Ten Simple Databricks Notebook Tips & Tricks for Data Scientists - The Databricks Blogの翻訳です。
"ベストなアイデアのいくつかはシンプルなものである!(some of the best ideas are simple!)"と言う格言が示す通り、小さな物事の積み重ねが大きな違いに繋がると言うことはよくあることです。2020年を通じて何回かのリリースを通じて、Databricksをよりシンプルするために、大きな違いに繋がる小さな機能追加を行いました。
本記事および関連ノートブックにおいては、データサイエンティストの開発経験を改善し、開発時間を短縮するために追加した、シンプルなマジックコマンドおよびノートブックにおけるユーザーインタフェースをご紹介します。
これらの機能は以下の通りとなります:
- %pip install
- %conda env export および update
- %matplotlib inline
- %load_ext tensorboard および %tensorboard
- コードをモジュール化するために %run による外部ノートブックの実行
- データのアップロード
- MLflow: Experimentの動的カウンター および Reproduce run ボタン
- UIに関するちょっとしたノウハウ
- SQLコードのフォーマット
- クラスターにログインするためのWebターミナル
シンプルにするために、個々の機能の使い方をこちらにまとめています。しかし、ノートブックをダウンロードすることをお勧めします。もし、Databricksの統合データ分析プラットフォームを利用したことが無いのでしたら、こちらから利用できます。ノートブックをDatabricks統合データ分析プラットフォームにインポートして実行するだけです。
1. %pipマジックコマンド: Pythonパッケージのインストール及びPython環境の管理
Databricks Runtime(DBR)あるいはDatabricks Runtime for Machine Learning(MLR)には一連のPython及び機械学習(ML)ライブラリがインストールされています。しかし、実行したいタスクに適合したライブラリやバージョンが存在しないケースがあります。この場合、%pipや%condaを使用することで簡単にクラスター上のPythonパッケージをカスタマイズすることができます。
この機能がリリースされる前は、データサイエンティストはinit scriptを作成し、wheelファイルをローカルで構築し、dbfs上にアップロードし、パッケージをインストールするためにinit scriptを実行する必要がありました。これは脆弱なプロセスです。今では、プライベートあるいはパブリックなリポジトリに対して%pip install <package>を実行するだけで済みます。
あるいは、複数のパッケージをインストールする必要がある場合には、%pip install -r <path>/requirements.txtを実行することができます。
pipとcondaを用いて、どの様にnotebookスコープのPython環境を管理するのかに関して理解を深めるのでしたら、こちらのブログを参考にしてください。
2. %condaおよび%pipマジックコマンド: Notebook環境の共有
クラスター環境がセットアップされると、いくつかのことが実行できる様になります。
a) 以降のセッションで再インストールできる様にファイルを保存する
b) 他の人に保存したファイルを共有する
