本書では、Pytorch LightningによるMNIST分類器をMLflowでトラッキングし、サービングするところまでを説明します。REST APIへの入力が画像になるので、MLflowのtensorサポートを活用します。これによって、画像分類器をREST APIで呼び出せるようになり、機械学習モデルのシステム連携が容易に行えます。
MLflowでTensorの入力をサポートしました - Qiita
注意
- MLflowのモデルサービングで
Cannot register 2 metrics with the same nameエラーが生じる場合、tensorflowのバージョンが2.6であることに起因する可能性があります。最新のランタイム10.2MLであればバージョン2.7になるので本エラーを回避できます。
- MLflowのオートロギングを用いてモデルをトラッキングします。オートロギングが対応しているバージョンのpytorch-lightningをインストールします。
Autologging is known to be compatible with the following package versions: 1.0.5 <= pytorch-lightning <= 1.5.9. Autologging may not succeed when used with package versions outside of this range.
PyTorch Lightningのインストール
%pip install pytorch_lightning==1.5.9
モデルの定義
こちらはトレーニングループのみを含む最もシンプルなサンプルです(バリデーション、テストなし)。
注意 LightningModuleはPyTorchのnn.Moduleです。単にいくつかの役立つ機能を持っているだけです。
from pytorch_lightning import LightningModule, Trainer
class MNISTModel(pl.LightningModule):
def __init__(self):
super(MNISTModel, self).__init__()
