11月28日のAWS re:Invent 2018のKeynoteにてAmazon Elastic Inferenceのリリースがアナウンスされました。本記事では、Keynoteとセッション内容を踏まえて解説していきます。
機械学習における推論コスト問題
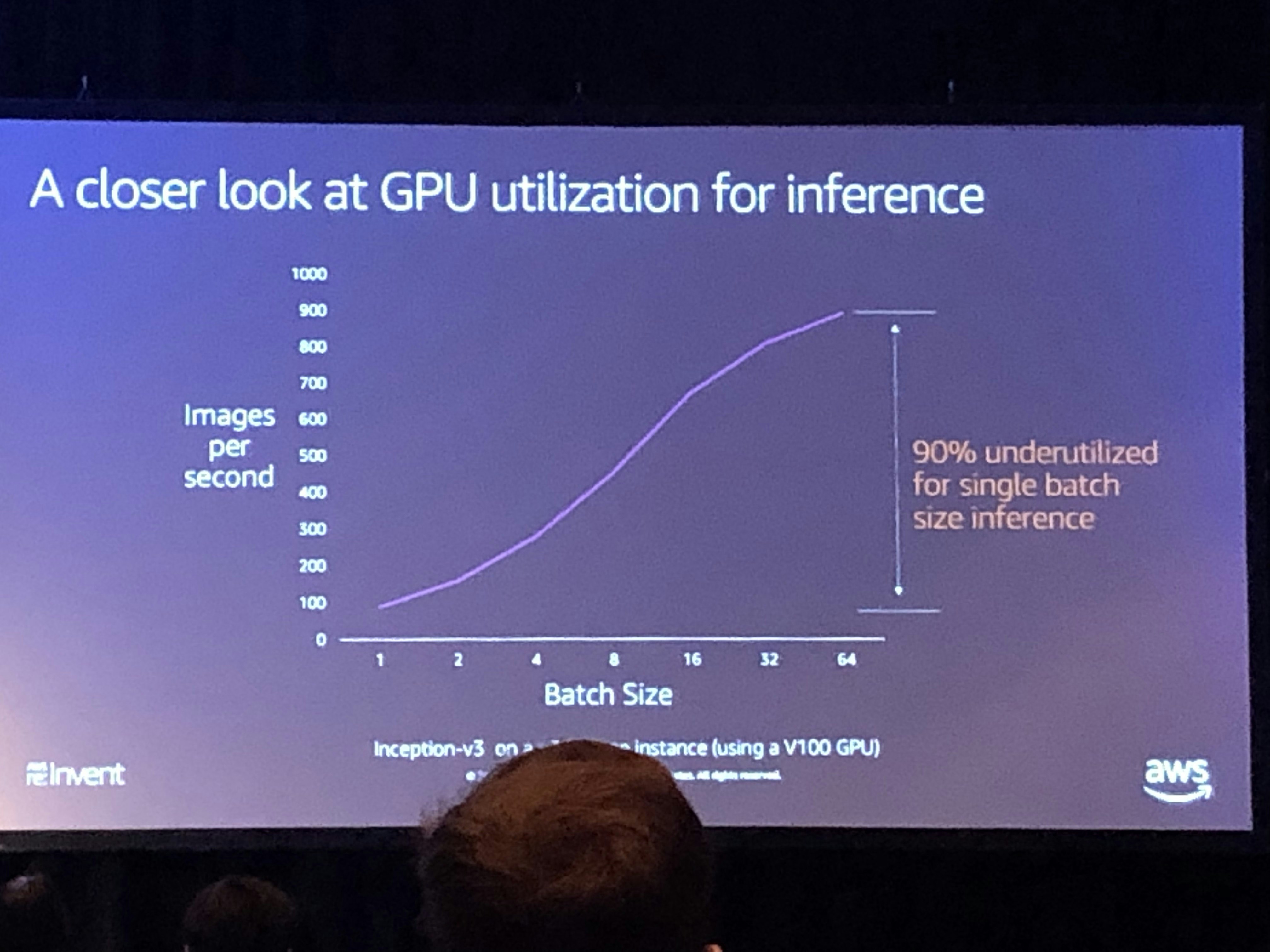
機械学習において、学習時と推論時ではGPUインスタンス利用率はまるで違います。特に深層学習などの大規模モデルは、学習時はハイスペックなGPUインスタンスを必要としますが、一方で推論時にはGPUはそれほど必要でなく、どちらかというとモデルを乗せるアプリケーション全体のパフォーマンスを重視して、CPUやRAMなどのリソースに割り当てることを最優先にした方が良いケースがほとんどです。