こちらは、NTTドコモ サービスイノベーション部のADVENT CALENDERの18日目の記事となります。
こんにちは!NTTドコモの大杉です。
学生時代はサッカーとフットサルに費やし、現在はマーケティング関連のデータ分析業務を行っています。
本日は、socceractionというサッカーに関するpythonパッケージについて、2018年に開催されたFIFA W杯ロシア大会における試合データを分析しながらご紹介していきたいと思います。
はじめに
socceractionは、KDD2019 Appried Data Sciense TrackのBest Paper Awardを受賞した ”Actions Speak Louder than Goals: Valuing Player Actions in Soccer” [^1 ]で紹介されています。
[^1 ]: Decroos, Tom, et al. "Actions speak louder than goals: Valuing player actions in soccer." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2019.
この論文ではサッカー選手の試合中の行動を評価する新たな指標を提案しており、具体的には以下の内容となっています。
- 試合中の選手の行動を表す**SPADL(Soccer Player Action Description Language)**の定義
- 選手評価を行うフレームワークである**VAEP(Valuing Actions by Estimating Probabilities)**の定義
- 攻撃/守備時における得点/失点確率の予測
- 2012/2013~2017/2018のヨーロッパ主要リーグのデータを用いた分析による結果や考察
そして、socceractionについてなんですが、このパッケージを使うことで、以下のようなことができます。
- 試合データのSPADLへの変換
- 各アクションの攻撃/守備時における成功確率の算出
- 各アクションにおける成功確率を用いたVAEPの算出
つまり、socceractionによって、論文で述べられている分析手法を手軽に試すことができます。
また、githubで公開されているpublic-notebooksを参考に進めていくことで一連の分析を行うこともできます。
今回はこちらのpublic-notebookをベースにデータを触っていきたいと思います。
本記事の最後に、本記事で使用したコードを掲載していますので、皆様もぜひ一度試してみていただければと思います。
socceractionで実際に分析してみる
socceractionのインストールについては、以下のようにpipでインストールが可能です。
pip install socceraction
1. データをダウンロードする
1.1 今回使用するデータについて
論文中では、Wyscoutのデータが用いられていますが、socceractionのpublic-notebookでは、StatsBombからのデータ取得を行っています。socceractionでは、他にOptaのデータをSPADLに加工が可能です。
今回は、私もStatsBombのデータを利用します。
![]()
[画像引用元] : https://github.com/statsbomb/open-data/blob/master/README.md
StatsBombではオープンデータが公開1されており、2019年12月17日現在、下記大会のデータを公開しています。
- FIFA World Cup(2018)
- Women's World Cup(2019)
- La Liga(2004/2005~2015/2016)
- NWSL(2018)
- FA Women's Super League(2018/2019,2019/2020)
こうしてみるとLa Liga(リーガエスパニョーラ:スペイン)のデータが豊富にあることがわかると思います。
今回はこの中でも、日本代表も出場した2018年のロシアW杯のデータを利用して進めていきます。
1.2 データの取得方法について
1-download-statsbomb-data.ipynbにあるようにzipファイルを取得/展開することでデータは取得可能です。
今回はSPADLへの変換やVAEPの算出を正確に行うため、私も上記のnotebookを参考に取得しました。
ちなみに、StatsBombのデータを取得する別の方法として、statsbombというpythonパッケージを用いて取得する方法があります。
下記のコードで実際にStatsBombのデータを取得することもできます。
# https://pypi.org/project/statsbomb/
import statsbomb as sb
# Competitions
comps = sb.Competitions()
comps_df = comps.get_dataframe() # 大会一覧
