Top 5 Databricks Performance Tips - How to Speed Up Your Workloads - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
イントロダクション
ソリューションアーキテクトとして我々は日々、お客様がDatabricksにおけるジョブの最高の性能を手にするお手伝いをするために密接にお客様と連携しており、多くのケースで同じアドバイスに辿り着きます。お客様と会話を行い、数回の微調整のみで2倍、3倍、あるいはそれ以上の性能を得ることはよくあることです。それでは、秘密は何なのでしょうか?我々はこれをどのように行っているのでしょうか?ここでは、お客様がお使いDatabricksで性能に大きなインパクトをもたらした5つのテクニックをご紹介します。
まとめると以下の通りとなります。
- より大規模なクラスターを使います 当たり前のように聞こえるかもしれませんが、これが我々が確認した問題のナンバー1です。ワークロードに対して小規模なクラスターを使うより、大規模なクラスターを使ったとしても、実際それほど高価にはなりません。皆様が本書から得られるべき何かがあるとすれば、それはこの事です。実際にセクション1をお読みください。
- Databricksの新しい超高速エンジンである Photonを使います。詳細はセクション2をご覧ください。後悔はさせません。
- ご自身の設定を綺麗にします。 あるバージョンのApache Spark™から次のバージョンに設定を引き継ぐことで、多くの問題を引き起こします。綺麗にしましょう!詳細はセクション3をご覧ください。
- Deltaキャッシングを使います。 もし、キャッシュを適切に活用していないのであれば改善の余地があります。詳細はセクション4をご覧ください。
- 遅延評価に注意します。Sparkのコードを書いていて、このことがピンとこないのであればセクション5にジャンプしてください。
- ボーナスのティップ!テーブル設計は超重要です。今後の記事でこの件を深掘りしますが、今時点ではDelta Lakeベストプラクティスのガイドをチェックしてください。
1. お使いのクラスターに馬力を与えましょう!
これがお客様が行う間違いのナンバー1です。多くのお客様は、4コアの2つのワーカー持つ小さいクラスターを作成しており、何をするにしても永遠の時間を必要としています。懸念事項は常に同じです。彼らは大規模なクラスターに多くの費用を費やしたくないのです。ここで一つ:ワークロードに対して小規模なクラスターを使うより、大規模なクラスターを使ったとしても、実際それほど高価にはなりません。単に高速になるだけです。
鍵となるのは、皆様はクラスターをワークロードの長さの分だけレンタルしているということです。なので、2ワーカーのクラスターを起動して、1時間処理を行なったとすると、これらの時間全てにおけるワーカーに対して支払いを行うことになります。しかし、4ワーカーのクラスターを起動し、30分処理を行なったとするならば、実際のコストは同じになります!そして、クラスターで行う処理が十分にあるのであれば、このトレンドは継続します。
このポイントを説明する仮定のシナリオを示します。
| ワーカー数 | 時間当たりのコスト | ワークロードの処理時間(時間) | ワークロードのコスト |
|---|---|---|---|
| 1 | $1 | 2 | $2 |
| 2 | $2 | 1 | $2 |
| 4 | $4 | 0.5 | $2 |
| 8 | $8 | 0.25 | $2 |
ジョブに要する現実世界の時間を劇的に削減しつつも、ワークロードのコストが一定であることに注意してください。ですので、追加のコストを費やすことなしに、Databricksクラスターのスペックを引き上げてワークロードの高速化を行いましょう。本当にこれ以上にシンプルなことはありません。
2. Photonを使いましょう
私のエンジニアリングの同僚がC++でSpark実行エンジンを再実装し、これをPhotonと名付けました。結果は衝撃的なものです!
