これまでの記事は、単一のグラフを作ってきた。
・Rで論文っぽい図を描く① 有意差マーク(*)の数を有意な度合いに従って変え、半自動的につける【t検定】(2020.08.04追記:geom_signifについて)
・Rで論文っぽい図を描く② veganで解析した微生物群集の構成の相違(NMDS)をggplot2で視覚化する
しかし、生物系の論文を見ると、1つのFigureに複数の図が記載されていることが多い。
例えば、Fig.1A, Fig.1B, ....のようにアルファベットが割り振られて複数の図がまとめられる。
ggplot2で作った図をまとめるにはgridExtraパッケージが代表的であるが、個人的にはggpubrを推したい。
というのも、ggpubrでは、上記のアルファベットを振るという作業が簡単だからである。
ついでに、凡例付きのグラフから凡例だけを取り出す方法も紹介する(凡例だけあると自由に配置できるので便利)。
サンプルデータの取り込み
今回も、Rにもとから入っているirisデータを使っていく。
# サンプルデータの取得
data <- iris
# 入ったかの確認
head(data)
1因子(Species)で3群(setosa, versicolor, virginica)いると、一元配置分散分析(One-way ANOVA)等をせねばならず、趣旨がずれるので今回はなしにする。
気が向いたらやる。
ということで、今回も以前と同様、2群だけ取ってt検定しようと思う。
# パッケージのインストールと読み込み
if (!require(dplyr))install.packages('dplyr')
library(dplyr)
# setosaとvirginicaだけ取り出したやつをdata2とする
data2 <- data %>% filter(Species == c("setosa", "virginica"))
t検定
4つのデータ(Sepal.Length, Sepal.Width, Petal.Length, Petal.Width)があるので、それぞれでt検定を行っていきたい。
# 4つのデータのt検定をそれぞれ格納
sl_t <- t.test(Sepal.Length ~ Species, data = data2, var.equal = T)
sw_t <- t.test(Sepal.Width ~ Species, data = data2, var.equal = T)
pl_t <- t.test(Petal.Length ~ Species, data = data2, var.equal = T)
pw_t <- t.test(Petal.Width ~ Species, data = data2, var.equal = T)
# 確認
sl_t
sw_t
pl_t
pw_t
出力結果↓
Two Sample t-test
data: Sepal.Length by Species
t = -15.386, df = 98, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.786042 -1.377958
sample estimates:
mean in group setosa mean in group virginica
5.006 6.588
Two Sample t-test
data: Sepal.Width by Species
t = 6.4503, df = 98, p-value = 4.246e-09
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.3143257 0.5936743
sample estimates:
mean in group setosa mean in group virginica
3.428 2.974
Two Sample t-test
data: Petal.Length by Species
t = -49.986, df = 98, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-4.252374 -3.927626
sample estimates:
mean in group setosa mean in group virginica
1.462 5.552
Two Sample t-test
data: Petal.Width by Species
t = -42.786, df = 98, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.862559 -1.697441
sample estimates:
mean in group setosa mean in group virginica
0.246 2.026
以前の記事でせっかく有意差の度合いごとにアスタリスクの数を調整する方法を紹介したのに、今回の4つのデータは全部、p < 0.001で面白くない笑
それでも前回の方法を使うが笑
# p値の取り出し(有意差マーク用)
sl_p <- sl_t$p.value
sw_p <- sw_t$p.value
pl_p <- pl_t$p.value
pw_p <- pw_t$p.value
有意差の度合いによって違う数のアスタリスクを返す関数を作成
# sigという関数を作り、pが以下の条件のときに適切な数だけ(*)を返すような関数を入れてみた
# p > 0.1 "", 0.1 ≧ p > 0.05 ".", 0.05 ≧ p > 0.01 "*", 0.01 ≧ p > 0.001 "**", 0.001 > p "***"
sig <- function(a) {
if (a > 0.1) {
return("")
} else {
if ((a <= 0.1)&&(a > 0.05)) {
return(".")