# Matches(FIFA World Cup : competition_id(event_id) = 43, session_id = 3)
matches = sb.Matches(event_id='43', season_id='3')
matches_df = matches.get_dataframe() # 試合一覧
# Events(Japan VS Belgium : event_id = '7584')
# event_typeの詳細は下記リンク
# https://github.com/imrankhan17/statsbomb-parser/blob/master/statsbomb/events.yaml
events = sb.Events(event_id='7584')
events.get_dataframe(event_type='substitution') # 選手交代時のデータ
2. データをSPADLに変換する
2.1 SPADLの形式について
SPADL(Soccer Player Action Description Language)の形式は下記の通りとなっています。
- StartTime : 行動の開始時間
- EndTime : 行動の終了時間
- StartLoc : 行動開始時の位置情報
- EndLoc : 行動終了時の位置情報
- Player : 行動した選手
- Team : 選手の所属するチーム
- ActionType : 行動の種類(パス/シュート/ドリブル/インターセプト/スローイン等、21種類)
- BodyPart : 行動時の選手が使用した体の部位
- Result : 行動の結果(成功 or 失敗)
参考のnotebookでは、StatsBombのデータを上記のSPADLの形式に変更するコードが書かれており、これを参考にすることで簡単にSPADLに変換することができます。
ここでは、下記のような手順となります。
-
socceraction.spadl.api.statsbombjson_to_statsbombh5(statsbomb_json,statsbomb_h5)でStatsBombのJSONをHDF5形式のファイルにに変換 -
statsbombh5_to_spadlh5(statsbomb_h5,spadl_h5)でStatsBombのファイルをSPADLの形式に変換
また、matplotsoccer というpythonパッケージのmatplotsoccer.actionsを使うことで、SPADL形式にしたデータを以下のようにプロットすることができます。
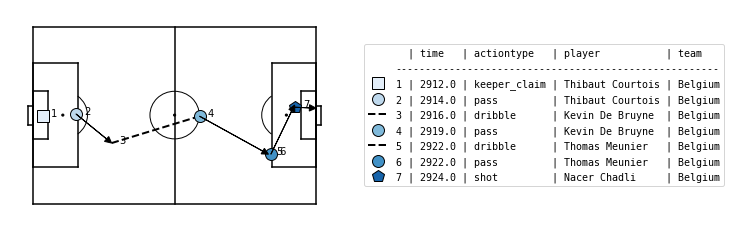
ここでは、日本のサッカーファンの皆さんならとても印象に残っているであろう、日本対ベルギー戦の1シーン^9 をプロットしてみました。
誰がいつ、どんなプレーをしているかが図と表でよくわかるかと思います。
3. モデルによる確率の予測
3.1 予測モデルの作成
次に、SPADLをもとに特徴量を作成し、攻撃/守備における得点/失点確率を求めます。
今回は1つ前までのプレーを特徴量に含めて予測モデルを作成してみました。
使用した特徴量は下記の通りです。これが直近のプレーと1つ前のプレーのそれぞれ2種類あります。
- actiontype(onehot)
- bodypart(onehot)
- result
- goalscore
- startlocation
- endlocation
- movement
- space_delta
- startpolar
- endpolar
- team
- time_delta
この特徴量と、目的変数については、socceraction.classification.featuresと、socceraction.classification.labelsを使うことで導出できます。
これら特徴量を用いてxgboostで予測モデルを実行し、予測精度を確認しました。
すると、今回作成した予測モデルの予測精度は以下のようになりました。
| Scores | Concedes | |
|---|---|---|
| brier_score_loss | 0.0092 | 0.0025 |
| AUC | 0.8512 | 0.8865 |
3.2 SHAPによる重要特徴量の確認
また、SHAP[^5 ] [^6 ]を用いて、特徴量がどのように予測モデルに寄与しているかを確認しました。
得点確率に寄与する特徴量をsummary_plotで見てみます。
[^5 ]: Lundberg, Scott M., and Su-In Lee. "A unified approach to interpreting model predictions." Advances in Neural Information Processing Systems. 2017.
[^6 ]: Lundberg, Scott M., et al. "Explainable AI for Trees: From Local Explanations to Global Understanding." arXiv preprint arXiv:1905.04610 (2019).
