Databricks公式ブログで紹介されている Many Model Forecasting(MMF) を触ってみました。正確には、ブログ記事 Databricksにおけるマルチモデル予測のためのフレームワーク を読んで「便利そう」と思い、サンプルノートブックを回し、結果のテーブルを前にして「で、これをどう読めばいいんだ」と詰まった、というのがスタート地点です。
動かすまでは比較的素直なのに、動かした後の「これで何が嬉しいのか」を説明する公式ドキュメントがdaily前提では不足しているので、1から順番に紐解いてみました。この記事では、1系列に複数モデルを当てる基本形から出発して、多系列×多モデルの結果を解釈するところまでを通しで歩きます。
MMFを一言で
多数の時系列に対して多数の予測モデル(古典統計、深層学習、時系列基盤モデル)を横並びで適用し、系列ごとの最適モデル選定を可能にする評価基盤
ここで重要なのは、MMFは「予測を出してくれる魔法の箱」ではなく「評価基盤」であるという点です。予測を意思決定に変える後工程は利用者側で組む必要があるという性格が、最初に見えていないと「何が嬉しいのか分からない」状態になりやすいです。
ゴール: 3段階で価値を体感する
この記事では以下3段階で進めます。
- Part 1: まず1本の時系列に複数モデルを当てて可視化する(MMF不要)
- Part 2: 同じ構造のデータが数千本あったら、という問題提起
- Part 3: MMFで多系列×多モデルを一括実行した結果を読む
MMFのリポジトリには examples/daily/local_univariate_daily.ipynb が同梱されていて、これを回せば run_forecast が走ってDeltaテーブルが生成されます。本記事のPart 3はその生成物を前提にしています。
Part 1: 1系列×5モデルの比較
まずはMMFなしで、単一の時系列に複数モデルを当てるところから始めます。pandasとstatsforecastだけで完結します。
使うデータはM4 Dailyのうち unique_id = "D1" の1本です。1,020点の日次データで、直近10日を予測ホライゾンに充てて、残り1,010点で学習します。
モデルは5つ並べる
from statsforecast import StatsForecast
