はじめに
こちらは、NTTドコモ R&D Advent Calendar 2020の12日目の記事となります。
こんにちは!NTTドコモの大杉です。
昨年度は、socceractionというサッカーのデータ分析に関するpythonパッケージを紹介させていただきました。
今年もsocceractionを活用した、サッカーに関する分析をしてみたいと思います。
具体的には、トピックモデルの手法の1つであるLDA(Latent Dirichlet Allocation)を用いて、各選手の1試合におけるプレーエリアからその選手のポジションを分類してみたいと思います。
分析の流れとサマリ
-
FIFAW杯ロシア大会における全選手の各位置(5m×5m区切り)でのプレー回数を集計し、LDAを用いて分析を実施しました。
-
11トピックに分類し、各位置のプレー回数からある程度ポジションを分類することができました。
- 各トピックの所属確率の高いプレー位置は下記図の通りです。(左から右に攻撃)

- 各トピックの所属確率の高いプレー位置は下記図の通りです。(左から右に攻撃)
-
日本代表の選手の最も所属確率が高いトピックを抽出することで、各選手における特徴を確認しました。
分析方法について
LDAは自然言語処理等で用いられるトピックモデルの一つです。
各文章における単語の出現頻度から、単語の潜在的なトピック(カテゴリ)を抽出し、各文章がどのようなトピックに属しているかを分類することができます。
今回は詳細な説明は割愛させていただきます。詳しい内容については、下記リンク等が参考になると思います。
実際に分析してみる
パッケージの準備
import numpy as np
import pandas as pd
import tqdm
import socceraction.spadl as spadl
import socceraction.vaep.features as fs
import socceraction.spadl.statsbomb as statsbomb
import seaborn as sns
import matplotlib.pyplot as plt
import gensim
from gensim import models,corpora
データの取得
今回も昨年同様、statsbombのオープンデータを活用して分析を進めていきます。

statsbombのオープンデータはgithubに上がっています。
データの取得方法については、socceractionのgithubにある下記のpublic-notebookを参考に進めていきます。
大会データの取得
はじめに大会データを取得し、どのようなオープンデータがあるかを確認してみます。
ここでは、利用可能な大会のデータを抽出し、オープンデータとして存在しているシーズン数を確認しています。
free_open_data_remote = "https://raw.githubusercontent.com/statsbomb/open-data/master/data/"
SBL = statsbomb.StatsBombLoader(root=free_open_data_remote,getter="remote")
comp = SBL.competitions()
comp.competition_name.value_counts()
出力結果は以下のようになりました。
La Liga 16
Champions League 15
FA Women's Super League 2
Women's World Cup 1
NWSL 1
FIFA World Cup 1
Premier League 1
Name: competition_name, dtype: int64
現在利用可能なデータでは、La Liga(スペイン)は16シーズン、Champions Leagueは15シーズンと比較的長期間のデータが存在していることがわかります。
データを確認したところ、La Ligaについてはバルセロナ試合のデータ、Champions Leagueについては決勝の試合データがオープンデータとして公開されているようでした。
今回は、日本代表も出場していた2018年のFIFA W杯のデータを利用したいと思います。
試合データの取得
次に、取得したい大会のデータを選択し、試合のデータを取得します。
selected_competitions = comp[comp.competition_name=="FIFA World Cup"]
matches = list(
SBL.matches(row.competition_id, row.season_id)
for row in selected_competitions.itertuples()
)
matches = pd.concat(matches, sort=True).reset_index(drop=True)
print(matches.columns)
試合データを確認すると、以下のようなデータが格納されていることがわかります。
Index(['away_score', 'away_team_gender', 'away_team_group', 'away_team_id',
'away_team_name', 'competition_id', 'competition_name', 'country_name',
'data_version', 'home_score', 'home_team_gender', 'home_team_group',
'home_team_id', 'home_team_name', 'id', 'kick_off', 'last_updated',