クラスターは揮発性なものですので、クラスターがシャットダウンされるとインストールされたライブラリは削除されます。インストールされたパッケージのリストを保存することは良いプラクティスです。これにより、再現性を確保できるとともに、データチームのメンバーが検証開発のために環境を再構築できる様になります。%condaマジックコマンドは2020年にリリースされた新機能の一部となっています。これにより作業がシンプルになります。インストールされたPythonパッケージのリストをエクスポートして保存するだけです。
%conda env export -f /jsd_conda_env.yml or %pip freeze > /jsd_pip_env.txt
共通のシャードあるいはパブリックdbfsから、別のデータサイエンティストが%conda env update -f <yaml_file_path>を実行することでPythonパッケージを再現することができます。
3. %matplotlibマジックコマンド: 画像をインラインに表示
探索的データ分析(EDA)においては、データの可視化は重要なステップとなります。データのクレンジング後に限らず、特徴量エンジニアリング、モデルトレーニングに至るまで、データにおけるパターン、関係性を見出すために可視化を行いたくなるでしょう。
数多くのデータ可視化のためのPythonライブラリのなかで、matplotlibが共通して用いられています。DBRやMLRにおいてはいくつかのPythonライブラリがインストールされていますが、現状matplotlib inline機能のみがノートブックセルでサポートされています。
DBR 6.5以降でビルトインされているマジックコマンドにより、display(figure)やdisplay(figure.show())の明示的な呼び出しや、spark.databricks.workspace.matplotlibInline.enabled = trueの設定なしにノートブックセルのインラインでグラフを表示することができます。
4. PyTorch、TensorFlowにおける%tensorboardマジックコマンド
最近発表した通り、Databricks Runtime(DBR)の一部としてリリースされたこのマジックコマンドは、ノートブックにTensorBoardから得られるトレーニングメトリクスを表示するものです。この新機能はこれまで提供していたdbutils.tensorboard.start()を置き換えるものになります。旧機能は別のタブでTensorBoardのメトリクスを参照する必要があり、データ分析者がノートブックから離れることでフローを切断するものでした。
もはや、データ分析者はノートブックを離れて別のタブでTensorBoardを参照する必要はありません。インラインでの可視化は開発者の体験とシンプルさを改善するものです。
DBRやMLRにインストールされているTensorFlowやPyTorchライブラリを利用することができますが、この記事ではPyTorch(ノートブックを参照ください)を使用しています。
%load_ext tensorboard
%tensorboard --logdir=./runs
5. 外部ノートブックを実行するための%runマジックコマンド
ソフトウェアエンジニアリングにおける一般的なデザインパターンおよびプラクティスを参考にして、データサイエンティストはクラス、変数、ユーティリティメソッドを外部のノートブックを定義できます。すなわち、データサイエンティストは、IDEでPythonモジュールをimportする様に、これらのクラスを"インポート"することができます。厳密に言うと、ノートブックの場合は、%run auxiliary_notebookコマンドを通じて、外部ノートブックで定義されたクラスが、現在実行しているノートブックのスコープに読み込まれる形になります。