from statsforecast.models import Naive, SeasonalNaive, AutoARIMA, AutoETS, AutoTheta
sf = StatsForecast(
models=[
Naive(),
SeasonalNaive(season_length=7),
AutoARIMA(season_length=7),
AutoETS(season_length=7),
AutoTheta(season_length=7),
],
freq="D",
n_jobs=1,
)
sf.fit(train[["unique_id", "ds", "y"]])
pred = sf.predict(h=10)
StatsForecastの models にリストで渡すだけで、5つのモデルを同時にfit/predictしてくれます。返ってくる pred は1つのDataFrameに各モデルの予測が列として並んだ形になっています。
予測 vs 実測
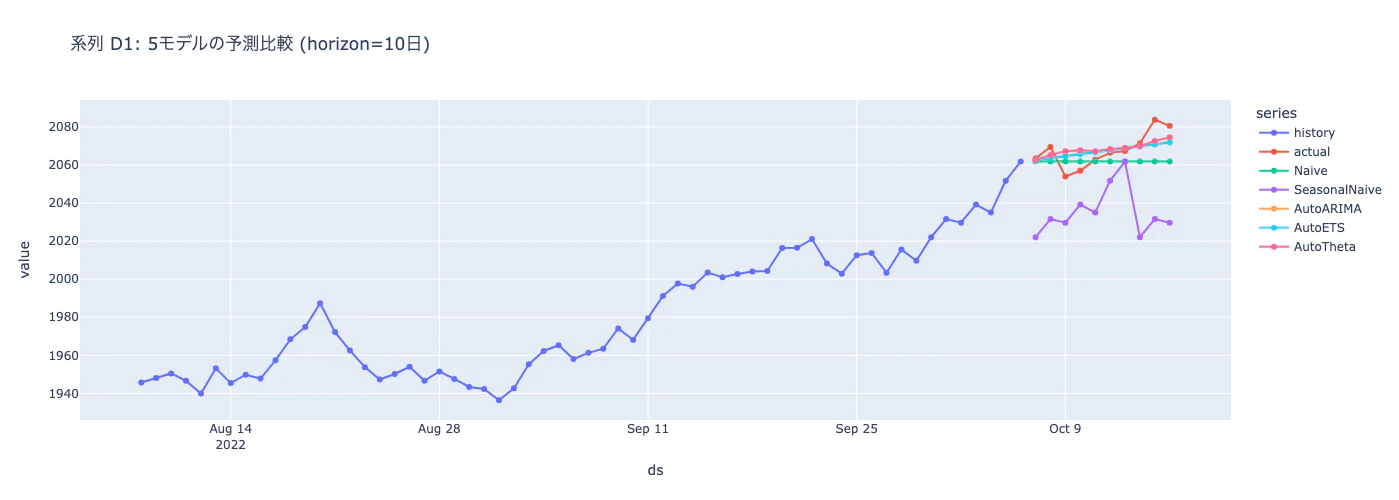
直近60日の履歴に対して、10日先の予測を各モデルで出したものを重ねています。モデルごとに予測線の形がはっきり違うことが見て取れます。
SMAPEでランキング
| model | smape |
|---|---|
| AutoTheta | 0.002697 |
| AutoARIMA | 0.002709 |
| AutoETS | 0.002709 |
| Naive | 0.004043 |
| SeasonalNaive | 0.015693 |
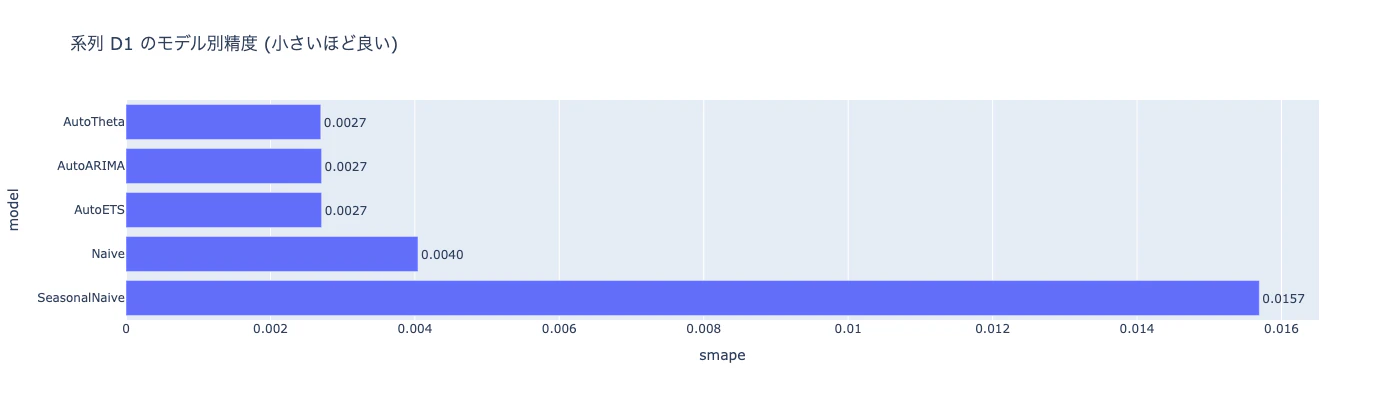
D1に関して言えば、AutoTheta/AutoARIMA/AutoETSの3つがほぼ団子で勝っていて、Naiveも意外と健闘、SeasonalNaiveだけ5〜6倍のズレという結果になりました。週次季節性が強くないデータでは、SeasonalNaiveは足を引っ張るということが見えます。
読み取れたこと
- 同じ時系列でも、モデルによってSMAPEが5倍以上違うことがあります
- どのモデルが勝つかは事前には分からない。当ててみて初めて分かります
- 1系列だけであれば、forループ相当の処理で十分扱えます
逆に言うと、1系列あたりの分析ではMMFは不要です。では、どこからMMFの出番になるのでしょうか。
Part 2: これが数千本あったら?
