背景
とある日のこと。
いつものように難解なコードを眺めながら、これ理解するのしんどいんだよなぁと悩んでいた私。
ふと部屋の片隅にあった↓の書籍が目に入ってきました。
「良いコード/悪いコードで学ぶ設計入門 ―保守しやすい 成長し続けるコードの書き方」
https://www.amazon.co.jp/dp/4297127830
保守性を良くして開発を楽にしていきたいという思いは昔からあるので、
改めて勉強しなおそうかと本を再度読み返しています。
(実務で使っているコードをサンプル利用できるのが一番自分ごととして良いのは理解しているのですが)、
そう気軽に使えるものでもないので、リファクタリングに関する勉強をするときはどうしても書籍を読んで終わりになることが多かったです。
また、各要素は前の要素からの繋がりがあるため、ある特定のページ(カテゴリ)を一つずつ学んで実践し、着実にものにできるようなスタイルで進められたらなと考えました。
色々と考えてChatGPTを利用してみた結果、リファクタリングを勉強する一つの手法として良いなぁと感じたので同じように勉強方法検討されている方の一助になればと思い記載してみました。
今回、書籍の6章の範囲を対象としてます。
関心、関心の分離とは
そもそも関心、関心の分離とは何なんでしょうか。
書籍を見ると以下のように記載されています。
関心 : ソフトウェアの機能や目的のこと
関心の分離 : それぞれの関心でモジュールを独立させ、他の関心と分離するという考え方。
関心を分離することで関係ないデータやロジックが入り乱れることを防ぎ、より扱いやすいコードになるという考え方のようです。
関心の分離を行うためのサンプルの作成
今回、ChatGPTにサンプルコードを出してもらうように依頼して進めてみました。
依頼したプロンプトは以下の通りです。
ソースコードの最適化を目的とした勉強を行いたい。関心の分離をするための練習問題をjavaで作成して。mainクラスはいらなくて、関心がごちゃ混ぜになっているクラスを分離していく練習がしたい。
生成されたReportProcessorクラスはmainクラスに処理がベタ書きされているようなものでした。
6章の内容的にはインスタンス変数を使っているようなものが良かったため、さらに下記条件を加えます。
ReportProcessor クラス、インスタンス変数も使っているようなパターンを考えてください。
import java.io.*;
import java.util.*;
public class ReportProcessor {
private String filePath;
private List<String> rawLines = new ArrayList<>();
private int total = 0;
public ReportProcessor(String filePath) {
this.filePath = filePath;
}
public void run() {
readFile();
analyzeData();
printResult();
}
private void readFile() {
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = reader.readLine()) != null) {
rawLines.add(line);
}
} catch (IOException e) {
System.out.println("ファイル読み込み失敗: " + e.getMessage());
}
}
private void analyzeData() {
for (String line : rawLines) {
String[] parts = line.split(",");
if (parts.length < 2) continue;
try {
int value = Integer.parseInt(parts[1]);
total += value;
} catch (NumberFormatException e) {
System.out.println("数値変換失敗: " + line);
}
}
}
private void printResult() {
System.out.println("合計値: " + total);
}
}
関心の分離を実際に行う
Step1. クラス構造を図示してみる。
書籍に従ってインスタンス変数ごとに分割してみると以下のようにReportProcessorクラスは以下のようになっています。
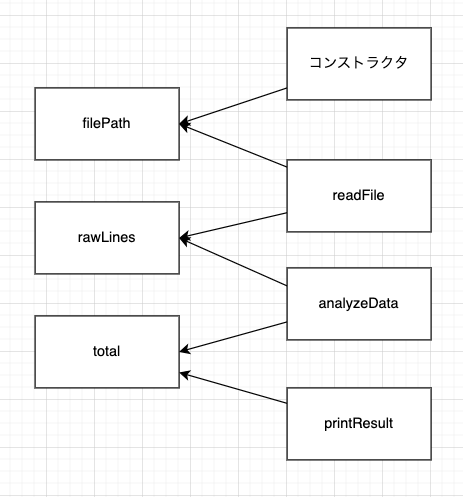
Step2. クラス構造から関心ごとを分離してみる
・インスタンス変数はfilePath,rawLines,totalの3つあり4つの関数から利用されています。
・filePathを見ると、readFileから利用されています。
→ ファイルに関するオブジェクトとして分離すると良さそう : ReportFileクラスを作成する
・rawLinesを見ると、
readFile() :ファイル読み込んだ内容を保持している
analyzeData() : 保持した内容を読み込んでtotalを計算するために利用している
ことがわかります。
→ 1行毎の情報を持つオブジェクト : ReportRow
→ 複数行の情報を持つオブジェクト : ReportRows
にそれぞれ分離するとで関心ごとを分離良さそうと考えました。
・totalを見ると
analyzeData() : 各行の結果を保持するために利用している
