はじめに
第1回目で立ち上げたSpark ClusterにAccess Logを喰わせて、色々処理を廻してみる部分をチラシの裏しておきます。
-
(第1回)Amazon EMR上でのSpark Clusterの起動/設定方法
- Spark, IPythonの設定方法
- Spot instanceについて
- (第2回)Sparkを使って簡単なAccess Log解析 (★今回はココ)
- Access LogをS3から読み込んで、ETLする
- Access Logを使って定番のMAU, DAU, UUをSparkで計算してみる
- 各種Monitoring toolの見方
-
(第3回)Sparkを使って簡単な機械学習
- matplotlib/seabornを使ってGraphを書いてみる
- MLLibを使ってAccess Logを機械学習(K-means, PCA)にかけてみる
機械学習というと、すぐにIrisとかタイタニックとかのData setが出てきますが、多くの人にとってはAccess Logの解析がMain use caseだと思うので、Access Logを使ってのチラ裏となります。
なお、ここからはIPython上での操作がメインになります、IPythonのWeb UIの操作方法等を事前に読んでおくと良いです。
最後に、本記事のIPython Notebookをこちらに置いておくので、随時実行してみて下さい。
事前準備
Sample LogのS3へのCopy
サンプルとなる様な手頃なサイズで且つ整形されたAccess LogのDatasetを知らないのですが、技術評論社さんの本で使われていたAccess Log(csv)を使いたいと思います。csv fileへの直リンはこちら。
このcsv fileをDownloadして、適当なS3 bucketにUploadしておきます。csvの中身ですが、以下の通りです。
- 各Recordが日付、User_ID, Campain_IDの3つの情報を持つ
- Totalの行数は
327431、最初の1行がcsv headerなので、実Record数は327430 - 2015/4/27-5/3の7日分のDataを持つ
- file sizeは13MB (このサイズなら、分散処理する必要無いですが)
click.at user.id campaign.id
2015/4/27 20:40 144012 Campaign077
2015/4/27 0:27 24485 Campaign063
2015/4/27 0:28 24485 Campaign063
2015/4/27 0:33 24485 Campaign038
最初の内は、Log SizeをExcelで扱えるぐらいに極力小さくして、Excelでの計算結果と付き合わせながらCodeをしていく事をお勧めします。
S3へアクセスする為のAPI/Secret Key
Sample LogをS3から読み込むので、S3のRead権限のあるIAM userを作成しておき、API Key,Secret Keyを払い出しておきます。
DataをS3からの読み込み
S3からSample Log fileを読み込んで見る
まずは、以下のCodeをIPython上にコピペして動かして見ます。
-
API Key,Secret Keyは前準備で用意した物に置き換えてください(以下のcodeは適当な文字列です)
なお、IPython上のCodeに、Keyを直書きするのはSecurity的に宜しくないので、環境変数に設定するなど対策を取ってください -
S3 bucket名も、Sample Log fileを置いたS3 bucket名に置き換えてください
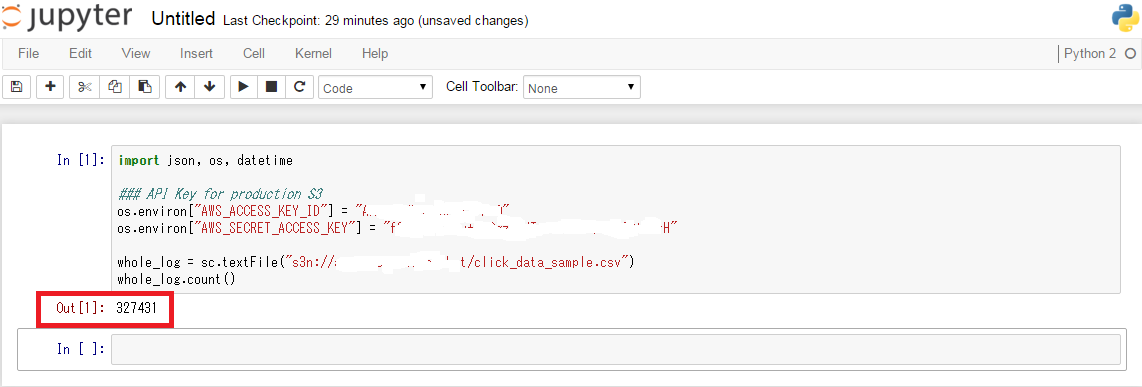
import json, os, datetime
### API Key for S3 bucket
os.environ["AWS_ACCESS_KEY_ID"] = "AKIAJUKJIM431KYVBEA"
os.environ["AWS_SECRET_ACCESS_KEY"] = "f73Ju/JqJ8h+VgOg738NTNiogW4hiGoE/OGj+GHk"
whole_log = sc.textFile("s3n://my-test-S3-bucket/click_data_sample.csv")
whole_log.count()
以下の様に、327431と表示されたら成功です。無事csv fileをS3から読み込めました。whole_logはRDD(Resilient Distributed Dataset)と言う分散配置されたObjectです。RDDは 不変(イミュータブル)で並列実行可能な(分散配置された)ObjectみたいなObjectで、SparkではRDD等の分散配置されたObjectに対して各種処理を並列に行います。
なお、複数のfileをS3からSpark Contextに読み込む場合には、以下の様なCodeで良いです
logfile_list = []
logfile_list.append("s3n://my-test-S3-bucket/log_sample1.csv")
logfile_list.append("s3n://my-test-S3-bucket/log_sample2.csv")
logfile_list.append("s3n://my-test-S3-bucket/log_sample3.csv")
whole_log = sc.textFile(','.join(logfile_list))
