Snowflake Claims Similar Price/Performance to Databricks, but Not So Fast! - The Databricks Blogの翻訳です。
2021/11/2に、我々はレイクハウスプラットフォームのDatabricks SQLによって、最速のデータウェアハウスとして公式な世界記録を打ち立てたと発表しました。この結果は、tpc.orgからオンラインで参照できる37ページのドキュメントにあるように、公式なTransaction Processing Performance Council(TCP)によって監査、レポートされたものです。我々はまた、Databricks SQLがSnowflakeよりも高速でコスト効率が高いことを示すBarcelona Supercomputing Center (BSC)によるサードパーティによるベンチマークも共有しました。
それ以来、多くのことがおきました。多くの祝福、いくつかの質問、そしていくつかの酸っぱい葡萄です。我々これを、Databricks SQLは、データウェアハウスワークロード(TCP-DS)においても、Snowflakeよりも優れた性能、そしてコストパフォーマンスを提供するという、我々のブログ記事と結果を支持する立場を再度主張する機会と考えました。
Snowflakeの反応:「完全性の欠如」?
Snowflakeは、我々の発表から10日後(先週の金曜日)に我々の結果には「完全性(integrity)が欠如している」という声明を発表しました。そして、彼らは彼らの製品はDatabrciks SQLの242ドルとほぼ同じ267ドルという価格で同様のパフォーマンスを達成するという、彼ら自身のベンチマークを発表しました。額面においては、彼らはDatabricks SQLの最も高い価格帯と、彼らの最も安価な価格帯を比較しているという事実を無視しています。(Snowflakeの「Business Critical」ティアは、最も安価なティアの2倍のコストであることに注意が必要です)また、彼らは、多くのお客様が使用しており、コストを146ドルまで削減できるスポットインスタンスをDatabricksで利用できるという事実もごかましています。しかし、これのどれもこの記事ではフォーカスされていません。
Snowflakeの主張の骨子は、彼らはBSCと同じベンチマークを実行し、BSCが計測した8,397秒ではなく3,760秒で全てのベンチマークを実行できたというものでした。また、彼らは読者に対してサインアップして、自身で確かめて欲しいと促してすらいます。いずれにしても、SnowflakeにTCP-DSデータセットは付属しておりすぐに利用可能であり、どのように実行するのかのチュートリアルもありました。このため、結果を検証することは簡単であるに違いありません。我々はまさにそれを行いました。
まず初めに、先人に従い、自身のプラットフォームでベンチマークを禁じるDeWitt条項を削除したSnowflakeに感謝の意を評します。このおかげで、我々はトライアルアカウントを取得でき、「完全性の欠如」の主張のベースを検証することができました。
SnowflakeにおけるTCP-DSの再現
我々はSnowflakeにログインし、TCP-DSのTutorial 4を実行しました。実際のところ、結果は彼らが主張した4,025秒に近いものであり、BSCベンチマークにおける8,397秒よりもはるかに早いものでした。しかし、次に明らかになったことは非常に興味深いことでした。
