最近トピックモデルに興味をもち、『自然言語処理シリーズ トピックモデルによる統計的潜在意味解析』を読んで勉強しています。2章まで読み、トピックモデルに使われるLDAの概要を理解した(つもりだけかもしれません汗)ので、例のごとくメモがわりに漫画風にまとめました。
漫画を描くつらさがだんだんわかってきましたが(笑)、時間をかけるぶんだけ頭にちゃんと入ってくるので、頑張ってこれからも続けていきたいと思います。
本の内容的には3章から各学習アルゴリズム(ギブスサンプリングとか、逐次ベイズとか)の説明になるので、こちらもちゃんと理解できたらわかりやすい形でまとめたいですが、ほとんど数式なのでこれをどう表現するか、エセ漫画家としての血が騒ぎます...
漫画でわかるトピックモデル(LDA, Latent Dirichlet Allocation)
トピックモデルはその名の通り、文章のトピックを分析するための手法です。

LDAでは文書の背後に1つのトピックのみが存在していると考えるのではなく、もともと複数のトピックが存在しており、文書ごとに各トピックの出現確率が変化する、という考え方に近い。
そして、ここでの「文書」とはBoW(Bag of Words)であり、単語の順番は考慮しないことを想定。
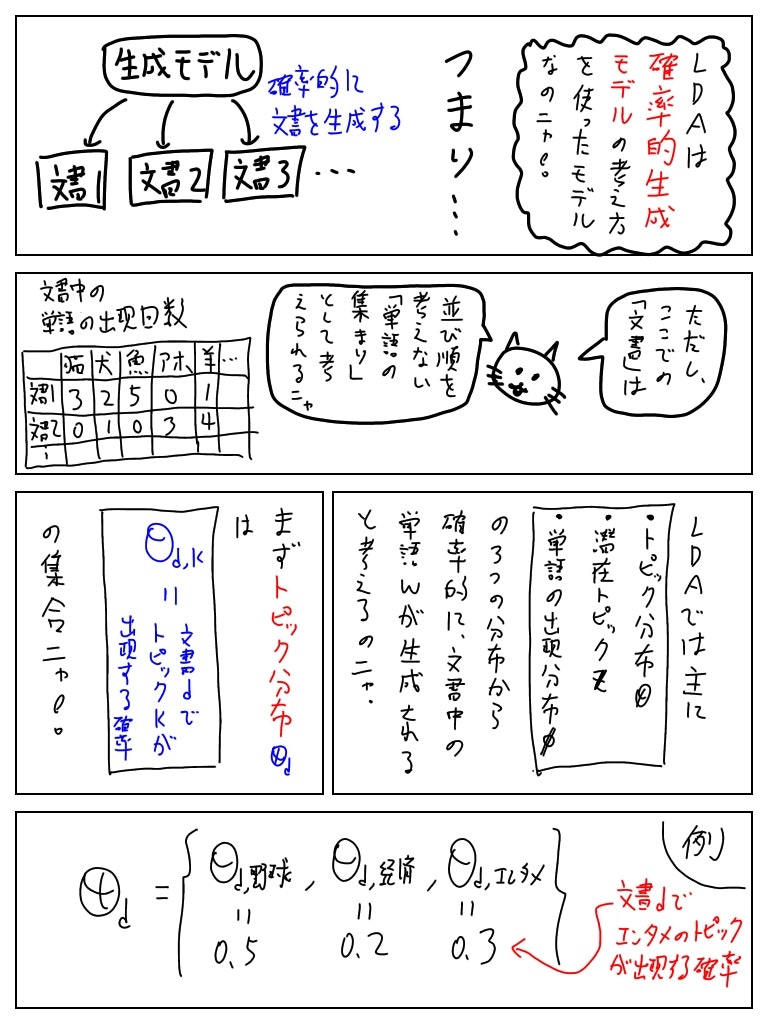
ここを勘違いしていたせいで理解するのが遅くなったのですが、「潜在トピックはその文書の単語の数だけ存在する」のだ!
