はじめに
Ateam Brides Inc. Advent Calendar 2020の2日目は
株式会社エイチームブライズ サイト開発部 20卒エンジニアの@takaHALが担当します!
やること

こういうデータが何百、何千とある場合に
データの転送を楽にサクッと行いたい!!
csvとmysql間の転送を公式のクイックスタートを元に試します。
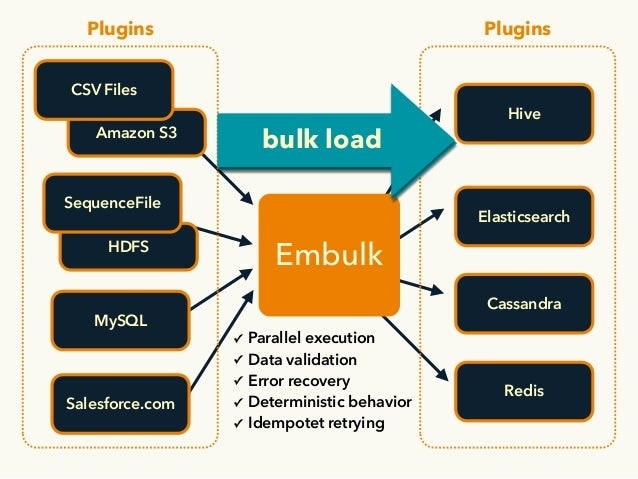
Embulk とは

様々なストレージ、DB、NoSQL、クラウドサービス間のデータ転送をサポートしてくれるオープンソースのETL(Extract/Transform/Load)ツール
豊富なプラグインを使用することで様々なデータ転送を実現することができます。
- csv → mysql
- mysql → BigQuery
- SalesForce → BigQuery
- mysql → Elasticsearch
などのデータが転送可能です。
引用: Embulk, an open-source plugin-based parallel bulk data loader
Embulkドキュメント
https://github.com/embulk/embulk
セットアップ
公式のクイックスタートを見ながらセットアップします。
$ curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"
$ chmod +x ~/.embulk/bin/embulk
$ echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
$ source ~/.bashrc
サンプルを動かしてみる
$ embulk example ./try1
$ embulk guess ./try1/seed.yml -o config.yml
- 作成されたサンプル
in:
type: file
path_prefix: ./try1/csv/sample_
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
null_string: 'NULL'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
out: {type: stdout}
config.ymlをみてみましょう embulkの書き方としては
- in (データを取得する部分)
- out (データを出力する部分)
の二つをそれぞれオプションを記載していくことで inで取ってきたものを → outで指定したところへのデータ転送を行います
in:
type: file
path_prefix: ./try1/csv/sample_
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
null_string: 'NULL'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
out: {type: stdout}
$ embulk preview config.yml
- embulk preview config.yml
embulk previewコマンドを利用することでどんなデータが転送されるかを事前にチェックすることができます。
+---------+--------------+-------------------------+-------------------------+----------------------------+
| id:long | account:long | time:timestamp | purchase:timestamp | comment:string |
+---------+--------------+-------------------------+-------------------------+----------------------------+
| 1 | 32,864 | 2015-01-27 19:23:49 UTC | 2015-01-27 00:00:00 UTC | embulk |
| 2 | 14,824 | 2015-01-27 19:01:23 UTC | 2015-01-27 00:00:00 UTC | embulk jruby |
| 3 | 27,559 | 2015-01-28 02:20:02 UTC | 2015-01-28 00:00:00 UTC | Embulk "csv" parser plugin |
| 4 | 11,270 | 2015-01-29 11:54:36 UTC | 2015-01-29 00:00:00 UTC | |
+---------+--------------+-------------------------+-------------------------+----------------------------+
サンプルのcsv
previewで問題なさそうなら実行するという流れになります。
このままだとUTCの時間なのでタイムゾーンを変更してみます
parserの部分にdefault_timezone: 'Asia/Tokyo'を追加します
parser:
default_timezone: 'Asia/Tokyo'
+---------+--------------+-------------------------+-------------------------+----------------------------+
| id:long | account:long | time:timestamp | purchase:timestamp | comment:string |
+---------+--------------+-------------------------+-------------------------+----------------------------+
| 1 | 32,864 | 2015-01-27 10:23:49 UTC | 2015-01-26 15:00:00 UTC | embulk |
| 2 | 14,824 | 2015-01-27 10:01:23 UTC | 2015-01-26 15:00:00 UTC | embulk jruby |
| 3 | 27,559 | 2015-01-27 17:20:02 UTC | 2015-01-27 15:00:00 UTC | Embulk "csv" parser plugin |
| 4 | 11,270 | 2015-01-29 02:54:36 UTC | 2015-01-28 15:00:00 UTC | |
+---------+--------------+-------------------------+-------------------------+----------------------------+