} else {
if ((a <= 0.05)&&(a > 0.01)) {
return("*")
} else {
if ((a <= 0.01)&&(a > 0.001)) {
return("**")
} else return("***")
}
}
}
}
追記:このsig関数について、もっとスタイリッシュに書く方法を、@doikoji 様が記事を書いてくださっているので、参考にしてください。
Rの多重ifブロックを良い感じに改良してみる
プロットを作成
このグラフの作り方については、以前の記事を参考に。
まず、Sepal.Lengthだけやってみた。
# パッケージの読み込み
library(ggplot2)
library(ggsignif)
# まず、Sepal.Lengthのやつを作る。
sl_g <- ggplot(data2, aes(x=Species, y=Sepal.Length, fill=Species)) + #data2でx軸Species、y軸Sepal.Length、色Species
geom_boxplot(lwd=2) + #画像にすると線が細くなりがちなので太めに(デフォルトは1)
theme(panel.grid = element_blank()) +
scale_fill_manual(values = c("gray40", "white")) + #論文って白黒のときあると思うので、色を指定
labs(y="Sepal length (cm)", x=NULL) + #y軸の名前いい感じに。x軸は凡例だけあればいいかなと思うので消す。
theme(axis.text=element_text(size=20, face = "bold", colour = "black"), #軸の数字の大きさ、字体、色
axis.title=element_text(size=25,face="bold", colour = "black"), #軸のタイトルの大きさ、字体、色
axis.line = element_line(size = 1.2, colour = "black"), #軸の大きさ、色
panel.grid.major = element_blank(), #以下、補助線や背景を消した
panel.grid.minor = element_blank(),
panel.background = element_blank(),
legend.position = "none",
) +
annotate("text", x=1.5, y=sl_yRoof, #タイトルをつけた。1.5は1個めと2個目の箱ひげの間を指す。
label="Sepal length",
vjust=0.7,
size=15,
fontface="bold") +
geom_signif(
y_position=sl_yRoof*0.85, #高さの設定
xmin=1.0, #線の始点の設定
xmax=2.0, #終点の設定