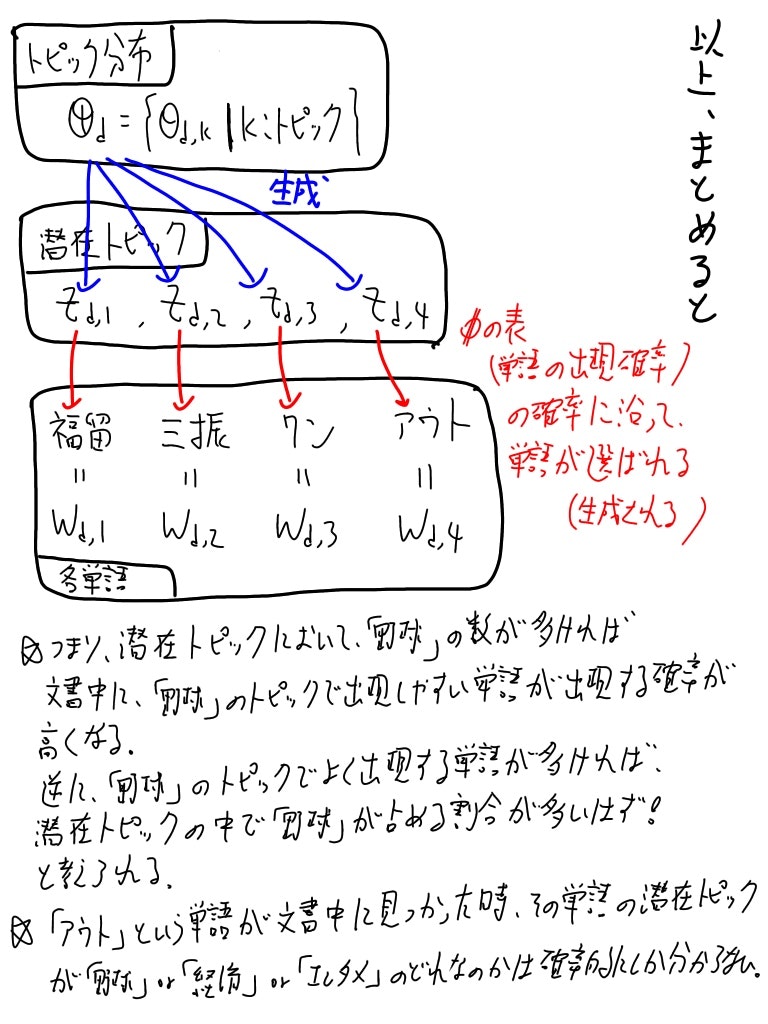
各潜在トピックはトピック分布θをパラメータにもつ多項分布から生成されると仮定する。
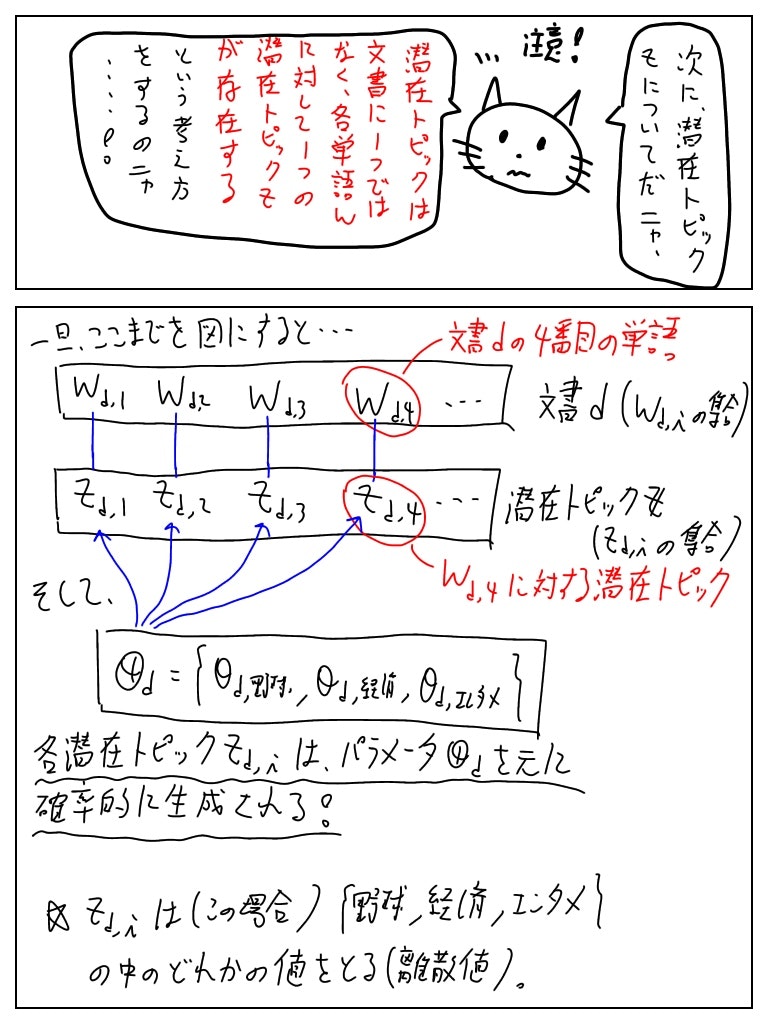
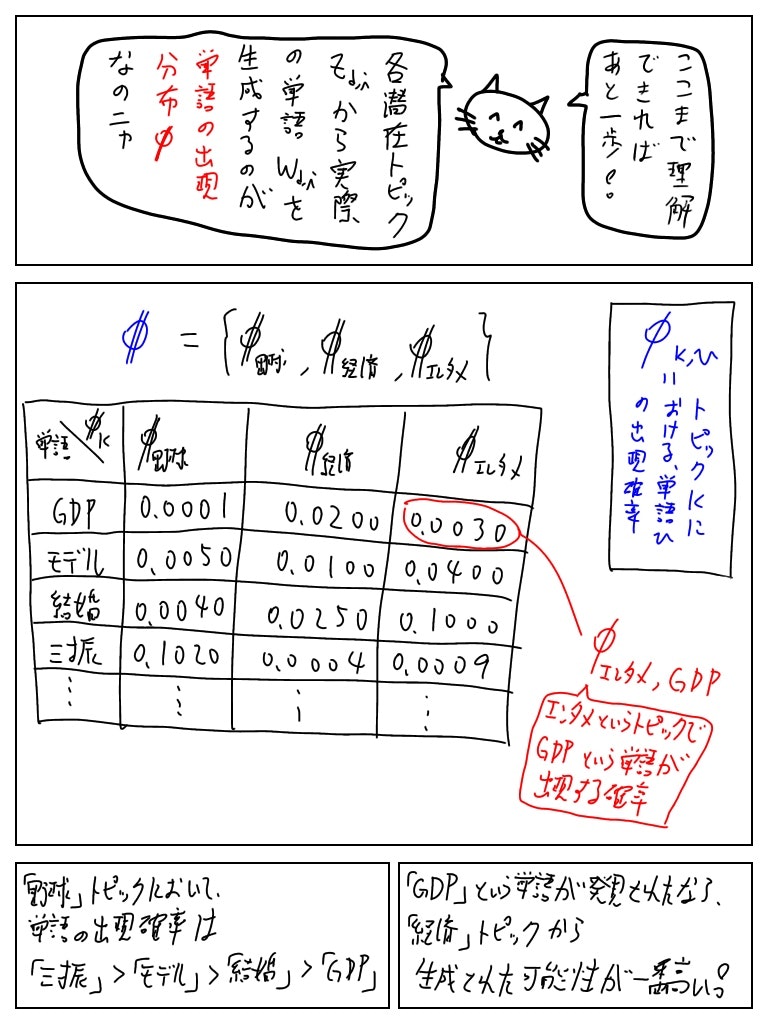
トピック分布・潜在トピックとは独立に、単語の出現分布φを想定する。
これは各トピックにおいてどのような単語が出現(生成)されやすいかのデータ表だと思えば良い。
各単語はφ_z(潜在トピックzにおける各単語の出現確率)をパラメータとする多項分布から生成されると仮定する。
漫画の中では説明しませんでしたが、トピック分布θと単語の出現分布φもそれぞれα(K(=トピック数)次元ベクター),β(V(=全単語数)次元ベクター)をパラメータにもつディリクレ分布から生成されると仮定します。
終わりに
時間があれば多項分布・ディリクレ分布、あと本の中で解説されていたLDAの幾何学的解釈もまとめたい...
最初にすごくざっくりと理解したい人向けに書いたものなので、正確でない記述など見つかりましたら教えていただけるとありがたいです!
あと、「これを漫画で理解したい」っていう要望があれば教えてください。
個人的には、VAEとかGANについて要点だけ理解したいです