$ embulk run config.yml
- embulk run config.yml
preview で確認した情報が出力できました。
1,32864,2015-01-27 10:23:49,20150126,embulk
2,14824,2015-01-27 10:01:23,20150126,embulk jruby
3,27559,2015-01-27 17:20:02,20150127,Embulk "csv" parser plugin
4,11270,2015-01-29 02:54:36,20150128,
サンプルを改造して様々なデータ転送を試してみましょう
csv ⇄ mysqlの場合
利用するプラグイン
- [embulk-input-mysql]
(https://github.com/embulk/embulk-input-jdbc/tree/master/embulk-input-mysql) - [embulk-output-mysql]
(https://github.com/embulk/embulk-output-jdbc/tree/master/embulk-output-mysql)
CSVはサンプルで取得したcsvをそのまま使います
csv → mysql
プラグインをインストール
$ embulk gem install embulk-output-mysql
in:
type: file
path_prefix: ./try1/csv/sample_
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
null_string: 'NULL'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
default_timezone: 'Asia/Tokyo'
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
out:
type: mysql
host: localhost
user: root
password: ""
database: my_database
table: my_table
mode: insert
modeを指定することで単純なinsertやテーブル置換、upsertなどに対応できます。
DBの用意
とりあえず元のcsvに合わせる感じでざっくりと作成
mysql> CREATE DATABASE my_database;
mysql> USE my_database;
mysql> CREATE TABLE my_database.my_table (
-> id INTEGER,
-> account INTEGER,
-> time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-> purchase DATETIME DEFAULT CURRENT_TIMESTAMP,
-> comment varchar(255)
-> );
実行
$ embulk preview config.yml
+---------+--------------+-------------------------+-------------------------+----------------------------+
| id:long | account:long | time:timestamp | purchase:timestamp | comment:string |
+---------+--------------+-------------------------+-------------------------+----------------------------+
| 1 | 32,864 | 2015-01-27 10:23:49 UTC | 2015-01-26 15:00:00 UTC | embulk |
| 2 | 14,824 | 2015-01-27 10:01:23 UTC | 2015-01-26 15:00:00 UTC | embulk jruby |
| 3 | 27,559 | 2015-01-27 17:20:02 UTC | 2015-01-27 15:00:00 UTC | Embulk "csv" parser plugin |
| 4 | 11,270 | 2015-01-29 02:54:36 UTC | 2015-01-28 15:00:00 UTC | |
+---------+--------------+-------------------------+-------------------------+----------------------------+
$ embulk run config.yml
データの確認
mysql> select * from my_database.my_table;
+------+---------+---------------------+---------------------+----------------------------+
| id | account | time | purchase | comment |
+------+---------+---------------------+---------------------+----------------------------+
| 1 | 32864 | 2015-01-27 19:23:49 | 2015-01-27 00:00:00 | embulk |
| 2 | 14824 | 2015-01-27 19:01:23 | 2015-01-27 00:00:00 | embulk jruby |
| 3 | 27559 | 2015-01-28 02:20:02 | 2015-01-28 00:00:00 | Embulk "csv" parser plugin |
| 4 | 11270 | 2015-01-29 11:54:36 | 2015-01-29 00:00:00 | NULL |
+------+---------+---------------------+---------------------+----------------------------+
mysql → csv
csv → mysql の際に利用したテーブルをそのまま利用します。
プラグインをインストール
$ embulk gem install embulk-input-mysql
in:
type: mysql
host: localhost
user: root
password: ""
database: my_database
table: my_table
select: "id, account, time, purchase, comment"
where: "comment <> 'embulk'"
out:
type: file
path_prefix: ./try1/csv/sample
sequence_format: "."
