はじめに
2015/6にAmazon EMRでSparkが標準サポートされました。これにより、EMRでSpark Clusterを起動すれば、ものの10分ぐらいでSpark + IPythonの環境を構築できるようになりました。
が、AWS ConsoleのEMRの設定UIが大きく変わったり、IPythonがJupyterになり一部設定方法が変わったり、それらの変化に各種Documentが追従していなかったりと、色々ハマッたので、設定方法と、IPython上でPysparkを動かす方法をチラシの裏しておきます(2015/11時点での情報です)。
以下の3本立てでチラ裏してみたいと思います
- (第1回)Amazon EMR上でのSpark Clusterの起動/設定方法 (★今回はココ)
- Spark, IPythonの設定方法
- Spot instanceについて
-
(第2回)Sparkを使って簡単なAccess Log解析
- Access LogをS3から読み込んで、ETLする
- Access Logを使って定番のMAU, DAU, UUをSparkで計算してみる
- 各種Monitoring toolの見方
-
(第3回)Sparkを使って簡単な機械学習
- matplotlib/seabornを使ってGraphを書いてみる
- MLLibを使ってAccess Logを機械学習(K-means, PCA)にかけてみる
そもそもHadoopとかMap ReduceとかSparkって何よ?
そもそもHadoopとは
- Hadoopの概念図はこの資料の以下の2つの図がわかりやすいです。


- 旧世代であるHadoop version1.0の特徴
- HDFS(分散File System)とMapReduce(Cluster Resource管理 + 分散処理Framework)という2層構成
- 現世代であるHadoop version2.0の特徴
- 分散File System, Cluster Resource管理, 分散処理Frameworkが3層で分離して、それぞれ独立したModuleを使えるようになった
- Resource管理は気にしなくて良くなったので、様々な分散処理Frameworkが開発された
- Cluster Resource管理として有名なのがYARNやMesos
- 分散処理Frameworkとして有名なのがSparkやStorm
- Resource管理と分散処理Frameworkの分離が出来たので、1つのCluster上でYARN上にSpark/Storm/Map Reduceを共存させる、と言った事も可能
SparkとMap Reduceの違い
分散処理FrameworkであるSparkとMap Reduceは、以下のような違いを持ちます。
- Spark
- 処理中のよく使うDataをRAM上に保存しておく事でMap Reduceの数百倍の処理速度が出せる(事がある)
- 同じDataを繰り返し使う機械学習では処理速度向上の恩恵を受けやすい
- Map Reduce
- 処理中のDataを毎回HDDなどのStorageに書き出すので、RAMに乗り切らない様な巨大なDataを扱う場合や、定型的なBatch処理に向いている