実務では、同じ構造の時系列が多数存在するケースが圧倒的に多くなります。
- 小売: 店舗 × SKUごとの日次売上(数十万〜数百万系列)
- 製造: 機材ごとのセンサー時系列(数千系列)
- エネルギー: 配電ノードごとの電力消費
- 物流: 倉庫 × 品目ごとの出荷数
ここで問題になるのは3点です。
- 系列ごとに最適なモデルが違う。Aは AutoARIMA、Bは Naive が勝つ、といった話
- アナリストが1本ずつモデル選定するのは非現実的
- 単純なforループでは時間がかかりすぎる。3,000系列 × 5モデル × 数秒 = 単一ノードでは数日
これを解決するのがMMFです。並列化の軸は時系列方向で、applyInPandas で各 unique_id を別workerに散らして fit/predict する構造になっています。ユーザーから見ると、run_forecast 関数を1回呼ぶだけで、評価結果と予測結果の2つのDeltaテーブルが自動生成されます。
Part 3: MMFの出力を読む
run_forecast を回した結果、以下2つのDeltaテーブルが生成されます(本記事ではM4 Dailyの99系列のうち、欠損のない28系列に対して、16モデルを全部当てた結果を使っています)。
-
daily_evaluation_output: バックテスト結果(2,688行) -
daily_scoring_output: 未来予測の結果(896行)
スキーマがややトリッキー
両テーブルのスキーマを見ると、すぐに配列型の列が混じっていることに気づきます。
daily_evaluation_output の主要列:
-
unique_id(string): 系列ID -
model(string): モデル名 -
backtest_window_start_date(timestamp): バックテストwindowの開始日 -
actual(array): 実測値の配列(このwindowぶん、長さ10) -
forecast(array): 予測値の配列(長さ10) -
metric_name,metric_value: 事前計算済みSMAPE
daily_scoring_output の主要列:
-
unique_id(string): 系列ID -
model(string): モデル名 -
ds(array): 予測対象日の配列(長さ10) -
y(array): 予測値の配列(長さ10)
注意点として、evaluation側は actual/forecast、scoring側は ds/y と名前が揃っていません。最初は戸惑いますが、「windowごとに1行にまとめた結果、配列として持っている」と理解すれば納得できる構造です。SMAPE計算やプロットを行うには、配列を展開する必要があります。

display(eval_df.limit(5)) で中身を見ると、actual と forecast がそれぞれ10要素の配列として入っていることが確認できます。
モデル全体ランキング
最初に見るべきは「全系列・全backtest windowの平均で、どのモデルが強いか」です。actual/forecastが配列なので、zip_with と aggregate を使って配列のままSMAPEを計算します。
WITH smape_per_window AS (
SELECT
unique_id,
model,
aggregate(
zip_with(actual, forecast, (a, f) ->
CASE
WHEN abs(a) + abs(f) = 0 THEN 0.0
ELSE 2.0 * abs(a - f) / (abs(a) + abs(f))
END
),
CAST(0.0 AS DOUBLE),
(acc, x) -> acc + x
) / size(actual) AS window_smape
FROM takaakiyayoi_catalog.m4.daily_evaluation_output
WHERE use_case = 'm4_daily'
)
SELECT
model,
ROUND(AVG(window_smape), 4) AS avg_smape,
COUNT(DISTINCT unique_id) AS n_series,
COUNT(*) AS n_windows
FROM smape_per_window
GROUP BY model
ORDER BY avg_smape ASC
