Auto Optimize | Databricks on AWS [2021/11/18時点]の翻訳です。
Auto OptimizeはDeltaテーブルに対するそれぞれの書き込みにおいて、自動で小さいファイルをコンパクトにするオプション機能です。書き込みの際に少量のコストを支払うことで、アクティブにクエリーされるテーブルに対して大きなメリットを提供することができます。Auto Optimizeは特に以下のシナリオで有効です。
- 数分のレーテンシーが許容できるストリーミングユースケース
- Delta Lakeに書き込む方法として
MERGE INTOが好ましいケース -
CREATE TABLE AS SELECTやINSERT INTOオペレーションが一般的に使用されるケース
Auto Optimizeの動作原理
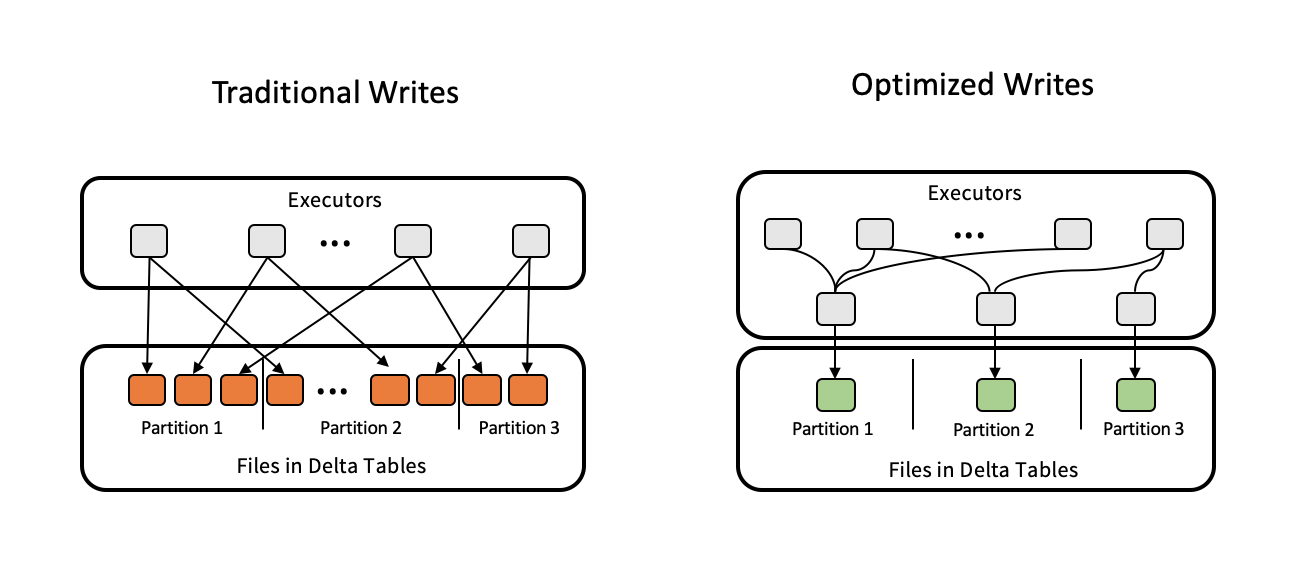
Auto Optimizeは補完し合う2つの機能で構成されます。最適化書き込みとオートコンパクションです。
最適化書き込みの動作原理
Databricksは実際のデータに基づきApache Sparkパーティションサイズを動的に最適化し、それぞれのテーブルパーティションに対して128MBのファイルを書き出そうとします。これは近似値のサイズであり、データセットの特性に応じて変動します。
オートコンパクションの動作原理
それぞれの書き込み処理の後、Databricksはファイルをさらにコンパクトにできないかをチェックし、小さいファイルの数が最も多いパーティションのファイルをコンパクトにするために(通常のOPTIMIZEでは1GBファイルが使用されますが、このケースでは128MBのファイルで)OPTIMIZEジョブを実行します。
Auto Optimizeの有効化
以下の方法のいずれかを用いて明示的に最適化書き込みとオートコンパクションを有効化する必要があります。
-
新規テーブル:
CREATE TABLEコマンドでテーブルプロパティdelta.autoOptimize.optimizeWrite = trueとdelta.autoOptimize.autoCompact = trueを設定します。SQL
CREATE TABLE student (id INT, name STRING, age INT) TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true, delta.autoOptimize.autoCompact = true)
```
-
既存テーブル:
ALTER TABLEコマンドでテーブルプロパティdelta.autoOptimize.optimizeWrite = trueとdelta.autoOptimize.autoCompact = trueを設定します。SQL
ALTER TABLE [table_name | delta.<table-path>] SET TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true, delta.autoOptimize.autoCompact = true)
```
-
全ての新規テーブル:
SQL
set spark.databricks.delta.properties.defaults.autoOptimize.optimizeWrite = true;
set spark.databricks.delta.properties.defaults.autoOptimize.autoCompact = true;
```
Databricksランタイム10.1以降では、テーブルプロパティdelta.autoOptimize.autoCompactはtrueとfalseに加えてautoとlegacyの値も受け付けます。auto(推奨)に設定すると、オートコンパクションはターゲットファイルサイズに32MBの設定を使用するなどより良いデフォルト値を使用します(しかし、デフォルトの挙動は将来変更される可能性があります)。legacyやtrueに設定するとオートコンパクションはターゲットファイルサイズとして128MBを採用します。