'managers', 'match_date', 'match_id', 'match_status', 'match_week',
'name', 'season_id', 'season_name'],
dtype='object')
試しにいくつかの項目をピックアップして見てみます。
試合の開催日、対戦相手、各チームの得点等を確認できます。
matches[["match_id","home_team_name","away_team_name","match_date","home_score","away_score"]].head()
| match_id | home_team_name | away_team_name | match_date | home_score | away_score | |
|---|---|---|---|---|---|---|
| 0 | 7581 | Croatia | Denmark | 2018-07-01 | 1 | 1 |
| 1 | 7549 | Nigeria | Iceland | 2018-06-22 | 2 | 0 |
| 2 | 7555 | Poland | Colombia | 2018-06-24 | 0 | 3 |
| 3 | 7529 | Croatia | Nigeria | 2018-06-16 | 2 | 0 |
| 4 | 7548 | Brazil | Costa Rica | 2018-06-22 | 2 | 0 |
プレーデータの取得
次に、試合データのmatch_idを用いて各試合における選手のプレーデータを取得します。
def load_play_data():
matches_verbose = tqdm.tqdm(list(matches.itertuples()),desc="Loading match data")
teams,players,player_games = [],[],[]
actions = {}
for match in matches_verbose:
teams.append(SBL.teams(match.match_id))
players.append(SBL.players(match.match_id))
events = SBL.events(match.match_id)
player_games.append(statsbomb.extract_player_games(events))
actions[match.match_id] = statsbomb.convert_to_actions(events,match.home_team_id)
players = pd.concat(players).drop_duplicates("player_id").reset_index(drop=True)
players['player'] = players[["player_nickname","player_name"]].apply(lambda x: x[0] if x[0] else x[1],axis=1)
games = matches.rename(columns={"match_id":"game_id"})
teams = pd.concat(teams).drop_duplicates("team_id").reset_index(drop=True)
player_dict = dict(players.set_index('player_id')['player'])
home_id_team_dict = dict(games.set_index('game_id')['home_team_id'])
team_dict = dict(teams.set_index('team_id')['team_name'])
return actions,player_dict,home_id_team_dict,team_dict,games
actions,player_dict,home_id_team_dict,team_dict,games = load_play_data()
ここで取得したデータは下記の通りとなります。
- player_dict : 各player_idと選手名(本名orニックネーム)が格納されたdict
- home_id_team_dict : 各game_id(=match_id)とホームチームのteam_idが格納されたdict
- team_dict : 各team_idとチーム名が格納されたdict
- games : 各試合のデータに関するデータフレーム
- actions : 各試合における行動データに関するデータフレームが格納されたdict
actionsは各game_id毎に以下のようなデータフレームを持ちます。
| game_id | period_id | time_seconds | timestamp | team_id | player_id | start_x | start_y | end_x | end_y | type_id | result_id | bodypart_id | action_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7581 | 1 | 1.0 | 00:00:01.013 | 776 | 3043 | 52.058824 | 34.430380 | 73.235294 | 30.987342 | 0 | 1 | 0 | 0 |
| 1 | 7581 | 1 | 2.0 | 00:00:02.653 | 776 | 3027 | 73.235294 | 30.987342 | 72.352941 | 35.291139 | 21 | 1 | 0 | 1 |