self.l1 = torch.nn.Linear(28 * 28, 10)
def forward(self, x):
return torch.relu(self.l1(x.view(x.size(0), -1)))
def training_step(self, batch, batch_nb):
x, y = batch
loss = F.cross_entropy(self(x), y)
#acc = accuracy(loss, y) # エラーになるのでコメントアウト
# PyTorchのロガーを使って精度情報を記録
self.log("train_loss", loss, on_epoch=True)
#self.log("acc", acc, on_epoch=True)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.02)
トレーニングおよびMLflowによるトラッキング
精度指標のメトリクスは、上でon_epoch=Trueを指定しているので、エポックごとに記録されます。
# MLflowのエンティティを全てオートロギング
mlflow.pytorch.autolog()
# モデルを初期化
mnist_model = MNISTModel()
# MNISTデータセットのDataLoaderを初期化
train_ds = MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor())
train_loader = DataLoader(train_ds, batch_size=32)
# トレーナーを初期化
trainer = Trainer(
gpus=0, # CPU
max_epochs=20,
progress_bar_refresh_rate=20,
)
# モデルをトレーニング ⚡
with mlflow.start_run() as run: # run IDを取得するためにブロックを宣言
trainer.fit(mnist_model, train_loader)
画面右上のExperimentボタンで表示される一覧でモデルを確認することができます。
