以前こちらの会社ブログを執筆しました。
実際にDatabricksを利用されているJapan Digital Design株式会社においても、こちらの並列処理の機能を活用して、さまざまな機械学習モデルのトレーニングの処理を並列化することで、使用計算資源の最適化、全体的な処理に要する時間の削減を実現されています。
こちらの記事を書いておいてなんですが、「具体的にこれを実装するにはどうしたらいいのか」と思い立ちました。
マルチタスクジョブで並列処理をGUIから作成することはできますが、このタスクが数十になると手動で作成するのが手間です。ここでは、Databricks SDK for Pythonを活用します。
Databricks SDK for Pythonとは
名前の通り、Pythonから直接DatabricksのリソースをコントロールできるSDKです。プロダクション用途でご利用いただけますがベータ版です。
ドキュメントはこちら。SDKを使う際にはこちらのリファレンスが欠かせません。
やりたいこと
ある機械学習モデルをトレーニングするノートブックで、あるパラメータを変えながらトレーニングをしたいのですが、この処理を並列化したいものとします。こちらのノートブックの簡素版です。そして、並列処理の前処理、後処理のためのノートブックも実行できるようにします。
import mlflow
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.metrics
import sklearn.model_selection
import sklearn.ensemble
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK
from hyperopt.pyll import scope
# データのロードと前処理
white_wine = pd.read_csv("/dbfs/databricks-datasets/wine-quality/winequality-white.csv", sep=';')
red_wine = pd.read_csv("/dbfs/databricks-datasets/wine-quality/winequality-red.csv", sep=';')
white_wine['is_red'] = 0.0
red_wine['is_red'] = 1.0
data_df = pd.concat([white_wine, red_wine], axis=0)
# ワイン品質に基づいた分類ラベルの定義
data_labels = data_df['quality'] >= 7
data_df = data_df.drop(['quality'], axis=1)
# 80/20でトレーニング/テストデータセットを分割
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data_df,
data_labels,
test_size=0.2,
random_state=1
)
# このノートブックでのMLflow autologgingを有効化
mlflow.autolog()
ジョブでパラメータを受け取れるように、dbutils.widgets.getを使ってエスティメータの数を受け取ります
# ジョブパラメータとしてn_estimatorsを受け取ります
n_estimators_para = dbutils.widgets.get("n_estimators")
# 新たなランをスタートし、後でわかるようにrun_nameを割り当てます
with mlflow.start_run(run_name=f'gradient_boost_{n_estimators_para}') as run:
model = sklearn.ensemble.GradientBoostingClassifier(
random_state=0,
# n_estimatorsで新たなパラメータ設定をトライします
n_estimators = int(n_estimators_para),
)
model.fit(X_train, y_train)
predicted_probs = model.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
mlflow.log_metric("test_auc", roc_auc)
print("Test AUC of: {}".format(roc_auc))
SDKによるジョブの作成
新規にノートブックを作成してSDKをインストールします。
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
ライブラリのインポートやジョブで使用するノートブックを設定します。今回は前処理、後処理のノートブックではprintで文字列を表示しているだけですが、必要に応じて実装することも可能です。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.jobs import Task, NotebookTask, Source, TaskDependency
from databricks.sdk.service.compute import ClusterSpec, RuntimeEngine
w = WorkspaceClient()
job_name = "ML parallel tasks job"
start_task_description = "開始タスク"
execution_task_description = "並列で処理を行うタスク"
finish_task_description = "終了タスク"
# 既存クラスターを使用する場合にはクラスターIDを指定
existing_cluster_id = "1118-004519-nu0u899x"
# 開始ノートブック: 前処理などを記述
start_notebook_path = "/Users/takaaki.yayoi@databricks.com/20231210_workflow/start"
# 並列実行するノートブック
execution_notebook_path = "/Users/takaaki.yayoi@databricks.com/20231210_workflow/ml-quickstart-training-jpn"
# 終了ノートブック: 後処理などを記述
finish_notebook_path = "/Users/takaaki.yayoi@databricks.com/20231210_workflow/finish"
ジョブの作成時には既存のクラスターも指定できますが、そうすると並列化の意味がありません。ここでは、新規のジョブクラスターを作成するようにします。新規クラスターの指定に必要な情報を取得しておきます。
# ノードタイプ一覧
nodes = w.clusters.list_node_types()
nodes
ListNodeTypesResponse(node_types=[NodeType(node_type_id='r3.xlarge', memory_mb=31232, num_cores=4.0, description='r3.xlarge (deprecated)', instance_type_id='r3.xlarge', category='Memory Optimized', display_order=1, is_deprecated=True, is_encrypted_in_transit=False, is_graviton=False, is_hidden=True, is_io_cache_enabled=False, node_info=None, node_instance_type=NodeInstanceType(instance_type_id='r3.xlarge'...