annotation= sig(sl_2), #さっき作ったsigを使う,
tip_length=0.05, #棒の下向きの線の長さ
textsize=10 #*の大きさ
)
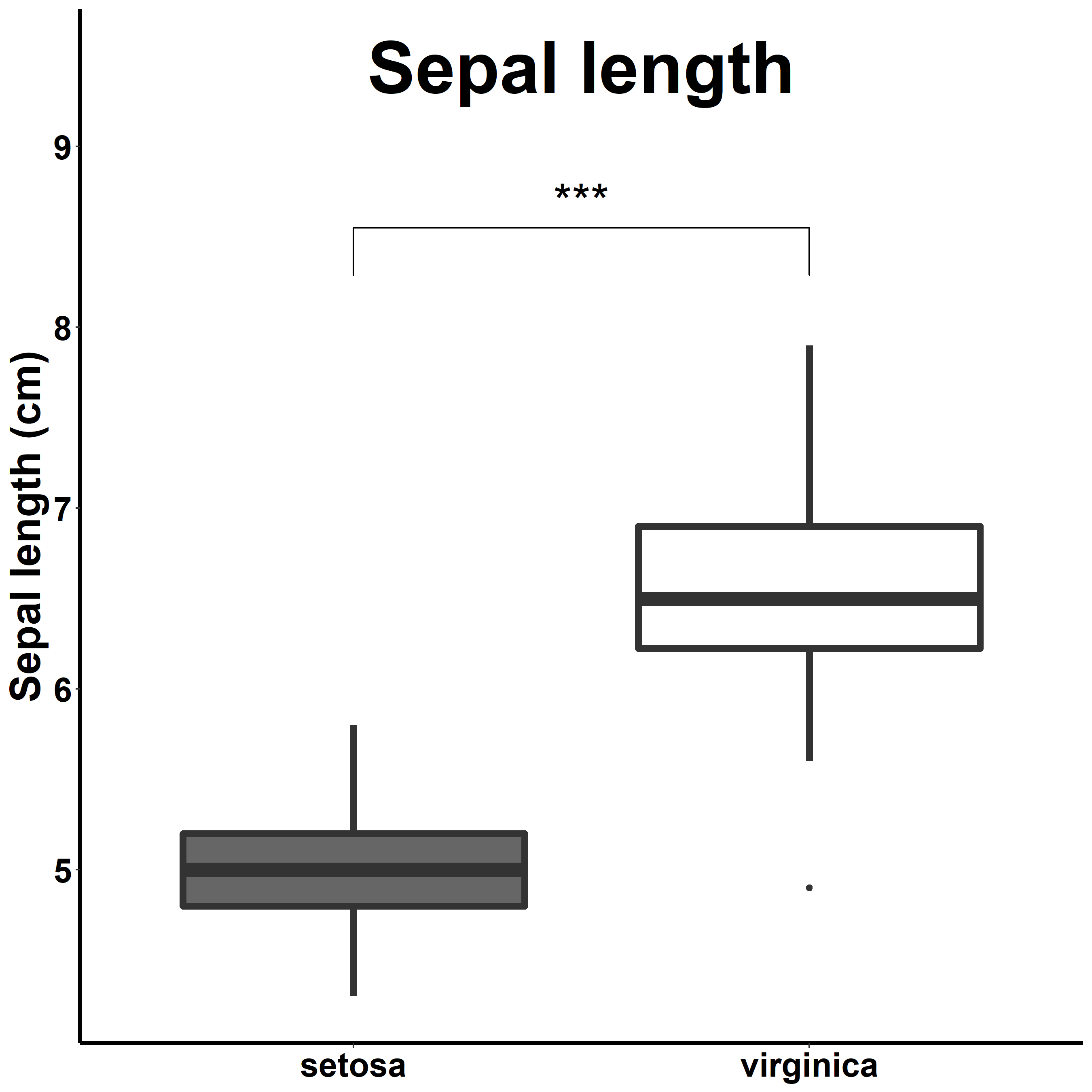
こんな感じになる。
同様にして、Sepal.Width, Petal.Length, Petal.Widthもやる。わかってる人はテキトーに飛ばしてほしい笑
# Sepal.Width
sw_g <- ggplot(data2, aes(x=Species, y=Sepal.Width, fill=Species)) +
geom_boxplot(lwd=2) +
theme(panel.grid = element_blank()) +
scale_fill_manual(values = c("gray40", "white")) +
labs(y="Sepal Width (cm)", x=NULL) +
theme(axis.text=element_text(size=20, face = "bold", colour = "black"),
axis.title=element_text(size=25,face="bold", colour = "black"),
axis.line = element_line(size = 1.2, colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
legend.position = "none",
) +
annotate("text", x=1.5, y=sw_yRoof,
label="Sepal Width",
vjust=0.7,
size=15,
fontface="bold") +
geom_signif(
y_position=sw_yRoof*0.85,
xmin=1.0,
xmax=2.0,
annotation= sig(sw_p),
tip_length=0.02,
textsize=10
)
# Petal.Length
pl_g <- ggplot(data2, aes(x=Species, y=Petal.Length, fill=Species)) +
geom_boxplot(lwd=2) +
theme(panel.grid = element_blank()) +
scale_fill_manual(values = c("gray40", "white")) +
labs(y="Petal Length (cm)", x=NULL) +
theme(axis.text=element_text(size=20, face = "bold", colour = "black"),
axis.title=element_text(size=25,face="bold", colour = "black"),