whole_log.count()
また、S3 Bucketの全てのFileを読み込む場合には、以下の様なCodeで良いです
whole_log = sc.textFile("s3n://my-test-S3-bucket/*")
whole_log.count()
幾つかのrecordを表示させてみる
読み込んだSpark Contextのrecordを幾つか表示させるには、sc.first()やsc.take(n)というMethondを使います。
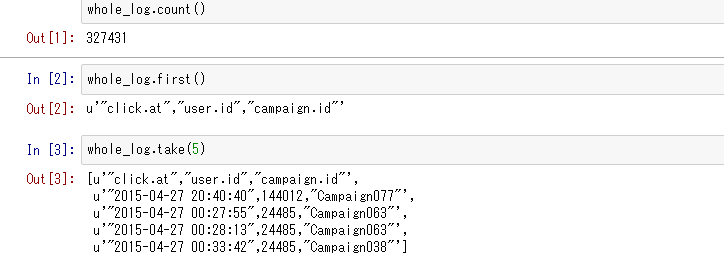
無事、読み込まれたLog fileが表示されていますが、2つ問題があります。
- csvのheaderも一緒に読み込まれている
-
u'"2015-04-27 20:40:40",144012,"Campaign077"'を見ると、"2015-04-27 20:40:40",144012,"Campaign077"という1つの文字列として認識されている
そのため、解析に移る前にDataの前処理を行い、この2つの問題を片付けます。
Dataの前処理
csvのheaderを削除する
まず、csvのheaderを削除します。1行目を削除する、というお手軽methodは無いので、1行目を取り出して、filterで1行目と同じでない物を取り出します。
header = whole_log.first() #extract header
whole_log_header_removed = whole_log.filter(lambda each_record: each_record != header) #filter out header
whole_log_header_removed.first()
whole_log_header_removed.take(5)
なお、ここら辺から、Pythonのlambda,filter, map辺りの知識が無いと、厳しくなってきます。これらはPyspark固有の機能ではなく、Python標準の機能ですので、この記事とかこの記事を参考に、まずはLocalのPython環境で動作を確認してみると良いと思います。
Pysparkでは、lambda関数と、filter, map辺りはゴリゴリ使うので、ある程度理解しておかないと厳しいです。
1行を3つの要素毎に分解する
続いて、1つのrecordが、1つの文字列として読み込まれている問題への対応です。1行づつ読み込み、それぞれを,でsplitします。
whole_log_split = whole_log_header_removed.map(lambda line: line.split(","))
whole_log_split.take(2)
すると、以下の様に表示されます。[record0, record1, record2..]と言うlistが、[ [record0[0], record0[1], record0[2]], [record1[0], record1[1], record1[2]] ... ]と言う(3つの文字列の)ListのListに変換されます。
[[u'"2015-04-27 20:40:40"', u'144012', u'"Campaign077"'],
[u'"2015-04-27 00:27:55"', u'24485', u'"Campaign063"']]
日付をdatetime objectに変換する
もう一つDataの前処理を行います。
- 最初の要素(
"2015-04-27 20:40:40")を、datetime objectに変換する - 最後の要素(
"Campaign063")は前後に"を含んで居るので削除する
以下の処理を行えばOKです。
whole_log_converted = whole_log_split.map(lambda line: [datetime.datetime.strptime(line[0].replace('"', ''), '%Y-%m-%d %H:%M:%S'), line[1], line[2].replace('"', '')])
whole_log_converted.take(2)
上記Codeの補足
上記のmap処理ですが、長くて微妙に分かりずらいと思うので補足します。
例えば、 test_list1 = [["hoge0", "fuga0", "piyo0"], ["hoge1", "fuga1", "piyo1"] ... ]の様な、"3つの文字列のList"のListのRDDが有ったとして、
test_list2 = test_list1.map(lambda line: [ line[0].uppercase, line[1], line[2] ] )
test_list2.take(2)
上記処理を実行すると、[["HOGE0", "fuga0", "piyo0"], ["HOGE1", "fuga1", "piyo1"] ... ]となり、別の"3つの文字列のList"のListのRDDを生成します。元の長ったらしいCodeも、"3つの文字列のList"のListから、別の"Datatime Object/文字列/文字列のList"のListを作る処理です。
map()の中から別のMethodを呼ぶ
ここまで、rdd.map(lambda x:xへの処理)というCodeを書いてきましたが、xへの処理が1行で表現できない場合(if分岐や内部でfor loopを回すような場合)、以下の様に別のMethodを呼ぶ様な記載も可能です。