- その他
- Map Reduceの登場が2004-2006年ぐらい、Sparkが2010-2013年ぐらい、設計思想の違いは当時のComputing resourceの違いにも起因(SSDの登場、RAMの大容量化etc)
- SparkはScala、Map ReduceはJavaがオリジナルの言語だが、PythonやSQLやRなどの言語で使う為のWrapperが存在する
- 上記の背景から、SparkはMap Reduceを『置き換える』とも言われるし、『棲み分けする』とも言われる
Spark上の便利Library群
Sparkは単体でも使えますが、Sparkの分散処理Frameworkを使い、様々な機能が提供されています(以下有名な例)
- MLlib(Spark上で機械学習を行う)
- Spark Stream(秒単位のLatencyでRealtime分散処理を行う)
- Spark SQL(SQLのCodeでSparkのdataを処理できる)
Amazon EMRとは
- AWS上でHadoop環境を立ち上げられるManagedなService、クリック1つで100 nodeのCluster構築、とかも容易に可能
- Spark/Pig/Hiveと言った有名どころのFrameworkやLibraryを標準でサポート
- Spot Instance(後述)での利用が簡単に行え、通常のEC2よりも格安で(1/10から1/3)で運用が可能(うまく使えばRedshiftよりも安く運用できる)
- Amazon S3との連携が楽なので、S3にDataを置いておき、Data sizeに合わせた規模のCluster起動→S3からData読み込み→探索的Data解析を行う、と言う処理を必要に応じて安価に実現できる
参考ページ
EMR上でSpark Clusterを起動させる
まずはSpark, IPythonの環境を立ち上げ、IPythonのWeb UIにアクセスする迄の流れです。
AWS Consoleから、EMR→Create cluster→Go to advanced optionsを選択します。
事前準備
-
このScriptをDownLoadして、S3 bucketにCopyしておく
- 中身は下の方で簡単に紹介しますが、JupyterのInstall/Setup/起動を行う物です
- ScriptはBrowserのDownLoadで保存する事を推奨します、Text editorに一旦コピペして保存する場合は、改行がLFになるように保存して下さい
- 最低限Inboundで
22(ssh),80(http),8080,8088,9000,50070,18080が開いているSecurity Groupを作成しておく- 最初はInboundもOutboundも全Portが開いたSecurity Groupを作っておいた方が悩まずにすみます
Step1の設定
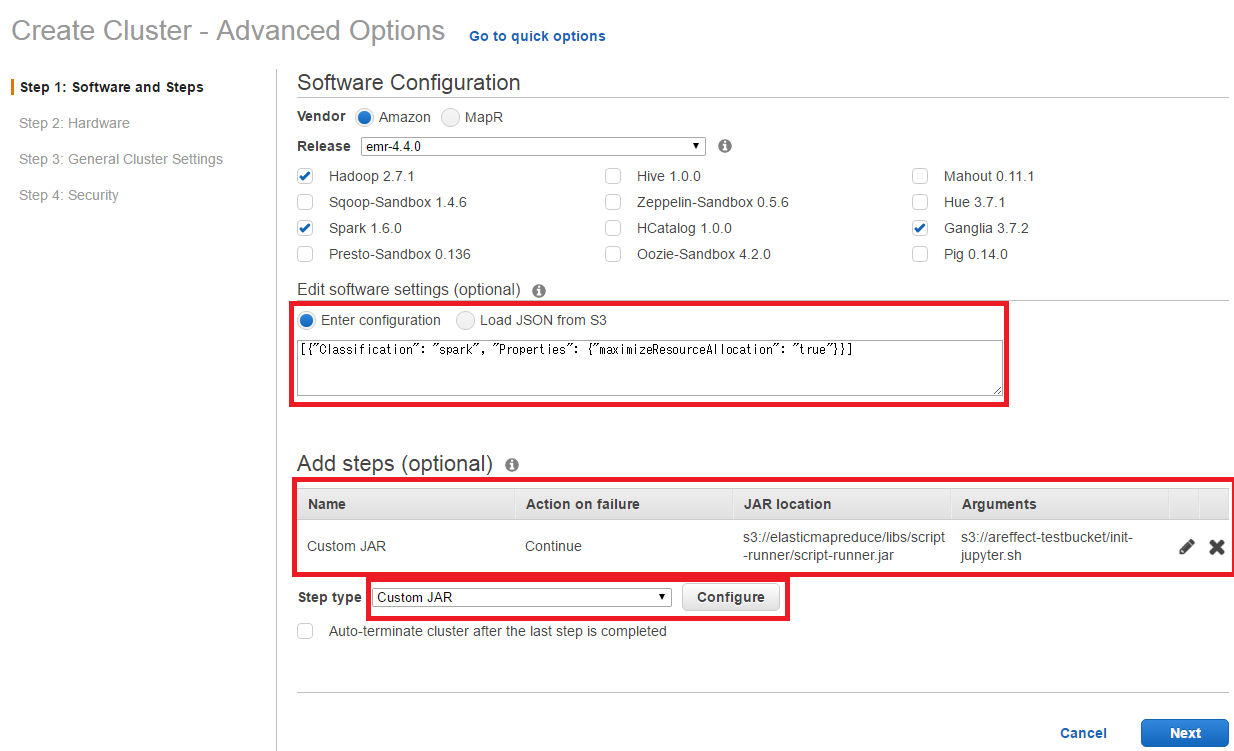
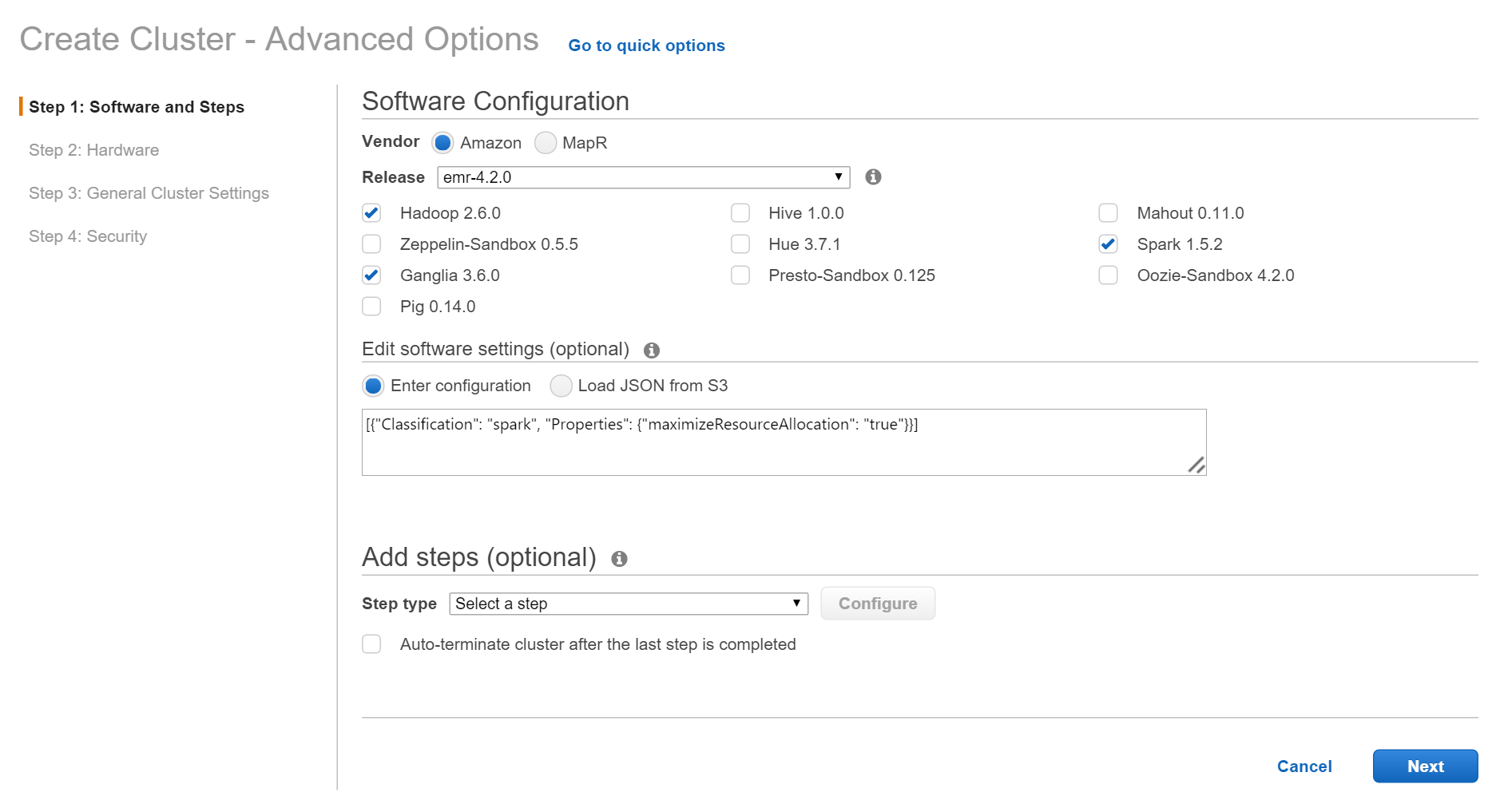