セッション中でも、GPUの推論時のコスト問題に関して問題提起されていました。AWSによるとDeepLearningの利用においてインスタンス費用の90%が推論で残り10%が学習にかかっているようです。

Amazon Elastic Inferenceとは
上記のような状況の中で、AWSから新サービス、Amazon Elastic Inferenceがリリースされました。
Elastic InferenceとはEC2インスタンスにGPUによる推論アクセラレーションをアタッチするためのサービスで、アプリケーションに最適なCPUインスタンスタイプを選択し、適切な量のGPUアクセラレーションをアタッチすることで、無駄なリソースのコストカットを行います。

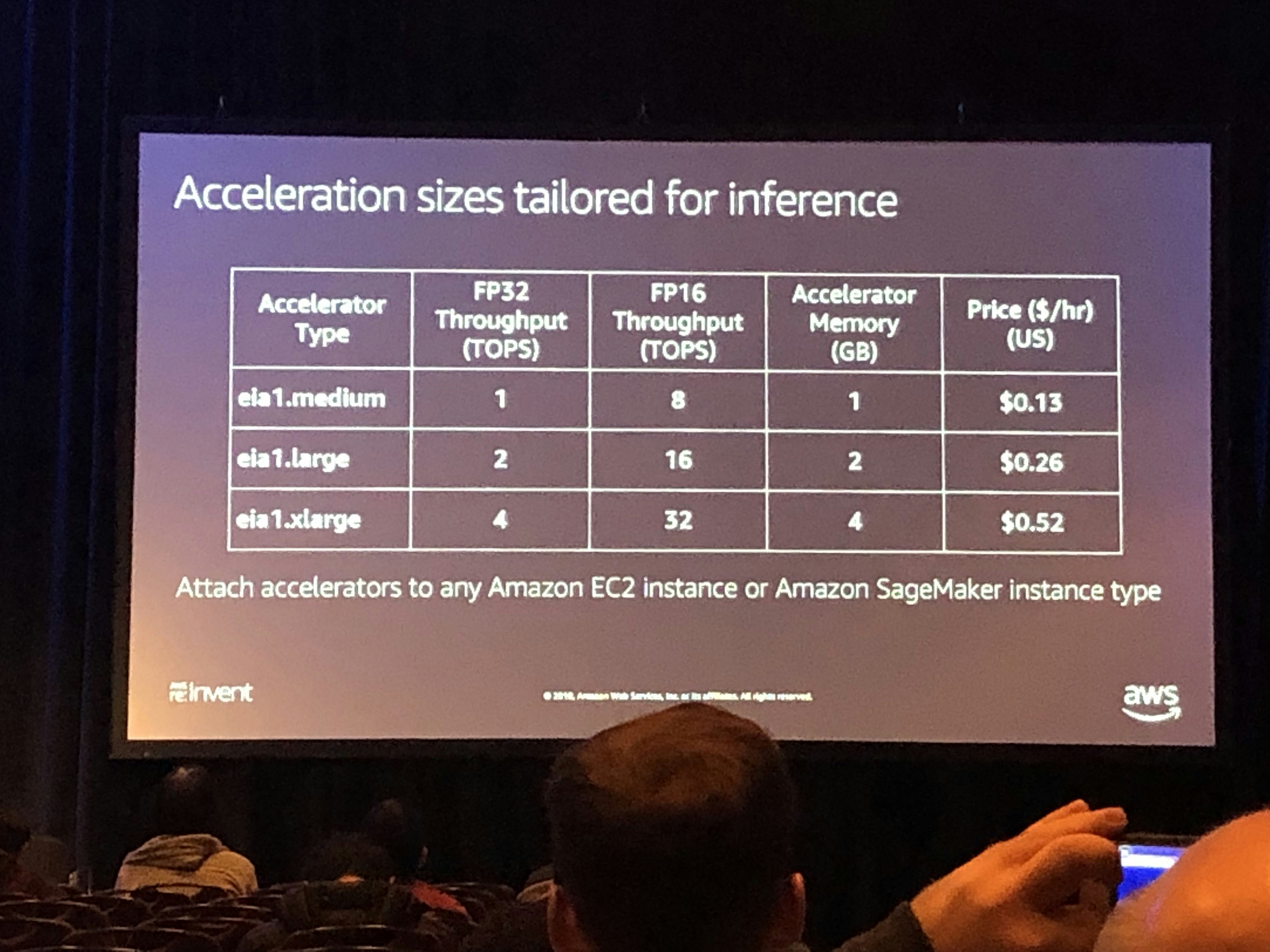
アクセラレーションサイズの種類
Elastic Inferenceには3つのサイズが利用可能で、1〜32【TFLOPS】のスループットが利用できるようです。これらのアクセラレーションはEC2インスタンスにもSageMakerインスタンスにもアタッチ可能です。
・eia1.medium
・eia1.large
・eia1.xlarge
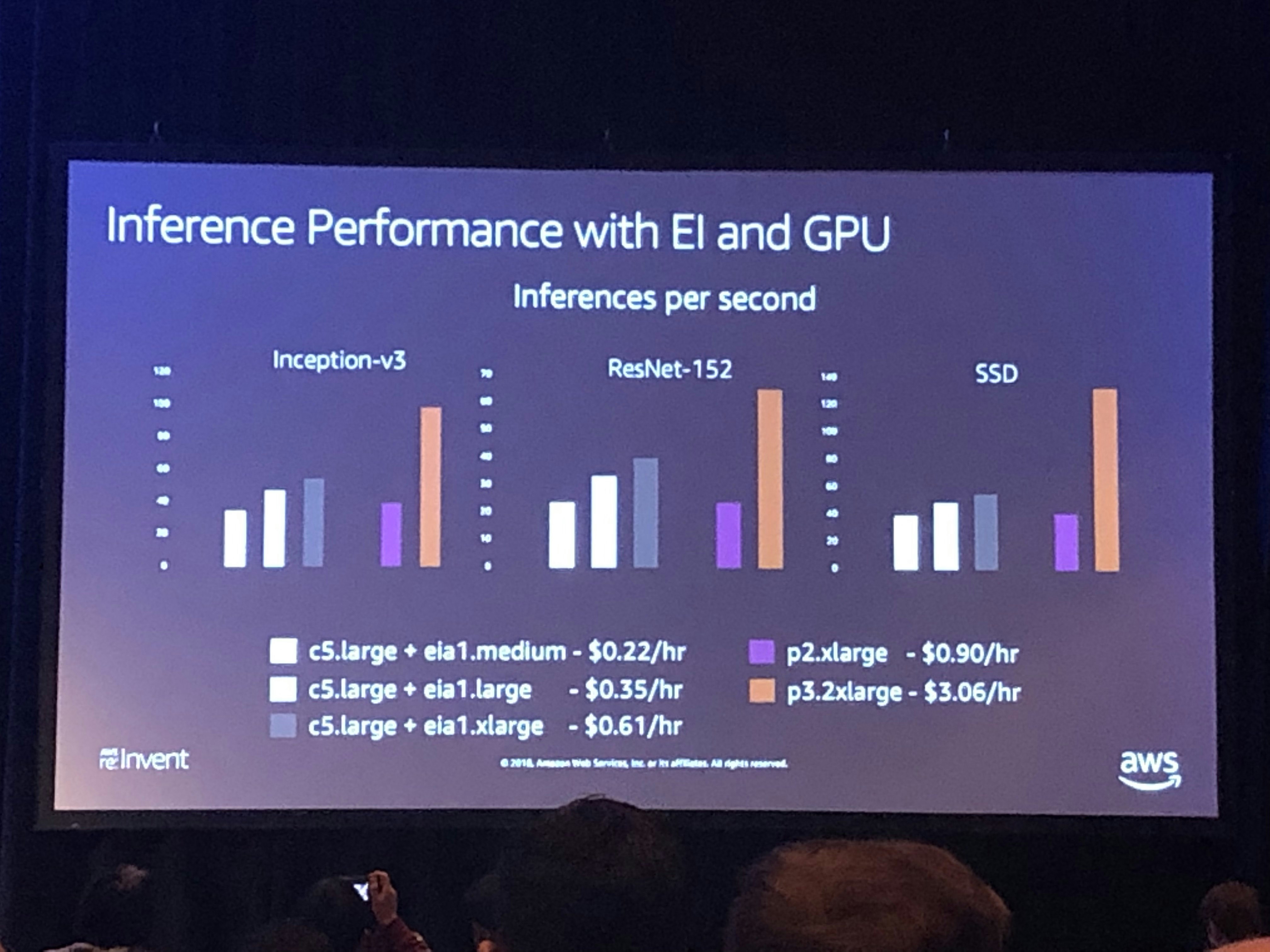
コスト面
セッションでは従来の方法とのコスト比較結果が述べられていました。例えば、C5.largeにeia1.mediumをアタッチすると、専用のNVIDIAをホストしたp2.xlargeインスタンスよりも約1/4のコストで済みます。めちゃくちゃ安いですね。。。