def hoge_func(obj):
return [datetime.datetime.strptime(obj[0].replace('"', ''), '%Y-%m-%d %H:%M:%S'), int(obj[1]), obj[2].replace('"', '')]
whole_log_converted = whole_log_split.map(hoge_func)
whole_log_converted.take(2)
計算結果をCacheする
whole_log_convertedという前処理済のRDD Objectを作れたので、このRDDをCacheします。Sparkは繰り返し使うDataをRAMに載せておく事で高速に分散処理が行えるFrameworkです。以下のcache()というMethodでwhole_log_convertedを明示的にRAMに永続的に載せておく事ができます。
repartition(4)は詳細は割愛しますが、今回はSlave Node数が4個なので、cache()する前にRDDを4つに均等に分割(Shuffle)して、それを各Slave NodeのRAMに載せるようにしています。
whole_log_converted.repartition(4).cache()
計算結果をS3に書き戻す
前処理した結果は、再度利用する可能性があります、S3に保存しておきたい場合には、saveAsTextFileを実行すればOKです。
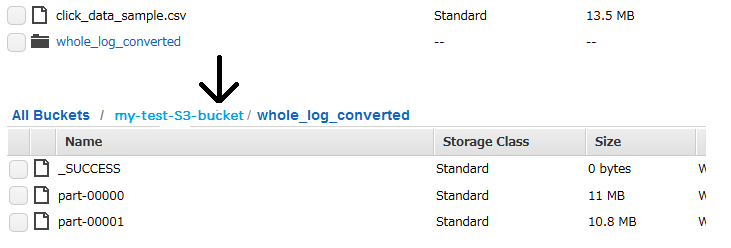
whole_log_converted.saveAsTextFile("s3n://my-test-S3-bucket/whole_log_converted")
Bucket上にwhole_log_convertedと言うFolderが作られ、part-00000, part-00001... というText fileが作成されます。次回以降はこれらfileをwhole_log_reload = sc.textFile("s3n://my-test-S3-bucket/whole_log_converted/*")で直接読み込めば良いです。
MAU/DAUなどの定番解析
長い前処理が終わりました、やっと実際の解析作業に入ります。Access log解析の定番である、以下の数値をSparkで計算してみます
- Daily Activity
- Daily Active User
- Retention User
- New User
Daily Activity
まずは定番のDaily Activityです。まずは2015/4/27のAccess数を計算してみます。以下の処理で41434が表示されれば正解です。
whole_log_converted.filter(lambda record: record[0].replace(hour=0, minute=0, second=0) == datetime.datetime(2015, 4, 27)).count()
record[0]は2015-04-27 20:40:40などのdatetime objectなので、.replaceでhour/minute/secondを0にして、datetime.datetime(2015, 4, 27)と等しい行のみをfilterで取り出して、その行数をcount()で返します
以下の様にすれば、7日間のRecord数(Daily access数)を一括計算可能です
for count in range(0, 7):
target_day = datetime.datetime(2015, 4, 27) + datetime.timedelta(days=count)
print target_day.strftime('%Y/%m/%d'),
print whole_log_converted.filter(lambda record: record[0].replace(hour=0, minute=0, second=0) == target_day).count()
Daily Active User
続いてDAU(特定の日のUnique User数)の計算をしてみます。listの2番目の要素がuser.idなので、特定の日のuser.idのUnique item数を計算します。こちらもまずは2015/4/27のDAUを計算してみます。以下の処理で20480が表示されれば正解です。
whole_log_converted.filter(lambda record: record[0].replace(hour=0, minute=0, second=0) == datetime.datetime(2015, 4, 27)).map(lambda record:record[1]).distinct().count()
以下、処理の簡単な説明です
- 最初の
filterで2015/4/27のrecordのみを取り出す - 次の
map(lambda record:record[1])で、user.idのみのlistにする - 最後の
distinct()で、listの重複を除く
同じく、以下の様にすれば、7日間のDAUを一括計算可能です
for count in range(0, 7):
target_day = datetime.datetime(2015, 4, 27) + datetime.timedelta(days=count)
print target_day.strftime('%Y/%m/%d'),
