こちらの記事のようになんとなく使い続けていますが、思った以上に便利なのがDatabricks SDKです。Python、Java、Go、R向けのものが提供されています。
サンプルはこちらが豊富です。ライブラリ自体はPyPIで公開されています。
Databricks SDKを活用することで、Python、Java、Go、Rといったプログラミング言語から直接Databricksを操作することができます。これは自動化に活用できる相当に強力な機能です。上述の記事でも、手動ではなくPythonからジョブを構成しています。そして、このSDKはDatabricksからの利用にとどまらず、ローカルマシンからも活用することができます。
あと、使いこなす際にはマニュアルは必須です。どのDatabricksオブジェクトをどのように操作するのかが網羅されています。
ここではDatabricks環境からPython SDKをウォークスルーします。
ワークスペースのクラスターの一覧
ローカルから実行する際にはライブラリのインストールが必要ですが、Databricksワークスペースで実行する際にはすぐにSDKを利用できます。
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
for c in w.clusters.list():
print(c.cluster_name)
:
:
Takaaki Yayoi's 16.0 ML Cluster
Takaaki Yayoi's 16.0 ML Single Node GPU Cluster
Takaaki Yayoi's Cluster
ファイルシステムへのアクセス
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
d = w.dbutils.fs.ls('/')
for f in d:
print(f.path)
dbfs:/FileStore/
dbfs:/Users/
dbfs:/Volume/
dbfs:/Volumes/
dbfs:/Workspace/
dbfs:/cluster-logs/
dbfs:/databricks-datasets/
dbfs:/databricks-results/
:
クラスターの作成
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
print("Attempting to create cluster. Please wait...")
c = w.clusters.create_and_wait(
cluster_name = 'my-cluster',
spark_version = '12.2.x-scala2.12',
node_type_id = 'i3.xlarge',
autotermination_minutes = 15,
num_workers = 1
)
print(f"The cluster is now ready at " \
f"{w.config.host}#setting/clusters/{c.cluster_id}/configuration\n")
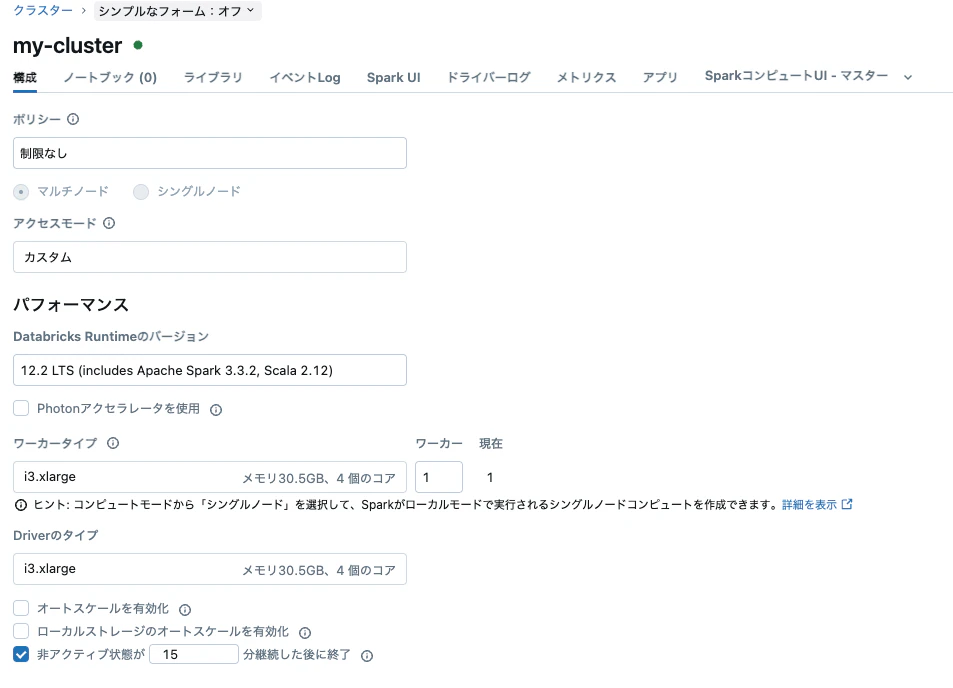
こちらを実行するとクラスター作成がスタートします。

クラスターが起動しました!