select_spark_versionを使うと色々な条件でDatabricks Runtimeバージョンを表現する文字列を取得できます。クラスターのスペックの指定に必要になります。
# 最新MLランタイム
latest = w.clusters.select_spark_version(ml=True)
latest
'14.2.x-cpu-ml-scala2.12'
ここがキモです。Taskオブジェクトを組み立ててマルチタスクジョブを構成します。ジョブを作成する際にTaskオブジェクトのリストを渡すので、先頭の処理、並列の処理、最終の処理のタスクを結合していきます。注意しなくてはならないのはdepends_onのパラメータです。前段のどのタスクに依存するのかを指定するので、並列処理は先頭の処理、最終の処理は並列処理に依存するように指定する必要があります。タスク名を指定してもエラーになり、TaskDependencyオブジェクトとしてリストに追加する必要があります。
tasks = []
# 先頭タスクの追加
start_task = Task(
description = start_task_description,
existing_cluster_id = existing_cluster_id,
notebook_task = NotebookTask(
base_parameters = {},
notebook_path = start_notebook_path,
source = Source("WORKSPACE")
),
task_key = "start_task",
depends_on = []
)
tasks.append(start_task)
# 並列処理タスクの追加
parallel_tasks_list = []
for n_estimators in range(10, 60, 10):
print(n_estimators)
task_item = Task(
description = execution_task_description,
#existing_cluster_id = existing_cluster_id,
# 新規ジョブクラスター
# クラスターの設定方法は以下を参照
# https://databricks-sdk-py.readthedocs.io/en/latest/autogen/compute.html#databricks.sdk.service.compute.ClusterSpec
new_cluster = ClusterSpec(num_workers=1, spark_version=latest, node_type_id="i3.xlarge"),
notebook_task = NotebookTask(
base_parameters = {"n_estimators": n_estimators},
notebook_path = execution_notebook_path,
source = Source("WORKSPACE")
),
task_key = f"execution_task_{n_estimators}", # タスク名が重複しないようにパラメータを埋め込み
