Stop using Pandas and start using Spark with Scala | by Chloe Connor | Towards Data Scienceの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
なぜデータサイエンティストやデータエンジニアがPandasの代替としてScalaとSparkを使うことを考えるべきなのか、どのように使い始めるのか

ソース: https://unsplash.com/photos/8IGKYypIZ9k
PandasからScala + Sparkへの移行は思うほど大変なことではなく、結果としてお使いのコードが高速になり、おそらくより良いコードを書くことになるでしょう。
データエンジニアとしての私の経験を通じて、Pandasでデータパイプラインを構築すると、増加するメモリーの使用量についていくために定期的にリソースを増強することが多くの場合必要となることを知りました。さらに、予期しないデータ型やnullによって多くの実行時エラーに遭遇しました。代わりにScalaとSparkを用いることで、ソリューションはより堅牢なものとなり、リファクタリングや拡張が容易になりました。
本書では以下をウォークスルーします
- なぜPandasではなくScalaとSparkを使用すべきなのか
- Scala Spark APIはPandas APIとそれほど違いがない
- Jupyterノートブック、お使いのIDEでどのようにスタートするのか
Sparkとは何か?
- SparkはApacheのオープンソースフレームワークです。
- ライブラリとして使うことができ、「ローカル」クラスターあるいはSparkクラスターで実行することができます。
- Sparkクラスターでは、単体のマスターノードと負荷を分担する複数のワーカーノードを用いて、コードを分散処理で実行することができます。
- ローカルクラスターにおいても、Pandasよりも優れた性能改善を得ることができ、以下でなぜなのかを見ていきます。
なぜSparkを使うのか?
Sparkは高速で大量データを処理できる能力があるので人気があります
デフォルトではSparkはマルチスレッドですが、Pandasはシングルスレッドです。- Sparkクラスター上でSparkコードを分散実行できますが、Pandasは単一のマシンで処理を実行します。
- Sparkはlazyであり、collectを行なった際(何かを返却する必要があった時)にのみ処理が実行されることを意味し、また、実行計画を構築し、お使いのコードを実行する最適な方法を見つけ出すことを意味します。
- この点は、それぞれのステップを貪欲に逐次実行するPandasとは異なります。
- また、Sparkはメモリーの制限に到達した際にはディスクを使い始めるので、アウトオブメモリーになる可能性が低いです。
実行時間のビジュアルな比較のために、Databricksから提供される以下の図を見てみます。ここでは、SparkはPandasよりもはるかに高速であり、Pandasはより低い閾値メモリーが枯渇していることがわかります。
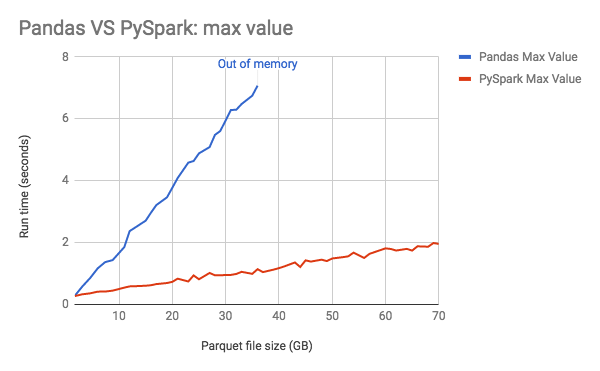
https://databricks.com/blog/2018/05/03/benchmarking-apache-spark-on-a-single-node-machine.html
日本語訳: https://qiita.com/taka_yayoi/items/70b0c0c1bbd473de1481
Sparkには豊富なエコシステムがあります
- ビルトインのSpark ML、グラフアルゴリズムのためのGraphXのようなデータサイエンスライブラリ
- リアルタイムデータ処理のためのSparkストリーミング
- 他のシステム、ファイルタイプ(orc、parquetなど)との相互運用性
なぜPySparkではなくScalaを使うのか?