print whole_log_converted.filter(lambda record: record[0].replace(hour=0, minute=0, second=0) == target_day).map(lambda record:record[1]).distinct().count()
Retension User
ここでは、2015/4/27-4/29の3日間すべてにAccessがあるUser数を計算してみます。まず、それぞれの日のDaily Active UserのlistをDaily Active Userを参考に作ります。
UU_4_27 = whole_log_converted.filter(lambda record: record[0].replace(hour=0, minute=0, second=0) == datetime.datetime(2015, 4, 27)).map(lambda record:record[1]).distinct()
UU_4_27.repartition(4).cache()
UU_4_28 = whole_log_converted.filter(lambda record: record[0].replace(hour=0, minute=0, second=0) == datetime.datetime(2015, 4, 28)).map(lambda record:record[1]).distinct()
UU_4_28.repartition(4).cache()
UU_4_29 = whole_log_converted.filter(lambda record: record[0].replace(hour=0, minute=0, second=0) == datetime.datetime(2015, 4, 29)).map(lambda record:record[1]).distinct()
UU_4_29.repartition(4).cache()
続いて、intersectionというMethodを使うと、UU_4_29のListの内でUU_4_28のListにも有る物、更にUU_4_27のListにも有る物を計算してくれます。以下の処理で4045が表示されれば正解です。
three_day_UU = UU_4_29.intersection(UU_4_28).intersection(UU_4_27)
three_day_UU.count()
この実装、余りイケて無い気がするので、どなたか良い実装があれば教えてくださいm(_ _)m
New User
最後に、New Userです。ここでは『4/27のNew User』とは、(2015/4/27-5/3の7日分の内で)最初にAccessした日が4/27のUnique User数を意味します。ここはちと複雑なので分けてチラ裏します。
(1) Listの変換
まず、[[user.id, click.at], [user.id, click.at] ... ]というListに変換します。
whole_log_converted.map(lambda record:[record[1], record[0]]).take(3)
以下の様な表示がされればOKです。
[[u'144012', datetime.datetime(2015, 4, 27, 20, 40, 40)],
[u'24485', datetime.datetime(2015, 4, 27, 0, 27, 55)],
[u'24485', datetime.datetime(2015, 4, 27, 0, 28, 13)]]
(2) groupByKey
続いて、SparkのgroupByKey()と言うMethodを使います。このMethodはその名の通り、Key-ValueのListをKeyでGroup化してくれます。
-
[[user.id, click.at], [user.id, click.at] ... ]というListから -
[[user.id, [click.at, click.at]], [user.id, [click.at, click.at, click.at]] ... ]というlistに
変換します。以下の様に、先ほどの処理の後ろにgroupByKey()を加えてを実行してみると、
whole_log_converted.map(lambda record:[record[1], record[0]]).groupByKey().take(3)
以下の様な表示がされればOKです。pyspark.resultiterable.ResultIterableはdatetimeのListのはずです。
[(u'35540', <pyspark.resultiterable.ResultIterable at 0x7fd4f14be190>),
(u'35546', <pyspark.resultiterable.ResultIterable at 0x7fd4f144e050>),
(u'73461', <pyspark.resultiterable.ResultIterable at 0x7fd4f144e090>)]
(3) listのminを取る
最後に、mapの中で、listに対してminというMethodを使います。minはlistの中の最小値を返してくれるので、最初にアクセスしたclick.atのみが残ります。