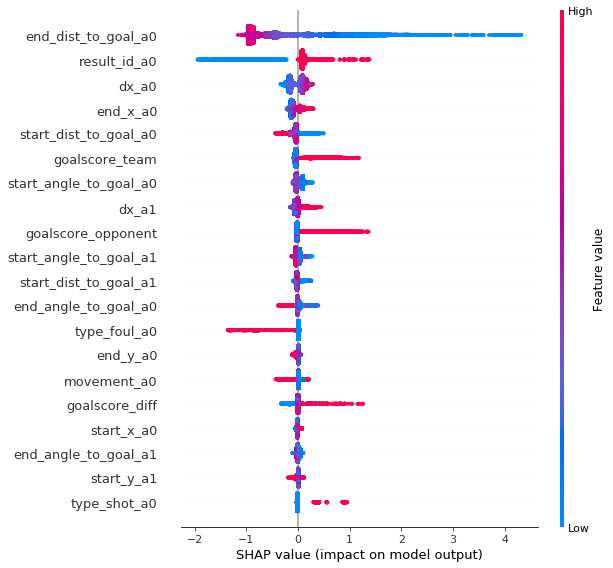
SHAPによって、特徴量が目的変数にどのような影響を与えるのかをで視覚的に確認することができます。
また、気になる変数があった場合に、各変数について詳しく見ることも可能です。
以下のdependence_plotでは、アクション時のゴールへの距離が得点確率にどのように寄与しているかを見ています。
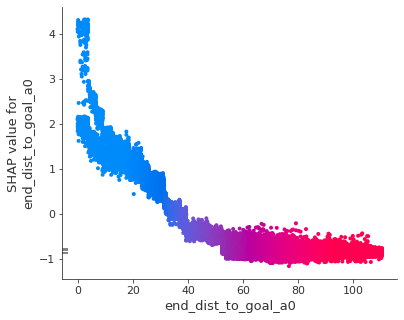
横軸がアクションが終了した際のゴールからの距離、縦軸がSHAP値となっているため、ここではアクション後の距離が短いほど得点確率が高くなるという傾向がここではわかります。
4. VAEPの算出
3で算出された、予測モデルによる得点確率/失点確率を元に、VAEP(Valuing Actions by Estimating Probabilities)を算出していきます。
チーム$x$のアクション$a_i$におけるVAEPは以下のように算出されます。
V(a_i,x) = \Delta P_{scores}(a_i,x) + (- \Delta P_{concedes}(a_i,x))
このとき、
$\Delta P_{scores}(a_i,x)$はアクションによる得点確率の増加分を意味し、$\Delta P_{concedes}(a_i,x)$はアクションによる失点確率の増加分を意味しています。
つまり、①得点確率を上げて、②失点確率を下げるアクションの場合、VAEPが高くなります。
socceractionを使って実際にVAEPを算出します。
ここでは、socceraction.vaep.value()を使うことで算出することができます。
VAEPの合計が高い順に並べた結果、以下のような結果となりました。
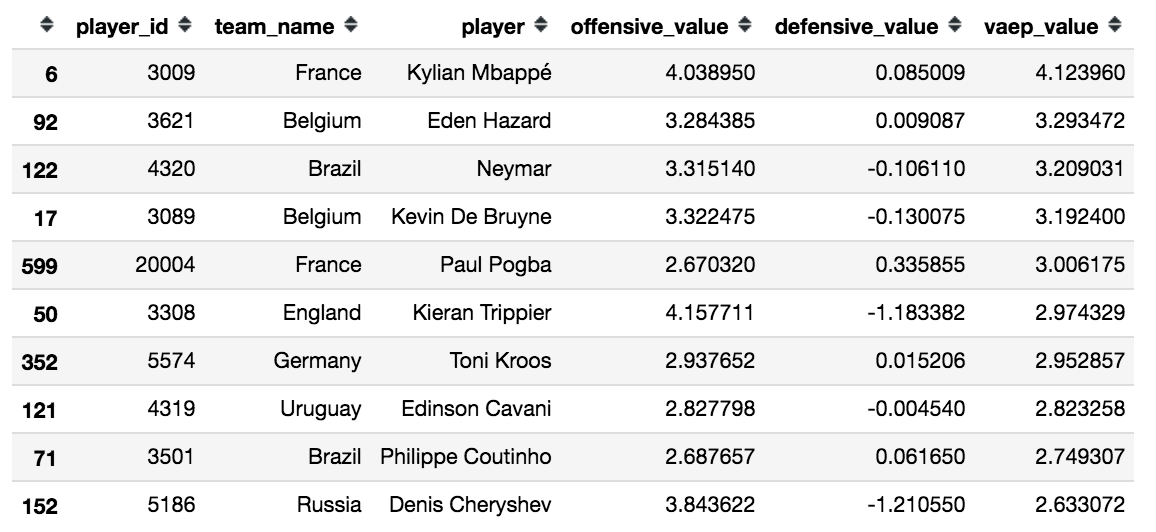
優勝したフランス代表のエムバペ選手がVAEPの合計が最も高いという結果となりました。
上ではVAEPの合計で出してみましたが、この結果だけではプレイ時間が考慮されていません。
そこで、論文で実施されているようにプレイ時間で平均をとり、90分間あたりのVAEPを算出します。
また、条件として、180分以上出場した選手のみに絞り込みを行なっています。
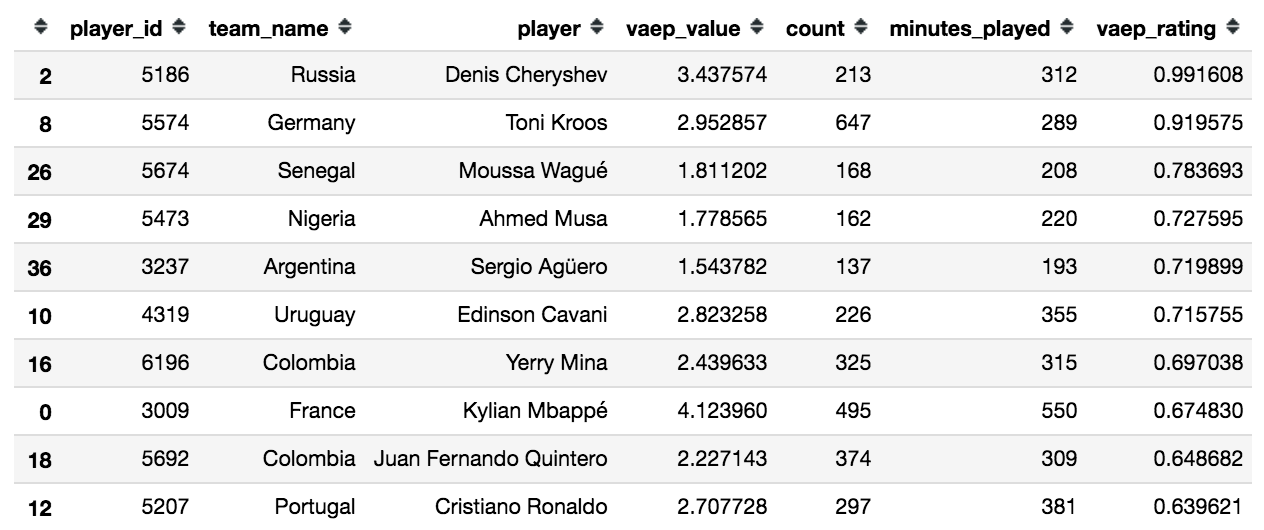
90分あたりのVAEPで見てみると、ロシア代表のデニス・チェリシェフ選手が1位となりました。
チェリシェフ選手は5試合中4得点を決める活躍だったのですが、途中出場や途中交代が多かったため、
90分あたりのVAEPをみることにより、1位まで順位が上がったのではないかと考えられます。
また、本大会ではグループリーグ敗退となってしまった、ドイツ代表のトニ・クロース選手が上位にランクインしているという点も興味深い結果となりました。
この他にも1プレイあたりの平均VAEPを出すことで、プレイ回数は少ないがいい仕事をするプレーヤー等が抽出できるかもしれません。
5. シーン毎の結果の可視化
先ほど紹介した、matplotsoccerによるプロットに、算出したVAEPを加えてみます。
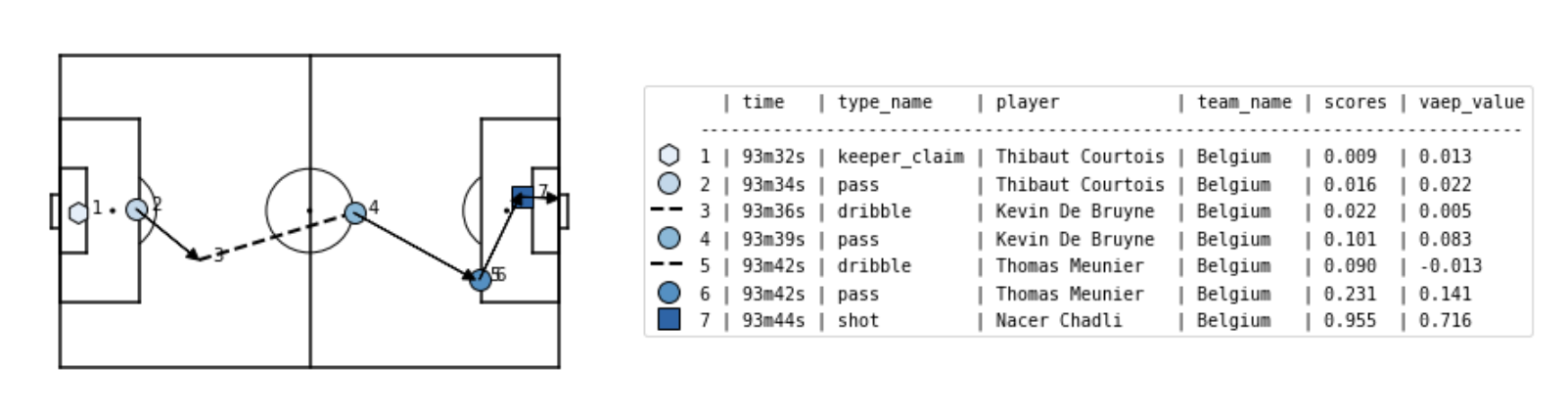
これによって、対象シーンにおける各選手の行動を数値化して評価することができます。
この図を見てみると、シュートとアシスト以外では、デブルイネ選手のパスが最も高く評価されています。
まとめ
今回は、socceractionについて、2018年に開催されたサッカーW杯ロシア大会の実際のデータを使ってご紹介しました。
率直な感想としては、StatsBombやWyscout等、複数のデータソースをSPADLに変換できるという点が非常に便利だなと感じました。
また、StatsBombのデータは非常に細かく、これを使うことで、様々な分析ができるのではないかと感じました。(無料で使用できるのがありがたい...)
socceractionのgithubにあるpublic-notebookについても、HDF5形式でのデータ処理等がされていて、普段はあまり使用しないので勉強になりました。
そしてなにより、実際の試合のデータをこのように分析できるのは非常に面白いなと感じました!
私のように、スポーツおよびサッカーの分析に興味のある方は是非socceractionを試して見ていただければと思います。
参考:今回使用したコード
1.データ取得&得点シーンの可視化