InstallするMiddleware、Optionを設定します。最終的に上のような画面になるように設定します。
- Software Configuration
-
Amazon emr-4.4.0を選択(or 新しい物) - 追加するSWに
Hadoop,Ganglia,Sparkを選択(他はCheck外す)
-
- Edit software configuration
- 以下のオマジナイを追加、オマジナイの詳細はAmazonのPageを参照
[{"Classification": "spark", "Properties": {"maximizeResourceAllocation": "true"}}]- この設定は、各nodeの(CPUとMemory)Resourceを可能な限り1つのSpark applicationに割り当てる、と言うSparkの設定で、ClusterをSparkでのみ1人で使う場合に適した設定です
- Add steps
- Cluster初期化後に、事前準備でS3にCopyしたShell scriptを実行し、Jupyter等のInstallを行う為の設定です
- 詳細は以下を参照
Add stepsの設定方法
-
Add stepsのStep typeでCustom JARを選択した状態でConfigureをクリックすると、以下の様なDialogが出ます
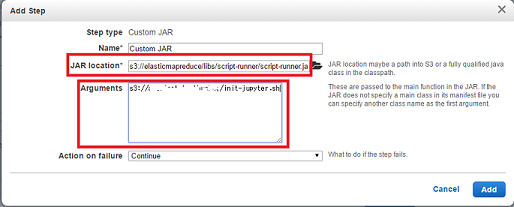
-
JAR locationには、s3://elasticmapreduce/libs/script-runner/script-runner.jarを設定します。
このJARは、Shell scriptを解釈するAmazon謹製のjar appです -
Argumentsには、事前準備で保存したShell scriptのpathを設定します。例えばs3://your-S3-bucket/init-jupyter.shなど
Step2の設定

Clusterのnode(=EC2)の種類や数を設定します。Spot instanceもここで設定可能です。
- Subnetの設定
- どれを指定しても問題無いですが、
1cの方が1aよりもSpot instanceが安い場合が多い気がします
- どれを指定しても問題無いですが、
- Master, core nodeの設定
- お試しなので、Master nodeをm2.xlarge, Core node(=Slave node)をm2.xlarge * 3つに設定
- Spot instanceにCheckを付けて、
iのiconにマウスを持って行くと、その時のSpot instanceの最低価格が表示されます。最低価格を上回る価格をBit priceに入力してください- Spot instanceは
Bit priceの入力値が課金される『のではなく』、あくまで最低価格が課金されます - この図の場合、
Bit priceは0.025ドル/hですが、課金は(変動しなければ)ec2 1 instance辺り 0.022ドル/hです。全体では4 instanceなので、0.022 * 4 = 0.088ドル/h(≒10.5円/h)が課金されます
