルな集計から複雑なパターンマイニングに至る様々な複雑度の99のクエリーから構成されています。これは、増加する分析の複雑性を反映した比較的新しいベンチマーク(取り組みは2000年代半ばからスタートしました)です。過去十数年において、TPC-DSはほぼ全てのベンダーに受け入れられ、データウェアハウスベンチマークのデファクトとなりました。
しかし、この複雑性のため、最も著名なベンダーによるものを含め、多くのデータウェアハウスシステムは、自身のシステムが優れた性能を示す様に公式のベンチマークを微調整してきました。(一般的な微調整は、rollupのような特定のSQL機能を削除したり、偏りを避けるためにデータ分布を変更するなどです。)これは、TPC-DSに言及しているインターネット上のページが400万以上もあるにもかかわらず、公式なTPC-DSベンチマークの数が非常に少なかった理由の一つとなっています。また、この微調整は、なぜ多くのベンダーが自身のベンチマークで、表面上は他のベンダーを打ち負かしている様に見えることを説明してます。
どの様に達成したのか?
上で述べた様に、オープンな疑問として、Databricks SQLがSQLのパフォーマンスにおいて、データウェアハウスのパフォーマンスを上回ることができるのかというものがありました。多くのチャレンジは、以下の4つの問題にまとめることができます。
- データウェアハウスはプロプライエタリなデータフォーマットを活用しています。このため、すぐに自身を改善できますが、Databricksはオープンフォーマット(Apache Parquet、Delta Lake)に依存しており、すぐに変更することはできません。結果として、EDW(エンタープライズデータウェアハウス)は固有のメリットを持っています。
- すぐれたSQLパフォーマンスには、MPP(大規模並列処理)アーキテクチャが必要となりますが、DatabricksとApache SparkはMPPではありません。
- 古典的なスループットとレーテンシーのトレードオフは、システムは大規模クエリー(スループットへのフォーカス)や小規模クエリー(レーテンシーにフォーカス)に対して優れた性能を示すことはできますが、両方はできないということを示唆しています。Databricksでは大規模クエリーにフォーカスしていたので、小規模クエリーでは高い性能を出せていませんでした。
- 仮に可能だっとしても、過去の知見から、データウェアハウスシステムを構築するには10年以上の時間を要することがわかっています。すぐに進捗を出す方法はありません。
この記事では、上の一つ一つを議論していきます。
プロプライエタリデータフォーマット対オープンデータフォーマット
レイクハウスアーキテクチャにおいてキーとなる信条の一つがオープンなストレージフォーマットです。「オープン」であることは、ベンダーロックインを回避できるだけではなく、ベンダーとは独立してツールを開発することができ、エコシステムを実現します。オープンフォーマットの主要なメリットは標準化です。この標準化によって、多くの企業データがオープンなデータレイクに格納されることになり、Apache Parquetはデータ格納におけるデファクト標準となりました。オープンなフォーマットでデータウェアハウスレベルのパフォーマンスを実現することで、データの移動を最小化し、BI、AIワークロードに対するデータアーキテクチャをシンプルにすることを望んでいます。
「オープン」であることに対するわかりやすい反対意見は、オープンフォーマットは変更しにくく、改善しにくいというものです。この議論は理論的には納得いくものですが、実際のところそれほど正確ではありません。
まず初めに、オープンフォーマットが進化できるのは間違いありません。大規模データ格納において最も人気のあるオープンフォーマットであるParquetは、複数回の改善イテレーションを経験しています。我々がDelta Lakeを導入した主なモチベーションの一つには、Parquetのレイヤーでは実現困難であった追加機能を導入することがありました。Delta LakeはParquetに対して、追加のインデックス機能と統計情報をもたらしました。