これまで述べてきた新機能と異なり、これは新しいものではありませんが、この機能を利用することで、全体をまとまりあるものにし、driver(メイン)ノートブックの可読性を高めます。何人かの開発者は、データ処理を別のノートブックに分割するために外部ノートブックを活用しています。個々のノートブックがデータ処理、探索のためのデータ分析を行い、結果を呼び出し元のノートブックに返却します。
外部ノートブックの他の使い道としては、クラス、変数、ユーティリティ関数の再利用が挙げられます。例えば、UtilsやRFRModelなどのクラスが外部ノートブックcls/import_classesで定義されます。%run ./cls/import_classesを実行することで、呼び出し元のノートブックのスコープにこれら全てのクラスが読み込まれます。このシンプルな手順で、ノートブックが散在することが無くなります。クラスを定義し、コードをモジュール化し、再利用するだけです!
6. データのアップロード
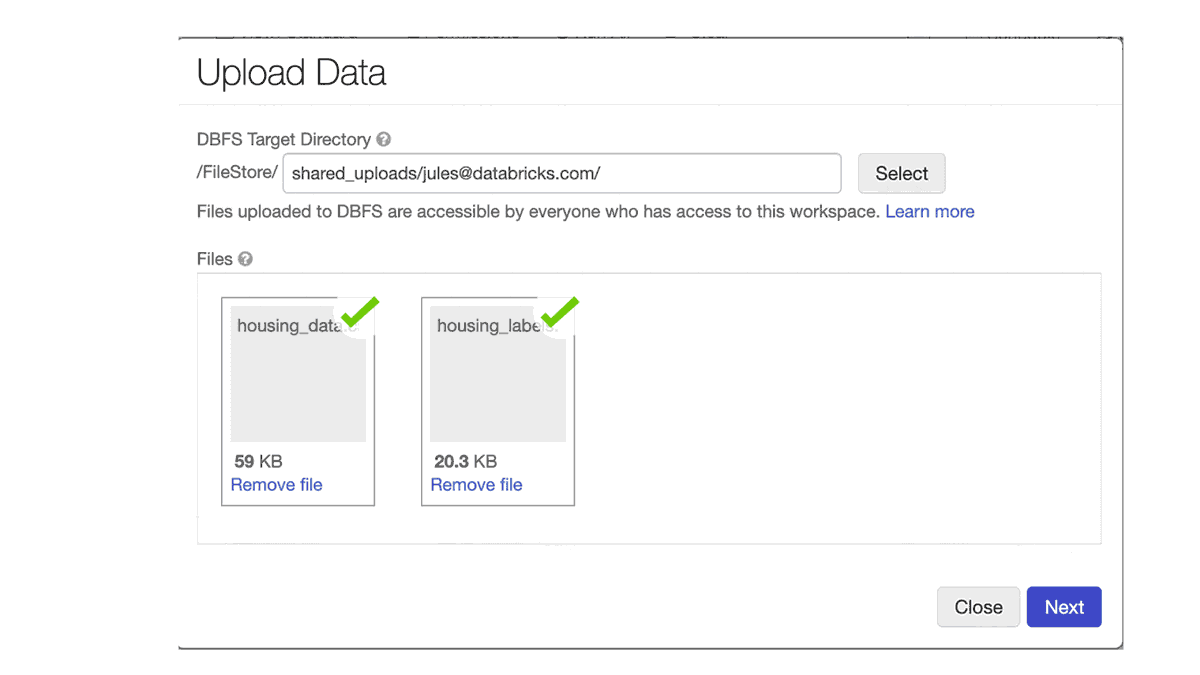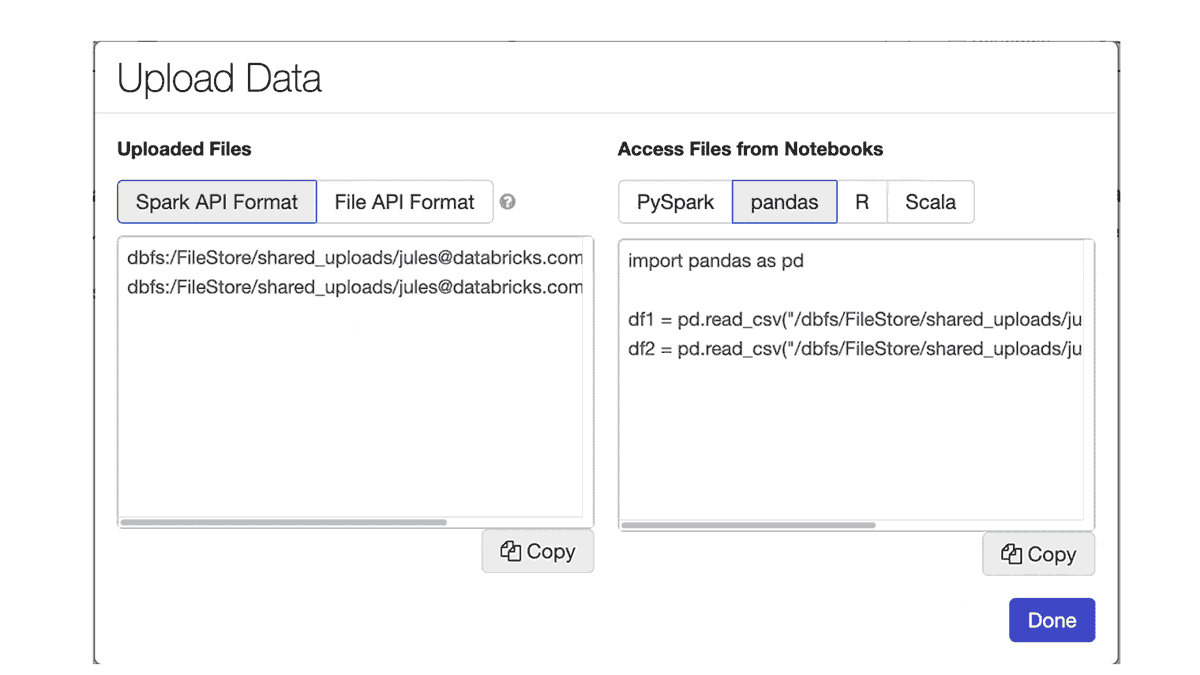
ラップトップにあるローカルのデータをDatabricksで分析したくなるケースがあるかと思います。ノートブックのFileメニューにある新たなデータアップロード機能でローカルデータをワークスペースにアップロードできます。デフォルトのアップロード先は /shared_uploads/your-email-address となりますが、アップロード先を選択できますし、Upload Fileダイアログからファイルを読み込むためのコードを取得することができます。今回のケースでは、CSVファイルを読み込むためのpandasのコードを選択しています。
7.1 MLflow Experimentの動的カウンター
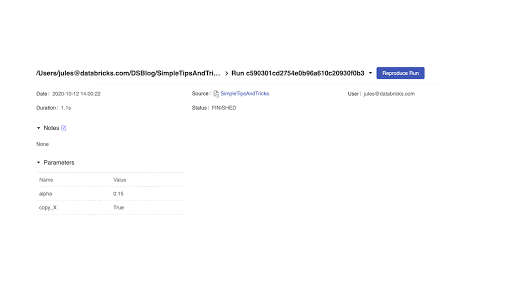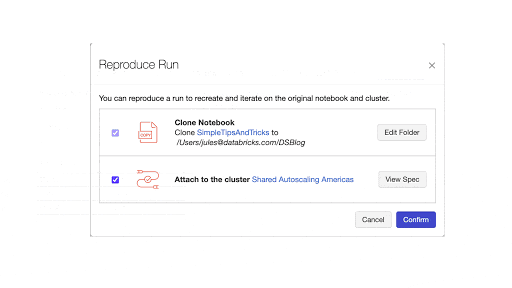
MLflowのUIはDatabricksと密に連携しています。MLflow APIを用いてモデルをトレーニングする都度、データサイエンティストにビジュアルなフィードバックを提供するためにExperimentラベルのカウンターが動的に増加します。

Experimentをクリックすることで、画面横に個々のRunのMLflowエンティティであるrun、パラメーター、メトリクス、モデルなどを含むサマリーを一覧で表示します。
7.2 MLflow Reproduce Runボタン
他の改善点として、Experimentを再現するためのノートブックを再作成する機能があります。MLflowのrunページからReproduce Runボタンをクリックすることでノートブックを生成し現在のクラスターにアタッチされます。
8. UIに関するちょっとしたノウハウ
データサイエンティストが自身のタスクを効率的にこなすために、データの中身を確認する、セル削除のアンドゥ、分割スクリーンの表示などを含め、ノートブックにおいては以下の改善がなされています:
より高速な処理実行のための電球ヒント(light bulb hint): ノートブック上のセルが実行される都度、Databricks runtimeは目の前のタスクを効率的にするためのヒントを提示することがあります。例えば、モデルのトレーニングを行なっている際には、MLflowによるパラメーター、メトリクスのトラッキングを提案します。