- Spot instanceは
Step3の設定
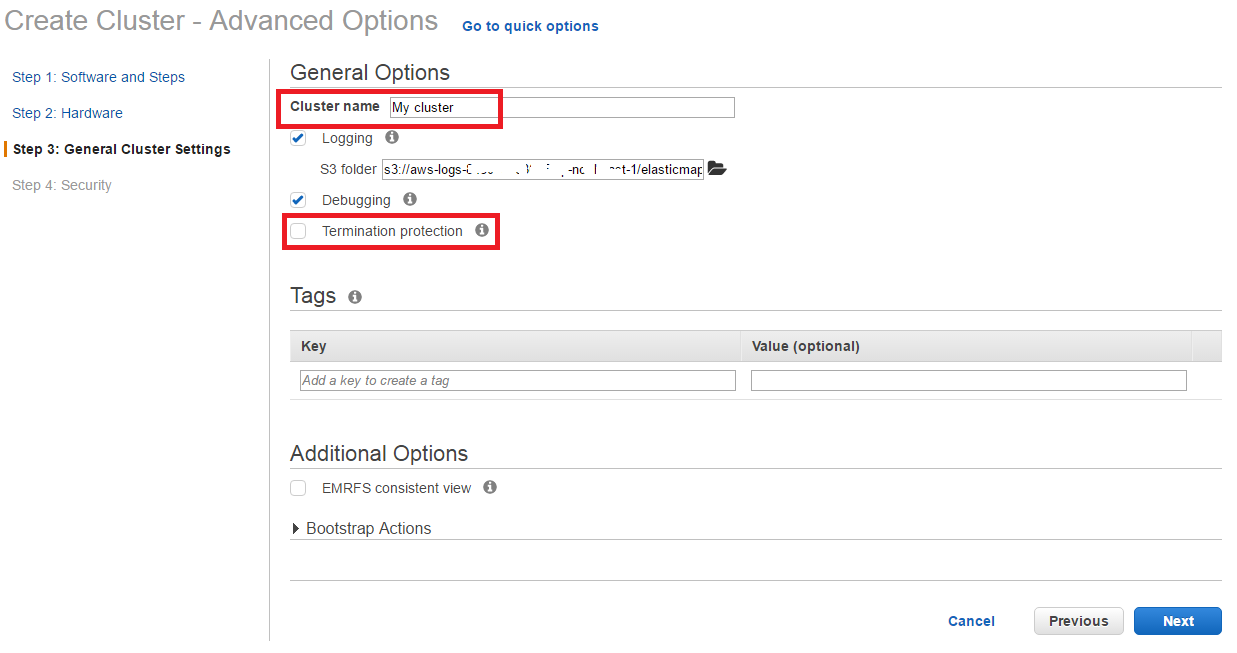
Cluster名、Bootstrap actionの設定をします。
- Cluster name
- 適当に名前を付けてください
- Termination protection
- テストなのでCheckboxを外します
- Bootstrap Actions
- Bootstrap actioは特に設定しなくても良いです。
- Bootstrap actionは、Clusterの各nodeで、Spark等を立ち上げる前に各種設定変更や追加Installを行う為の機能で、よくある例は、Middlewareの追加、Network等の設定変更、解析DataをlocalにCopyするなどです
- Bootstrap actionは2種類あります
-
Custom action:全てのnodeで実行される -
Run if:特定条件(例えばMaster nodeでのみ、等)で実行される
-
Step4の設定
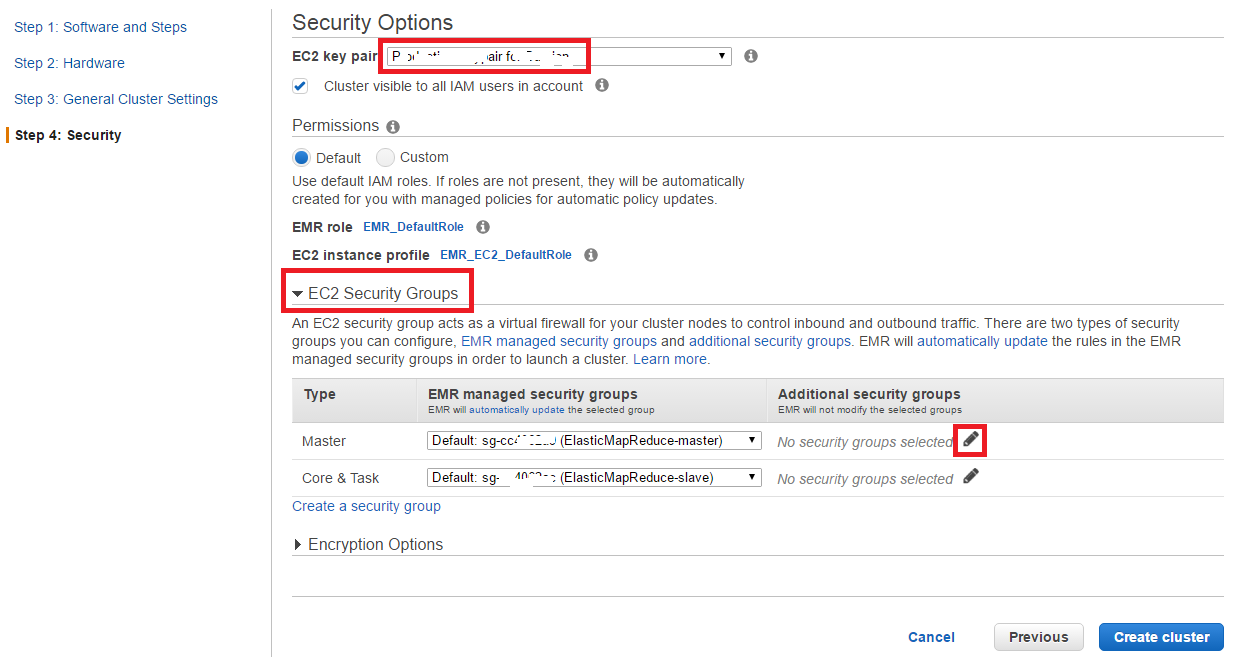
Security関連の設定です。
-
EC2 key pairで(ここでは使いませんが)Master nodeにsshで入る場合のKey pairを設定 -
EC2 Security GroupでSpark Master nodeに対してのSecurity Groupの設定-
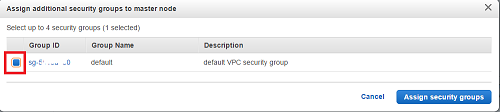
EC2 Security Groupをクリックし、Masterに対して、Additional security groupsを追加する為に、ペンアイコンをクリックする - 以下のDialogが出るので、事前準備で作成した(各種Portの開いた)Security Groupを選択し、
Assign security groupsを選択(この設定で、Master nodeに対し、sshやhttpでアクセス可能となる)
-
後はdefatulでOKです。Create clusterをクリックすれば、Cluster起動が始まります。
Clusterの起動の確認

Create clusterをクリック後に上記画面に切り替わります、Master node/Core nodeのStatusがProvisioning→Bootstrapping→Running→Waitingと変わるまでお待ちください、5-6分かかります。また、Master nodeのpublic DNS(ec2-52-xxx-xx-xx.ap-northeast-1.compute.amazonaws.comみたいなURL)をメモっておきます
補足:Jupyterの設定Scriptについて
Step1のAdd stepsで、Cluster初期化後に、指定したShell scriptを実行しJupyter等のInstallを行う様に設定していますが、Scriptの中身と簡単な説明をしておきます。なお、Cluster起動後、Master nodeにsshで入り、hadoop userで以下のScriptを実行させても同様の事が可能です。