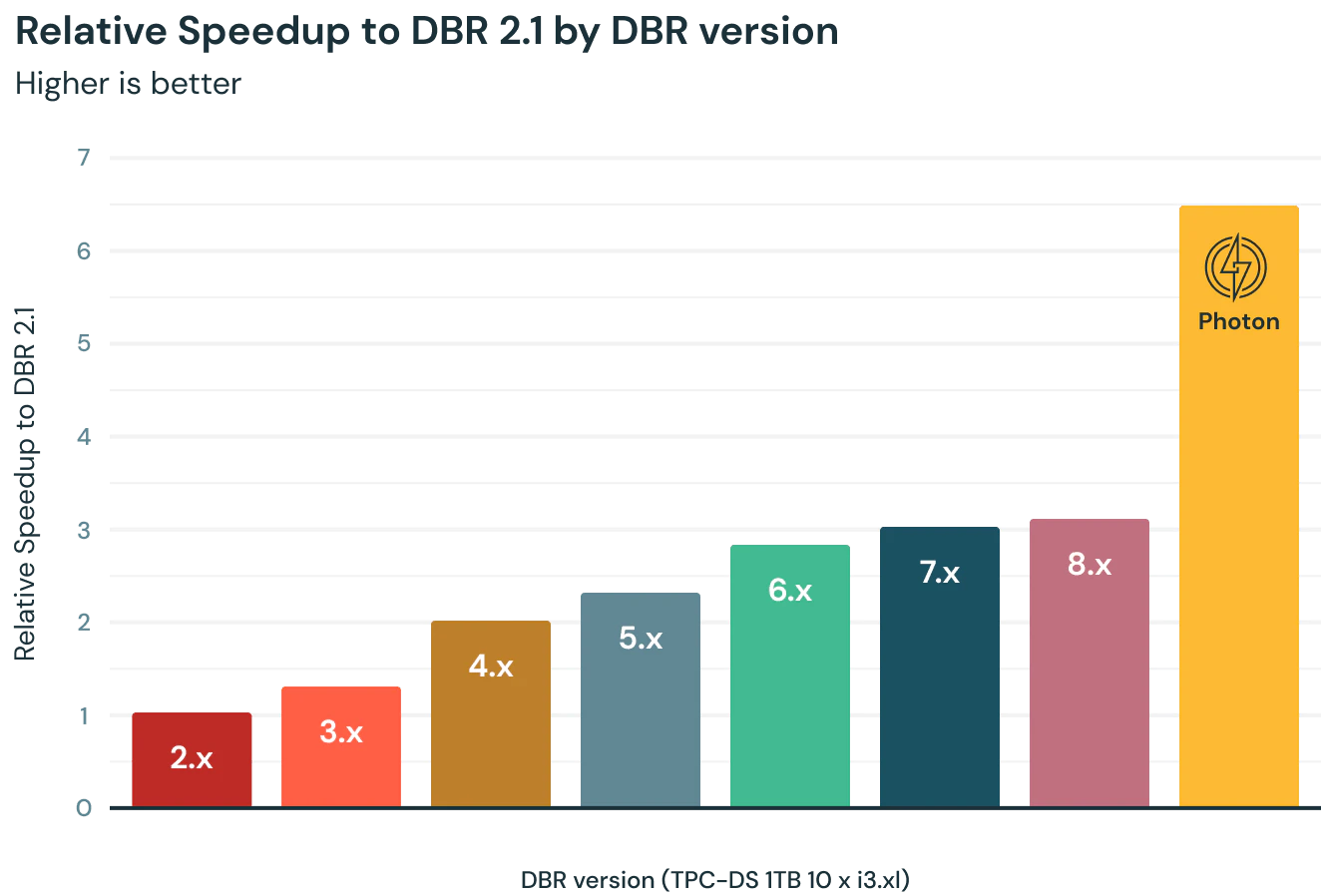
ネイティブコードでエンジンを実行することによる明確な改善に加え、かれらはCPUレベルのパフォーマンス機能と優れたメモリー管理を実現しました。さらに、ParquetのライターをC++で再実装しました。これにより、Parquet、Delta(Parquetをベースにしています)への書き込みも非常に高速になりました!
しかし、Photonが何を高速化しているのを明確にさせてください。これは、いかなるビルトインの関数やオペレーションの計算速度とParquet、Deltaへの書き込み速度を改善します。それではJOINは?大丈夫です!集計処理は?もちろんです!ETLは?間違いありません!私が書くUDF(ユーザー定義関数)は?すみませんが、それはここでは助けになりません。時代遅れのオンプレミスのデータベースからの読み込みに多くの時間を費やしているジョブは?残念ながら、それもここでは助けになりません。
良いニュースは、これが役立つところでは役立つということです。なので、あなたのジョブの一部が高速化されなかったとしても、他の部分は高速化されます。また、多くのジョブはネイティブのオペレーションで記述されているので、Deltaに書き込む多くの時間が高速化され、Photonが非常に役立つことになります。いずれにしても試してみてください。結果に驚くことになるでしょう!