結果はこうなりました。
| model | avg_smape | n_series | n_windows |
|---|---|---|---|
| StatsForecastAutoTbats | 0.0326 | 28 | 168 |
| StatsForecastAutoArima | 0.0334 | 28 | 168 |
| StatsForecastBaselineNaive | 0.0337 | 28 | 168 |
| StatsForecastAutoETS | 0.0345 | 28 | 168 |
| StatsForecastAutoTheta | 0.0346 | 28 | 168 |
| StatsForecastAutoCES | 0.0354 | 28 | 168 |
| StatsForecastADIDA | 0.0369 | 28 | 168 |
| StatsForecastCrostonOptimized | 0.0369 | 28 | 168 |
| StatsForecastIMAPA | 0.0369 | 28 | 168 |
| StatsForecastAutoMfles | 0.0373 | 28 | 168 |
| StatsForecastBaselineWindowAverage | 0.0390 | 28 | 168 |
| StatsForecastTSB | 0.0390 | 28 | 168 |
| StatsForecastBaselineSeasonalNaive | 0.0442 | 28 | 168 |
| StatsForecastCrostonClassic | 0.0484 | 28 | 168 |
| StatsForecastBaselineSeasonalWindowAverage | 0.0841 | 28 | 168 |
| StatsForecastCrostonSBA | 0.0856 | 28 | 168 |
168 = 28系列 × 6バックテストwindow です。backtest_length=30、stride=10、prediction_length=10 の設定で回しています。
ランキングの読み方
- AutoTbatsが全体1位で、AutoArimaとBaselineNaiveが僅差で続きます
- Naiveが3位に食い込んでいるのが地味に重要です。複雑なモデルが必ずしも勝つわけではないということが分かります
- Crostonの系列(間欠需要向けモデル)が軒並み下位に並んでいます。M4 Dailyは普通の時系列で、間欠需要ではないのでこれは当然の結果です
- Seasonal系(BaselineSeasonalNaive、BaselineSeasonalWindowAverage)が最下位クラスです。日次データで7日周期が弱い系列が混じっているとこうなります
ここで「じゃあAutoTbatsを全系列に使えばいいのでは?」と思うのが自然ですが、そうならないのが次のクエリのポイントです。
系列ごとのチャンピオンモデル
MMFの真価はここからです。各系列で、どのモデルが一番精度が良かったかを見ていきます。
WITH smape_per_window AS ( -- 同上 ),
per_series AS (
SELECT unique_id, model, AVG(window_smape) AS smape
FROM smape_per_window
GROUP BY unique_id, model
),
ranked AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY unique_id ORDER BY smape) AS rnk
FROM per_series
)
SELECT unique_id, model AS champion_model, ROUND(smape, 4) AS smape
FROM ranked
WHERE rnk = 1
ORDER BY unique_id
28系列ぶんの結果がこちらです(抜粋)。
| unique_id | champion_model | smape |
|---|---|---|
| D1 | StatsForecastAutoCES | 0.0039 |
| D11 | StatsForecastTSB | 0.0109 |
| D12 | StatsForecastAutoCES | 0.0128 |