Scriptの中身
# Environments
SPARK_PACKAGES=com.databricks:spark-avro_2.11:3.2.0
ANACONDA_VERSION=2-2.5.0
JUPYTER_LOG=/dev/null
# JUPYTER_LOG=/home/hadoop/.jupyter/jupyter.log
PYENV=~/.pyenv
PYENV_BIN=$PYENV/bin
## Install git and Anaconda
sudo yum -y install git
git clone https://github.com/pyenv/pyenv.git $PYENV
echo -e "\nexport PYENV_ROOT=$PYENV" | sudo tee -a ~/.bash_profile >> /dev/null
echo -e "\nexport PATH=$PYENV_BIN:$PATH" | sudo tee -a ~/.bash_profile >> /dev/null
echo -e "\neval '$($PYENV_BIN/pyenv init -)'" | sudo tee -a ~/.bash_profile >> /dev/null
source ~/.bash_profile
pyenv install -l | grep ana
pyenv install anaconda$ANACONDA_VERSION
pyenv rehash
pyenv global anaconda$ANACONDA_VERSION
echo -e "\nexport PATH='$PYENV/versions/anaconda$ANACONDA_VERSION/bin/:$PATH'" | sudo tee -a ~/.bash_profile >> /dev/null
source ~/.bash_profile
conda update --yes conda
## Install addtional python libraries
conda install --yes seaborn plotly
## Configure Jupyter
sudo su -l hadoop -c "jupyter notebook --generate-config"
JUPYTER_NOTEBOOK_CONFIG=/home/hadoop/.jupyter/jupyter_notebook_config.py
sudo sed -i -e "6i c.NotebookApp.ip = '0.0.0.0'" $JUPYTER_NOTEBOOK_CONFIG
sudo sed -i -e "6i c.NotebookApp.open_browser =False" $JUPYTER_NOTEBOOK_CONFIG
sudo sed -i -e "6i c.NotebookApp.port = 8080" $JUPYTER_NOTEBOOK_CONFIG