axis.line = element_line(size = 1.2, colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
legend.position = "none",
) +
annotate("text", x=1.5, y=pl_yRoof,
label="Petal Length",
vjust=0.7,
size=15,
fontface="bold") +
geom_signif(
y_position=pl_yRoof*0.85,
xmin=1.0,
xmax=2.0,
annotation= sig(pl_p),
tip_length=0.02,
textsize=10
)
pw_g <- ggplot(data2, aes(x=Species, y=Petal.Width, fill=Species)) +
geom_boxplot(lwd=2) +
theme(panel.grid = element_blank()) +
scale_fill_manual(values = c("gray40", "white")) +
labs(y="Petal Width (cm)", x=NULL) +
theme(axis.text=element_text(size=20, face = "bold", colour = "black"),
axis.title=element_text(size=25,face="bold", colour = "black"),
axis.line = element_line(size = 1.2, colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
legend.position = "none",
) +
annotate("text", x=1.5, y=pw_yRoof,
label="Petal Width",
vjust=0.7,
size=15,
fontface="bold") +
geom_signif(
y_position=pw_yRoof*0.85,
xmin=1.0,
xmax=2.0,
annotation= sig(pw_p),
tip_length=0.02,
textsize=10
)
定義したp値(sl_pとか)やyの最大値(pw_yRoofとか)を間違えないように。
ggpubrによる複数グラフのまとめ
ggpubrを使ってまとめていくが、その前に、そのまままとめるとグラフ同士が近すぎて見にくかったり干渉したりするので、余白を空けておく。
sl_g <- sl_g + theme(plot.margin = unit(c(0.5, 0.5, 0.5, 0.5), "cm"))
sw_g <- sw_g + theme(plot.margin = unit(c(0.5, 0.5, 0.5, 0.5), "cm"))