| 2 | 7581 | 1 | 4.0 | 00:00:04.053 | 776 | 3027 | 72.352941 | 35.291139 | 20.294118 | 48.202532 | 0 | 0 | 0 | 2 |
| 3 | 7581 | 1 | 7.0 | 00:00:07.000 | 785 | 5468 | 20.294118 | 48.202532 | 41.470588 | 40.455696 | 0 | 0 | 1 | 3 |
| 4 | 7581 | 1 | 9.0 | 00:00:09.293 | 776 | 5527 | 41.470588 | 40.455696 | 45.882353 | 40.455696 | 0 | 1 | 1 | 4 |
actionsに格納されているデータフレームの変数は以下の通りです。
- game_id : 試合のid
- period_id : 前半/後半/延長戦前半/延長戦後半/PK戦を表すid
- time_seconds : 経過時間
- timestamp : 各periodにおける時間
- team_id : プレーした選手が所属するチームのid
- player_id : プレーした選手のid
- start_x : プレーを開始した際のx座標
- start_y : プレーを開始した際のy座標
- end_x : プレーが終了した際のx座標
- end_y : プレーが終了した際のx座標
- type_id : プレー内容についてのid
- result_id : プレー結果についてのid
- bodypart_id : プレーの際に使用した部位のid
- action_id : 試合における各プレーのid
また、下記3つ変数については、socceraction.spadlにおいて各idに対するラベルが定義されています
- type_id
- result_id
- bodypart_id
def get_dict():
actiontypes= spadl.actiontypes_df()
results= spadl.results_df()
bodyparts= spadl.bodyparts_df()
actiontype_dict = dict(actiontypes.set_index('type_id')['type_name'])
result_dict = dict(results.set_index('result_id')['result_name'])
bodypart_dict = dict(bodyparts.set_index('bodypart_id')['bodypart_name'])
return actiontype_dict,result_dict,bodypart_dict
actiontype_dict,result_dict,bodypart_dict = get_dict()
print(f"- actiontype_dict:\n{actiontype_dict}\n")
print(f"- result_dict:\n{result_dict}\n")
print(f"- bodypart_dict:\n{bodypart_dict}\n")
- actiontype_dict:
{0: 'pass', 1: 'cross', 2: 'throw_in', 3: 'freekick_crossed', 4: 'freekick_short', 5: 'corner_crossed', 6: 'corner_short', 7: 'take_on', 8: 'foul', 9: 'tackle', 10: 'interception', 11: 'shot', 12: 'shot_penalty', 13: 'shot_freekick', 14: 'keeper_save', 15: 'keeper_claim', 16: 'keeper_punch', 17: 'keeper_pick_up', 18: 'clearance', 19: 'bad_touch', 20: 'non_action', 21: 'dribble', 22: 'goalkick'}
- result_dict:
{0: 'fail', 1: 'success', 2: 'offside', 3: 'owngoal', 4: 'yellow_card', 5: 'red_card'}
- bodypart_dict:
{0: 'foot', 1: 'head', 2: 'other'}
分析データセット作成
上記手順で取得したデータをまとめて、分析用のデータセットを作成いたします。
def create_dataset(df):
df['player'] = df['player_id'].map(player_dict)
df['team_name'] = df['team_id'].map(team_dict)
df['home_team_name'] = df['game_id'].map(home_team_dict)
df['type'] = df['type_id'].map(actiontype_dict)
df['result'] = df['result_id'].map(result_dict)
df['bodypart'] = df['bodypart_id'].map(bodypart_dict)
df = df.loc[df.period_id != 5,
['game_id','period_id','time_seconds','team_name','home_team_name','player','start_x','start_y','bodypart','type','result']]