ジョブの作成
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.jobs import Task, NotebookTask, Source
w = WorkspaceClient()
job_name = input("ジョブの短い名前 (例: my-job): ")
description = input("ジョブの短い説明 (例: My job): ")
existing_cluster_id = input("ワークスペース内の既存クラスターのID (例: 1234-567890-ab123cd4): ")
notebook_path = input("実行するノートブックのワークスペースパス (例: /Users/someone@example.com/my-notebook): ")
task_key = input("ジョブのタスクに適用するキー (例: my-key): ")
print("ジョブの作成を試みています。お待ちください...\n")
j = w.jobs.create(
name = job_name,
tasks = [
Task(
description = description,
existing_cluster_id = existing_cluster_id,
notebook_task = NotebookTask(
base_parameters = dict(""),
notebook_path = notebook_path,
source = Source("WORKSPACE")
),
task_key = task_key
)
]
)
print(f"ジョブを表示 {w.config.host}/#job/{j.job_id}\n")
質問に答えていくとジョブが作成されます。
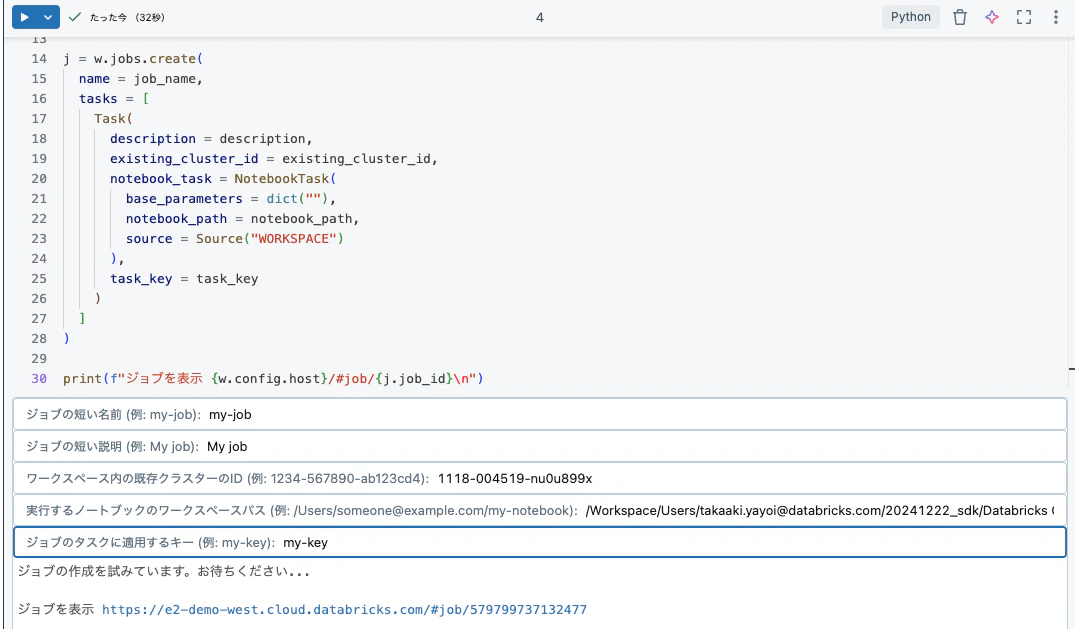
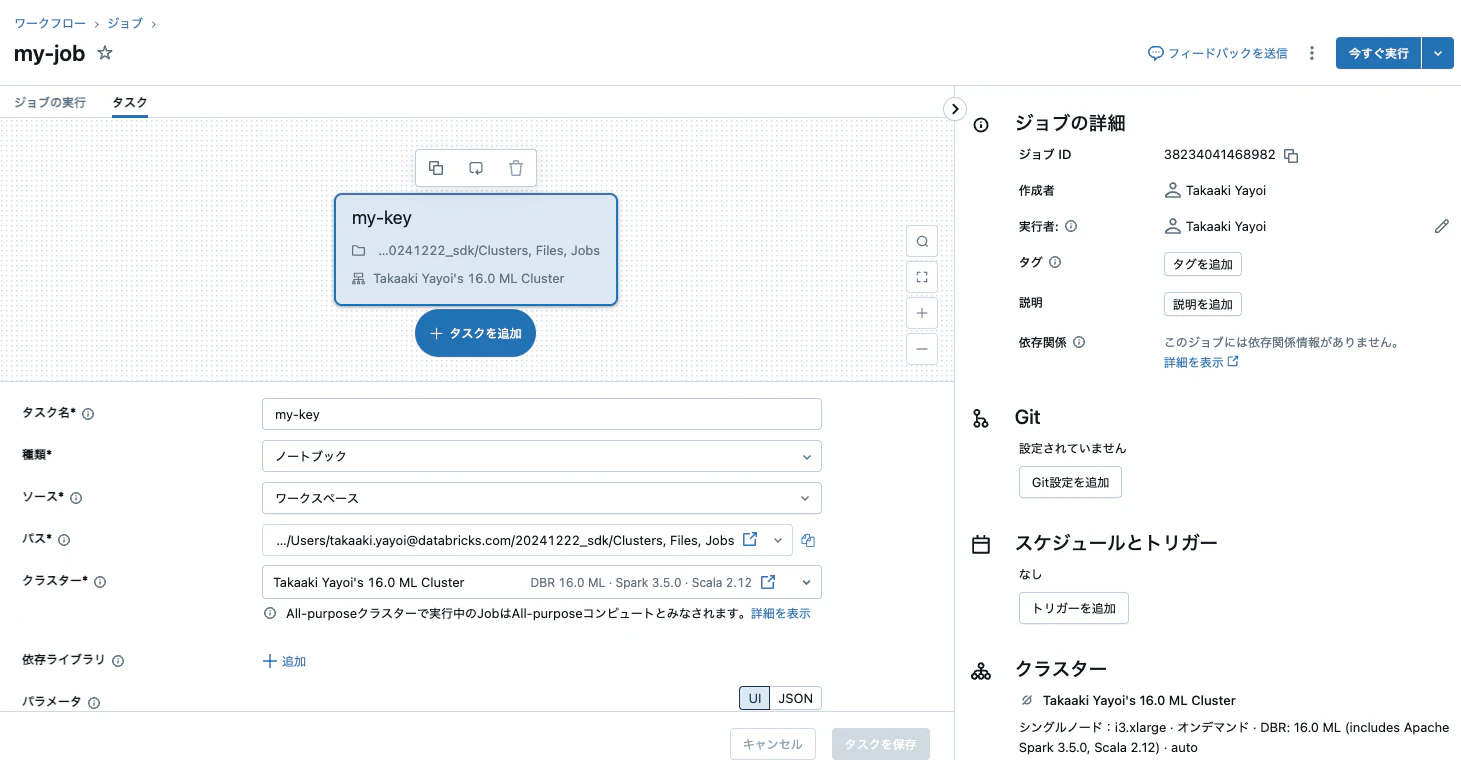
指定された内容でジョブが作成されました。
ボリュームの操作
Databricksにおけるファイル格納場所であるボリュームもSDKで操作できます。ここでは、catalog、schema、volumeが作成済みのものとします。また、upload_file_pathにファイルが存在していることを前提としています。
from databricks.sdk import WorkspaceClient
import io
w = WorkspaceClient()
# ボリューム、フォルダー、およびファイルの詳細を定義します。
catalog = 'users'
schema = 'takaaki_yayoi'
volume = 'data'
volume_path = f"/Volumes/{catalog}/{schema}/{volume}"
volume_folder = 'my-folder'
volume_folder_path = f"{volume_path}/{volume_folder}"
volume_file = 'data.csv'
volume_file_path = f"{volume_folder_path}/{volume_file}"
upload_file_path = "/Workspace/Users/takaaki.yayoi@databricks.com/20241222_sdk/japan_cases_20220818.csv"
# ボリュームに空のフォルダーを作成します。
w.files.create_directory(volume_folder_path)