# ----
# 参考にしたpublic-notebookのMIT license
# (c) 2019 KU Leuven Machine Learning Research Group
# Released under the MIT license.
# see https://github.com/ML-KULeuven/socceraction/blob/master/LICENSE
# ----
# package
%load_ext autoreload
%autoreload 2
import os; import sys;
import tqdm
import requests
import math
import zipfile
import warnings
import pandas as pd
warnings.simplefilter(action='ignore', category=pd.errors.PerformanceWarning)
import socceraction.spadl.api as spadl
import matplotsoccer
import matplotlib
# フォルダ名/ファイル名の指定
datafolder = "hogehoge" #フォルダ名を指定
statsbombzip = os.path.join(datafolder, "open-data-master.zip")
statsbombroot = os.path.join(datafolder, "statsbomb-root")
statsbombdata = os.path.join(datafolder, "statsbomb-root", "open-data-master", "data")
# zipファイルの展開
with zipfile.ZipFile(statsbombzip, 'r') as zipObj:
zipObj.extractall(statsbombroot)
# StatsBomb(json)のデータをSPADL(HDF5)に変換する
## StatsBomb(Raw Data) : json -> StatsBomb(Raw Data) : h5
statsbomb_json = os.path.join(datafolder,"statsbomb-root","open-data-master","data")
statsbomb_h5 = os.path.join(datafolder,"statsbomb.h5")
spadl_h5 = os.path.join(datafolder,"spadl-statsbomb.h5")
spadl.statsbombjson_to_statsbombh5(statsbomb_json,statsbomb_h5)
tablenames = ["matches","players","teams","competitions"]
tables = {name : pd.read_hdf(statsbomb_h5,key=name) for name in tablenames}
match_id = tables["matches"].match_id[0]
tables["events"] = pd.read_hdf(statsbomb_h5,f"events/match_{match_id}")
for k,df in tables.items():
print("#",k)
print(df.columns,"\n")
## StatsBomb(Raw Data) : h5 -> SPADL : h5
spadl.statsbombh5_to_spadlh5(statsbomb_h5,spadl_h5)
tablenames = ["games","players","teams","competitions","actiontypes","bodyparts","results"]
tables = {name : pd.read_hdf(spadl_h5,key=name) for name in tablenames}
game_id = tables["games"].game_id[0]
tables["actions"] = pd.read_hdf(spadl_h5,f"actions/game_{game_id}")
for k,df in tables.items():
print("#",k)
print(df.columns,"\n")
# FIFA W杯:日本対ベルギーの試合を可視化
## game_idの抽出
tablenames = ["games","players","teams","competitions","actiontypes","bodyparts","results"]
tables = {name: pd.read_hdf(spadl_h5, key=name) for name in tablenames}