sudo sed -i -e "6i c.NotebookApp.token = ''" $JUPYTER_NOTEBOOK_CONFIG
sudo sed -i -e "6i c = get_config()" $JUPYTER_NOTEBOOK_CONFIG
IPYTHON_KERNEL_CONFIG=/home/hadoop/.ipython/profile_default/ipython_kernel_config.py
sudo su -l hadoop -c "ipython profile create"
sudo sed -i -e "3a c.InteractiveShellApp.matplotlib = 'inline'" $IPYTHON_KERNEL_CONFIG
## Launch Jupyter by executing "pyspark"
JUPYTER_PYSPARK_BIN=/home/hadoop/.jupyter/start-jupyter-pyspark.sh
cat << EOF > $JUPYTER_PYSPARK_BIN
export SPARK_HOME=/usr/lib/spark/
export PYSPARK_PYTHON=/usr/bin/python
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
export SPARK_PACKAGES=$SPARK_PACKAGES
nohup pyspark --packages $SPARK_PACKAGES > $JUPYTER_LOG 2>&1 &
EOF
chmod +x $JUPYTER_PYSPARK_BIN
$JUPYTER_PYSPARK_BIN
Scriptの内容補足
- 全体として以下の流れになります
- Pythonの実行環境としてAnacondaのsetup
- Jupyterの設定
- JupyterをBackgroundで実行
-
SPARK_PACKAGESで、Spark packageを設定しています。Spark packageはSparkに各種便利libraryを追加できる機能です。追加が必要無ければこのままで良いです -
ANACONDA_VERSIONでAnacondaのversion指定しています。ここではPython2.7 baseのAnacondaを使っていますが、Python3系が良ければ、anaconda3-2.5.0などに変更して下さい -
JUPYTER_NOTEBOOK_CONFIGにJupyter Notebookの設定をしています。ここではPort 8080でJupyterへアクセスする様に設定しています - 最後に、
JUPYTER_PYSPARK_BINから、nohup pysparkでJupyterをBackgroud実行しています -
JUPYTER_LOGで、JupyterのLogの出力先を設定しています、Logを確認したい場合は、/dev/null以外に設定して下さい
Jupyter Web UIにアクセスする
