以前に以下の記事を書きました。
こちらでは、Unity Catalogのボリューム機能を用いることで画像ファイルを簡単に扱えることを説明しました。
今回、さらに話を広げて、非構造化の画像ファイルからどのように構造化したテーブルに変換するのかを説明します。
オブジェクトストレージにおける小さなファイル問題
上述のボリューム機能も実態はクラウドのオブジェクトストレージです。ファイルの登録は簡単ですが、大量の画像ファイルに対して一括で処理を行いたい、集計処理を行いたいというケースでは、小さな大量のファイルに対するアクセスによるパフォーマンスの低下や管理が大変というような問題も出てきます。
Delta Lakeによる画像の格納

Delta Lakeでは、Sparkの画像データソースと組み合わせることで、テーブルの一つのカラムとして画像を格納することができます。これによって、テーブルで画像を管理しつつも、以下のようなDelta Lakeのメリットを享受することができます。
- 高速なクエリー
- ストリーム処理
- ACIDトランザクション
- 設定可能な圧縮処理
探索メインか格納メインか
Delta lakeでは画像の2つのフォーマットをサポートしています。
- イメージフォーマット - 探索向け
画像をデコードし、サムネイルを作成します。データのサブセットを可視化し、サンプルデータの高さや幅、チャンネル数をチェックする際に有用です。 - バイナリーファイルフォーマット - 格納向け
それぞれのファイルは、バイナリーのコンテンツとメタデータを持つ単一行として格納されます。画像のデコードは行いません。
格納形態 - 生の画像ファイル

この形態ではDeltaは使いません。画像ファイルをオブジェクトストレージに格納するだけです。
- メリット
- 管理が簡単
- デメリット
- パフォーマンスが出ない
- バージョン管理ができない(タイムトラベル)
- データを拡張できない(列を追加できない)
画像の格納形態 - Deltaテーブルに格納

- メリット
- バージョン管理(タイムトラベル)
- 大規模処理でも高いパフォーマンス(OPTIMIZE、Z-Orderなど)
- Single source of truth(データが散在しない)
- 管理が簡単
- デメリット
- DeltaのAPIを使う必要あり
この形態はメリットが多いですが、カラムに画像を持つことになるので、レコードあたりのサイズが大きくなりボトルネックになる場合もあります。この場合、次のハイブリッドアプローチを取ります。
画像の格納形態 - ハイブリッド
画像データ自体はファイルで持ち、ファイルへのパスをDelta Lakeテーブルで保持します。

サンプルノートブックのウォークスルー
こちらで紹介したノートブックを追加います。
最初にS3から画像ファイルをダウンロードします。この時点ではDatabricksクラスターのドライバーノードのローカルストレージに保持しています。
%pip install awscli
%sh
mkdir -p /tmp/data
aws s3 cp --no-progress --no-sign-request s3://amazon-visual-anomaly/VisA_20220922.tar /tmp
%sh
mkdir -p /tmp/data
tar xf /tmp/VisA_20220922.tar --no-same-owner -C /tmp/data/
画像ファイルをボリュームに移動
%sh
rm -rf /Volumes/takaakiyayoi_catalog/pcb/data/pcb1
mkdir -p /Volumes/takaakiyayoi_catalog/pcb/data/pcb1/labels
cp -r /tmp/data/pcb1/Data/Images/ /Volumes/takaakiyayoi_catalog/pcb/data/pcb1/
cp /tmp/data/pcb1/image_anno.csv /Volumes/takaakiyayoi_catalog/pcb/data/pcb1/labels/
カタログエクスプローラからボリューム上のファイルを確認できます。
ボリューム上の画像ファイルにはPILなどでもアクセスできます。
from PIL import Image
import matplotlib.pyplot as plt
def display_image(path, dpi=300):
img = Image.open(path)
width, height = img.size
plt.figure(figsize=(width / dpi, height / dpi))
plt.imshow(img, interpolation="nearest", aspect="auto")
display_image("/Volumes/takaakiyayoi_catalog/pcb/data/pcb1/Images/Normal/0000.JPG")
display_image("/Volumes/takaakiyayoi_catalog/pcb/data/pcb1/Images/Anomaly/000.JPG")