2つ目に、システムアーキテクチャに対する理解が必要となるより細かい話があります。多くのクエリーにおいては、背後にあるデータフォーマットではなく、中間のキャッシュフォーマットがスキャンのパフォーマンスを決定づけます。実際のところ、多くのクラウドシステムは、格納はオブジェクトストア、キャッシュはローカルのSSD/メモリーに依存しています。Databricksも同様です。このことは、適切にアーキテクチャが設計されたデータシステムにおいては、多くのクエリーにおいてキャッシュからデータを読み込めるということを意味しています。Databricks SQLはこの可能性を積極的に活用しており、キャッシュの際、オンザフライでデータをNVMe SSDに適したより効率的なフォーマットに変換しています。
MPPアーキテクチャ
よくある誤解として、データウェアハウスは優れたSQLパフォーマンスを達成するMPPアーキテクチャを採用しており、Databricksはそうではない、というものがあります。MPPアーキテクチャは、単一のクエリーを処理するために複数ノードを活用する能力のことを指し示しています。これはまさに、Databricksのアーキテクチャそのものです。これは、Apache Sparkをベースとしたものではなく、むしろ、モダンなSIMDハードウェアに対応し、高負荷な並列クエリー処理を行うために完全に新たにスクラッチでC++を用いて構築されたエンジンであるPhotonをベースとしたものです。すなわち、PhotonはMPPエンジンです。
スループットとレーテンシーのトレードオフ
スループットとレーテンシーは、コンピュータシステムにおいて昔から存在するトレードオフであり、システムは高いスループットと低いレーテンシーを同時に達成することはできないことを意味しています。設計がスループットに対してフォーカス(例:データのバッチ処理)している場合、レーテンシーを犠牲することになります。データシステムの文脈においては、システムは同時に大規模なクエリーと小規模なクエリーを効率的に処理できないことを意味します。
このトレードオフが存在することを否定するつもりはありません。実際、我々も技術的設計文書において、よくこのことを議論しています。しかし、我々自身のシステムおよびすべての著名なウェアハウスを含む現在の最先端のシステムは、スループット、レーテンシーの領域において、優れた開拓者の位置よりも遥か遠い場所まで到達しています。
結果として、スループットとレーテンシーの両方を同時に改善する新たなデザイン、実装を考案することが完全に可能となっています。これがまさに、我々が過去の2年間で構築した、キーとなる実現技術なのです。Photon、Delta Lake、そして、その他の最先端技術が大規模クエリー、小規模クエリー両方のパフォーマンスを改善し、新たなパフォーマンス記録を打ち立てたのです。
時間とフォーカス
最後に、一般論としてデータベースシステムが成熟するには少なくとも十数年かかるというものがあります。Databricksの最近のレイクハウスのフォーカス(SQLワークロードのサポート)によって、SQLをより高性能にするための投資が必要となりました。これは適切なものですが、ここでは、我々が予想する以上の高い性能をどの様に達成したのかを説明させてください。
まず初めに、この投資は1年、2年前にスタートしたものではありません。Databricksの誕生以来、我々はDatabricksにおけるAIワークロードにも利益をもたらすような、SQLワークロードをサポートする様々な基盤技術を調査してきました。これには、完全なコストベースのクエリーオプティマイザ、ネイティブのベクトル化クエリーエンジン、ウィンドウ関数の様な様々な機能が含まれます。Databricksにおけるワークロードの大部分はSparkのデータフレームAPIを通じて実行され、これらは自身のSQLエンジンにマッピングされます。このため、これらのコンポーネントは数年のテスト、最適化を経てきたものとなっています。我々があまりフォーカスしていなかったのは、SQLワークロードへの対応です。最近のレイクハウスのポジショニングの変更は、お客様が自身のデータアーキテクチャをシンプルにしたいという願いを受けて行われたものです。
2つ目に、SaaSモデルはソフトウェア開発サイクルを加速しました。これまでは、多くのベンダーは年次ベースのリリースサイクルを持っており、お客様がソフトウェアをインストール、導入するのには複数年のサイクルが必要となっていました。SaaSにおいては、我々のエンジニアチームが新たなデザインを考案し、実装、一部のお客様にリリースするまでに数日で済むようになっています。この短縮された開発サイクルによって、チームは迅速にフィードバックを取得し、より高速にイノベーションを行える様になっています。