games = tables["games"].merge(tables["competitions"])
game_id = games[(games.competition_name == "FIFA World Cup")
& (games.away_team_name == "Japan")
& (games.home_team_name == "Belgium")].game_id.values[0]
game_id # 7584
## 得点に関係するaction_idの抽出
actions = pd.read_hdf(spadl_h5, f"actions/game_{game_id}")
actions = (
actions.merge(tables["actiontypes"])
.merge(tables["results"])
.merge(tables["bodyparts"])
.merge(tables["players"],"left",on="player_id")
.merge(tables["teams"],"left",on="team_id")
.sort_values(["period_id", "time_seconds", "timestamp"])
.reset_index(drop=True))
actions["player"] = actions[["player_nickname",
"player_name"]].apply(lambda x: x[0] if x[0] else x[1],axis=1)
list(actions[(actions.type_name=='shot')&(actions.result_name=='success')].index)
# [1215, 1334, 1658, 1742, 2153]
## ベルギー3点目
shot = 2153
a = actions[shot-8:shot+1]
games = tables["games"]
g = list(games[games.game_id == a.game_id.values[0]].itertuples())[0]
minute = int((a.period_id.values[0]-1)*45 +a.time_seconds.values[0] // 60) + 1
game_info = f"{g.match_date} {g.home_team_name} {g.home_score}-{g.away_score} {g.away_team_name} {minute}'"
print(game_info)
labels = a[["time_seconds", "type_name", "player", "team_name"]]
matplotsoccer.actions(
location=a[["start_x", "start_y", "end_x", "end_y"]],
action_type=a.type_name,
team= a.team_name,
result= a.result_name == "success",
label=labels,
labeltitle=["time","actiontype","player","team"],
zoom=False,
figsize=6)
2.特徴量の作成,予測モデル作成,SHAP算出
# ----
# 参考にしたpublic-notebookのMIT license
# (c) 2019 KU Leuven Machine Learning Research Group
# Released under the MIT license.
# see https://github.com/ML-KULeuven/socceraction/blob/master/LICENSE
# ----
# package
%load_ext autoreload
%autoreload 2
import os; import sys; sys.path.insert(0,'hogehoge')#フォルダ名
import pandas as pd
import tqdm
import warnings
warnings.simplefilter(action='ignore', category=pd.errors.PerformanceWarning)
import socceraction.classification.features as fs
import socceraction.classification.labels as lab
import xgboost
