本書では、以下で説明されている資格情報パススルー(クレディンシャルパススルー)を用いてマウントしたADLSに格納されているzipファイルを解凍し、zipファイルにあるCSVを保存する流れを説明します。
資格情報パススルーを用いることで、ADLSに対するアクセスコントロールを保持したままDatabricksからデータにアクセスすることができるのでセキュリティレベルを高く保つことができます。
本記事で説明している手順はこちらのノートブックにまとめています。
要件
- 資格情報パススルー(クレディンシャルパススルー)を用いてマウントしたAzure Data Lake Storage(ADLS)には機密性が高い情報が格納されており、これをDatabricksクラスター上には保存したくない。
- ADLS上のファイルはZIPで圧縮されているので、これを解凍してCSVとして保存し直したい。この場合にもDatabricks上には保存したくない。
制限
普通に考えれば難しいことはないと思うのですが、いくつかの制限のため思った以上に難しいものになっています。
- Sparkはネイティブでzipフォーマットに対応していません。このため、以下のマニュアルにあるように、通常はクラスターのローカルファイルシステムにファイルをコピーし、unzipして戻すという流れが推奨です。しかし、上の要件からこの手法を取ることはできません。
-
制限事項にあるように、資格情報パススルーを用いてADLSをマウントした場合、通常であればローカルファイルAPIからアクセスできるFUSEマウントポイント
/dbfsがサポートされていないため、ローカルファイルAPIからADLSのマウントポイントにアクセスすることができません。
FUSE マウント (
/dbfs) は、Databricks Runtime 7.3 LTS 以降でのみ使用できます。 資格情報のパススルーが構成されているマウント ポイントは、FUSE マウントではサポートされていません。
アプローチ
資格情報パススルーが設定されたFUSEマウントポイントがサポートされていないということは、ローカルファイルAPIでの操作ができないことを意味します。このため、Spark API経由でファイルを操作します。具体的には、ADLSとのファイルのやり取りはSpark APIを用い、解凍処理をPythonのライブラリzipfileで行うというアプローチを取ります。
以下のステップでは、dbfs:/mnt/test_mntにADLSがマウントされていることを前提としています。
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<コンテナ名>@<ストレージアカウント名>.dfs.core.windows.net/",
mount_point = "/mnt/test_mnt",
extra_configs = configs)
解凍処理
SparkのbinaryFileコネクターでzipファイルを読み込み、解凍処理を行うUDF(User Defined Function)を定義します。
from pyspark.sql.functions import *
from pyspark.sql.types import *
schema = StructType([
StructField("file_name", StringType(), False),
StructField("contents", StringType(), False)
])
def zip_extract_file(binary_data):
# ZIPを解凍するUDF
import zipfile, io
in_memory_data = io.BytesIO(binary_data)
with zipfile.ZipFile(in_memory_data, "r") as zf:
# zipファイルあたり1ファイルを想定
target_file = zf.namelist()[0]
with io.TextIOWrapper(zf.open(target_file), encoding="utf-8") as f:
contents = f.read()
return (target_file, contents)
decompress_func = lambda x: zip_extract_file(x)
udf_decompress = udf(decompress_func, schema)
注意
上のUDFでは、1つのzipファイルに1つのcsvファイルが格納されていることを想定しています。複数ファイルがzipされている場合には、処理の修正が必要となります。
上のUDFは、解凍したファイル名をfile_name、解凍した生データをcontentsに格納して返却します。
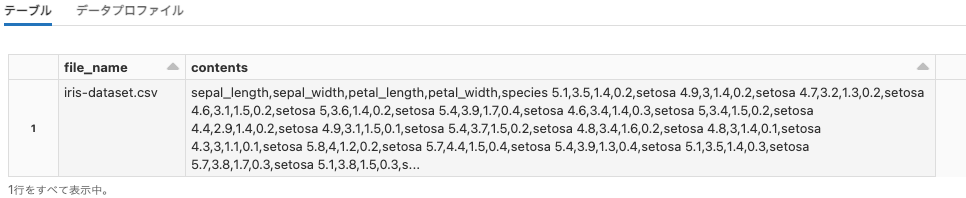
以下を実行することで、dbfs:/mnt/test_mnt/iris-dataset.csv.zipを解凍して、解凍結果をデータフレームに追加します。
# バイナリーファイルとして読み込み
df = spark.read.format("binaryFile").load("dbfs:/mnt/test_mnt/iris-dataset.csv.zip")
# UDFを適用して解凍
df = df.withColumn('decoded', udf_decompress('content')).select("decoded.file_name", "decoded.contents")
display(df)
参考資料
- python - How do I read text files within a zip file? - Stack Overflow
- Python : How to get the list of all files in a zip archive – thisPointer
- Apache Spark Assign The Result Of Udf To Multiple Dataframe Columns
- pyspark - Write each row of a spark dataframe as a separate file - Stack Overflow
解凍ファイルの保存
この時点では、各行にファイル名と生データが格納されている状態です。以下のステップで単一のファイルとしてCSVを保存します。
# '_started'と'_committed_'で始まるファイルを書き込まないように設定
spark.conf.set("spark.sql.sources.commitProtocolClass", "org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol")
# '_SUCCESS'で始まるファイルを書き込まないように設定
spark.conf.set("mapreduce.fileoutputcommitter.marksuccessfuljobs","false")
# 最初の行からファイル名を取得
file_name_to_save = df.first().file_name
# 保存先
file_path_to_save = f'dbfs:/mnt/test_mnt/melted_csv/{file_name_to_save}'
# repartition(1)を指定して1つのファイルに保存します
# クォーテーションがあると読み込み時にパースできないので除外します
df.select("contents").repartition(1).write.option("quote", "").mode("overwrite").csv(file_path_to_save)
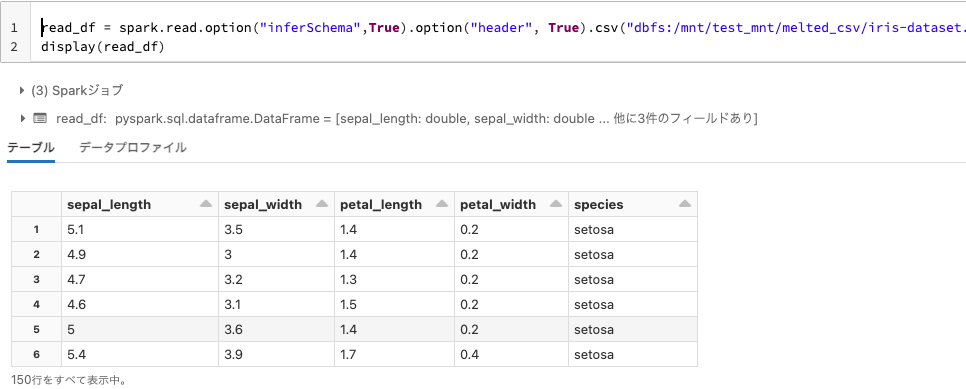
保存したCSVの読み込み
保存時に指定したファイル名はフォルダとなりますが、問題なくCSVを読み込むことができます。
read_df = spark.read.option("inferSchema",True).option("header", True).csv("dbfs:/mnt/test_mnt/melted_csv/iris-dataset.csv/")
display(read_df)
参考資料
- pyspark - Save each row in Spark Dataframe into different file - Stack Overflow
- python - How to save a PySpark dataframe as a CSV with custom file name? - Stack Overflow
- Databrikcs(Spark)のPysparkにて単一ファイルとしてCSVファイルを書き込む方法 - Qiita