Sparkは馴染み深いAPIを提供しているので、PythonではなくScalaを使うことで大きな学習曲線を感じることはありません。なぜScalaを使いたいと考えるのかの理由を以下に示します。
- Scalaは静的な型付きの言語であり、Pythonを使うときよりもお使いのコードが実行時エラーに遭遇する可能性が低いことを意味します。
- また、Scalaは不変なオブジェクトを作成することができ、作成時から呼び出し時までの間でオブジェクトを参照する際に状態が変化しないことに自信を持つことができます。
- SparkはScalaで記述されているので、PythonよりもScalaで利用できる新機能が存在します。
- データサイエンティストとデータエンジニアが一緒に作業する際、Scalaの型安全性と不変性によってコラボレーションを支援します。
Sparkのコアコンセプト
- データフレーム: データフレームはPandasデータフレームと非常によく似たデータ構造です。
- データセット: データセットは型付けされたデータフレームであり、期待するスキーマにデータが準拠していることを保証するために非常に有用なものとなります。
- RDD: Sparkにおけるコアのデータ構造であり、この上にデータフレームとデータセットが構築されています。
データセットは型安全であり、より効率的であり、データセットに何を期待するのかをクリアにできるので可読性を高められるので、通常我々は可能な限りデータセットを使用します。
データセット
データセットを作るためには、Pythonのデータクラスタと類似したcaseクラスを最初に作成する必要があります。これがまさにデータ構造を指定する手段となります。
例えば、いくつかのフィールドを持つFootballTeamというcaseクラスを作成してみましょう。
case class FootballTeam(
name: String,
league: String,
matches_played: Int,
goals_this_season: Int,
top_goal_scorer: String,
wins: Int
)
このcaseクラスのインスタンスを作成してみましょう。
val brighton: FootballTeam =
FootballTeam(
"Brighton and Hove Albion",
"Premier League",
matches_played = 29,
goals_this_season = 32,
top_goal_scorer = "Neil Maupay",
wins = 6
)
manCityという別のインスタンスを作成し、これら二つのフットボールチームを用いてデータセットを作成してみましょう。
val teams: Dataset[FootballTeam] = spark.createDataset(Seq(brighton,
manCity))
別の方法で作成することもできます。
val teams: Dataset[FootballTeam] =
spark.createDataFrame(Seq(brighton, manCity)).as[FootballTeam]
2番目の方法は、外部データソースから読み取りデータフレームを返却する際に有用です。お使いのデータセットにキャストできるので、型付けされたコレクションを得ることができます。
データの変換
(全てでないなら)多くのPandasデータフレームに適用できるデータ変換は、Sparkでも利用できます。もちろん、構文の違いや注意すべき事柄が存在しており、それらのいくつかを以下で見ていきます。
通常、Pandasと比べてSparkの記法はより一貫性があり、Scalaは静的に型付けされるので、多くの場合myDataset.と入力し、コンパイラがどのようなメソッドを利用できるのかを表示させましょう!