from sklearn.metrics import roc_auc_score,brier_score_loss
import shap
shap.initjs()
# ファイル名とフォルダ名の定義
datafolder = "hogehoge" #フォルダ名を指定
spadl_h5 = os.path.join(datafolder,"spadl-statsbomb.h5")
features_h5 = os.path.join(datafolder,"features.h5")
labels_h5 = os.path.join(datafolder,"labels.h5")
predictions_h5 = os.path.join(datafolder,"predictions.h5")
# データ読込
games = pd.read_hdf(spadl_h5,"games")
games = games[games.competition_name == "FIFA World Cup"]
print("nb of games:", len(games))
actiontypes = pd.read_hdf(spadl_h5, "actiontypes")
bodyparts = pd.read_hdf(spadl_h5, "bodyparts")
results = pd.read_hdf(spadl_h5, "results")
# ラベルの作成
yfns = [lab.scores,lab.concedes,lab.goal_from_shot]
for game in tqdm.tqdm(list(games.itertuples()),
desc=f"Computing and storing labels in {labels_h5}"):
actions = pd.read_hdf(spadl_h5,f"actions/game_{game.game_id}")
actions = (
actions.merge(actiontypes,how="left")
.merge(results,how="left")
.merge(bodyparts,how="left")
.sort_values(["period_id", "time_seconds", "timestamp",'action_id'])
.reset_index(drop=True))
Y = pd.concat([fn(actions) for fn in yfns],axis=1)
Y.to_hdf(labels_h5,f"game_{game.game_id}")
# 特徴量の作成
xfns = [fs.actiontype,
fs.actiontype_onehot,
fs.bodypart,
fs.bodypart_onehot,
fs.result,
fs.result_onehot,
fs.goalscore,
fs.startlocation,
fs.endlocation,
fs.movement,
fs.space_delta,
fs.startpolar,
fs.endpolar,
fs.team,
fs.time,
fs.time_delta]
for game in tqdm.tqdm(list(games.itertuples()),
desc=f"Generating and storing features in {features_h5}"):
actions = pd.read_hdf(spadl_h5,f"actions/game_{game.game_id}")
actions = (
actions.merge(actiontypes,how="left")
.merge(results,how="left")
.merge(bodyparts,how="left")
.sort_values(["period_id", "time_seconds", "timestamp",'action_id'])
.reset_index(drop=True))
gamestates = fs.gamestates(actions,2)
gamestates = fs.play_left_to_right(gamestates,game.home_team_id)
X = pd.concat([fn(gamestates) for fn in xfns],axis=1)
X.to_hdf(features_h5,f"game_{game.game_id}")
xfns = [fs.actiontype_onehot,
fs.bodypart_onehot,
fs.result,
fs.goalscore,