| D13 | StatsForecastAutoArima | 0.0313 |
| D14 | StatsForecastAutoTbats | 0.0215 |
| D16 | StatsForecastBaselineWindowAverage | 0.0095 |
| D33 | StatsForecastBaselineSeasonalWindowAverage | 0.0217 |
| D34 | StatsForecastBaselineNaive | 0.0005 |
| D35 | StatsForecastCrostonSBA | 0.0239 |
| D44 | StatsForecastAutoTheta | 0.0076 |
| D7 | StatsForecastAutoArima | 0.2206 |
| D99 | StatsForecastAutoETS | 0.0269 |
ここがMMFの価値
2点あります。
(1) 系列ごとにチャンピオンがバラバラ
D1はAutoCES、D14はAutoTbats、D34はBaselineNaive、D35はなんとCrostonSBA(全体最下位のモデル)になっています。「ある系列の最強モデル = 全体最強モデル」ではないことが数値で分かります。
(2) 全体下位モデルでも、特定系列では輝くことがある
全体ランキング最下位のCrostonSBAが、D35では唯一のチャンピオンとなっています。D33やD64ではBaselineSeasonalWindowAverage(全体15位)がチャンピオンです。これらは「業界平均では使えないが、このデータ固有の癖には合っている」パターンになります。
つまり、全系列を単一モデルで予測するより、系列ごとに最適モデルを選ぶほうが全体精度が上がるという、MMFの存在意義そのものがここで可視化されます。
チャンピオン回数の集計
さらに踏み込んで、「28系列中、このモデルが何回チャンピオンになったか」を集計します。
| model | n_series_where_best |
|---|---|
| StatsForecastAutoTbats | 8 |
| StatsForecastAutoCES | 5 |
| StatsForecastBaselineWindowAverage | 4 |
| StatsForecastAutoArima | 3 |
| StatsForecastBaselineNaive | 2 |
| StatsForecastBaselineSeasonalWindowAverage | 2 |
| StatsForecastAutoETS | 1 |
| StatsForecastAutoTheta | 1 |
| StatsForecastCrostonSBA | 1 |
| StatsForecastTSB | 1 |

読み解き
- 全体ランキング1位のAutoTbatsは、チャンピオン回数でも1位の8系列(29%)です
- ところが残り71%の系列ではAutoTbatsは勝っていません
- AutoCESは全体6位なのにチャンピオン回数2位(5系列)です。「全体平均は普通だが、刺さる系列が多い」モデルと言えます
- 全体ランキング最下位のCrostonSBAも1系列でチャンピオンになっています
ここから導ける実務的な結論は以下のとおりです。
- 単一モデルで全系列を予測するのは、精度面で機会損失になる
- AutoTbatsを含む上位2〜3モデルとBaselineモデルを混ぜておくのが安全策
- 全体下位のモデルも、捨ててはいけない(特定系列で効くため)
特定系列のバックテスト可視化
数値だけでは肌感が取れないので、特定系列の予測 vs 実測をプロットします。evaluation_outputの配列を posexplode で展開して、step数を日付に加算すれば、バックテストwindowの推移が1つの折れ線グラフで見られます。
バックテストとは、過去の時点に遡って「その時予測していたらどれくらい当たったか」を検証する手法です。1回の訓練/テスト分割では偶然の影響を受けやすいため、過去の複数windowで同じ検証を繰り返してSMAPEを平均することで、モデルの安定した精度を測ります。今回の設定では28系列×6windowで合計168回の検証が回っています。
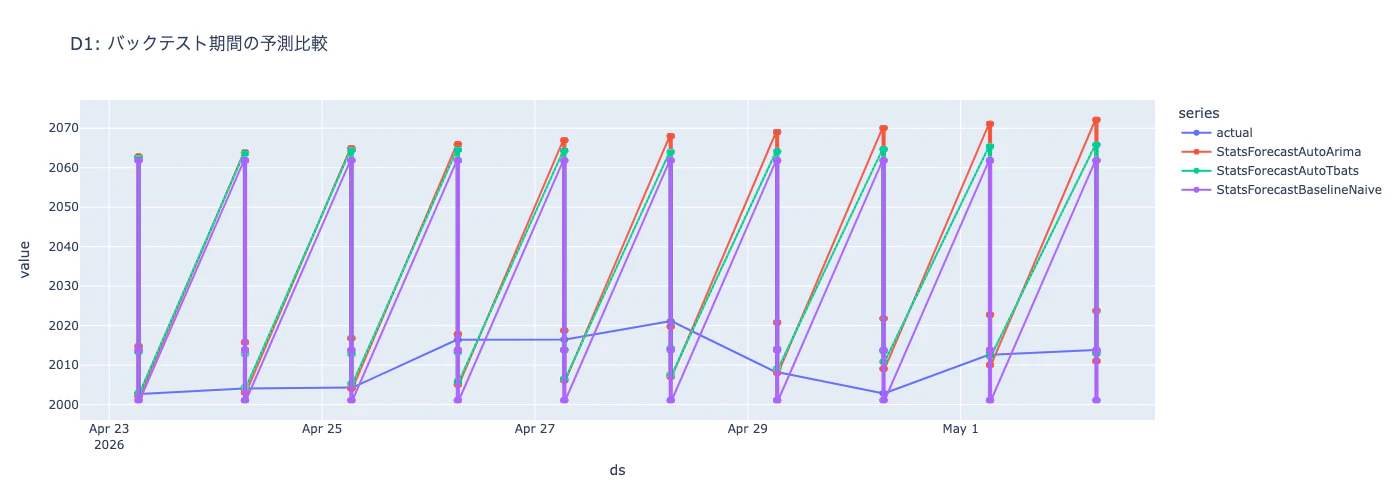