pl_g <- pl_g + theme(plot.margin = unit(c(0.5, 0.5, 0.5, 0.5), "cm"))
pw_g <- pw_g + theme(plot.margin = unit(c(0.5, 0.5, 0.5, 0.5), "cm"))
早速使っていく。
library(ggpubr)
png(filename = "ggpubr.png", width = 1000, height = 1200, res = 100)
ggpubr::ggarrange(sl_g, sw_g, pl_g, pw_g,
nrow=2, #何行に分けるか
ncol=2, #何列に分けるか
labels = c("A", "B", "C", "D"), #振るアルファベット。下記参照
font.label = list(size = 20, #アルファベットのフォントの調整
color = "black",
face = "bold",
family = NULL),
hjust=-1, vjust=1.8) #アルファベットの場所
dev.off()
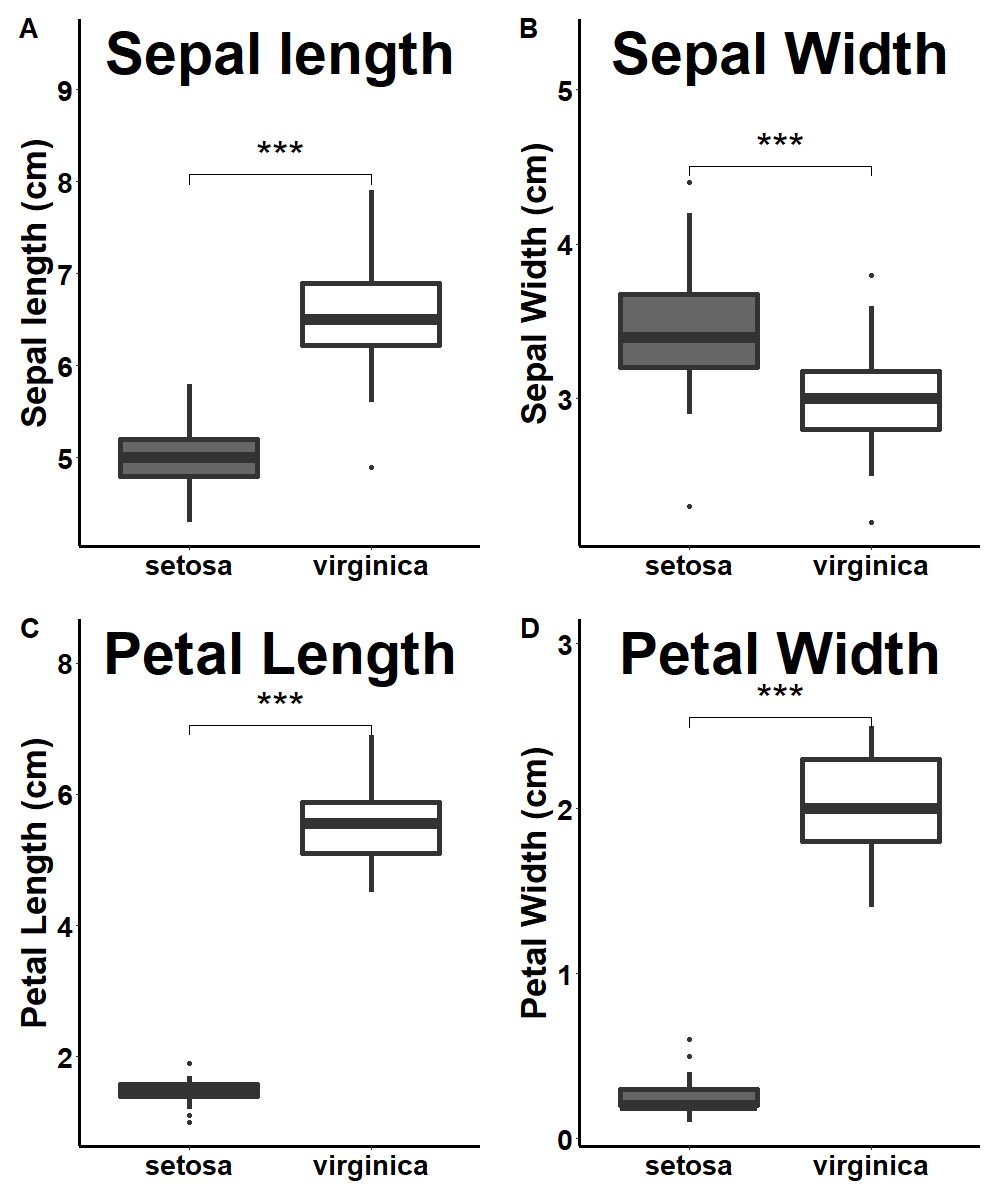
若干各データのタイトルが大きい気がするが、そのへんは各自で調整してほしい。
ちなみに、
labels = LETTERSとすると、勝手に大文字のアルファベットを、
labels = lettersとすると、小文字のアルファベットを振ってくれる。
論文執筆者にはすごく便利だと思う。
おまけ:凡例だけを取り出して、任意の場所につける
複数のグラフの場合、すべてのグラフに凡例がくっついていると、正直くどい。
なので、これに凡例を付けるときは、プロットから凡例だけ取り出して、任意の場所につけたほうが具合がいい。
凡例用のプロットを作成する
上のプロット(sl_g, sw_g, pl_g, pw_g)の中から1つどれでもいいので選び、凡例の情報だけ取り出す。
pw_gを取り出してみる。
上ではすべてのプロットで、
legend.position = "none"
としていたが、これでは凡例が生成されないので、
legend.positon = "right"とかにする(なんでもいいけど)。
for_legend <- ggplot(data2, aes(x=Species, y=Petal.Width, fill=Species)) +
geom_boxplot(lwd=2) +
theme(panel.grid = element_blank()) +
scale_fill_manual(values = c("gray40", "white")) +
labs(y="Petal Width (cm)", x=NULL) +
theme(axis.text=element_text(size=20, face = "bold", colour = "black"),
axis.title=element_text(size=25,face="bold", colour = "black"),