3つ目に、Databricksはこの問題に対して、リーダーシップの帯域、資本の観点でより多くのフォーカスをもたらすことができます。新たなデータウェアハウスシステムを構築するという過去の取り組みは、スタートアップや大企業における新規チームによって行われていました。データウェハウスシステムを構築するために必要となる人材を惹きつける、Databricksのようなデータベーススタートアップ(35億ドル以上を調達)は存在していませんでした。大企業における新たな取り組みは、新たな労力を必要としますが、リーダーシップの完全なるサポートを受けることはないでしょう。
ここでユニークなシチュエーションをご紹介します。我々は最初は自身のビジネスにおいて、データウェアハウスにフォーカスしておらず、多くの共通する技術的課題を持つ関連する領域(データサイエンス、AI)にフォーカスしていました。この最初の成功によって、歴史上最もアグレッシブなSQLチームを組成するための投資が可能となりました。短い時間で、我々は強力なデータウェアハウスのバックグラウンドを持つ人でチームを構成することができ、これは他の企業であれば10年程度時間を要することになる偉業となりました。彼らは、Amazon Redshift、Googleの BigQuery、F1(Googleの内部データウェアハウスシステム)、Procella(Youtubeの内部データウェアハウスシステム)、Oracle、IBM DB2、Microsoft SQL Serverといった、最も成功しているデータシステムのリードエンジニア、デザイナーから構成されています。
まとめると、優れたSQLパフォーマンスを実現するには数年かかるということです。我ら固有の状況を活用するだけでなく、メガフォンを使って計画をお知らせはしませんでしたが、数年前から取り組みをスタートしていたのです。
実世界におけるお客様のワークロード
お客様によってこのベンチマーク結果が検証されたのを見て非常に嬉しく思っています。世界中で5,000以上のお客様が、Databricksのレイクハウスプラットフォームを活用して、世界で最も困難な問題の解決に取り組まれています。
- Bread Financeは、財務レポート、不正検知、クレジットリスク、損害の推定、フルファンネルのレコメンデーションエンジンのようなビッグデータユースケースを持つ、テクノロジードリブンのペイメントプラットフォームです。Databricksレイクハウスプラットフォームにおいて、夜間バッチからニアリアルタイムのデータ取り込みに移行することができ、データ処理時間を90%削減しました。さらに、1.5倍のコストで、彼らのデータプラットフォームは140倍の規模のデータにスケールすることができました。
- Shellでは、数百人のデータアナリストが標準的なBIツールを用いてペタバイト級のデータセットに対して高速なクエリーを実行しており、これを「ゲームチェンジャー」だと考えています。
- Regeneronでは、すべてのデータセットに対するクエリーの時間を30分から3秒へと600倍の性能改善を行い、計算機を使用する生物学者に迅速に洞察を提供することで、創薬ターゲットの特定を加速しています。
まとめ
レイクハウスアーキテクチャの上に構築されたDatabricks SQLは、市場において最も高速なデータウェアハウスであり、ベストなコストパフォーマンスを提供します。今や、あなたは別のシステムにデータをエクスポートすることなしに、新たなデータが到着するとすぐに、低レーテンシーで全てのデータに対して、優れたパフォーマンスを手に入れることができます。
これは、データレイクにワールドクラスのデータウェアハウスのパフォーマンスをもたらすという、レイクハウスのビジョンの証明です。もちろん、我々は単なるデータウェアハウスを開発したのではありません。レイクハウスアーキテクチャは、データウェアハウスからデータサイエンス、機械学習まで、すべてのデータワークロードをカバーする機能を提供しています。
しかし、まだ終わりではありません。我々は市場でベストなチームを組んでおり、彼らは次のパフォーマンスのブレークスルーを提供するために懸命に働いています。パフォーマンスに加え、使いやすさ、ガバナンスに関する数多くの改善に取り組んでいます。来年の我々からのニュースにご期待ください。