ベンチマークを実行している間、我々は、我々のベンチマークの発表の2日後にSnowflakeによる事前準備されたTCP-DSのデータセットが再作成されたことに気づきました。公式なベンチマークの重要なところは、データセット作成を検証することです。このため、Snowflakeによって準備されたデータセットを用いる代わりに、我々は公式のTCP-DSのデータセットをアップロードし、Snowflakeが事前準備済みデータセット(同じクラスタリングカラムセットを含みます)と用いているのと同じスキーマ、同じクラスターサイズ(4XL)を使用しました。そして、POWERテストを3回実行し、時間を計測しました。最初のコールドランは10,085秒かかり、3回の実行における最速なものは7,276秒かかりました。繰り返しになりますが、我々は公式なTCP-DSデータセットをSnowflakeにロードし、POWERテストを実行するのにどのくらいかかるのかを計測し、それはSnowflakeがブログで報告したものより1.9倍(3つの中で最速のもの)かかりました。
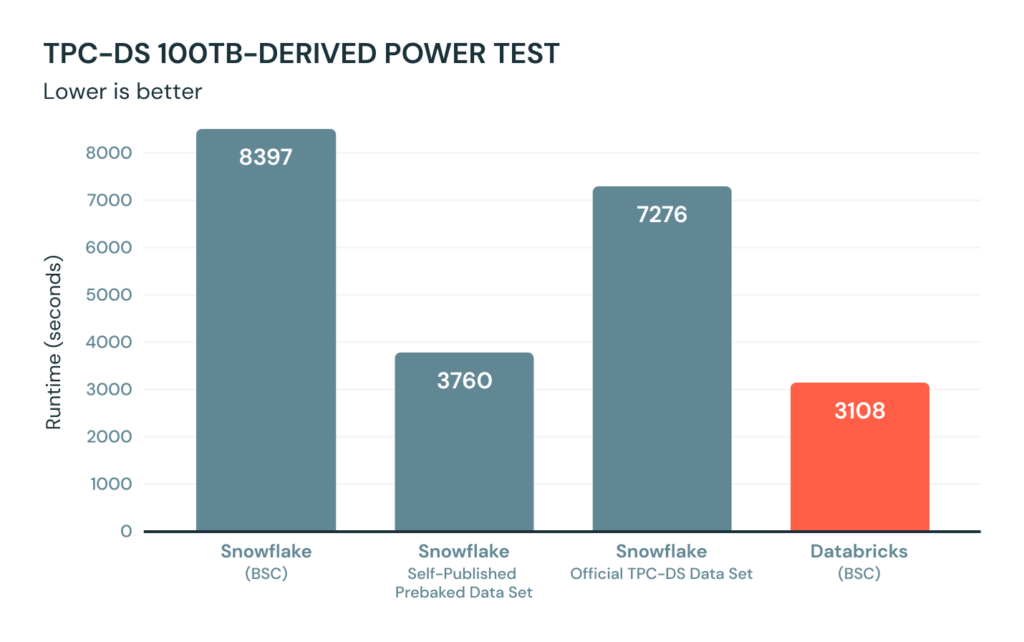
この結果は誰でも容易に検証できます。Snowflakeアカウントを取得し、100TBデータウェアハウスを生成するための公式のTCP-DSスクリプトを使用します。そして、いくつかのPOWERランを実行し、自身で時間を計測します。7000秒に近い結果になることは間違いありません。そして、彼らのクラスタリングカラムを使わない場合にはさらに長い時間になることでしょう(次のセクションをご覧ください)。また、Snowflakeに同梱されているデータセットでPOWERテストを実行することができます。この結果は、彼らのブログでレポートされた時間に近いものになることでしょう。
なぜ公式のTCP-DSなのか
なぜ、Snowflakeで準備されているTCP-DSを実行した際と、公式なデータセットをSnowflakeにロードした際の結果に大きな相違があるのでしょうか?正確なことは我々も知りません。しかし、データをどのようにレイアウトするのかはTCP-DS、そして一般的には、全てのワークロードに大きな影響を与えます。多くのシステムにおいては、特定のワークロードに対するデータのクラスタリングやパーティショニングはその特定のワークロードのパフォーマンスを改善しますが、そのような最適化は追加のコストを必要とします。このような時間、労力はベンチマークの結果に含まれるべきです。
これが公式なベンチマークにおいては、レイアウトを最適化するのにシステムが要したあらゆる時間とコストを適切に考慮できるように、データウェアハウスにデータをロードするのに要した時間のレポートを求めている理由です。いくつかのストレージスキーマにおいては、この時間はPOWERテストクエリーよりもはるかに大きなものとなります。また、公式なベンチマークには、実世界におけるデータセットやワークロードと同様にデータの更新、メンテナンスも含まれます(変化しないデータセットに対してどのくらいの頻度でクエリーを行いますか?)。これはすべて、以下のようなシナリオを防ぐために行われます:不変な一連のワークロードに対する静的なデータセットをオフラインで最適化するのにシステムが膨大なリソースを費やして、これらのワークロードを非常に高速に処理する。
さらに、公式なベンチマークでは再現性が求められます。このため、我々の記録を再現するために必要なコードをsubmissionから確認することができます。
このことは、我々の最後のポイントにつながります。ベンチマークはすぐに業界のプレーヤーによる「設定のノブ、特別な設定、ベンチマークを改善しうる特別な最適化の追加」に委ねられるという点に関しては、Snowflakeに同意します。誰でも自身のベンチマークでは本当によく見えるものです。このため、自身がどのようにうまくやっているのかというベンダーの言葉を受け取るのではなく、我々はSnowflakeに対して公式なTCPベンチマークに参加することを求めます。