データセットに新規カラムを追加し、定数値を割り当てるシンプルな変換処理から始めましょう。Pandasでは以下のようになります。
df_teams['sport'] = 'football'
Sparkでは構文以外に小さな差異があり、新規フィールドに定数値を割り当てるためにはlitというSpark関数をインポートする必要があります。
import org.apache.spark.sql.functions.lit
val newTeams = teams.withColumn("sport", lit("football"))
オリジナルのteamsデータセットとして作成した新規オブジェクトがvalであり、不変であることを意味することに注意してください。teamsデータセットを使うときには常に同じオブジェクトを取得することを知っているので、これは良いことです。
それでは、関数に基づいて列を追加してみましょう。Pandasでは以下のようになります。
def is_prem(league):
if league == 'Premier League':
return True
else:
return False
df_teams['premier_league'] = df_teams['league'].apply(lambda x:
is_prem(x))
Sparkで同じことを行うためには、Sparkが適用できるように関数をシリアライズする必要があります。これは、UserDefinedFunctionsと呼ばれるものを用いて行います。また、if-elseよりもScalaの優れた実装であるcaseマッチを使用しました。どちらも利用することは可能です。
また、カラムを参照するために使用する別の有用なspark関数であるcolをインポートする必要があります。
import org.apache.spark.sql.functions.col
def isPrem(league: String): Boolean =
league match {
case "Premier League" => true
case _ => false
}
val isPremUDF: UserDefinedFunction =
udf[Boolean, String](isPrem)
val teamsWithLeague: DataFrame = teams.withColumn("premier_league",
isPremUDF(col("league")))
これで、我々のcaseクラスに存在しない新規カラムを追加し、データフレームに変換し直しています。このため、オリジナルのcaseクラスに別のフィールドを追加するか(そして、Optionsを用いてnullableを許可する)、新たなcaseクラスを作成する必要があります。
ScalaのOptionはフィールドでnullを許可することを意味します。値がnullの場合はNone、値がある場合にはSome("value")を使います。オプション文字列の例を以下に示します。
val optionalString : Option[String] = Some("something")
これから文字列を取得するためにoptionalString.get()を呼び出すことができ、これは単に"something"を返却します。nullかそうでないかがわからない場合、nullの場合に文字列"nothing"を返却するoptionalString.getOrElse("nothing")を使うことができます。
データセットのフィルタリングは別の一般的な要件であり、他の変換処理と同じように、データセット「ドット」変換処理(dataset.filter(...))という同じパターンに従うのでPandasよりもSparkが一貫性がある良い例となります。
df_teams = df_teams[df_teams['goals_this_season'] > 50]
val filteredTeams = teams.filter(col("goals_this_season") > 50)
PandasとSparkで非常に類似した集計処理をデータセットに対する行う可能性は高いです。
df_teams.groupby(['league']).count()
teams.groupBy("league").count()
複数の集計処理においては、ここでもPandasと同じように集計処理に対してフィールドをマッピングすることができます。ご自身の集計処理を行いたい場合には、UserDefinedAggregationsを使うこともできます。
teams.agg(Map(
"matches_played" -> "avg",
"goals_this_season" -> "count"))
多くのケースでは、複数のデータセットを組み合わせることになりこれはunionで実行することができます。
pd.concat([teams, another_teams], ignore_index=True)
teams.unionByName(anotherTeams)
あるいはjoinで行います。
val players: Dataset[Player] = spark
.createDataset(Seq(neilMaupey, sergioAguero))
teams.join(players,
teams.col("top_goal_scorer") === players.col("player_name"),
"left"
).drop("player_name")
この例では、新たなデータセットを作成しており、今回はPlayerというcaseクラスを用いています。このcaseクラスではnullを許可するinjuryフィールドがあることに注意してください。
case class Player(player_name: String, goals_scored: Int,
injury: Option[String])
top_goal_scorerと重複するplayer_nameを削除したことに注意してください。
また、コードのある部分でArrayやListのようなScalaネイティブのデータ構造を使いたいと考えるかもしれません。カラムをArrayとして取得するには、値にマッピングを行い.collect()を呼び出す必要があります。
val teamNames: Array[String] = teams.map(team => team.name)
.collect()