fs.startlocation,
fs.endlocation,
fs.movement,
fs.space_delta,
fs.startpolar,
fs.endpolar,
fs.team,
fs.time_delta]
nb_prev_actions = 2
Xcols = fs.feature_column_names(xfns,nb_prev_actions)
X = []
for game_id in tqdm.tqdm(games.game_id,desc="selecting features"):
Xi = pd.read_hdf(features_h5,f"game_{game_id}")
X.append(Xi[Xcols])
X = pd.concat(X)
Ycols = ["scores","concedes"]
Y = []
for game_id in tqdm.tqdm(games.game_id,desc="selecting label"):
Yi = pd.read_hdf(labels_h5,f"game_{game_id}")
Y.append(Yi[Ycols])
Y = pd.concat(Y)
print("X:", list(X.columns))
print("Y:", list(Y.columns))
# xgboostによる予測モデル構築
%%time
# scores
model_scores = xgboost.XGBClassifier()
model_scores.fit(X,Y['scores'])
# concedes
model_concedes = xgboost.XGBClassifier()
model_concedes.fit(X,Y['concedes'])
Y_hat = pd.DataFrame()
Y_hat['scores'] = model_scores.predict_proba(X)[:,1]
Y_hat['concedes'] = model_concedes.predict_proba(X)[:,1]
# 予測精度
print(f"scores_brier : \t\t{brier_score_loss(Y['scores'],Y_hat['scores']).round(4)}")
print(f"concedes_brier : \t{brier_score_loss(Y['concedes'],Y_hat['concedes']).round(4)}")
print(f"scores_auc : \t\t{roc_auc_score(Y['scores'],Y_hat['scores']).round(4)}")
print(f"concedes_auc : \t{roc_auc_score(Y['concedes'],Y_hat['concedes']).round(4)}")
# SHAPを用いた予兆要因の特定(scores)
explainer_scores = shap.TreeExplainer(model_scores)
shap_scores = explainer_scores.shap_values(X)
## summary_plot
shap.summary_plot(shap_scores,features=X,feature_names=X.columns)
## dependence_plot
shap.dependence_plot('end_dist_to_goal_a0',
shap_scores,
features=X,
feature_names=X.columns,
interaction_index='end_dist_to_goal_a0')
# 予測結果の保存
A = []
for game_id in tqdm.tqdm(games.game_id,"loading game ids"):
Ai = pd.read_hdf(spadl_h5,f"actions/game_{game_id}")
A.append(Ai[["game_id"]])
A = pd.concat(A)
A = A.reset_index(drop=True)
grouped_predictions = pd.concat([A,Y_hat],axis=1).groupby("game_id")
for k,df in tqdm.tqdm(grouped_predictions,desc="saving predictions per game"):
df = df.reset_index(drop=True)
df[Y_hat.columns].to_hdf(predictions_h5,f"game_{int(k)}")