D1について、AutoArima / AutoTbats / BaselineNaiveの3モデルの予測を実測と重ねてプロットすると、モデル同士の個性が見えてきます。AutoTbatsは滑らかに追従し、AutoArimaは直近のトレンドを強く反映し、Naiveは水平線となります。SMAPE数値を補完する形で「どう外すか」が直感的に分かるようになります。
最終アウトプット: 系列ごとのチャンピオン予測
ここまでで揃った情報を組み合わせて、「系列ごとに最適モデルの未来予測」を1つのテーブルとして取り出すのが最後の仕上げです。
WITH smape_per_window AS ( -- 同上 ),
per_series AS ( -- 同上 ),
champions AS (
SELECT unique_id, model
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY unique_id ORDER BY smape) AS rnk
FROM per_series
)
WHERE rnk = 1
),
scoring_exploded AS (
SELECT
s.unique_id,
s.model,
s.ds[pos] AS forecast_date,
y_val AS forecast_value
FROM takaakiyayoi_catalog.m4.daily_scoring_output s
LATERAL VIEW posexplode(s.y) t AS pos, y_val
WHERE s.use_case = 'm4_daily'
)
SELECT
se.unique_id,
se.forecast_date,
se.forecast_value AS forecast,
c.model AS used_model
FROM scoring_exploded se
JOIN champions c
ON se.unique_id = c.unique_id AND se.model = c.model
ORDER BY se.unique_id, se.forecast_date
ポイントは scoring_output 側の展開方法です。ds と y がそれぞれ長さ10の配列なので、posexplode(y) で位置 pos と値を取り出し、同じ位置の ds[pos] で対応する予測日を引きます。これで10日ぶんが10行に綺麗にほどけます。
結果として得られるのが、「D1は2022-10-17から2022-10-26までAutoCESで予測、D11は同期間をTSBで予測」というテーブルです。これが業務システムやBIダッシュボードに渡す最終成果物になります。
ハマりポイントの備忘録
今回の体験で地味に時間を取られた落とし穴を残しておきます。
1. RUNME.pyは新しいDBRで動かない
RUNME.py は自動でクラスタとジョブを作るヘルパーですが、dbacademy@v1.0.13 が古すぎて、DBR 17.3 LTS ML(Spark 4)では JavaPackage object is not callable で落ちます。
回避策: RUNME.pyは飛ばして、examples配下のノートブックを直接実行します。クラスタは手動で作ります。
2. SKTimeProphetはワーカー側で動かない
active_modelsに SKTimeProphet を入れると、evaluationでは静かに空DataFrameを返し、scoringで PythonException で落ちます。原因はワーカーノードでのProphet/cmdstanpy初期化失敗です。
回避策: active_modelsから外します。どうしても必要な場合はクラスタライブラリとして prophet + cmdstanpy を明示的に入れる必要があります。
3. クラスタ設定について
READMEには spark.sql.execution.arrow.enabled=true / spark.sql.adaptive.enabled=false の設定が必須として記載されています。これを踏まえて当初はClassic Computeで実行していましたが、実際にはサーバレスコンピュートでも問題なく動作しました。local_univariate_daily.ipynb (MMF本体の run_forecast 実行) と本記事Part 3の post-evaluation 分析SQLの両方とも、サーバレスで完結します。