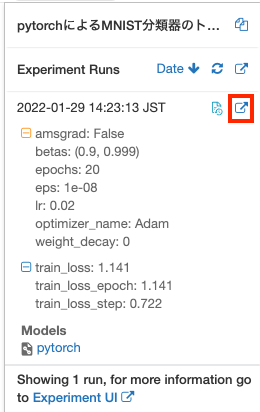
日付の右にある アイコンをクリックすることで、さらに詳細を確認することができます。こちらでは、エポックごとのメトリクスの変化を確認することも可能です。
アイコンをクリックすることで、さらに詳細を確認することができます。こちらでは、エポックごとのメトリクスの変化を確認することも可能です。
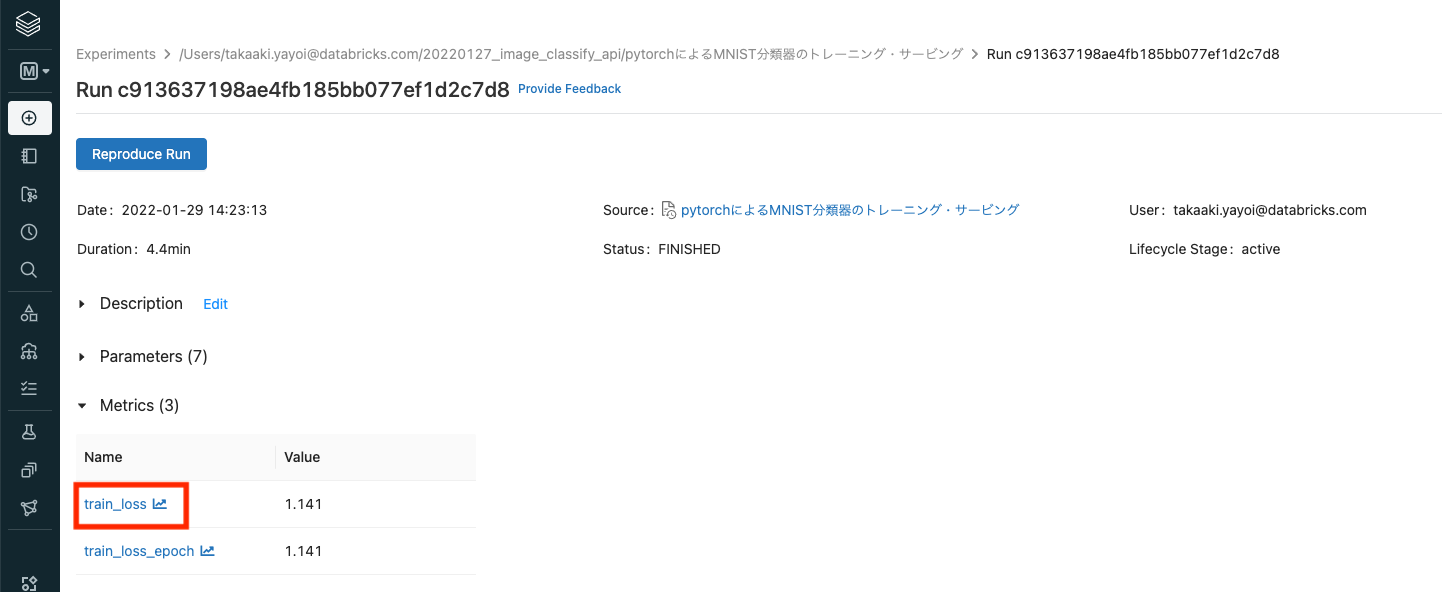
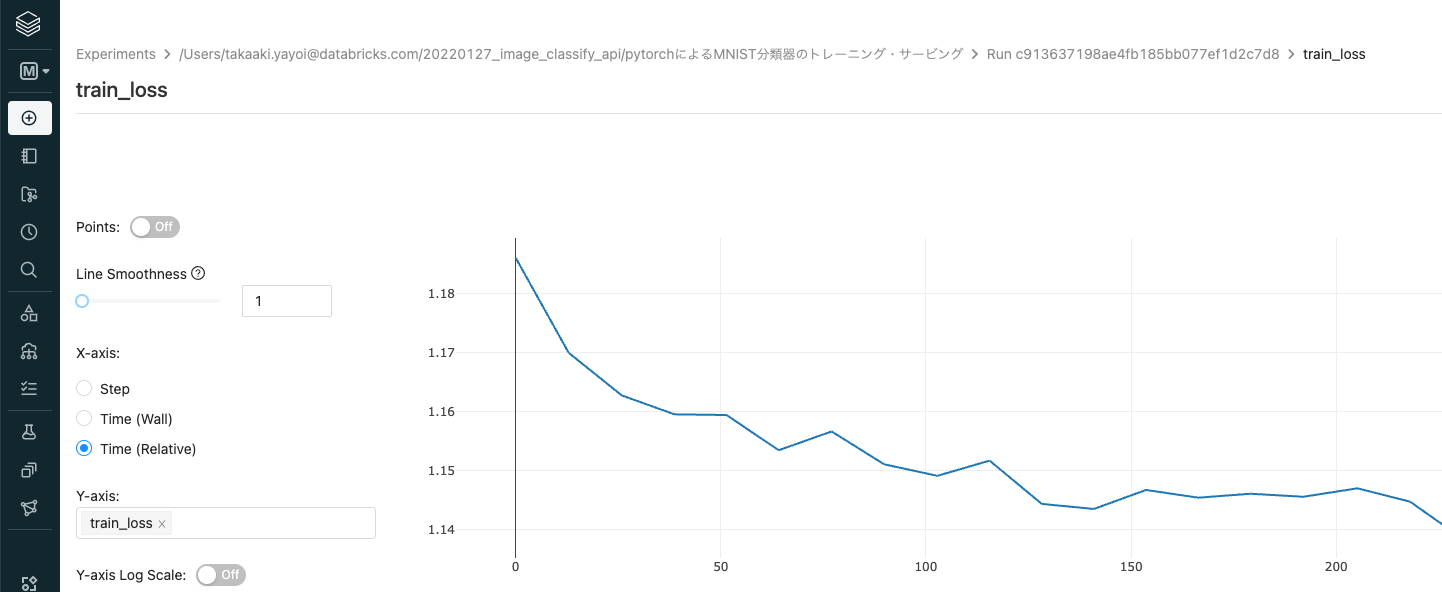
メトリクスをクリックするとグラフが表示されます。
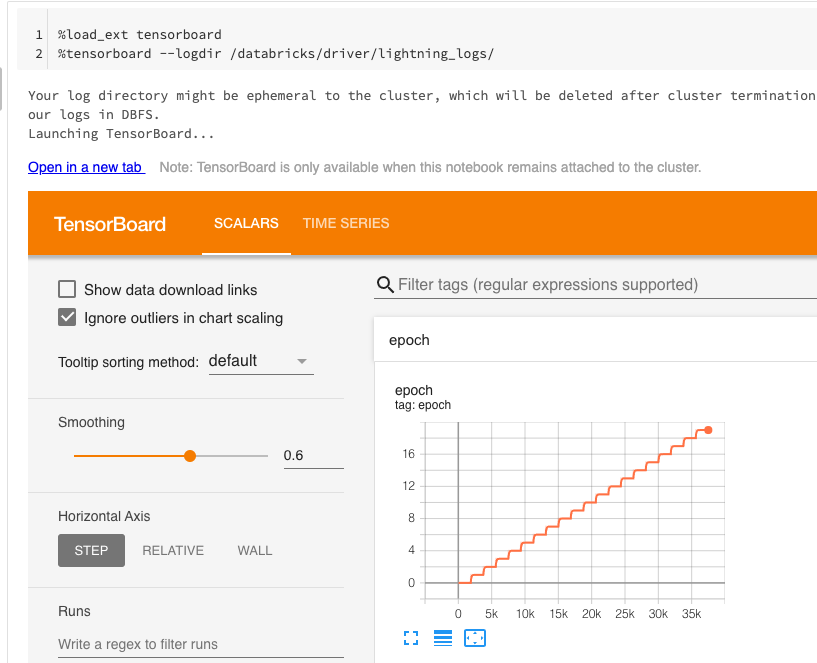
TendorBoardの活用
ノートブック上で直接TensorBoardを活用することができます。
データサイエンティスト向けの10個のシンプルなDatabricksノートブック tips & tricks - Qiita
%load_ext tensorboard
%tensorboard --logdir /databricks/driver/lightning_logs/
モデルによる分類
これはデモなので、トレーニングデータセットの一部を用いて分類を行ないます。
PyTorch 1.0 - How to predict single images - mnist example? - PyTorch Forums
下のセルでは画像を確認するためにmatplotlibのimshowを用いて、ノートブック上に画像を表示しています。
from matplotlib.pyplot import imshow
single_loaded_img = train_loader.dataset.data[0]
imshow(single_loaded_img)
single_loaded_img_conv = single_loaded_img[None, None]
single_loaded_img_conv = single_loaded_img_conv.type('torch.FloatTensor') # DoubleTensorの代替
out_predict = mnist_model(single_loaded_img_conv)