return df
all_df = pd.DataFrame([])
for i in tqdm.tqdm(actions.keys()):
tmp = create_dataset(actions[i])
all_df = pd.concat([all_df,tmp],ignore_index=True)
作成したデータセットは下記のような形となります。
all_df[all_df['team_name']=="Japan"].head()
| game_id | period_id | time_seconds | team_name | home_team_name | player | start_x | start_y | bodypart | type | result | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 36365 | 7584 | 1 | 34.0 | Japan | Belgium | Hiroki Sakai | 28.235294 | 68.000000 | foot | throw_in | success |
| 36366 | 7584 | 1 | 35.0 | Japan | Belgium | Gaku Shibasaki | 22.058824 | 66.278481 | foot | dribble | success |
| 36367 | 7584 | 1 | 36.0 | Japan | Belgium | Gaku Shibasaki | 19.411765 | 66.278481 | foot | pass | fail |
| 36368 | 7584 | 1 | 37.0 | Japan | Belgium | Yūya Ōsako | 18.529412 | 65.417722 | foot | dribble | success |
| 36369 | 7584 | 1 | 38.0 | Japan | Belgium | Yūya Ōsako | 17.647059 | 59.392405 | foot | pass | success |
データの加工
プレー位置の補正
今回は作成したデータセットの中から、start_x,start_yを利用してLDAを行うのですが、
LDAを実施する前に、データの補正を実施します。
start_x,start_yは、以下の通り定義されています。
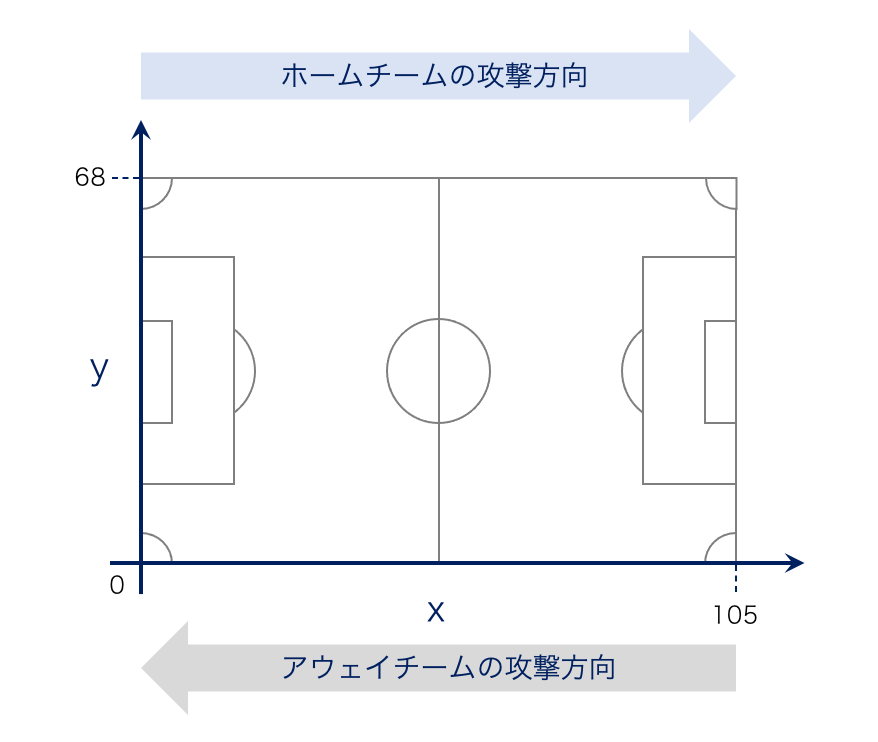
このとき、各チームがホームチームかアウェイチームであるかによって攻撃方向が変わってしまうため、同様のポジションであったとしても、start_x,start_yの座標が上下左右反転してしまっています。
参考として、日本代表の長友選手、川島選手のデータで確認してみます。
japan_df = all_df[(all_df.team_name=='Japan')].reset_index(drop = True)
# heatmap用に5m単位で丸める
japan_df['start_x_trim'] = (np.floor(japan_df['start_x']/5)*5).astype(int)
japan_df['start_y_trim'] = (np.floor(japan_df['start_y']/5)*5).astype(int)
日本代表がホームチームの場合は以下のようなヒートマップとなります。
plt.rc('figure',figsize=[12,4])
fig, axes = plt.subplots(nrows=1, ncols=2, sharex=False,sharey = False)
sns.heatmap(japan_df[(japan_df.home_team_name=='Japan')&(japan_df.player=='Yuto Nagatomo')].pivot_table(
index='start_y_trim',columns='start_x_trim',values = 'player',aggfunc = "count").sort_index(ascending = False),cmap = "RdPu",ax=axes[0])
axes[0].set_title('Yuto Nagatomo')
sns.heatmap(japan_df[(japan_df.home_team_name=='Japan')&(japan_df.player=='Eiji Kawashima')].pivot_table(
index='start_y_trim',columns='start_x_trim',values = 'player',aggfunc = "count").sort_index(ascending = False),cmap = "RdPu",ax=axes[1])
axes[1].set_title('Eiji Kawashima')
plt.tight_layout()

長友選手はピッチの上側、川島選手はピッチの左側でのプレーが多いことがわかります。
一方、日本代表がアウェイチームの場合は以下のようなヒートマップとなります。
plt.rc('figure',figsize=[12,4])
fig, axes = plt.subplots(nrows=1, ncols=2, sharex=False,sharey = False)
sns.heatmap(japan_df[(japan_df.home_team_name!='Japan')&(japan_df.player=='Yuto Nagatomo')].pivot_table(