顧客視点でのベンチマーク
このベンチマークに参加すると決定した際、我々は過去のエントリーとは異なり、現実的に全てのお客様で行われている一般的な最適化のみを用いるべきと、我々のエンジニアチームに制約を設けました。彼らは、(Snowflakeの事前準備済みデータセット、追加のクラスタリングカラムとは異なり)データセットやクエリーに対する深い理解を必要とする最適化を適用することは許されませんでした。これは、現実世界のワークロードと合致し、多くのお客様が見たいと考えるもの(チューニングなしにシステムが優れたパフォーマンスを達成すること)です。
我々の提出内容を詳細に読んでいただければ、再現可能なステップが典型的なユーザーがデータを管理したいと考える方法とマッチしていることがわかることでしょう。新規データセットに対する生産性改善に要する労力の最小化が、Databricks SQLのデザイン上の最優先の目標となっています。
まとめ
Databricksからの最後の言葉となります。共同創始者として、我々はお客様に対して最高の価値を提供することと、我々が開発するソフトウェアがお客様のビジネスニーズを解決することに関して、深い注意を払っています。世界に対する我々の理解と共鳴しないベンチマーク結果は、感情的あるいは本能的な反応を引き起こすことでしょう。我々はそのようなことが起きないように努力しています。我々は真実を探求しており、検証可能なエンドツーエンドの結果を公表しています。我々は、Snowflakeが彼らのブログで公表した結果に完全性が欠如していることを告発しようとは思いません。我々は単に彼らに公式なTCPカウンセルによる結果検証をお願いしたいだけです。
TPCデータウェアハウスベンチマークに参加した我々の主たるモチベーションは、どのデータウェアハウスが早いか安いかを証明したいことではありませんでした。むしろ、FAANG企業のようにすべての企業がデータドリブンになるべきだと信じています。これらの企業はデータウェアハウスに依存していません。そうではなく、よりシンプルなデータ戦略を持っています。全てのデータ(構造化、テキスト、動画、音声)をオープンフォーマットで蓄積し、データサイエンス、機械学習、リアルタイム分析、古典的なビジネスインテリジェンスやデータウェアハウスなど、あらゆる種類の分析に対して単一のコピーを使用します。SQLだけで、これらすべてを行いません。むしろ、データを活用するオープンソースエコシステムにおける数多くのツール、Python、Rと共に、SQLは彼らの武器の中のキーとなるツールとなります。我々はこのパラダイムをデータレイクハウスと呼びます。データレイクハウスはデータウェアハウスと異なり、データサイエンス、機械学習、リアルタイムストリーミングに対するネイティブサポートを提供します。しかし、SQL、BIに対するネイティブサポートも提供します。我々のゴールは、データレイクハウスはベストな価格とパフォーマンスを持ち得ないという通念を打ち払うことです。我々自身でベンチマークを行うのではなく、我々は現実を探求し、公式なTCPベンチマークに参加しました。これによって、データレイクハウスパラダイムが、古典的なデータウェアハウスワークロード(TCP-DS)においても、データウェアハウスよりも優れた性能、価格を提供できることを示せて非常に嬉しく思っています。これによって、全てのデータを管理するために、複数のデータレイク、データウェアハウス、ストリーミングシステムを維持管理する必要がなくなる企業にメリットを提供します。このシンプルなアーキテクチャによって、彼らが毎日直面しているビジネスニーズと問題を解決するために彼らのリソースを再配置することが可能となります。