さらに、以下の設定でSparkセッションにおいてこれら両方の機能を有効化、無効化することができます。
spark.databricks.delta.optimizeWrite.enabledspark.databricks.delta.autoCompact.enabled
セッション設定はテーブルプロパティより優先されるので、これらの機能のオプトイン、オプトアウトを容易にコントロールすることができます。
いつ有効化・無効化すべきか
このセクションでは、Auto Optimize機能をいつオプトインし、いつオプトアウトすべきかについてのガイドを提供します。
最適化書き込みを有効化すべき時
最適化書き込みは、ストレージサービスに書き込まれるデータのスループットを最大化すること狙いとしています。これは、大量の並列性を犠牲にすることなしに、書き込まれるファイルの数を削減することで実現されます。
最適化書き込みには、ターゲットテーブルのパーティション構造に応じたデータのシャッフルが必要となります。このシャッフルは通常追加のコストを引き起こします。しかし、書き込みにおけるスループットの改善はシャッフルのコストに見合うものといえます。そうでない場合でも、データをクエリーする際のスループット改善はこの機能を価値あるものにしています。
最適化書き込みのキーとなる部分は、これが適応性シャッフルであるということです。ストリーミングのデータ取り込みのユースケースである場合、そして時間ごとにデータの量が変化する場合、適応性シャッフルはマイクロバッチごとの流入データレートに応じて自身を調整します。ストリームに書き出す前にcoalesce(n)やrepartition(n)をおこなっているコードがあるのであれば、これらの行を削除することができます。
有効化すべき時
- 数分のレーテンシーが許容されるストリーミングユースケース
-
MERGE、UPDATE、DELETE、INSERT INTO、CREATE TABLE AS SELECTのようなSQLコマンドを使う場合
無効化すべき時
- 書き込むデータがテラバイト規模であり、ストレージ最適化インスタンスが利用できない場合
- スポットインスタンスを使用しているがスポット価格が安定せず、ノードの大部分が失われる場合
オートコンパクションを有効化すべき時
オートコンパクションはテーブルへの書き込みが成功した後に動作し、書き込みを実行したクラスターで同期的に実行されます。これは、オートコンパクションを有効化した際、Delta Lakeへの書き込み後、即座にOPTIMIZEを呼び出しているようなコードパターンがある場合にはこのOPTIMIZE呼び出しを削除することができることを意味します。
オートコンパクションはOPTIMIZEとは違うヒューリスティックスを使用します。書き込み後に同期的に実行されるので、以下の特性を持つようにオートコンパクションをチューニングしています。
- Z-Orderingは単なるコンパクションよりも非常に大きなコストを要するので、オートコンパクションではZ-Orderingをサポートしていません。
- オートコンパクションは
OPTIMIZE(1GB)よりも小さいファイル(128MB)を生成します。 - オートコンパクションはコンパクションを最大限活用できるように、貪欲に限定されたパーティションのセットを選択します。選択されるパーティションの数は起動されたクラスターのサイズに応じて変動します。クラスターに多くのCPUがあるほど、多くのパーティションが最適化されます。
- 出力ファイルサイズを制御するには、Spark設定で
spark.databricks.delta.autoCompact.maxFileSizeを指定します。デフォルトは128MBを意味する134217728です。104857600を設定すると100MBとなります。
有効化すべき時
- 数分のレーテンシーが許容されるストリーミングユースケース
- テーブルに対して定期的に
OPTIMIZEを実行していない場合
無効化すべき時