nameフィールドを取得するためにcaseクラスにビルトインされているゲッターを使うことができ、我々が使っているFootballTeamクラスにnameフィールドが含まれていない場合にはコンパイルされないことに注意してください。
ご参考ですが、caseクラスに関数を追加することができ、IntelliJやMetalsプラグインありのvs codeのようなIDEを使う際にオートコンプリートのオプションとして値と関数の両方が表示されます。
このArrayに存在するのかどうかに基づいてデータセットをフィルタリングするには、_*を呼び出して引数のシーケンスとして取り扱う必要があります。
val filteredPlayers: Dataset[Player] = players
.filter(col("team").isin(teamNames: _*))
いくつかコードを動かす
ここまでで、Pandasとそれほど違いがないという私の主張を確かめるためでも、Sparkコードを書いてみたいと思ってもらえていると嬉しいです。
スタートするにはいくつかの選択肢があります。何かしらのデータを取得し遊び始めるにはクイックな手段であるノートブックを使うことができます。あるいは、シンプルなプロジェクトをセットアップすることもできます。どちらの場合でもJava 8のインストールが必要です。
ノートブック
この例では、Jupyter notebookでspylonカーネルを使用します。https://pypi.org/project/spylon-kernel/ ノートブックをセットアップするために最初に以下のコマンドを実行すると、ブラウザでノートブックが開きます。次に、利用可能なカーネルからspylon-kernelを選択します。
pip install spylon-kernel
python -m spylon_kernel install
jupyter notebook
セルに以下を追加して適切なJavaバージョンがあることを確認しましょう。
!java -version
アウトプットは以下のようになるはずです。
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
そうでない場合には、お使いのbashプロファイルのJAVA_HOMEを確認し、Java 8を参照していることを確認してください。
次のステップではいくつかの依存関係をインストールします。このためには、新規セルに以下のコードスニペットを追加します。これによって、いくつかのSpark設定をセットアップし、依存関係を追加できるようになります。こちらではvegasという可視化ライブラリを追加しました。
%%init_spark
launcher.num_executors = 4
launcher.executor_cores = 2
launcher.driver_memory = '4g'
launcher.conf.set("spark.sql.catalogImplementation", "hive")
launcher.packages = ["org.vegas-viz:vegas_2.11:0.3.11",
"org.vegas-viz:vegas-spark_2.11:0.3.11"]
データソースに接続するために、いかのような関数を定義します。
def getData(file: String): DataFrame =
spark.read
.format("csv")
.option("header", "true")
.load(file)
これは、csvファイルに接続しますが、接続できるデータソースは他にも多く存在します。この関数はデータフレームを返却しますが、データセットに変換したいと思うかもしれません。
val footballTeams: Dataset[FootballTeam] =
getData("footballs_teams.csv").as[FootballTeam]
これで、このデータを使用して、ここまでで議論したデータ変換処理や他のことを試すことができます。
プロジェクトのセットアップ
ここまでで、いくつかのデータで遊んでみたので、今度はプロジェクトをセットアップしたいと思うかもしれません。
プロジェクトには主に以下の2つを含める必要があります。
- build.sbt - 先ほどノートブックのセルに追加した依存関係を、ここではbuild.sptファイルに追加する必要があります。
-
SparkSession - ノートブック上では既にSparkセッションがあり、
spark.createDataFrameのようなことが可能であることを意味しました。プロジェクトではこのSparkセッションを作成する必要があります。
build.sbtサンプル
name := "spark-template"
version := "0.1"
scalaVersion := "2.12.11"
val sparkVersion = "2.4.3"
libraryDependencies += "org.apache.spark" %% "spark-core" % sparkVersion
libraryDependencies += "org.apache.spark" %% "spark-sql" % sparkVersion
Sparkセッションサンプル
import org.apache.spark.sql.SparkSession
trait SparkSessionWrapper {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("spark-example")
.getOrCreate()
}
これで、このラッパーを用いてオブジェクトを拡張することができ、これによってSparkセッションを得ることができます。
object RunMyCode extends SparkSessionWrapper {
//your code here
}
これでSparkコードを書き始めることができます!
まとめ
まとめると、Sparkは高速データ処理のための偉大なツールであり、データの世界において非常に人気を得ています。このため、Scalaもまた人気のある言語となっており、型安全によって、PythonやPandasに馴染みのあるデータエンジニアやデータサイエンティストにとって優れた選択肢となっています。Sparkにおいては、データフレームのような馴染みのあるコンセプトを用いるので、言語に対する優れた入門となっており、学習曲線が大きいと感じることはありません。
この記事がクイックなオーバービューを伝え、皆様がノートブックあるいは新規プロジェクトでSparkを使い始める助けになれば幸いです。幸運を!