print(out_predict)
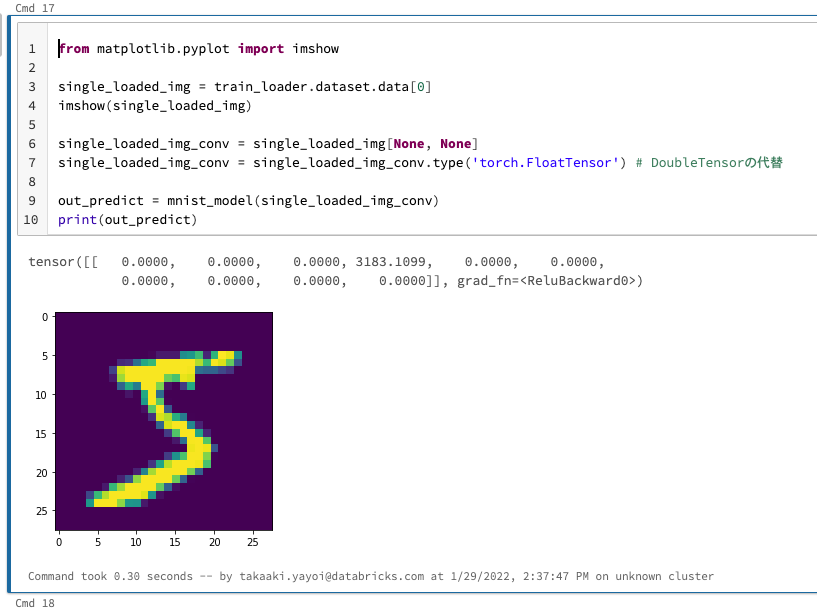
結果は0-9の判定結果となり、今回の例では3と判定してしまっていますが、次に進みます。
モデルをMLflowモデルレジストリに登録
MLflowモデルレジストリに機械学習モデルを登録することで、モデルのバージョン、ステータス管理が可能となります。加えて、後述するモデルサービングと組み合わせることで、実験段階、テスト段階を経た機械学習モデルを本格運用することが可能となります。
モデルを登録する際に、モデルの入出力を規定するシグネチャ、デバッグに活用できるサンプルデータを指定します。
シグネチャの準備
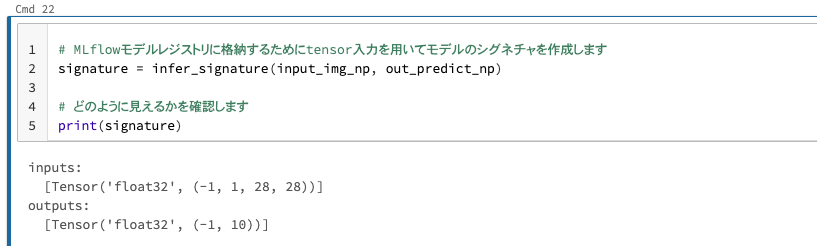
以下ではtensorをnumpyのarrayに変換した後で、シグネチャを推定しています。
input_img_np = single_loaded_img_conv.to('cpu').detach().numpy().copy()
out_predict_np = out_predict.to('cpu').detach().numpy().copy()
# MLflowモデルレジストリに格納するためにtensor入力を用いてモデルのシグネチャを作成します
signature = infer_signature(input_img_np, out_predict_np)
# どのように見えるかを確認します
print(signature)
入力サンプルの準備
- MLflowモデルレジストリに格納する入力サンプルを作成します
- 入力サンプルをモデルレジストリに登録しておくと、モデルサービングの画面で入力サンプルを用いて簡単に動作確認を行うことができます
# np.expand_dims() は、第2引数の axis で指定した場所の直前に dim=1 を挿入します
input_example = np.expand_dims(input_img_np[0], axis=0)
モデルレジストリへの登録
上で準備したシグネチャ、入力サンプルを指定してモデルレジストリに登録します。
