はじめに
気軽にできる範囲内で、マイ・Guarded Horn Clauses コンパイラの性能改善を試みることにします。
これまでに行った改善内容
トレースログ削除
各 GIR 命令にトレースログを仕込んでいたので削除しました。
これにより、ログレベル判定コストを削減しました。
レジスタ消費削減
もともとは、節の中にローカル変数が出てくる毎に、レジスタ上に専用の場所を割り当てていました。これだと、以下のようにレジスタを多く消費することになります:
| ソースコード | X[5] | X[6] | X[7] | X[8] | X[9] | X[10] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
tarai(X, Y, _, R) :- X =< Y | R = Y. |
||||||||||||
otherwise. |
||||||||||||
tarai(X, Y, Z, R) :- true | |
||||||||||||
X1 := X - 1, |
X1 |
O[0] | O[1] | O[2] | ... | |||||||
tarai(X1, Y, Z, |
X1 |
|||||||||||
Rx), |
Rx |
O[0] | O[1] | O[2] | O[3] | O[4] | ... | |||||
Y1 := Y - 1, |
Rx |
Y1 |
O[0] | O[1] | O[2] | ... | ||||||
tarai(Y1, Z, X, |
Rx |
Y1 |
||||||||||
Ry), |
Rx |
Ry |
O[0] | O[1] | O[2] | O[3] | O[4] | ... | ||||
Z1 := Z - 1, |
Rx |
Ry |
Z1 |
O[0] | O[1] | O[2] | ... | |||||
tarai(Z1, X, Y, |
Rx |
Ry |
Z1 |
|||||||||
Rz), |
Rx |
Ry |
Rz |
O[0] | O[1] | O[2] | O[3] | O[4] | ... | |||
tarai(Rx, Ry, Rz, R). |
Rx |
Ry |
Rz |
O[0] | O[1] | O[2] | O[3] | O[4] | ... |
ここで、X[1] - X[4] は入力レジスタとして使われるため、一時変数として使うのは X[5] 以降のレジスタとなります。
O[0], O[1], O[2], ... と書いてある部分は、サブゴール呼び出し時にレジスタウィンドウの出力レジスタ、あるいはサブゴール呼び出し時の一時領域(末尾呼び出しの場合には入力レジスタへのコピーが発生する)として扱われる部分を表します。
性能のことを考えるともっとアクセスの局所性を改善するべきです。
また、レジスタウィンドウ方式を使っていることから、たらい回しのようにサブゴール呼び出しの連鎖が深い場合にはレジスタ使用量の多寡が思わぬインパクトを与える可能性があります。
例えば、上記の例の場合には以下のようにレジスタ使用量を減らすことができます:
| ソースコード | X[5] | X[6] | X[7] | ||||||
|---|---|---|---|---|---|---|---|---|---|
tarai(X, Y, _, R) :- X =< Y | R = Y. |
|||||||||
otherwise. |
|||||||||
tarai(X, Y, Z, R) :- true | |
|||||||||
X1 := X - 1, |
X1 |
O[0] | O[1] | O[2] | ... | ||||
tarai(X1, Y, Z, |
X1 |
||||||||
Rx), |
Rx |
O[0] | O[1] | O[2] | O[3] | O[4] | ... | ||
Y1 := Y - 1, |
Rx |
Y1 |
O[0] | O[1] | O[2] | ... | |||
tarai(Y1, Z, X, |