3.VAEPの算出
# ----
# 参考にしたpublic-notebookのMIT license
# (c) 2019 KU Leuven Machine Learning Research Group
# Released under the MIT license.
# see https://github.com/ML-KULeuven/socceraction/blob/master/LICENSE
# ----
# package
%load_ext autoreload
%autoreload 2
import os; import sys; sys.path.insert(0,'hogehoge') #フォルダ名
import pandas as pd
import tqdm
import warnings
warnings.simplefilter(action='ignore', category=pd.errors.PerformanceWarning)
import socceraction.vaep as vaep
import matplotsoccer
import matplotlib
# ファイル名とフォルダ名の定義
datafolder = "hogehoge" #フォルダ名
spadl_h5 = os.path.join(datafolder,"spadl-statsbomb.h5")
predictions_h5 = os.path.join(datafolder,"predictions.h5")
# データの取得
games = pd.read_hdf(spadl_h5,"games")
games = games[games.competition_name == "FIFA World Cup"]
print("nb of games:", len(games))
players = pd.read_hdf(spadl_h5,"players")
teams = pd.read_hdf(spadl_h5,"teams")
actiontypes = pd.read_hdf(spadl_h5, "actiontypes")
bodyparts = pd.read_hdf(spadl_h5, "bodyparts")
results = pd.read_hdf(spadl_h5, "results")
# VAEPの算出
A = []
for game in tqdm.tqdm(list(games.itertuples())):
actions = pd.read_hdf(spadl_h5,f"actions/game_{game.game_id}")
actions = (
actions.merge(actiontypes)
.merge(results)
.merge(bodyparts)
.merge(players,"left",on="player_id")
.merge(teams,"left",on="team_id")
.sort_values(["period_id", "time_seconds", "timestamp"])
.reset_index(drop=True)
)
preds = pd.read_hdf(predictions_h5,f"game_{game.game_id}")
values = vaep.value(actions,preds.scores,preds.concedes)
A.append(pd.concat([actions,preds,values],axis=1))
A = pd.concat(A).sort_values(["game_id","period_id", "time_seconds", "timestamp"]).reset_index(drop=True)
A.columns
A["player"] = A[["player_nickname",
"player_name"]].apply(lambda x: x[0] if x[0] else x[1],axis=1)
# 各プレーヤーのVAEPの合計を算出し、降順で確認
summary = A.groupby(['player',
'team_name',
'player'])[['offensive_value',
'defensive_value',
'vaep_value']].sum().reset_index()
summary.sort_values('vaep_value',ascending = False).head(10)
# 90分あたりの平均VAEPを算出し、降順で確認
players = A_[["player_id",
"team_name",
"player",
"vaep_value",
"count"]].groupby(["player_id",
"team_name",
"player"]).sum().reset_index()
players = players.sort_values("vaep_value",ascending=False)
pg = pd.read_hdf(spadl_h5,"player_games")
pg = pg[pg.game_id.isin(games.game_id)]
mp = pg[["player_id","minutes_played"]].groupby("player_id").sum().reset_index()
stats = players.merge(mp)
stats = stats[stats.minutes_played > 180]
stats["vaep_rating"] = stats.vaep_value * 90 / stats.minutes_played
stats.sort_values("vaep_rating",ascending=False).head(10)
# matplotsoccerによる可視化
## ゴールが入った場面の抽出
shot_goal_index = A[(A.game_id == 7584)&A.type_name.str.contains("shot")&(A.result_name=='success')]
## ベルギー3点目の可視化
def get_time(period_id,time_seconds):
m = int((period_id-1)*45 + time_seconds // 60)
s = time_seconds % 60
if s == int(s):
s = int(s)
return f"{m}m{s}s"
### 場面の抽出
a = A.iloc[shot_goal_index.index[4]-6:shot_goal_index.index[4]+1,:].sort_values('action_id')
a["player"] = a[["player_nickname",
"player_name"]].apply(lambda x: x[0] if x[0] else x[1],axis=1)
### 試合情報
g = list(games[games.game_id == a.game_id.values[0]].itertuples())[0]
game_info = f"{g.match_date} {g.home_team_name} {g.home_score}-{g.away_score} {g.away_team_name}"
minute = get_time(int(a[a.index == a.index[-1]].period_id),int(a[a.index == a.index[-1]].time_seconds))
print(f"{game_info} {minute}' {a[a.index == a.index[-1]].type_name.values[0]} {a[a.index == a.index[-1]].player_name.values[0]}")
### データ整形
a["scores"] = a.scores.apply(lambda x : "%.3f" % x )
a["vaep_value"] = a.vaep_value.apply(lambda x : "%.3f" % x )
a["time"] = a[["period_id","time_seconds"]].apply(lambda x: get_time(*x),axis=1)
cols = ["time","type_name","player","team_name","scores","vaep_value"]
### プロット
matplotsoccer.actions(a[["start_x","start_y","end_x","end_y"]],
a.type_name,
team=a.team_name,
result = a.result_name == "success",
label=a[cols],
labeltitle = cols,
zoom=False)