サーバレス環境では2つの設定について以下のような状況です:
-
spark.sql.execution.arrow.enabled→ サーバレスはArrowベースのデータ転送が標準なので設定不要 -
spark.sql.adaptive.enabled=false→ サーバレスでは上書きできないが、AQEオンのまま動作した
サーバレスで動かす場合のメリット:
- クラスタ起動を待たずにすぐ実行できる
- READMEの面倒なSparkコンフィグの上書きを気にしなくてよい
- コスト最適化を自動で任せられる
AQEをオフにできない場合の影響について
READMEがあえて spark.sql.adaptive.enabled=false を要求している意図は、AQEがパーティションを動的に合体(coalesce)する機能が groupBy("unique_id").applyInPandas(...) の並列度を下げる可能性を避けるためと推測されます。具体的には、AQEが「小さいパーティションが多すぎる」と判断して複数の unique_id を1パーティションに詰め込むと、1ワーカーが直列に複数モデルfitすることになり、実行時間が想定より長くなる可能性があります。
ただし今回の28系列規模では実害は観測されませんでした。本番規模(数千〜数万系列)でAQEの影響を厳密に避けたい場合はClassic Computeを選ぶ余地がありますが、PoCや小〜中規模のワークロードであればサーバレスを第一候補にしてよいと思います。
なお Global Models / Foundation Models はGPUが必要なため、引き続きGPUクラスタが要ります。Local Modelsだけならサーバレス、というのが一番楽です。
4. post-evaluation-analysis.ipynbはmonthly前提
リポジトリに同梱されている分析ノートブックは、テーブル名も周期もmonthlyで書かれているので、dailyで回した結果をそのまま食わせても動きません。カタログ/スキーマ名と周期関連の定数を全部差し替える必要があります。
5. evaluation_outputとscoring_outputでスキーマが違う
- evaluation:
actual(array),forecast(array),run_date(scalar) など - scoring:
ds(array),y(array),run_date(scalar) など
同じ情報を actual/forecast と ds/y で名前を変えて持っているうえに、日付が scoring では配列の中に入っています(run_date はスカラーで「実行日時」、配列内の ds が「予測対象日」)。両テーブルで名前が揃っていないことを事前に知らないとクエリで詰みます。
6. 配列型のSMAPE計算は zip_with + aggregate
actual - forecast のようなスカラー演算は配列では効きません。arrays_zip + explode も struct のフィールド名競合で落ちることがあります。配列のまま計算する zip_with + aggregate パターンが一番安定します。
まとめ
MMFは「多モデル × 多系列」を大規模に並列評価する基盤であり、回した後の分析まで含めて初めて価値が見えます。Part 1とPart 3の対比で言えば、
- Part 1(1系列)では、モデル間のSMAPE差が数倍違うことが分かります
- Part 3(28系列)では、系列ごとに勝つモデルが違うことが数値で示されます
これがMMFの核心的な価値提案であり、単一モデル予測に対する精度アドバンテージの源泉になります。逆に、これを自分で集計しないとMMFを使っている意味が半減しますので、後処理のSQLパターンを持っておくのが実務上は重要です。
配列型の出力、スキーマの揺れ、クラスタ要件といったクセが多いですが、系列ごとに最適モデルを選ぶというやりたいことは綺麗に実現できます。需要予測ソリューションを検討しているチームは、一度回して、本記事のようなSQLでチャンピオン一覧を眺めてみることをおすすめします。
参考リンク:
- Many Model Forecasting GitHub
- Databricksにおけるマルチモデル予測のためのフレームワーク(Databricks Blog)
- MLflow(Databricks公式ドキュメント)
- Unity Catalog(Databricks公式ドキュメント)