あるいは、SQLテーブルとしてParquet形式のデータフレームをSQLテーブルとして永続化しようとした際に、より効率的、信頼性のあるDelta Lakeのテーブルをお勧めします。また、バックエンドのエンジンが、最適化の余地がある複雑なSpark処理、あるいは、不均一なデータフレーム(一方が非常に大きく、一方が非常に小さい)のJOINを実行しようとしていることを検知した場合には、より良いパフォーマンスのためにApache Spark 3.0の適合クエリ実行を提案します。
これらの小さなノウハウによって、データサイエンティストやデータエンジニアが、最適化されたSparkの機能や、トレーニングを容易に管理できるMLflowの様なツールを活用できる様になります。
セル削除のアンドゥ: 重要なコードを開発する過程で、不可逆的にセルを削除してしまい、取り返しのつかない状態になって初めてそれに気づくと言うことを何度経験したことがありますでしょうか。今となっては、ノートブックが削除されたセルを追跡していますので、簡単にセル削除をアンドゥできます。
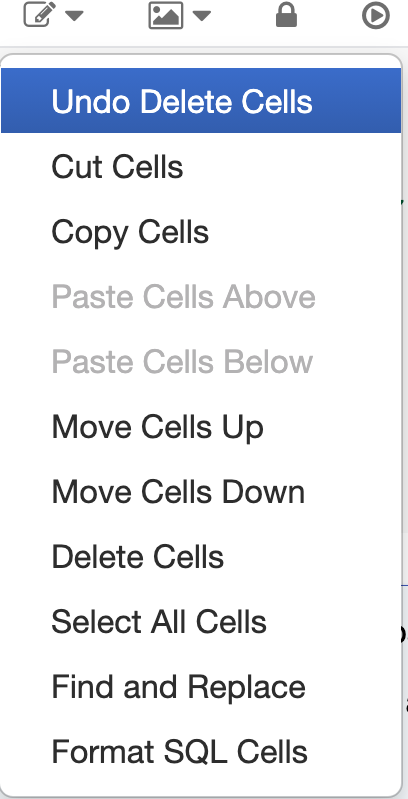
ここまでを全て実行(Run All Above): いくつかのシナリオにおいては、現在のセルの上までのセルにあったバグを修正し、上にあるセル全てを実行したいと言うケースがあるかと思います。この作業を簡単に実行できます。
コードコンプリーションのためのタブキー: 一般的なPython3の関数、Spark 3.0のメソッド両方に対して、メソッド名の後でタブキーを押すと、メソッド、プロパティがドロップダウンリストが表示されます。

Side-by-Sideビュー: PyCharmの様なPython IDE同様、ノートブック上でマークダウンの内容とレンダリング結果を横並びで表示することができます。メニューのView->Side-by-Sideを選択することでビューを切り替えることができます。
9. SQLコードのフォーマット
新たな機能ではないですが、このノウハウによって、フリーフォーマットで書かれたSQLを簡単にフォーマットできます。

10. クラスターにログインするためのWebターミナル
データサイエンティストを含むデータチームの方々は、ノートブックから直接ドライバーノードにログインできます。面倒なsshの設定が必要となるsshマジックコマンドの%shは不要です。さらに、システム管理者、セキュリティ担当は仮想プライベートネットワークにsshポートを開けることを嫌がります。ユーザー視点からしても、ドライバーノードにアクセスするためにSSHキーのセットアップが不要です。お使いのワークスペースの管理者が、クラスターに対して"Can Attach To"権限を付与していれば、すぐにWebターミナルを利用できます。
こちらの記事で発表されている様に、完全にインタラクティブなシェルとドライバーノードに対して制御されたアクセスを提供します。Webターミナルを使うためには、ドロップダウンメニューからTerminalを選択します。
これらの機能は小さいながらも、実験、プレゼンテーション、データ探索に至るプロセスにおける摩擦を軽減し、コードフローを円滑にします。次回は、これらのシンプルなアイデアをDatabricksノートブック上で実現してみてください。
サンプルノートブックをダウンロードいただき、Databricks統合データ分析プラットフォーム(DBR 7.2以降あるいはMLR 7.2以降)でインポートの上、活用してみてください。
データチームがどのように困難な課題を解決するのかを知りたいのでしたら、是非Data + AI Summit Europeを見てください。