depends_on = [TaskDependency("start_task")]
)
tasks.append(task_item)
parallel_tasks_list.append(task_item)
# 依存関係を指定するためにtask_keyをTaskDependencyに変換してリストに格納
parallel_task_keys = []
for task in parallel_tasks_list:
parallel_task_keys.append(TaskDependency(task.task_key))
# 終了タスクの追加
finish_task = Task(
description = finish_task_description,
existing_cluster_id = existing_cluster_id,
notebook_task = NotebookTask(
base_parameters = {},
notebook_path = finish_notebook_path,
source = Source("WORKSPACE")
),
task_key = "finish_job",
depends_on = parallel_task_keys
)
tasks.append(finish_task)
# ジョブの作成
j = w.jobs.create(
name = job_name,
tasks = tasks
)
print(f"View the job at {w.config.host}/#job/{j.job_id}\n")
上のセルを実行すると、期待した通りにジョブが作成されます。おおー、すごい。
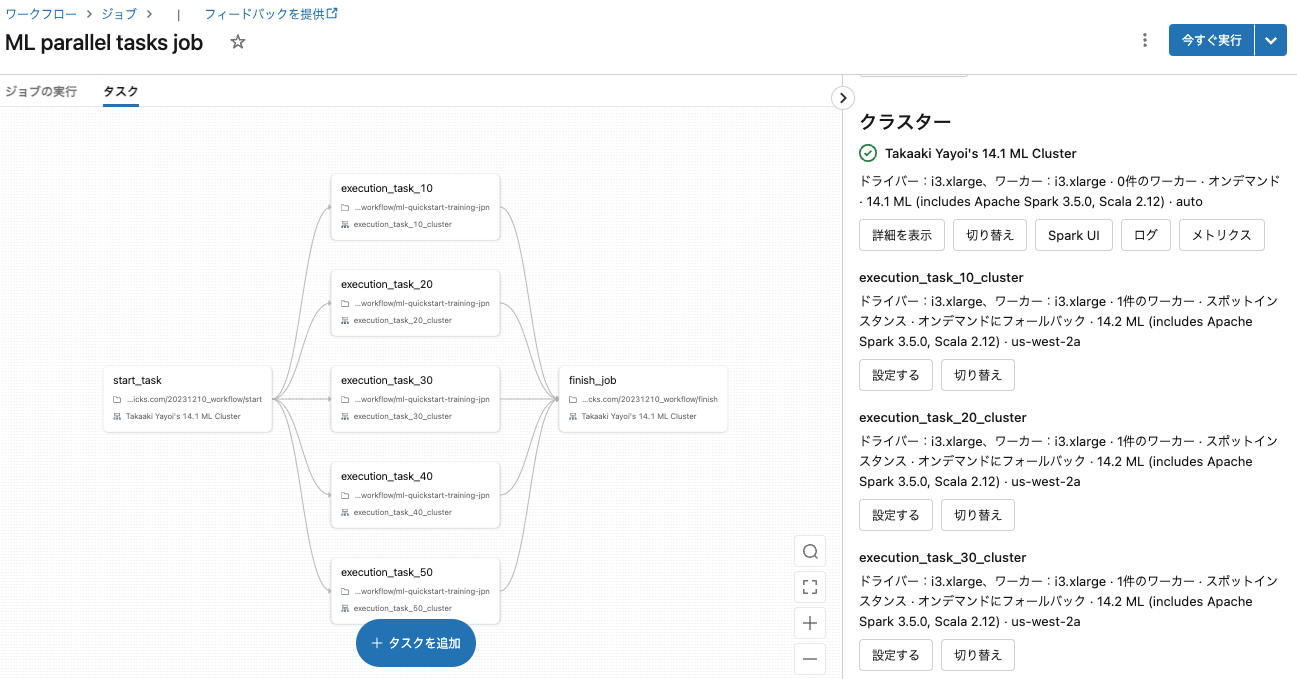
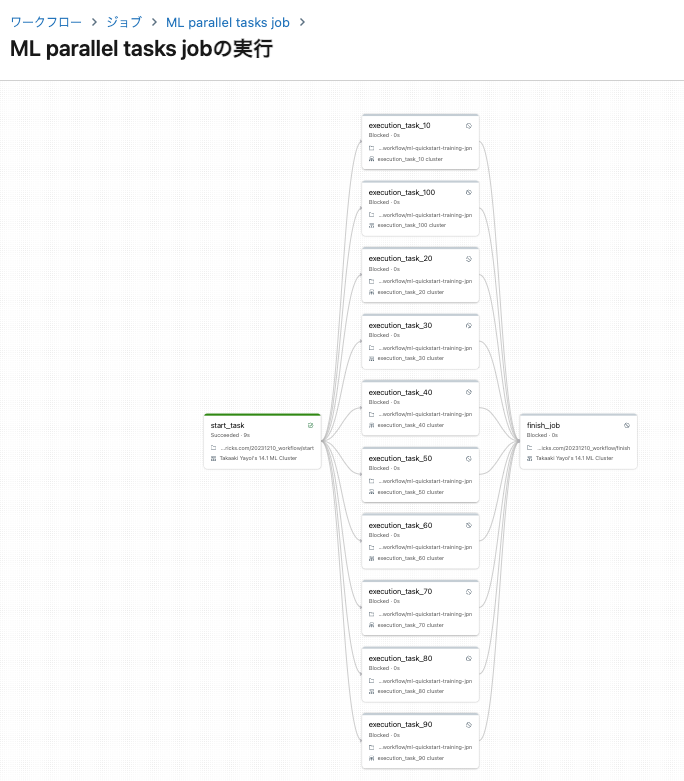
ジョブの実行
並列タスクのクラスターは分離されているのでリソースが競合することもありません。早速ジョブを実行します。

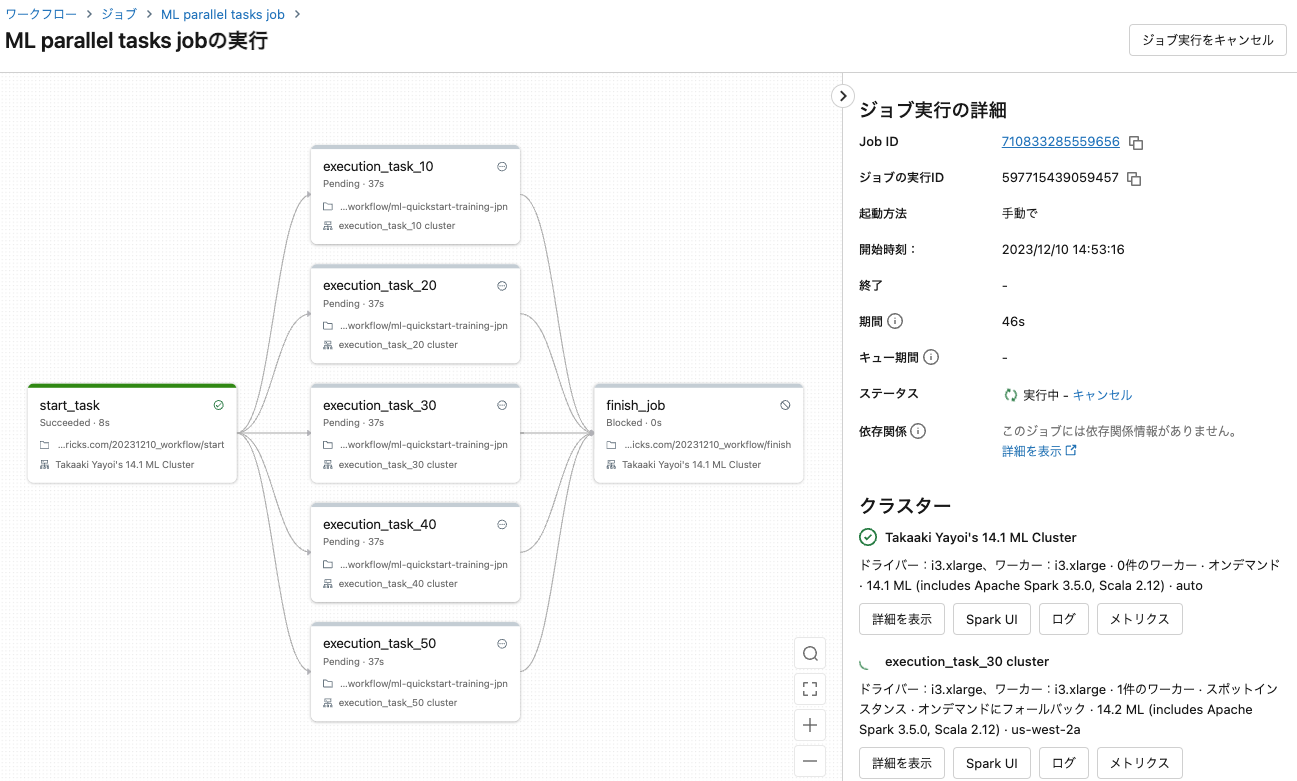
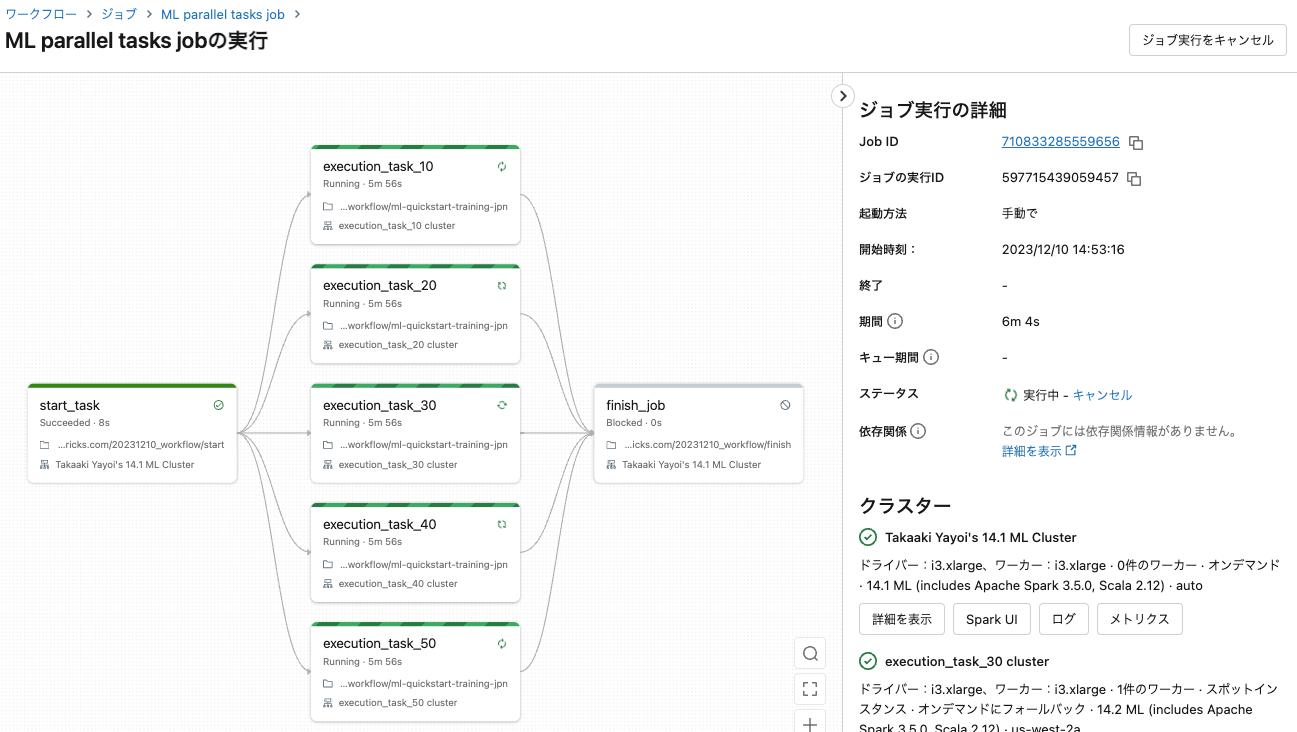
すべての並列タスクが完了してから最終タスクが実行されます。

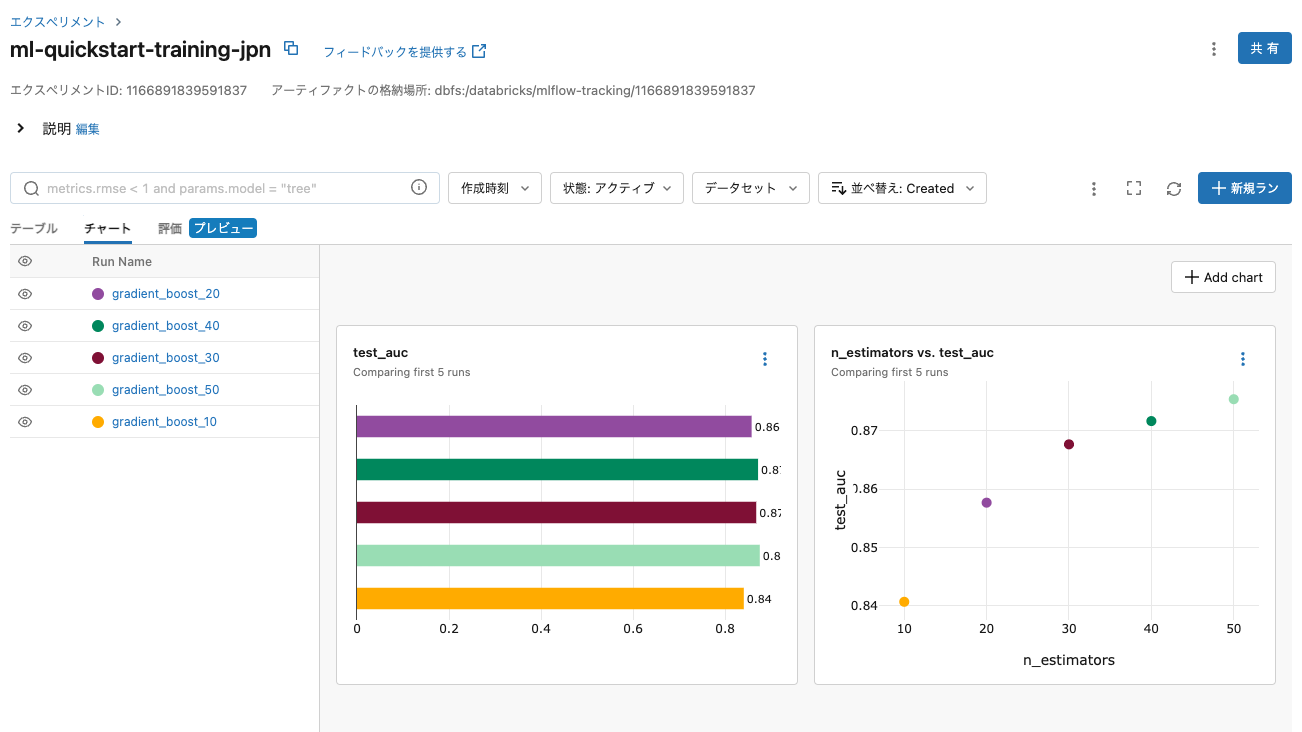
そして、並列実行にしようしたノートブックにアクセスします。上でトレーニングした機械学習モデルはMLflowによってトラッキングされているので、記録の手間を気にする必要がありません。

グラフを用いてモデルを簡単に比較することもできます。
このジョブはすべてをプログラムから作成しているので、ループの部分を変更すれば任意の並列度を達成することができます。
for n_estimators in range(10, 110, 10):
ジョブの作成においては、GUIとSDKを適材適所で活用いただけると良いかと思います。是非ご活用ください!
注意
こちらにあるように、ワークスペースにおける同時タスク実行数は1000に制限されていますのでご注意ください。