3. 古い設定を綺麗にしましょう
あなたは、あるバージョンからあるバージョンに引き継いだSpark設定を知ってはいますが、それが何をするのかを誰も知らないのではないでしょうか?害は無いかもしれません。我々は、シンプルに古い設定を綺麗にすることでジョブの実行が数時間から数分に削減した例を目撃しています。ある特定のSparkバージョンだけの設定、うまくできなかったパフォーマンスの調整、あるいは実際にはなんの意味もないがどこかのブログ記事から引っ張ってきたものもあるかもしれません。少なくとも、このような状況に皆様がいるのであれば、Spark設定の見直しを行う価値があると言えます。多くの場合、デフォルトの設定がベストであり、ここから改善することだけが可能です。あなたの設定があなたを邪魔しているのかもしれません。
4. Deltaキャッシュはあなたの友達です
これは当たり前のように見えるかもしれませんが、クラウドストレージ(S3、ADLS)からデータをロードし、アクセスを高速化するためにワーカーのSSDに保持する、Deltaキャッシュを多くの人々が使っていないことに驚くかもしれません。
もし、Databricks SQLのエンドポイントをお使いなのであれば、あなたはついています。これらではデフォルトでキャッシングを行います。実際、エンドポイントを起動する際には、お使いの「ホットな」テーブルを事前ロードしておくためにCACHE SELECT * FROM tableをしておくことをお勧めします。
通常のクラスターを使用しているのであれば、Amazon Web Services (AWS)のi3シリーズ、Azure DatabricksであればLシリーズかEシリーズ、GCPであればn2を使っていることを確認してください。これらには全て、高速なSSDが搭載されており、デフォルトキャッシュが有効化されています。
もちろん、皆様のアプローチは変化することがあります。同じテーブルから何度も何度も読み込みを行うBIを行なっているのであれば、キャッシュによる効果は計り知れません。しかし、何かしらのETLジョブでシンプルにテーブルを一度読み込み、結果を書き出すのであれば、それほどの効果は得られないかもしれません。あなた自身があなたのジョブを誰よりも理解しているのです。前進して打ち破ってください。

5. 遅延評価に気を配りましょう
あなたがSQLのみを使用するあるいはBIを行うデータアナリスト、データサイエンティストなのであればこのセクションをスキップしてください。しかし、あなたがデータエンジニア、あるいは、DatabricksとSparkを用いて処理を行う人なのであれば読み進めてください。
select、groupBy、filterなどのSparkコードを記述する際、実際には実行計画を立てていることになります。これらの関数を実行すると、コードはすぐに結果を返すことに気づくでしょう。これは、実際には何の計算処理も行なっていないためです。なので、あなたがペタバイトのデータを持っていたとしても、1秒以内に結果が返ってきます。
しかし、結果を書き出そうとすると、より長い時間を要することに気づくと思います。これは遅延評価によるものです。あなたの実行計画が実際に実行されるのは、結果の表示や書き出しをしようとしたタイミングです。
# Build an execution plan.
# This returns in less than a second but does no work
df2 = (df
.join(...)
.select(...)
.filter(...)
)
# Now run the execution plan to get results
df2.display()
しかし、ここにはキャッシュが存在します。結果を表示、書き出しする都度、再度実行計画が実行されます。同じコードロックですが、いくつかのオペレーションで拡張されたものを見てみましょう。
# Build an execution plan.
# This returns in less than a second but does no work
df2 = (df
.join(...)
.select(...)
.filter(...)
)
# Now run the execution plan to get results
df2.display()
# Unfortunately this will run the plan again, including filtering, joining, etc
df2.display()
# So will this…
df2.count()
このコードの開発者は、これらは結果を3回表示していると考えるかもしれませんが、実際には同じ処理を3回実行しているのです。ウップス。これは余計な作業です。これは、よくある間違いです。それでは、なぜ遅延評価があって、これに対して何をすべきなのでしょうか?
簡単に言えば、遅延評価による処理は、そうで無いものよりも高速だからです。DatabricksとSparkは、完全な実行計画を参照し、数倍の規模で処理時間を削減できる最適化の機会を見つけ出します。これは素晴らしいことですが、どのように追加の計算処理を回避できるのでしょうか?答えは非常にわかりやすいものです。再利用する計算結果を保存します。
同じコードブロックを見てみますが、今度は再計算を回避しましょう。
# Build an execution plan.
# This returns in less than a second but does no work
df2 = (df
.join(...)
.select(...)
.filter(...)
)
# save it
df2.write.save(path)
# load it back in
df3 = spark.read.load(path)
# now use it
df3.display()
# this is not doing any extra computation anymore. No joins, filtering, etc. It’s already done and saved.
df3.display()
# nor is this
df3.count()
これはDeltaキャッシュが有効化されている場合は特に効果的です。まとめると、遅延評価によって、皆様は大きなメリットを享受できますが、多くのお客様が見逃しているものです。ですので、この存在を理解し、不要な計算処理を回避するために、再利用する結果を保存しましょう。
次の記事:テーブルをきちんと設計しましょう!
これは信じられないほど重要なトピックですが、別の記事として記載する必要があります。楽しみにしていてください。それまでは、Delta Lakeベストプラクティスのガイドをチェックしてください。