Chrome/Firefox等のBrowserで、Master nodeのPort 8080にアクセスしてください (ec2-52-xxx-xx-xx.ap-northeast-1.compute.amazonaws.com:8080)。以下の様なJupyter(IPython Notebook)のWeb UIが表示されれば、今までの手順が成功です(Jupyterが動き始めるまで時間がかかります、気長にお待ち下さい)。

Jupyterの操作方法は、こちらの記事をご覧下さい。
EMR上での設定項目のまとめ
EMR上で設定するべき項目を振り返ってみます。EMRでの設定項目は以下の5つに大別されます。
- Clusterの物理的な構成 (各NodeのEC2 Instanceの種類、Nodeの数)
- InstallするべきApplicationの選択と、個別のAppの初期設定(Software settingsの箇所)
- Bootstrap Action(今回は設定は無し)
- Security関連の設定
- Application起動後のJobの設定
最後に
第2回の記事では、立ち上げたSpark Clusterを使って、以下の紹介をしたいと思います
- Pysparkの紹介
- MLLibを使ってAccess Logを機械学習にかけてみる
- 各種Monitoring toolの見方
(おまけ1) Spot instanceについて
Spot instanceの詳細は以下の記事がとてもよく纏まっています、まずはご一読されると概要が掴めます。
以下、Spot Instanceを使ってSpark Clusterを運用する為のTipsです
Spot instanceの値動きについて
ここにあるように、AWS Console上で(EC2→Spot Requests→Pricing History)で最大過去3ヶ月までの値動きを確認できます。幾つかのInstanceの直近の値動きをみると、以下の内容のイメージが湧くと思います。確認ポイントは、値段、(通常価格に対しての)割引率とともに、突発的な値段の急騰が頻発していないか、です。
Spot価格を安くするには
- 旧世代のInstance (m2やc1)の方が、現行世代(m4やc3)よりも割引率が高い
- AZ-aよりもAZ-cの方が安い場合が多い
課金について
-
課金額はBit priceではなく、需要供給により決まる"市場価格"です、
You are charged the Spot market price (not your bid price)...です -
Bit priceはあくまで『"市場価格"がその価格以内なら支払う』という意思表示に過ぎない
突発的な値段の急騰について
- 急騰の頻度は、xlarge以下は概ね少なく、2xlarge以上はちょいちょいおきます
- 突発的な値段の急騰により、市場価格がBit priceを上回ると、ClusterはTerminateされます
- 急にClusterの反応が無くなった場合には値段の急騰を疑ってみてください。ConsoleのCluster list上は