他のwriterがDELETE、MERGE、UPDATE、OPTIMIZEのようなオペレーションを同時に実行する可能性がある場合。オートコンパクションはそれらのジョブとトランザクション競合を引き起こす場合があります。トランザクション競合でオートコンパクションが失敗する場合、Databricksはコンパクションの失敗、リトライは行いません。
サンプルワークフロー: 同時実行のdelete/updateを用いたストリーミングによるデータ取り込み
このワークフローでは、24/7でデータを取り込むストリーミングジョブを実行するクラスターが1台あり、レコードのバッチを1時間周期、1日周期あるいはアドホックで削除、更新する1台のクラスターがあることを想定しています。このユースケースにおいては以下を推奨します。
-
以下を用いて、テーブルレベルでの最適化書き込みを有効化します。
SQL
ALTER TABLE SET TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true)
```
これによって、ストリーム、削除、更新ジョブによって書き込まれるファイルの数を最適なサイズにすることができます。
-
以下の設定を用いて、削除、更新を行うジョブのセッションレベルでのオートコンパクションを有効化します。
Scala
spark.sql("set spark.databricks.delta.autoCompact.enabled = true")
これによって、お使いのテーブルのファイルがコンパクトにされます。これは削除、更新後に実行されるのでトランザクション競合のリスクを低減することができます。
# FAQ
## Auto OptimizeはZ-Orderを行いますか?
Auto Optimizeは小規模ファイルに対してのみコンパクションを実行します。ファイルの[Z-Order](https://qiita.com/taka_yayoi/items/a82b0b8fbdc74e6f9f01#z-ordering%E5%A4%9A%E6%AC%A1%E5%85%83%E3%82%AF%E3%83%A9%E3%82%B9%E3%82%BF%E3%83%AA%E3%83%B3%E3%82%B0)は実行しません。
## Auto OptimizeはZ-Orderされたファイルを改変しますか?
Auto OptimizeはZ-Orderされたファイルを無視します。新規ファイルのみをコンパクトにします。
## ストリーミングを行うテーブルに対してAuto Optimizeを有効化している場合、同時実行のトランザクションが最適化処理と競合する場合、ジョブは失敗しますか?
いいえ。Auto Optimizeが失敗となるトランザクション競合は無視され、ストリーム処理は通常通り継続されます。
## テーブルでAuto Optimizeが有効化されているテーブルに対して`OPTIMIZE`ジョブをスケジューリングする必要がありますか?
10TB以上のサイズのテーブルに対しては、ファイルをさらに統合し、Deltaテーブルのメタデータを削減するために`OPTIMIZE`のスケジュール実行を継続することをお勧めします。Auto OptimizeはZ-Orderingをサポtーしていないので、定期的に`OPTIMIZE ... ZORDER BY`ジョブを実行するようにスケジューリングすべきです。
## 小さいファイルが大量に存在しています。なぜAuto Optimizeはこれらをコンパクションしないのですか?
デフォルトでは、Auto Optimizeはディレクトリに50以上の小さいファイルができるまでコンパクションを開始しません。この挙動は`spark.databricks.delta.autoCompact.minNumFiles`で変更できます。データスキッピングが有効に動作し、マージや削除の間の再書き込みを最小化すれば、大量の小さいファイルが常に問題になるわけではありません。しかし、あまりにも大量の小規模ファイルは過剰なパーティショニングのサインかもしれません。
### Databricks 無料トライアル
[Databricks 無料トライアル](https://databricks.com/jp/try-databricks)