Rx |
Y1 |
|||||||
Ry), |
Rx |
Ry |
O[0] | O[1] | O[2] | O[3] | O[4] | ... | |
Z1 := Z - 1, |
Rx |
Ry |
Z1 |
O[0] | O[1] | O[2] | ... | ||
tarai(Z1, X, Y, |
Rx |
Ry |
Z1 |
O[0] | O[1] | O[2] | O[3] | O[4] | ... |
Rz), |
Rx |
Ry |
Rz |
||||||
tarai(Rx, Ry, Rz, R). |
Rx |
Ry |
Rz |
O[0] | O[1] | O[2] | O[3] | O[4] | ... |
これを実現するために、以下のようなレジスタ割付けアルゴリズムを実装しました:
- 準備として、節内に登場する各変数を寿命の長さ順にソートする。
- 最も寿命の長い変数から順に以下を行う。
- その寿命の範囲内すべてについてレジスタウィンドウ上で空きがある(未割り当てである)最低位アドレス位置に当該変数を割り当てる。
- 寿命の最も長い変数から最も短い変数に向かって、全ての変数に割り付けを繰り返す。
デリファレンス結果保存の削除
型無し言語の宿命で、なにか変数を受け渡しするたびに「デリファレンスしてからタグを確認」という処理を繰り返す必要があります。
当初は「入力レジスタ上の値をデリファレンスしたらデリファレンス結果を入力レジスタに書き戻す」ことでデリファレンスが繰り返された際のコストを削減しようとしていました。
ゴール再実行が必要になったときなどでのデリファレンス処理コストを削減できるかもしれない、という目論見だったのですが、実際にはゴール再実行の頻度はそこまで高くないこと、同じ入力レジスタの値を何度もデリファレンスするとも限らないことなどから書き戻し処理を削除しました。
デリファレンス処理でのタグ判定削減
予想外にインパクトが大きかったのはこれで、もとのデリファレンス処理は以下のような実装でした。
inline Q deref(Q q) {
for (;;) {
const TAG_T tag = tag_of(q); // 値のタグを取得
if (tag != TAG_REF) { // 参照タグでない場合には値をそのまま返す
break;
}
A* a = ptr_of<A>(q); // 参照タグなら参照先を手繰る
const Q q2 = a->load();
if (q == q2) { // 自己参照ループならそのまま返す
break;
}
q = q2; // 自己参照ループでないなら手繰ることを繰り返す
}
return q;
}
タグ REF は通常の参照を、タグ SUS は当該ポインタが指す先がサスペンションレコード(変数の具体化待ちゴールの情報)の先頭であることを表します(具体化待ち合わせ の図を参照)。
未具体化変数の具体化待ち処理追加の際に、REF だけでなく SUS も手繰っていけるように判定条件に追加していました。
inline Q deref(Q q) {
for (;;) {
const TAG_T tag = tag_of(q);
if ((tag != TAG_REF) || (tag != TAG_SUS)) { // ← ここに条件を追加
break;
}
A* a = ptr_of<A>(q);
const Q q2 = a->load();
if (q == q2) {
break;
}
q = q2;
}
return q;
}
IF 分岐に条件を一つ追加するだけのことなのですが、これにより大きく性能が下がっていました。
deref 関数の条件分岐は元の REF だけの判定に戻して、タグ SUS での参照の連鎖が起きないようにする(タグ SUS は自己参照ループのみとし、タグ SUS による参照をコピーする際には REF 参照に書き換える)、ということで deref 関数内の分岐を元の REF のみチェックする形に戻しました。
整数演算の最適化
:=/2 は与えられた任意の数式を処理して答えを与えます。