index='start_y_trim',columns='start_x_trim',values = 'player',aggfunc = "count").sort_index(ascending = False),cmap = "RdPu",ax=axes[0])
axes[0].set_title('Yuto Nagatomo')
sns.heatmap(japan_df[(japan_df.home_team_name!='Japan')&(japan_df.player=='Eiji Kawashima')].pivot_table(
index='start_y_trim',columns='start_x_trim',values = 'player',aggfunc = "count").sort_index(ascending = False),cmap = "RdPu",ax=axes[1])
axes[1].set_title('Eiji Kawashima')
plt.tight_layout()

先ほどとは異なり、長友選手はピッチの下側、川島選手はピッチの右側でのプレーが多くなっていることがわかります。
そのため、今回は下記関数でstart_x,start_yの補正を実施し、ホームチームとアウェイチームの座標を揃えて分析を行いました。
def convert_away(df):
df.loc[df.team_name != df.home_team_name,'start_x'] = np.abs(df['start_x']-105)
df.loc[df.team_name != df.home_team_name,'start_y'] = np.abs(df['start_y']-68)
return df
all_df = convert_away(all_df)
5m×5mグリッドにおけるプレーデータを作成
次に、LDAで分析ができるようにstart_x,start_yを加工します。
今回は、5m×5m区切りでのプレー回数をつかってLDAを行うので、start_x,start_yを5m単位になるように丸めます。
def round_xy(df):
df['start_x'] = (np.floor(df['start_x']/5)*5).astype(int)
df['start_y'] = (np.floor(df['start_y']/5)*5).astype(int)
return df
all_df = round_xy(all_df)
また、丸められたstart_x,start_yを組み合わせて、5m×5m単位で区切られたグリッドにおけるプレーデータとします。
def merge_xy(df):
df['start_xy'] = df.apply(lambda x:(str(x['start_x'])+"_"+str(x['start_y'])),axis=1)
return df
all_df= merge_xy(all_df)
選手/試合毎にグリット毎のプレーデータを集計
続いて、各選手の1試合におけるグリッド毎のプレー回数を集計します。
all_df_pivot = all_df.pivot_table(index = ['team_name','player','game_id'],columns = 'start_xy',
values = 'period_id',aggfunc = 'count',fill_value=0)
all_df_pivot.head()
データとしては以下のような形となります。
| start_xy | 0_0 | 0_10 | 0_15 | 0_20 | 0_25 | 0_30 | 0_35 | 0_40 | 0_45 | 0_5 | ... | 95_25 | 95_30 | 95_35 | 95_40 | 95_45 | 95_5 | 95_50 | 95_55 | 95_60 | 95_65 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| team_name | player | game_id | |||||||||||||||||||||
| Argentina | Cristian Pavón | 7531 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 |
| 7545 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 7564 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ||
| 7580 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ||
| Eduardo Salvio | 7531 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
5 rows × 308 columns
LDA用のcorpus,dictionaryの作成
最後に、上記で作成したデータセットをLDAによる分析が可能な形式にします。
はじめに、5m単位のグリッド毎におけるプレー回数のデータをDense2Corpusを用いてcorpusに変換します。
また、LDAで使う辞書(各グリッド)も、Dictionaryで作成します。
X = np.array(all_df_pivot, dtype=np.int16)
corpus = gensim.matutils.Dense2Corpus(X.T)
vocab = list(all_df_pivot.columns)
dictionary = corpora.Dictionary([vocab])
これで分析の準備が整いました!