first_access_date = whole_log_converted.map(lambda record:[record[1], record[0]]).groupByKey().map(lambda record:[record[0], min(record[1])])
first_access_date.take(3)
以下の様な表示がされればOKです。これで、[[user.id, 最初のclick.at], [user.id, 最初のclick.at] ... ]というlistができました。
[[u'35540', datetime.datetime(2015, 5, 1, 14, 15, 1)],
[u'145750', datetime.datetime(2015, 5, 1, 0, 46, 31)],
[u'73461', datetime.datetime(2015, 4, 29, 20, 37, 47)]]
(4) New Userを計算する
前処理が終わったので、New Userを計算します。.replaceの部分の処理内容はDaily Active Userと同じです。以下の処理で20480が表示されれば正解です。
first_access_date.filter(lambda record: record[1].replace(hour=0, minute=0, second=0) == datetime.datetime(2015, 4, 27)).count()
以下の様にすれば、7日間のそれぞれのNew User数を一括計算可能です。
for count in range(0, 7):
target_day = datetime.datetime(2015, 4, 27) + datetime.timedelta(days=count)
print target_day.strftime('%Y/%m/%d'),
print first_access_date.filter(lambda record: record[1].replace(hour=0, minute=0, second=0) == target_day).count()
ちなみに、全体のUnique User数は、以下の処理で計算でき75545となるはずです。
上記の7日間のそれぞれのNew User数の合計値が、75545となるかも確認しておいて下さい。
whole_log_converted.map(lambda record:record[1]).distinct().count()
最後に
今回はAccess Logを使って、SparkでMAU/DAUなどの定番KPIの計算をしてみました。これらの計算は、LogをDBに入れておいてSQLで計算する場合が多いと思うのですが、Sparkでも同等の事ができるという紹介ができたと思います。またSchemeがバラバラな複数のLogを組み合わせてKPIを計算しないといけないようなCaseにおいては、寧ろPython+Sparkの方が柔軟で小回りが効くSolutionだと思っています。
今回は、SparkのMethodとして、distinct, groupByKey, map, filter, takeぐらいしか紹介しませんでしたが、ホントはこの100倍の数の便利Methodがあるので、探してみて下さい。
さて、次回はAccess Logを機械学習にかける手順をチラ裏したいと思います。
(第3回)Sparkを使って簡単な機械学習
- MLLibを使ってAccess Logを機械学習にかけてみる
- 各種Monitoring toolの見方
(おまけ1)各種Monitoring toolについて
最後に、Monitoring toolの説明をしておきます。Amazon EMRでSparkを立ち上げると、標準で幾つかのWeb UIのMonitoring toolも同時に立ち上がります。
- 最初の内はGangliaとSpark Web UIの内容が解れば良いです
- IPythonのURLを
ec2-52-xxx-xx-xx.ap-northeast-1.compute.amazonaws.com:8080だとして、URLを読み替えてください
Ganglia
-
ec2-52-xxx-xx-xx.ap-northeast-1.compute.amazonaws.com/gangliaでアクセス - Clusterの各NodeのCPU負荷、Memory消費、Network I/Oなどが確認できます
これで各Nodeに均等に負荷が掛かっているか確認してください -
公式Pageにはssh tunnelを使ってのアクセスが必要、と書いてありますが、最新のEMRだと
/gangliaでアクセスできるみたいです - スゴイ色んな情報(metrics)が見れるので、色々試して見てください
Spark Web UI
-
ec2-52-xxx-xx-xx.ap-northeast-1.compute.amazonaws.com:18080でアクセス -
Spark history serverとかSpark Web UIと呼ばれ、Sparkのjobの状況、環境変数の設定などが確認できます
HDFS NameNode
-
ec2-52-xxx-xx-xx.ap-northeast-1.compute.amazonaws.com:50070でアクセス - HDFS(HadoopのFile System)の利用状況が確認できます
Hadoop ResourceManager
-
ec2-52-xxx-xx-xx.ap-northeast-1.compute.amazonaws.com:8088でアクセス - GangliaとSpark Web UIがあれば特に必要無し?