テーブルへの保存
%sql
-- 使用するDeltaテーブルのリセット
USE takaakiyayoi_catalog.pcb;
DROP TABLE IF EXISTS circuit_board;
DROP TABLE IF EXISTS circuit_board_gold;
DROP TABLE IF EXISTS circuit_board_label;
DROP TABLE IF EXISTS circuit_board_prediction;
cloud_storage_path="/Volumes/takaakiyayoi_catalog/pcb/data/pcb1"
Auto LoaderによるCSVラベルファイルのロード
こちらは画像ファイルではないのですが、画像のラベルファイルをテーブルにロードしておきます。
from pyspark.sql.functions import substring_index, col
(
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("header", True)
.option("cloudFiles.schemaLocation", f"{cloud_storage_path}/circuit_board_label_schema")
.load(f"{cloud_storage_path}/labels/")
.withColumn("filename", substring_index(col("image"), "/", -1))
.select("filename", "label")
.withColumnRenamed("label", "labelDetail")
.writeStream.trigger(availableNow=True)
.option("checkpointLocation", f"{cloud_storage_path}/circuit_board_label_checkpoint")
.toTable("circuit_board_label")
.awaitTermination()
)
display(spark.table("circuit_board_label"))

可視化してラベルの割合を確認します。

Auto Loaderによるバイナリーファイルのロード
これで、画像をロードするためにAuto Loaderを用い、ラベルのカラムを作成するためにspark関数を活用することができます。また、テーブルとして画像のコンテンツとラベルを簡単に表示することができます。DatabricksにおけるテーブルのデフォルトフォーマットはDelta Lakeなので、toTableでテーブルに保存すると自動でDeltaテーブルになります。
そして、以下ではPySparkを使っているので、大量の画像ファイルに対して同じ処理を適用する際には、クラスターのコア数を増加させることでパフォーマンスを簡単に改善することができます。
from pyspark.sql.functions import substring_index, col, when
(
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "binaryFile")
.option("pathGlobFilter", "*.JPG")
.option("recursiveFileLookup", "true")
.option("cloudFiles.schemaLocation", f"{cloud_storage_path}/circuit_board_schema")
.load(f"{cloud_storage_path}/Images/")
.withColumn("filename", substring_index(col("path"), "/", -1))
.withColumn(
"labelName",
when(col("path").contains("Anomaly"), "anomaly").otherwise("normal"),
)
.withColumn("label", when(col("labelName").eqNullSafe("anomaly"), 1).otherwise(0))
.select("filename", "content", "label", "labelName")
.writeStream.trigger(availableNow=True)
.option("checkpointLocation", f"{cloud_storage_path}/circuit_board_checkpoint")
.toTable("circuit_board")
.awaitTermination()
)
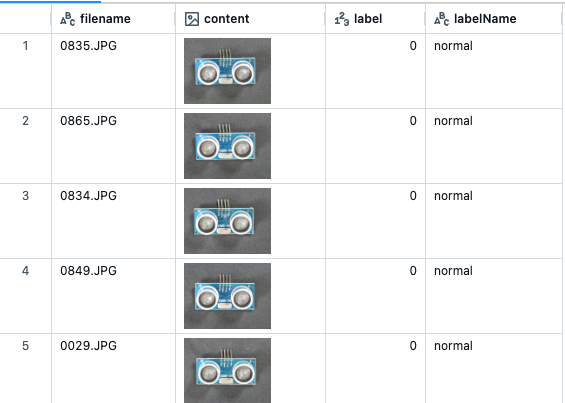
display(spark.table("circuit_board"))
content列にサムネイルが表示されています。
ラベルと画像テーブルをマージ
画像が格納されていてもテーブルとして問題なく扱えるので、joinも可能です。
%sql
CREATE TABLE circuit_board_gold as (
select
cb.*,
labelDetail
from
circuit_board cb
inner join circuit_board_label cbl on cb.filename = cbl.filename
);
画像テーブルに対する自動最適化を有効化
自動最適化は2つの補完的な機能となります: 最適化書き込みとオートコンパクションです。
%sql
ALTER TABLE circuit_board_gold SET TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true, delta.autoOptimize.autoCompact = true);
ALTER TABLE circuit_board SET TBLPROPERTIES (delta.autoOptimize.optimizeWrite = true, delta.autoOptimize.autoCompact = true)
最終テーブルに対するクエリー
%sql
select
*
from
circuit_board_gold
limit 10

リネージの確認
ボリューム、テーブルとデータを加工してきましたが、これらの依存関係はすべてリネージとして記録されています。