# ボリュームにファイルをアップロードします。
with open(upload_file_path, 'rb') as file:
file_bytes = file.read()
binary_data = io.BytesIO(file_bytes)
w.files.upload(volume_file_path, binary_data, overwrite = True)
# ボリュームの内容を一覧表示します。
for item in w.files.list_directory_contents(volume_path):
print(item.path)
# ボリューム内のフォルダーの内容を一覧表示します。
for item in w.files.list_directory_contents(volume_folder_path):
print(item.path)
# ボリューム内のファイルの内容を表示します。
resp = w.files.download(volume_file_path)
print(str(resp.contents.read(), encoding='utf-8'))
# ボリュームからファイルを削除します。
w.files.delete(volume_file_path)
# ボリュームからフォルダーを削除します。
w.files.delete_directory(volume_folder_path)
/Volumes/users/takaaki_yayoi/data/access.log
/Volumes/users/takaaki_yayoi/data/client_hostname.csv
/Volumes/users/takaaki_yayoi/data/covid_cases.csv
/Volumes/users/takaaki_yayoi/data/japan_cases_20220818.csv
/Volumes/users/takaaki_yayoi/data/covid_cases/
/Volumes/users/takaaki_yayoi/data/my-folder/
/Volumes/users/takaaki_yayoi/data/my-folder/data.csv
Prefecture,Cases,date_parsed
ALL,1,2020-01-16T00:00:00.000Z
ALL,0,2020-01-17T00:00:00.000Z
ALL,0,2020-01-18T00:00:00.000Z
Databricksは基本的にコードファーストです。AutoMLやGenieのようなGUIフレンドリーの機能を提供してますが、背後には必ずコードで活用できるようにするという哲学があります。
GUIでの操作は簡単ではありますが、それを実環境に乗せようとすると途端にバージョン管理や再現性の問題に直面します。なので、Databricksではいかなる物事もコードで制御できるようにすることが徹頭徹尾考慮されています。このSDKもDatabricksの環境自体をコードでコントロールできるようにする強力なツールとなっており、マウスやキーボードを用いたDatabricksにおける手作業をほとんどカバーしています(クリーンルームやDelta Live Tables、Delta Sharing、Databricks SQLも対応しています!)。このSDKはまさにDatabricksの哲学を具現化するものだと個人的には考えています。効率化、自動化においては非常に強力な武器となりますので、是非ご活用ください!