mlflow.pytorch.log_model(mnist_model, model_name, signature=signature, input_example=input_example, registered_model_name=registered_model_name)
モデルレジストリからモデルをロードして分類
モデルレジストリにモデルを登録すると、モデルバージョン固有のURIでモデルをロードすることができるようになります。
# モデルをロードしてサンプルの予測を実行しましょう
model_version = "1"
loaded_model = mlflow.pytorch.load_model(f"models:/{registered_model_name}/{model_version}")
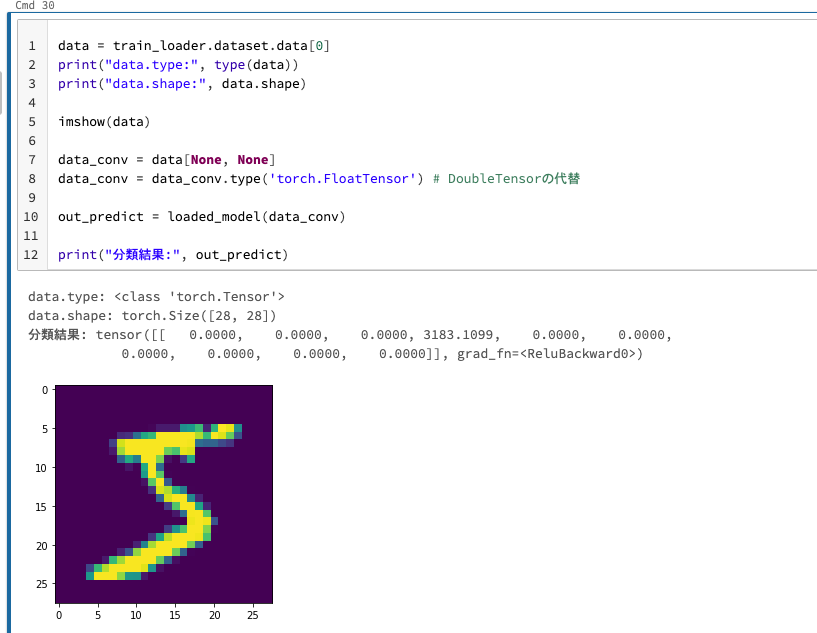
data = train_loader.dataset.data[0]
print("data.type:", type(data))
print("data.shape:", data.shape)
imshow(data)
data_conv = data[None, None]
data_conv = data_conv.type('torch.FloatTensor') # DoubleTensorの代替
out_predict = loaded_model(data_conv)
print("分類結果:", out_predict)
REST APIを通じたモデルの呼び出し
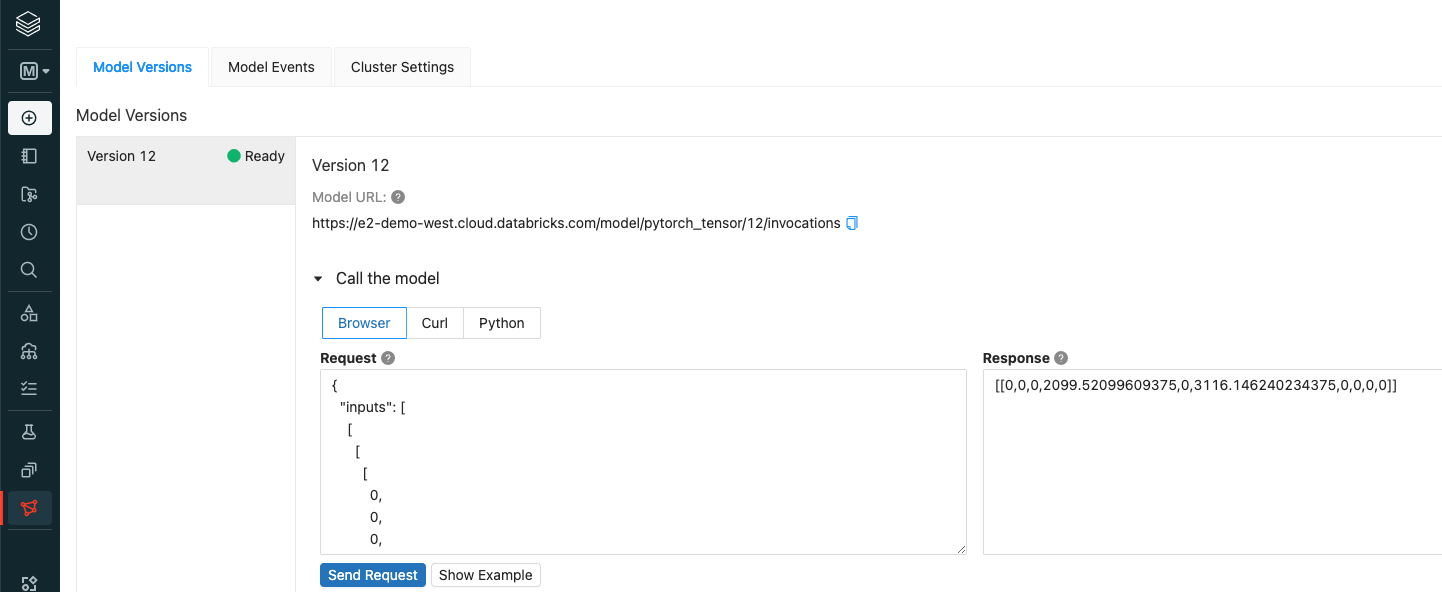
上記モデルレジストリに移動し、モデルサービングを有効化します。
これまでのステップでtensorを受け取れるtensorflowモデルをモデルレジストリに登録しているので、REST API経由で画像分類が行えます。REST APIを使用する際には、パーソナルアクセストークンを発行し、REST API呼び出しの中にBearerトークンとして埋め込む必要があります。パーソナルアクセストークンは、サイドメニューのSettings > User Settingsを開き、Access TokensでGenerate New Tokenをクリックします。