file_ext: csv
formatter:
type: csv
delimiter: ","
newline: CRLF
newline_in_field: LF
charset: UTF-8
quote: '"'
config.ymlのinの部分で以下のデータが取得できます。
mysql> SELECT id, account, time, purchase, comment
-> FROM my_database.my_table
-> WHERE comment <> 'embulk';
+------+---------+---------------------+---------------------+----------------------------+
| id | account | time | purchase | comment |
+------+---------+---------------------+---------------------+----------------------------+
| 2 | 14824 | 2015-01-27 19:01:23 | 2015-01-27 00:00:00 | embulk jruby |
| 3 | 27559 | 2015-01-28 02:20:02 | 2015-01-28 00:00:00 | Embulk "csv" parser plugin |
+------+---------+---------------------+---------------------+----------------------------+
実行
$ embulk preview config.yml
+---------+--------------+-------------------------+-------------------------+----------------------------+
| id:long | account:long | time:timestamp | purchase:timestamp | comment:string |
+---------+--------------+-------------------------+-------------------------+----------------------------+
| 2 | 14,824 | 2015-01-27 19:01:23 UTC | 2015-01-27 00:00:00 UTC | embulk jruby |
| 3 | 27,559 | 2015-01-28 02:20:02 UTC | 2015-01-28 00:00:00 UTC | Embulk "csv" parser plugin |
+---------+--------------+-------------------------+-------------------------+----------------------------+
$ embulk run config.yml
データの確認
id,account,time,purchase,comment
2,14824,2015-01-27 19:01:23.000000 +0000,2015-01-27 00:00:00.000000 +0000,embulk jruby
3,27559,2015-01-28 02:20:02.000000 +0000,2015-01-28 00:00:00.000000 +0000,"Embulk ""csv"" parser plugin"
mysql → csvへの出力も確認できました。
やってみて感じたこと
mysql → BigQuery
SalesForce → BigQuery
mysql → SalesForce
csv、mysql以外にも試してみてみたのでembulkについて感じたことを書きます
-
ポジティブ
-
いろんなデータを並列で転送できる便利なやつ
-
プラグインを入れるのが楽
-
条件抽出することが可能
-
抽出したものをそのまま転送するだけではなく、フィルターを通すことでデータを加工してから転送することもできる
-
embulkを活用し、いろんなデータを集約することでデータ分析が捗りそう
-
ネガティブ
- プラグインの最終コミットが古いので利用するプラグインによっては、使い勝手が悪い場合などモヤモヤしたり、バグを見つけた際に困りそう
- embulkで使える型と、送る先の型などで微妙に慣れないうちは直感的ではなくフィルタープラグインで少し加工しないといけない場合があった
SalesForceなど
総合的にデータ連携の基盤を作ってる感があり楽しい👍
他にもETLはたくさんあるので色々試してみようと思ってます
オススメのものがあればコメントで教えてください
直近だと
Embulk + Argoの組み合わせも面白そうなので今度試す予定です。
最後に
Ateam Brides Inc. Advent Calendar 2020の3日目は、
@oekazumaがお送りします!!どんなネタを用意してくるのか楽しみです!!
参考にさせていただいた記事
Embulk(エンバルク)組み込みプラグインの設定覚え書き
大量データの転送にEmbulkを使ってみたら本当に楽だった
Embulkを使って、RDSのデータをBigQueryへロード