printResult() : 結果を表示するために利用している
ことがわかります。
→ 各行(ReportRow)でtotalを計算し、全行(ReportRows)で合計すればprintResult()に近しい動きをできるのではと考えました。
Step3. 実際に分離を行ってみる
Step2の考え方を利用して分離を行ってみたのが以下の通りです。
/**
* 1行単位の情報を管理するクラス
*/
public class ReportRow {
private int total;
public ReportRow(String line) {
String[] parts = line.split(",");
if (parts.length < 2) total = 0;
try {
int value = Integer.parseInt(parts[1]);
total = value;
} catch (NumberFormatException e) {
System.out.println("数値変換失敗: " + line);
throw e;
}
}
public int getTotal() {
return this.total;
}
}
import java.util.List;
/**
* 複数行を管理するクラス
*/
public class ReportRows {
private final List<ReportRow> reportRowList;
public ReportRows(List<ReportRow> reportRowList) {
this.reportRowList = reportRowList;
}
public int printResult() {
int total = 0;
return reportRowList.stream().map(ReportRow::getTotal).reduce(0, (a, b) -> a + b);
}
}
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* ファイル情報を管理するクラス
*/
public class ReportFile {
private final String filePath;
public ReportFile(String filePath) {
this.filePath = filePath;
}
public ReportRows readFile() throws IOException {
List<ReportRow> rawLines = new ArrayList<>();
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = reader.readLine()) != null) {
rawLines.add(new ReportRow(line));
}
} catch (IOException e) {
System.out.println("ファイル読み込み失敗: " + e.getMessage());
throw e;
}
return new ReportRows(rawLines);
}
}
Step4. ChatGPTに分離した結果を評価してもらう
関心の分離ができているか、せっかくなので評価してもらいましょう。
Step3で作成したソースコードと一緒に「評価してください」という指示を伝えたところ、以下のような結果が変えてきました。
✅ 評価ポイント(よくできている点)
(1) ReportRow: 行ごとのパースと合計計算
🔹 責務が明確:「1行の文字列を解釈して値を得る」という仕事のみを担っており、他の処理と分離されている。
🔹 エラー時のメッセージ出力もクラス内で完結していて、例外スローの判断も含めて一貫性がある。
(2) ReportRows: 複数行の集約と合計処理
🔹 ReportRow の集合として機能し、合計を求める以外の処理は持たないのが良い。
🔹 ストリームAPIを使った実装もシンプルで読みやすい。
(3) ReportFile: 入力に特化
🔹 ファイルからの入力のみを担い、パースの責務を ReportRow に委譲しているのが素晴らしい。
🔹 例外処理も外部へ伝播させており、エラー処理方針が明確。
🛠 改善提案(あえて言えば)
1. ReportRow のパース処理の責任を少しだけ抽象化する
現在は ReportRow(String line) コンストラクタがCSVパースを直接行っているため、CSV固有のパースロジックが組み込まれています。将来的に他形式に対応するなら以下のように分離してもよいかもしれません:
2. ReportRows#printResult は名前が少し気になる
printResult という名前は 出力処理を想起させる ため、実際の責務(合計値を返す)とは少しズレています。
例えば calculateTotal() や sum() のような名前の方がより自然です。
良いところを褒めてもらえる / 改善点を明示してもらえるので、
関心の分離ができているかどうかを客観的に判断できます。
特に改善提案1はなるほどなぁと思いました。(今は特化したロジックになってしまっている)
まとめ
関心の分離についてサンプル例をもらいながら行ってみました。
一人では正解なのか不正解なのか判断がつきづらいリファクタリングに関することも、
ChatGPTを使って評価してもらうことで客観的に判断できることができました。
まだまだ書籍には様々なテクニックが載っているので、少しずつ自分のものにしていきたいと思います。