サーバレスSQLに次いで、ジョブもサーバレス化されます。従来のジョブではジョブクラスターの起動に数分を要していましたが、サーバレスになることで十数秒でジョブクラスターが起動して、すぐにジョブが実行されます。
注意
- 本機能はパブリックプレビューです。
- こちらの機能は特定のリージョンで利用できます。執筆時点では日本リージョンでは利用できません。
ノートブックの準備
クイックスタートに従ってノートブックを作成します。
baby_names_csv_load
import requests
response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv')
csvfile = response.content.decode('utf-8')
dbutils.fs.put("/Volumes/takaakiyayoi_catalog/workflow/my-volume/babynames.csv", csvfile, True)
spark_babynames_year_filter
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/takaakiyayoi_catalog/workflow/my-volume/babynames.csv")
babynames.createOrReplaceTempView("babynames_table")
years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist()
years.sort()
dbutils.widgets.dropdown("year", "2014", [str(x) for x in years])
display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
ジョブの作成
上のノートブックを指定して、タスクを作成します。なお、ノートブックを選択する際に最近使用したアイテムタブを使うと、クイックにノートブックにアクセスできて便利です。
サーバレスワークフローが有効化されているワークスペースでは、デフォルトのクラスターがサーバレスになっています。
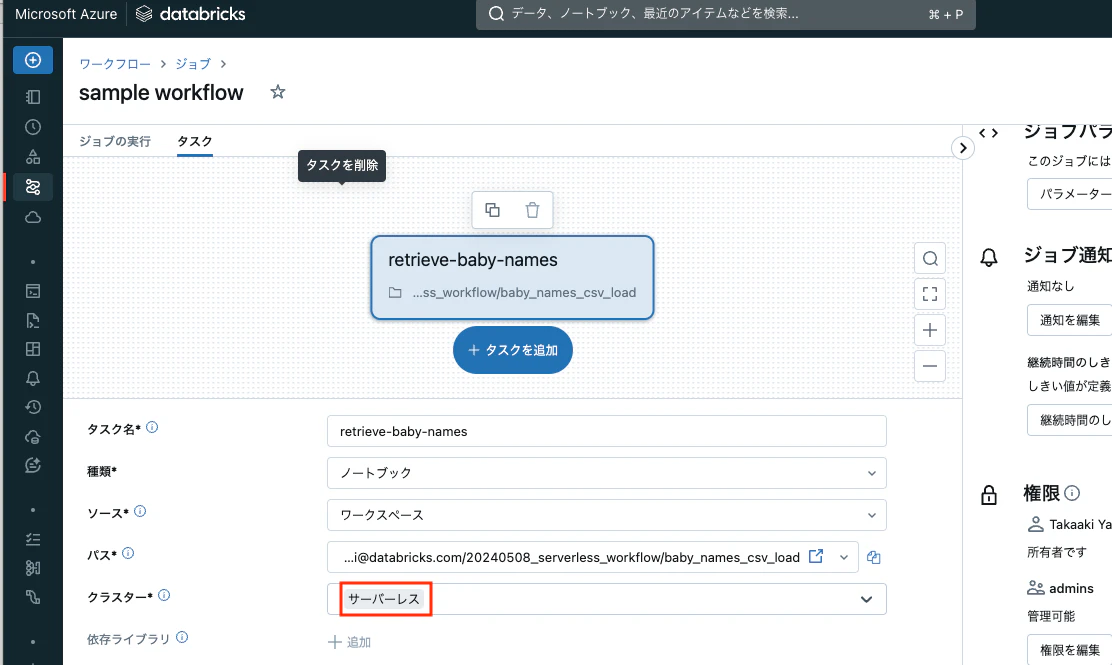
後段のタスクとして二つ目のノートブックも指定します。

これでサーバレスのジョブが作成されました。
ジョブの実行
こちらをご覧ください。従来のジョブですと数分待ちますが、数十秒でジョブの実行が始まります。
(日本リージョンに来たら)こちらの機能も是非ご活用ください!