(おまけ2) API Keyを隠す方法
上記例では、以下の様に、IPython上に直接API/Secret Keyをべた書きしていました。自分一人で使う分にはこれで良いですが、IPythonをexportして他の人に渡す、などの場合にはべた書きはよろしくありません。
### API Key for S3 bucket
os.environ["AWS_ACCESS_KEY_ID"] = "AKIAJUKJIM431KYVBEA"
os.environ["AWS_SECRET_ACCESS_KEY"] = "f73Ju/JqJ8h+VgOg738NTNiogW4hiGoE/OGj+GHk"
Master node側の環境変数としてAPI/Secret Keyを設定すると、Sparkが自動的に読み込んでくれます。手順は以下の通りです。
- Master nodeにsshで入る
- 以下のコマンドで、
hadooopuserになり、aws congigureを実行する。API Key, Secret Key, Regionの入力を促されるので、入力する(regionはAWS Tokyoならap-northeast-1)
sudo su
su - hadoop
aws configure
この設定をしておけば、上記2行無しでいきなりwhole_log = sc.textFile("s3n://my-test-S3-bucket/click_data_sample.csv")とS3からFileを読み込む事が可能になります。
(おまけ3)自分のAWS Account以外のS3 bucketからFile持ってくる方法
S3からfileを読み込んでRDDにするsc.textFile("s3n://my-test-S3-bucket/sample.csv")ですが、どうやら自分のAWS Account配下のS3 bucketからの読み込みのみ可能で、別のAWS AccountのS3 bucketのfileは(API/Secret keyを設定しても)直接は読み込む事はできない模様です。
なので、以下の様なCodeで、boto3を使って(別のAWS Accountの)S3からlocal storageにCopyして、それを読み込んでRDDとします。
import boto3, datetime, commands
os.environ["AWS_ACCESS_KEY_ID"] = "AKIAJUNKYHJBCFKYLMQQ"
os.environ["AWS_SECRET_ACCESS_KEY"] = "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"
AWS_accessID = "AKIAJUNKYHJBCFKYLMQQ"
AWS_secretKey = "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"
AWS_region = "ap-northeast-1"
AWS_download_path = "my_target_bucket"
local_download_path = "/home/hadoop/"
session = boto3.Session(aws_access_key_id=AWS_accessID, aws_secret_access_key=AWS_secretKey, region_name=AWS_region)
s3_resource = session.resource("s3")
s3_client = session.client("s3")
s3_bucket = s3_resource.Bucket(AWS_download_path)
logfile_list = []
for item in s3_client.list_objects(Bucket=AWS_download_path)["Contents"]:
file_name = item["Key"].split("/")[-1]
file_size = item["Size"]
## ignore subfolder
if str(item["Key"]).find("/") == -1:
print "downloading : %s : %dMB" % (file_name, (file_size / 1048576)),
start_time = datetime.datetime.now()
try:
s3_bucket.download_file(item["Key"], local_download_path + item["Key"])
except IOError:
print "file download error for (%s)." % file_name
else:
print " -- download done, consume time\t%d(sec)" % (datetime.datetime.now() - start_time).seconds
commands.getoutput("hadoop fs -copyFromLocal -f ./" + str(item["Key"]) + " /user/hadoop/")
logfile_list.append("/user/hadoop/" + str(item["Key"]))
my_rdd = sc.textFile(",".join(logfile_list))
print my_rdd.count()
print my_rdd.take(10)