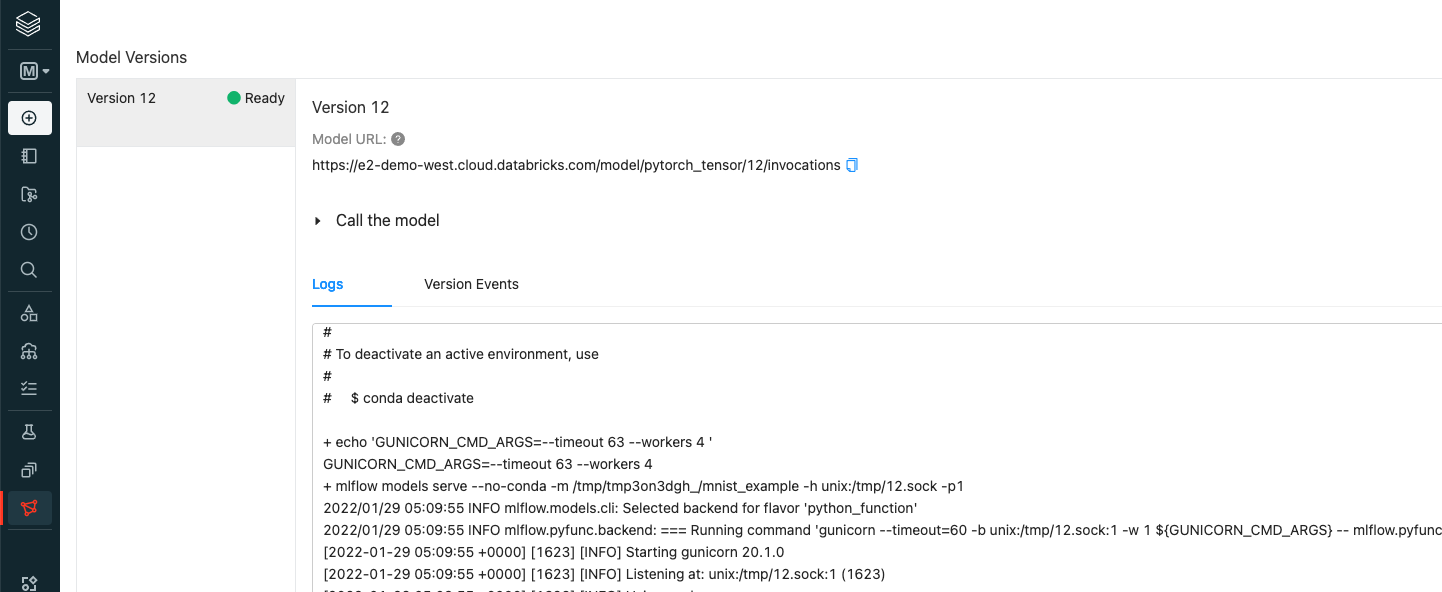
モデルサービングを有効化してもモデルがPendingからReadyにならない場合、モデルのデプロイに失敗している可能性があります。サービングの画面下部のLogsでエラーが起きていないか確認してください。
Databricksにおけるモデルサービング - Qiita
import os
import requests
import numpy as np
import pandas as pd
# tensorをエンドポイントに引き渡す際のフォーマットに変換
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(dataset):
# モデルのREST APIエンドポイント(モデルサービングの画面で確認できます)
url = f'https://<Databricksホスト名>/model/{registered_model_name}/{model_version}/invocations'
#print(url)
headers = {'Authorization': f'Bearer {os.environ.get("DATABRICKS_TOKEN")}'}
# datasetがデータフレームの場合はJSONに変換、そうでない場合はtensorを渡す際のJSONにフォーマットに変換
data_json = dataset.to_dict(orient='split') if isinstance(dataset, pd.DataFrame) else create_tf_serving_json(dataset)
#print(data_json)
# API呼び出し
response = requests.request(method='POST', headers=headers, url=url, json=data_json)
if response.status_code != 200:
raise Exception(f'Request failed with status {response.status_code}, {response.text}')