LDAの実施
今回はトピック数を11に設定して、LDAを実施しました。
topic_num = 11
LDA = models.LdaMulticore(corpus,num_topics=topic_num,id2word=dictionary,
iterations=100,
passes=20,
minimum_probability=0.01,
random_state = 42,
workers=32)
分析結果の確認
各トピックの特徴の確認
はじめに、各トピックに関する所属確率の高いプレーエリア上位5個を確認してみます。
def check_topic(LDA):
topic_tags = []
for topic in LDA.show_topics(num_topics=11,num_words=5,formatted=False):
topic_tags.append([tag[0] for tag in topic[1]])
topic_app = pd.DataFrame(topic_tags).T
topic_app.columns = [f"topic_{i:02}" for i in topic_app.columns ]
return topic_app
topic_app = check_topic(LDA)
topic_app
| topic_00 | topic_01 | topic_02 | topic_03 | topic_04 | topic_05 | topic_06 | topic_07 | topic_08 | topic_09 | topic_10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 55_65 | 80_0 | 75_30 | 45_45 | 55_45 | 45_30 | 55_20 | 55_0 | 75_55 | 0_30 | 45_20 |
| 1 | 45_65 | 80_10 | 80_20 | 30_45 | 50_45 | 35_30 | 45_20 | 45_0 | 75_50 | 5_30 | 30_20 |
| 2 | 75_65 | 75_0 | 80_30 | 35_45 | 55_55 | 45_35 | 55_15 | 60_0 | 80_50 | 0_35 | 30_15 |
| 3 | 65_65 | 85_10 | 75_20 | 30_50 | 45_45 | 45_40 | 60_20 | 65_0 | 80_60 | 5_35 | 35_15 |
| 4 | 60_65 | 85_0 | 70_30 | 25_45 | 45_50 | 35_35 | 45_15 | 75_0 | 75_60 | 10_30 | 35_20 |
少しこれではわかりづらいですね...
今度は、トピックの所属確率を毎にヒートマップを作って可視化してみます。
topic_df = pd.DataFrame([])
for i in range(topic_num):
tmp = pd.DataFrame(LDA.show_topic(i, topn=425),columns=['topic_vocab','prob'])
tmp['topic_id'] = i
topic_df = pd.concat([topic_df,tmp],ignore_index=True)
topic_df = topic_df[['topic_id','topic_vocab','prob']]
topic_df['topic_x'] = topic_df['topic_vocab'].apply(lambda x :x.split('_')[0])
topic_df['topic_y'] = topic_df['topic_vocab'].apply(lambda x :x.split('_')[1])
topic_df['topic_x'] = topic_df['topic_x'].astype(int)
topic_df['topic_y'] = topic_df['topic_y'].astype(int)
key_list = [
np.sort(topic_df['topic_id'].unique()),
np.sort(all_df['start_x'].unique()),
np.sort(all_df['start_y'].unique())
]
master_table = pd.DataFrame(
index = pd.MultiIndex.from_product(
key_list
)
).reset_index()
master_table.columns = ['topic_id','topic_x','topic_y']
topic_all = pd.merge(master_table,topic_df[['topic_id','topic_x','topic_y','prob']],how = 'left',on = ['topic_id','topic_x','topic_y'])
topic_all['prob'] = topic_all['prob'].fillna(0)
plt.rc('figure',figsize=[20,10])
fig, axes = plt.subplots(nrows=3, ncols=4, sharex=True,sharey = True)
for i in range(11):
sns.heatmap(topic_all[topic_all.topic_id==i].pivot_table(
index='topic_y',columns='topic_x',values = 'prob',aggfunc = "sum").sort_index(ascending = False),cmap = "RdPu",ax=axes[i//4,i%4])