Terminated with errors Instance failureと表示されます。Clusterの詳細画面で、Master node was terminated due to an increase in the market price.と表示されていたら、値段の急騰が原因です - ClusterをSpot Instanceで運用するのであれば、必要なDataはS3に常に待避しておく事を推奨します
- 最初のうちは、Bit priceに余裕を持たせて置くと吉です
- 急にClusterの反応が無くなった場合には値段の急騰を疑ってみてください。ConsoleのCluster list上は
その他
- SparkはArch的に、
高SpecなNodeが少数 > 低SpecなNodeが多数の方がPerfomanceが出るそうです - EC2の各InstanceのSpec/価格の比較はこのページが纏まっています(一番上でRegionを変更するのをお忘れ無く)
(おまけ2) 頻繁にClusterを立ち上げる場合
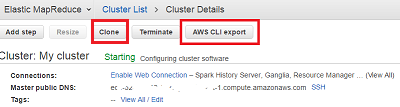
頻繁にClusterを作る場合、Cloneを使うか、Cluster作成設定をAmazon CLI化する方法がおすすめです。Clusterの詳細画面で、
-
Cloneを選択すると、元のClusterの作成設定がDefaultで入力された状態で、EMRの作成UIになります -
AWS CLI exportを選択すると、そのCluster設定をAmazon CLIとしてScriptに吐き出してくれます
(おまけ3) 標準サポートされているApplicationについて
Step1で、InstallするApplicationの選択をしました。今回はHadoop,Ganglia,Sparkのみを選択しましたが、それぞれのAppの機能の超概略をまとめておきます(Spark/Ganglia/Zeppelin以外使った事無いです)
- Hadoop みんな大好きHadoop、これ外すとどうなるんだろ?
- Hive 分散File System(HDFS)上に分散SQLを構築して、SQL(風)でデータ処理が可能
- Presto Hiveの後発で、On Memory処理してくれるな分散SQL。Hiveとの棲み分けはここら辺参照
- Mahout Hadoop上で機械学習を動かすLibrary。『マハウト』と読むらしい
- Zeppelin Web baseのInteractiveなNotebook。『ツェッペリン』と読む。IPythonの競合(機能比較はこの記事を参照)
- Hue HadoopをWeb UIから動かす為のサービス、JobとかもWeb UIから追加できるみたい
- Ganglia Clusterの(CPUやRAMの)Resource monitoring tool、『ガングリア』と読む。
- Oozie Hadoop/Spark用のWorkflow design/Schedulingの為のApp
- Pig SQLにInspireされた、Hadoop/Map ReduceのDomain Specific言語/App、複雑な処理も柔軟にかけるらしい