もちろん10%程度遅くなってしまいますが、p2.xlargeの仮想CPU数の少なさによるアプリケーションの影響とコスト面を考えると、Elastic Inferenceはかなり強力なGPUアタッチサービスと言えます。
サポートフレームワーク
Elastic Inferenceは現在以下の機械学習フレームワークをサポートしています。PyTorchなどの他のフレームワークにも今後対応予定とのこと。
・TensorFlow
・MXNet
・ONNX(MXNet経由)
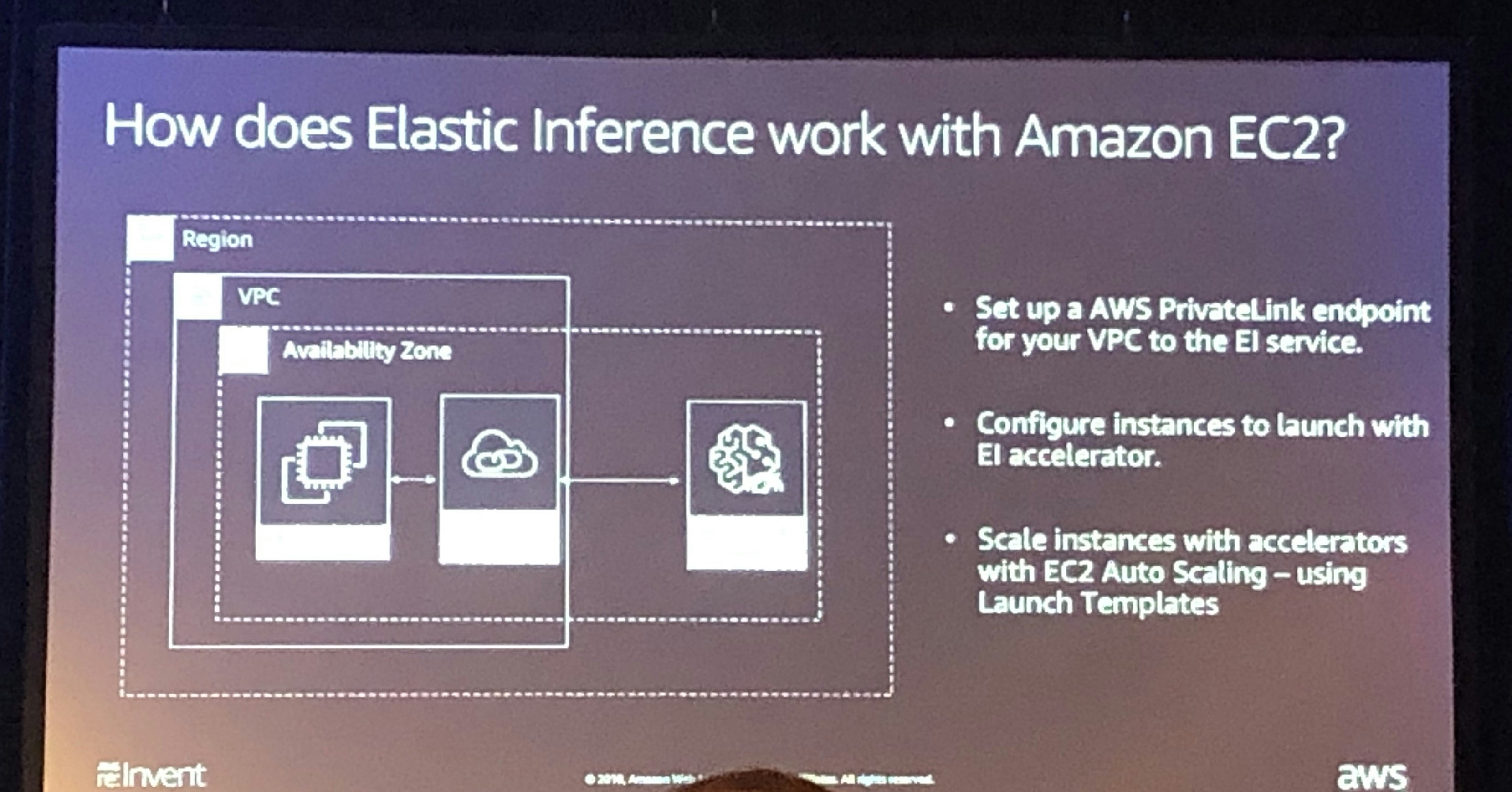
EC2へのアタッチ
アクセラレータはAWS PrivateLinkエンドポイントサービスを使用してネットワーク経由で接続します。