axes[i//4,i%4].set_title(f'topic_{i}')
axes[2,3].axis("off")
plt.tight_layout()
ヒートマップにすることで、各トピックの特徴がわかりやすくなりました。
比較的、各ポジション毎にトピックが分類されているように見えます。
わかりやすい例で言えば、topic_09は自陣ゴール前でのエリアが多く、GKであることがわかるかと思います。
また、その他のトピックも前線-最終ライン&左サイド-右サイドという2つ組み合わせの中でポジションが分かれていることがわかると思います。
選手別のトピック所属傾向の確認
次に、各選手がどのようなトピックに属しているかを確認してみたいと思います。
tmps = []
for i in tqdm.tqdm(range(X.T.shape[1])):
Topic_prob = [l[1] for l in LDA.get_document_topics(gensim.matutils.dense2vec(X.T[:,i]),minimum_probability=0)]
tmps.append(Topic_prob)
df = pd.DataFrame(tmps)
df.index = all_df_pivot.index
df.columns = ['topic_{0:02d}'.format(l) for l in range(topic_num)]
df['top_topic'] = df.idxmax(axis=1)
参考として、日本代表選手の各試合における最も確率が高い所属トピックを確認してみます。
player_topic = df['top_topic'].reset_index()
player_topic_japan = player_topic[player_topic['team_name']=='Japan'].reset_index(drop = True)
plt.rc('figure',figsize=[12,5])
sns.heatmap(player_topic_japan.pivot_table(
index = 'player',columns = 'top_topic',values='game_id',aggfunc = 'count',fill_value= 0),cmap = "RdPu",annot=True)

各試合において同じトピック、つまり同じようなポジションでプレーしている方もいれば、試合毎にポジションが変わっている選手も見受けられます。
- GKの川島選手 : topic_09のみ
- SBの長友選手・酒井宏樹選手 : それぞれtopic_00,topic_07のみ(左サイド全体、右サイド全体)
- CBの吉田選手・昌子選手 : それぞれtopic_10,topic_03のみ
- FWの大迫選手 : topic_01,topic_02,topic_06の3つのトピック
こちらをみるとディフェンスの選手はプレーエリアは試合毎に大きく変化しないことがわかるのかなと思います。
一方、前線の選手については、各試合における所属トピックが異なる選手が多いという印象を感じました。
ここで参考として、大迫選手がどの試合でどのトピックに属しているのか確認してみたいと思います。
(大迫選手はコロンビア/セネガル/ベルギー戦はワントップ、ポーランド戦は2トップで出場されていました。)
player_topic_japan[player_topic_japan['player']=='Yūya Ōsako'].merge(
games[['game_id','home_team_name','away_team_name','home_score','away_score']])
| team_name | player | game_id | top_topic | home_team_name | away_team_name | home_score | away_score | |
|---|---|---|---|---|---|---|---|---|
| 0 | Japan | Yūya Ōsako | 7541 | topic_02 | Colombia | Japan | 1 | 2 |
| 1 | Japan | Yūya Ōsako | 7556 | topic_02 | Japan | Senegal | 2 | 2 |
| 2 | Japan | Yūya Ōsako | 7572 | topic_01 | Japan | Poland | 0 | 1 |
| 3 | Japan | Yūya Ōsako | 7584 | topic_06 | Belgium | Japan | 3 | 2 |
- コロンビア&セネガル戦とポーランド戦で所属トピックが異なるのは、出場したポジションの違いによるものが大きいのではないかと感じました。
- コロンビア&セネガル戦とベルギー戦では出場しているポジションが同じであるものの、異なるトピックとなりました。
- topic02に比べtopic06の方がプレーエリアが若干後ろ目であることから、同じワントップであるものの、引き気味にプレーしていたことが言えるのではないでしょうか。
- 理由としては、ボール支配率等や相手がどれだけ攻勢であったか等、様々な要因があるように感じます。
最後に
いかがでしたでしょうか。
この記事では、LDAを用いて、サッカー選手の1試合におけるプレーエリアからポジションを分類してみました。
今回はプレー開始位置のデータを使い分析を行いましたが、位置だけではなく、ドリブルやパス等のプレーの種類も分析に使うことで、選手のプレースタイルをより細分化できるのではないと感じています。
皆さんも是非試してみていただけると幸いです!
また、NTTドコモ R&D Advent Calendar 2020とNTTドコモ R&D 控え室 Advent Calendar 2020の他記事もどうぞお楽しみください!