引数に与えられた構造体が和・差・積・商のどれに該当するかをパターンマッチにより実行時に調べる、ということを再帰的に行うのでそれなりに重い処理です。
ループ処理でのインクリメント・デクリメントで :=/2 はよく使うので、これを高速化できればかなりの効果があります。
インデキシングを実装してパターンマッチを高速化するというのが正攻法なのだろうと思います。これができれば整数演算以外も高速化できるはずなのですが、あまり気軽に実装できそうな気がしませんでした。
お手軽に、コンパイル時にパターンマッチを済ませてしまう形で実装することにしました。
C := A + B, C := A - B, C := A * B, C := A / B, C := A mod B はそれぞれ対応する組み込み述語を直接呼び出しするコードを生成するように修正しました。
引数 A, B は実行時にしか型が特定できず、場合によっては具体化待ち合わせすら必要となるため、これらに再帰的なパターンマッチを適用する必要があるのは同じですが、ほとんどの場合これらは単純な整数のはずなので性能へのインパクトは比較的小さいと想定しています。
更に、C := A + 1 や C := A - 1 といったパターンについてはインクリメント・デクリメントの組み込み述語を新たに設けて特別に対応しました。
この引数 A についてもやはり再帰的パターンマッチや待ち合わせが必要ですが、性能へのインパクトが比較的小さいのは同じです。
さらに =:=/2 と =\=/2 の右辺の数式についても同様の最適化を行うことにしました。
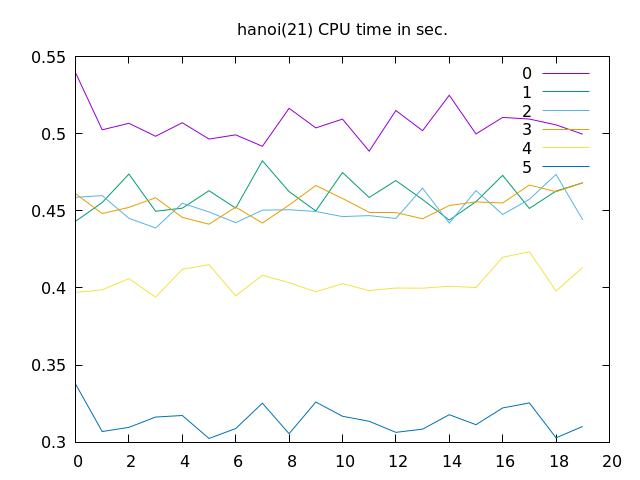
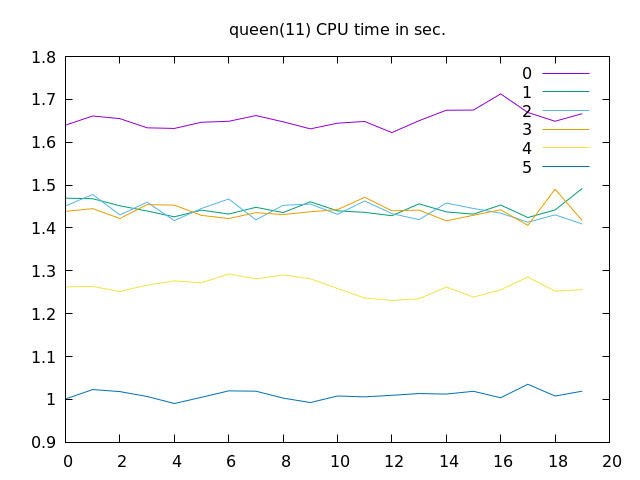
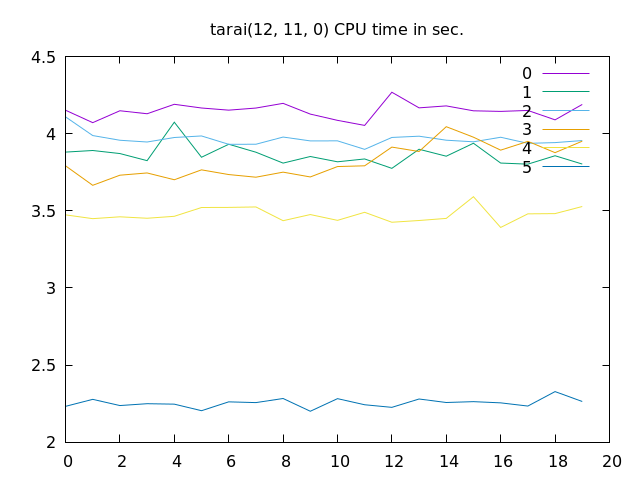
性能改善の効果
それぞれについて性能改善効果を確認してみました。
[0] 性能改善前
[1] トレースログ削除
[2] 1 + レジスタ消費削減
[3] 1 + 2 + デリファレンス結果保存の削除
[4] 1 + 2 + 3 + デリファレンス処理でのタグ判定削減
[5] 1 + 2 + 3 + 4 + 整数演算の最適化
「[1] トレースログ削除」はそれなりの効果があります。とはいえ、なにか不具合が発生したときに困るかもしれないので、コンパイルオプションでトレースログあり・なしを切り替えられるようにするべきかもしれません。
「[2] レジスタ消費削減」は初期レジスタ数を十分多く用意しておけば実行時間への影響はほとんどないようです。
「[3] デリファレンス結果保存の削除」に至ってはこうしてみると全く影響があるように見えません。影響がないなら余計な処理は削除しておこう、程度のものになっています。
「[4] デリファレンス処理でのタグ判定削減」は字面からは想像できないくらいのインパクトがあります。
「[5] 整数演算の最適化」もかなりの効果があります。
ハノイの塔
N-Queens
tarai
まとめ
マイ・GHC コンパイラはマルチスレッド推論を目標に実装しているので、シングルスレッドなら不必要な処理(例えば、WAM の get 系命令に相当する処理において、構築中の構造体を他スレッドに見せないために単一化を繰り返すようなことを行っている、など)があったりで通常の Prolog と比較して性能向上に関しては不利な面もあります。
それでも、ハノイの塔や、たらい回しについては当面の目標としていた SWI-Prolog を上回る速度を実現できました。
にも関わらず、N-Queens については SWI-Prolog に負けています。なにかが足を引っ張っている要因があるはずなのですが、それがなんなのかはまだ特定できていません。
また、コンパイラベースの実装として本来比較すべきは GNU-Prolog でしょう。
たらい回しについて GNU-Prolog でバイナリを生成すると 4 倍近く速いコードを生成するので、まだまだ伸びしろはあると思います。