axis.line = element_line(size = 1.2, colour = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
legend.position = "right", #以下、変更点
legend.title = element_text(size = 20, face = "bold", colour = "black"), #凡例タイトルの文字太く黒く
legend.text = element_text(size = 20, face = "bold", colour = "black"), #凡例の文字太く黒く
)
有意差マークなどの情報もいらないので抜いといた。
凡例の情報を抜き出す
for_legendからlegendの情報を抜き出す。
ggplotGrobを使う。
fl_gtable <- ggplotGrob(for_legend)
# guide-boxは凡例のこと
fl_gtable[["grobs"]][[grep("guide-box", fl_gtable$layout$name)]]
# そこまで詳しくないので説明割愛
legend <- gtable::gtable_filter(fl_gtable, pattern = "guide-box")
最後に、ggpubrで凡例も含めてまとめて完成(ggpubr有能すぎる)
png(filename = "ggpubr2.png", width = 1800, height = 1200, res = 100)
ggpubr::ggarrange(sl_g, sw_g, legend, pl_g, pw_g, #legendを入れた
nrow=2,
ncol=3, #3列にした
labels = c("A", "B", NA, "C", "D"), #凡例にはアルファベット振らないでのNA
font.label = list(size = 20,
color = "black",
face = "bold",
family = NULL),
hjust=-1, vjust=1.8)
dev.off()
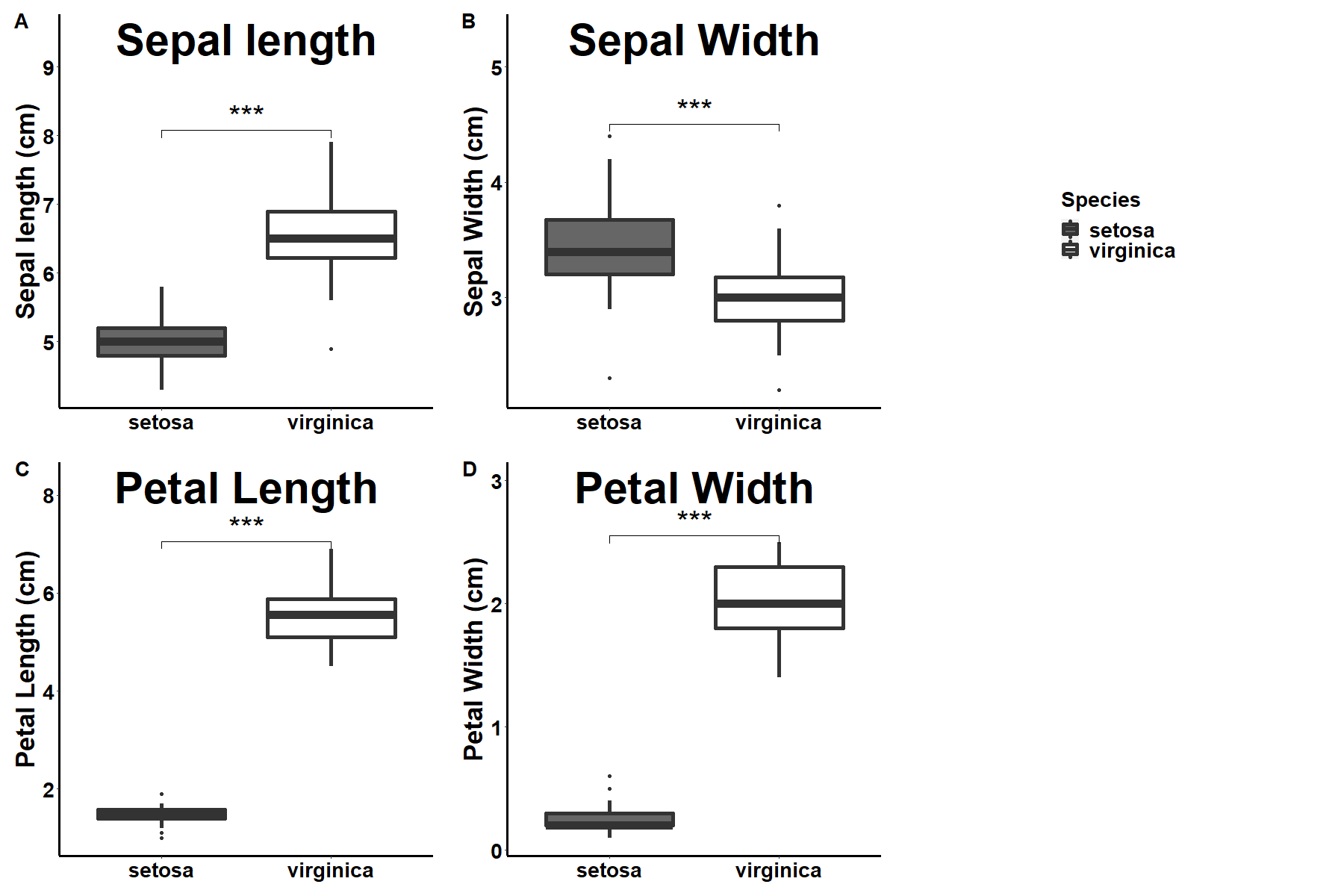
これで、かなり論文っぽくなったのではないだろうか。
凡例を大きくするには、凡例用のプロット(今回ならfor_legend)のパラメータを変えて大きくする。
参考にさせていただいたサイト
複数プロットをまとめる
https://qiita.com/nozma/items/cd98ec7938e0783d5d89
凡例の取り出し
https://uribo.hatenablog.com/entry/2018/09/13/225604
ggplot2のパラメータあれこれ
https://knknkn.hatenablog.com/entry/2019/02/23/181311