return response.json()
data = train_loader.dataset.data[10]
print("data.type:", type(data))
print("data.shape:", data.shape)
imshow(data)
data_conv = data[None, None]
data_conv = data_conv.type('torch.FloatTensor') # DoubleTensorの代替
print(data_conv.shape)
# モデルサービングは、比較的小さいデータバッチにおいて低レーテンシーで予測するように設計されています。
served_predictions = score_model(data_conv)
print("分類結果:", served_predictions)
REST API経由でモデルを呼び出し、分類結果を取得できていることが確認できます。

ファイルを指定して分類を実行
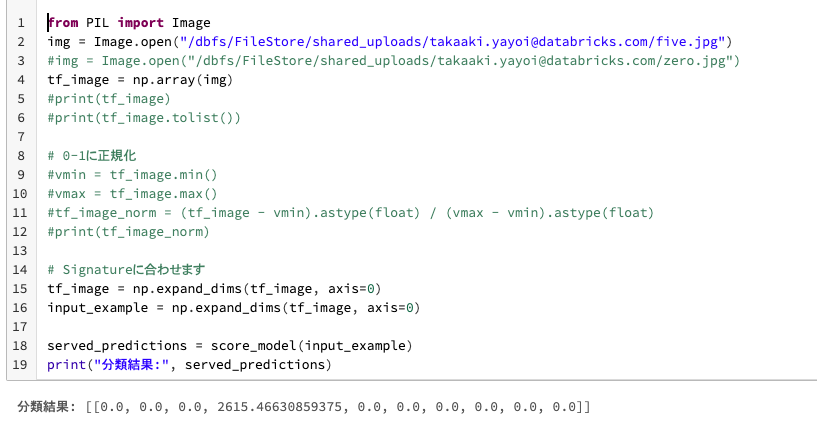
以下のセルのロジックは、ローカルマシンで画像を指定してモデルを呼び出して分類することを想定しています。
img = Image.open("/dbfs/FileStore/shared_uploads/takaaki.yayoi@databricks.com/five.jpg")
# img = Image.open("/dbfs/FileStore/shared_uploads/takaaki.yayoi@databricks.com/zero.jpg")
tf_image = np.array(img)
# Signatureに合わせます
tf_image = np.expand_dims(tf_image, axis=0)
input_example = np.expand_dims(tf_image, axis=0)
served_predictions = score_model(input_example)
print("分類結果:", served_predictions)
サンプルノートブック