自動スケーリングインスタンスを設定するには、アクセラレータタイプとともにインスタンス設定で起動テンプレートを指定します。
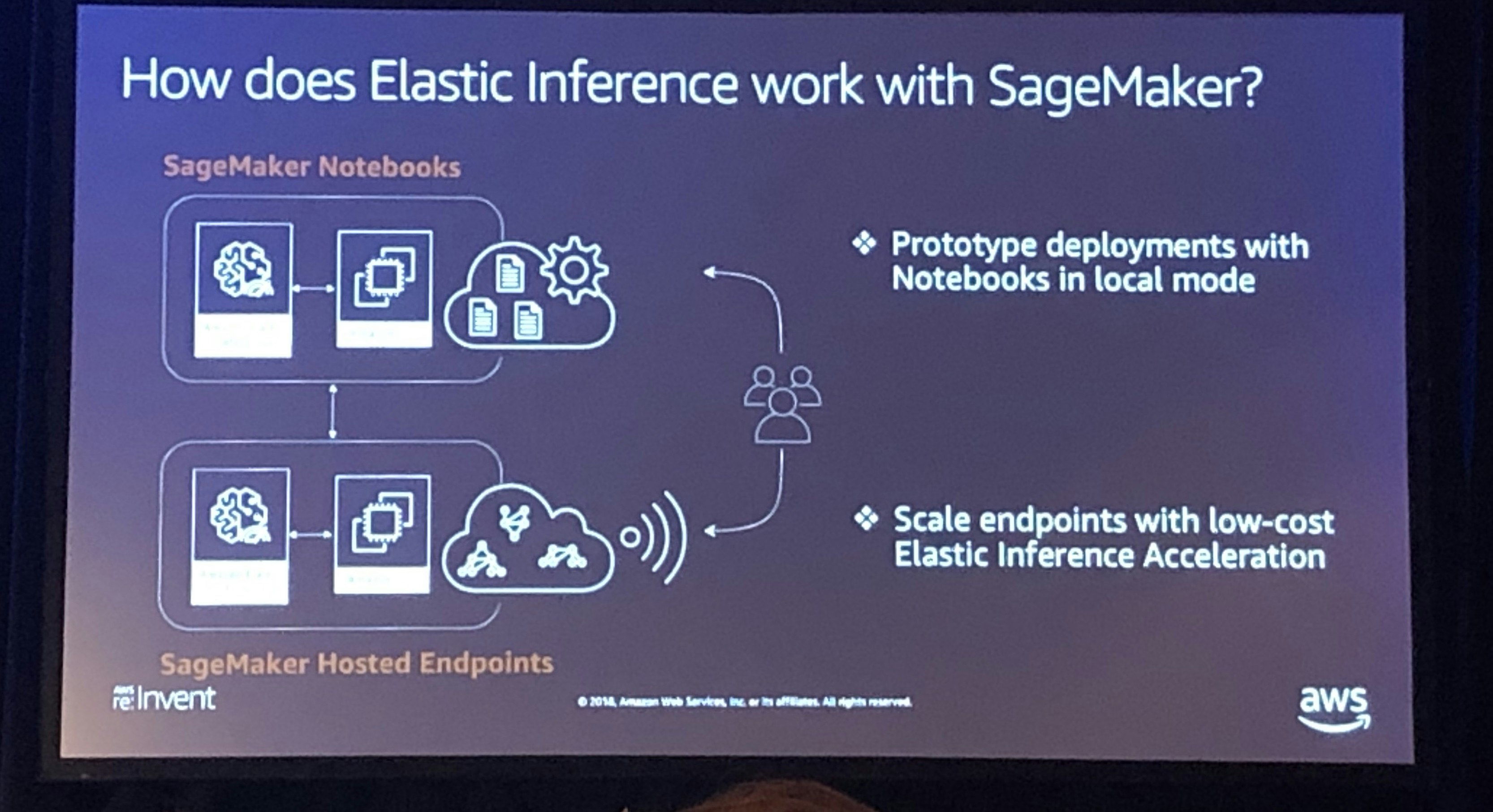
SageMakerとの組み合わせ
ローカルCPUリソースとアクセラレータが接続されたリソース間で計算を分散することができます。
この機能はSageMaker経由のS3上のDeepLearning AMIで利用できるので、自身のコンテナに組み込むことも可能です。
終わりに
AIブームの最中、コスト面に問題を抱えている方は非常に多いと思います。
今回登場したElastic Inferenceの推論コスト最適化によって今後のアプリケーション開発がどう変化していくのか楽しみです。