はじめに
Source Target Attentionを前回整理したので、これを前提に次はSelf-Attentionを整理してみます。前回分はこちらです↓ので、見ていただけると嬉しいです。
「Attentionを理解するためにRNN、Word2Vec、LSTM、Seq2Seq、Attentionの順に整理してみた」https://qiita.com/ta2bonn/items/c645ecbcf9dabd0c4778
参考元
Self-Attentionを整理するに当たり、こちらのサイトを参考にさせていただきました。
https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a
Self-Attentionとは
まずそもそも何者?から入ります。Source Target Attentionはエンコーダーとデコーダー(inputとmemory)を使用していましたが、Self-Attentionでは自Layer内で全てを完結することで計算を高速化するというものです(input=memory)。また、並列計算によって出力をより複雑に表現できます。文章だと本当に意味が分からないですよね。これをがんばって整理してみます。
Source Target Attention との比較
Source Target AttentionとSelf-Attentionを超ざっくり比較すると↓のとおりです。Source Targetではinputとmemoryを使っていましたが、selfではinputだけです。
またkey、valueはmemoryの代わりにinput全ての単語を使用します。
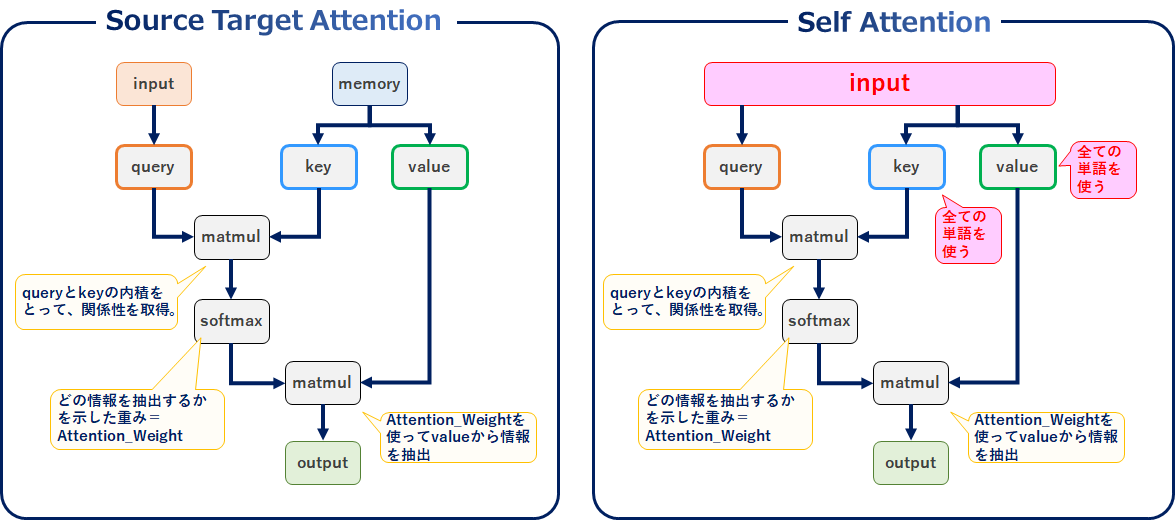
Self-Attentionのレイヤ
全体レイヤ
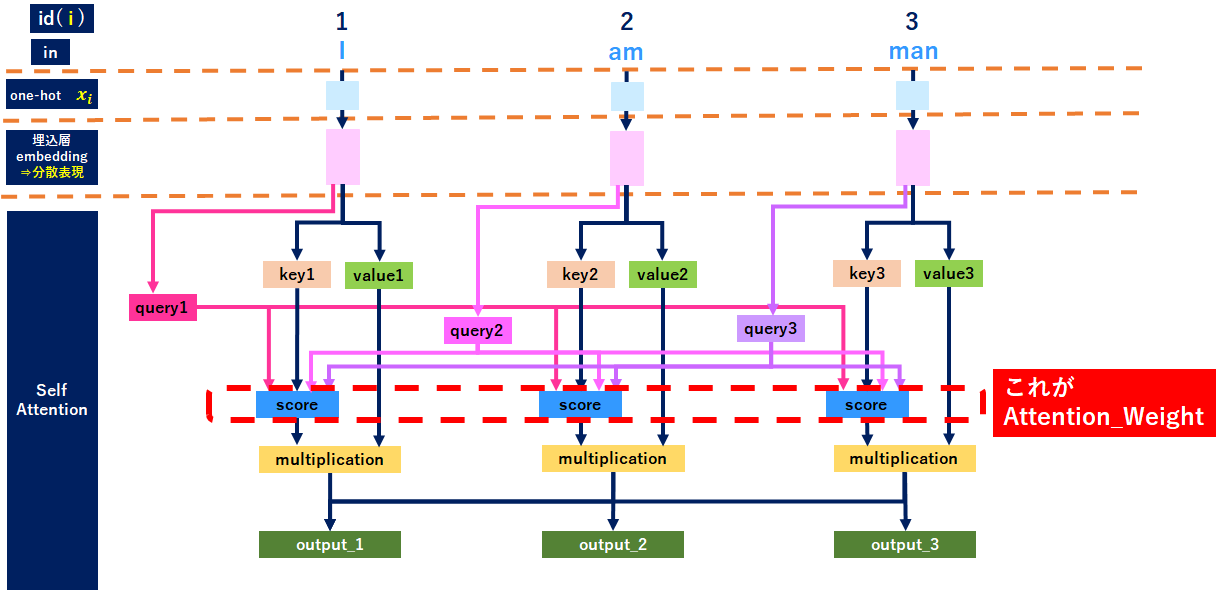
もう絵を見ても何のことやら分からないと思うのですが、順番に整理します。
まずインプット文章を「I am man」とします。「何だその文章?」と思われるかもしれませんが、3単語が絵にする限界だったので適当に文章を作っています。ご容赦いただければ幸いです。また、one-hotから分散表現の獲得までは省略します(気になる方は前回投稿を参照くださいhttps://qiita.com/ta2bonn/items/c645ecbcf9dabd0c4778 )。
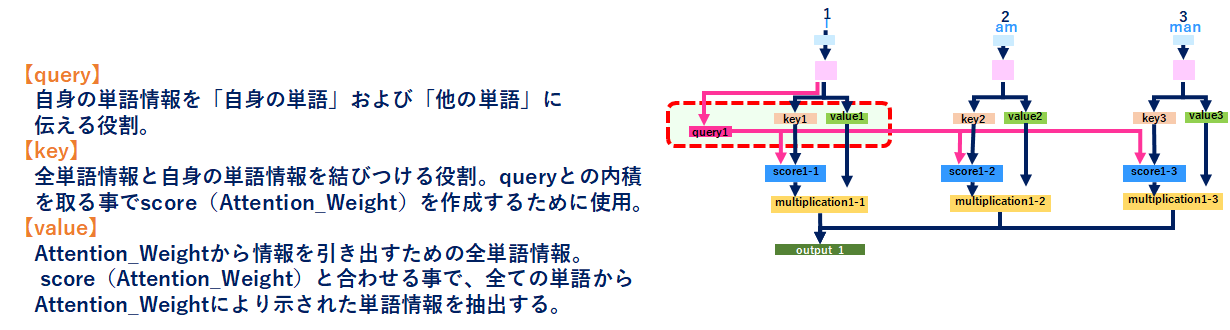
Self-Attentionのレイヤを見ると、それぞれの単語から「query、key、value」が作成されていますので、説明はココから始めるとして、以降「I」の単語を使って説明します。
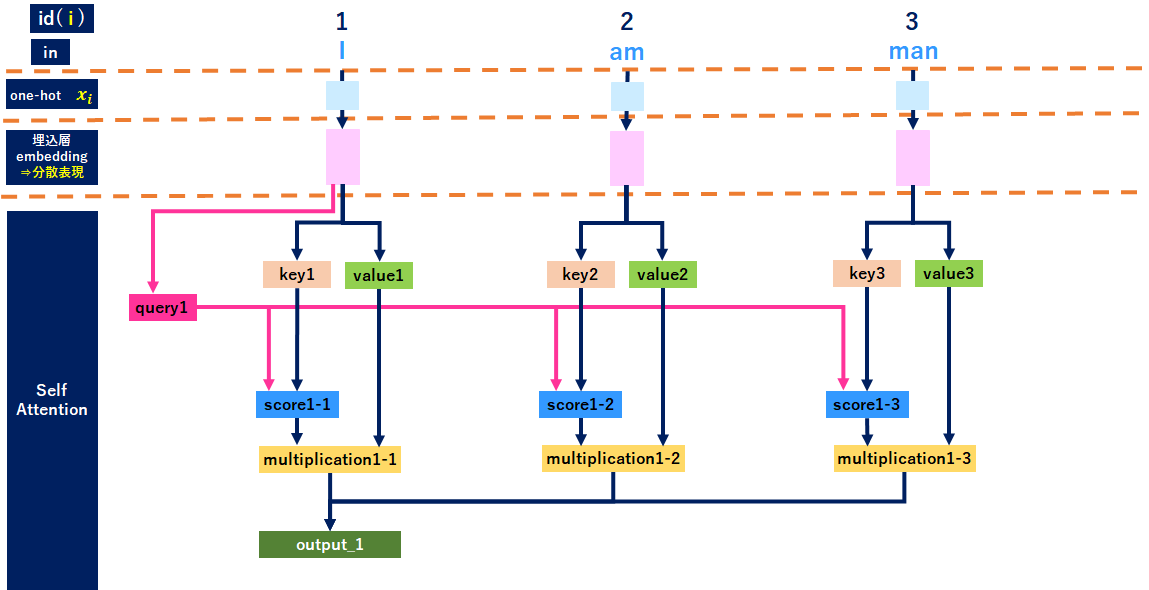
最初の単語「I」に絞ったレイヤ
「I」に絞ると↓のようなイメージです。ポイントは「I」から出てるqueryが全ての単語につながっている箇所です。詳細は後で説明します。
Self-Attentionの処理順序
参考元から拝借させていただきました。が、この手順を眺めてもまだ良く分からないと思うので、順番に説明します。参考元と紐づけできるように英語をそのまま書いてますが、日本語「()」の方を見ていただければOKです。
1.Prepare inputs(インプット前処理)
2.Initialise weights(query、key、valueの重み設定)
3.Derive key, query and value(query、key、valueの導出)
4.Calculate attention scores for Input 1(scoreの導出)
5.Calculate softmax(scoreベクトルをsoftmaxで処理)
6.Multiply scores with values(scoreとvalueを分ける)
7.Sum weighted values to get Output 1(計算したベクトルを全部足す)
8.Repeat steps 4-7 for Input 2 & Input 3(全てのインプットに適用)
Self-Attentionの処理
1.Prepare inputs(インプット前処理)
ここは先ほど説明を省略するといったone-hotから分散表現の獲得までの処理です。詳細は割愛しますが、↓のとおりになります。
2.Initialise weights(query、key、valueの重み設定)
いよいよSelf-Attentionレイヤの説明に入ります。まず、「query」「key」「value」が何者なのか記載しておきます。
やりたい事は「重み設定」ですので、それぞれに重みwを設けます。重みの数値は適当で列数は自由に設定可能です(ここでは3列)。

<ポイント>
源泉となるデータは同一のinputですが、重み(w)はそれぞれで用意する所です。
3.Derive key, query and value(query、key、valueの導出)
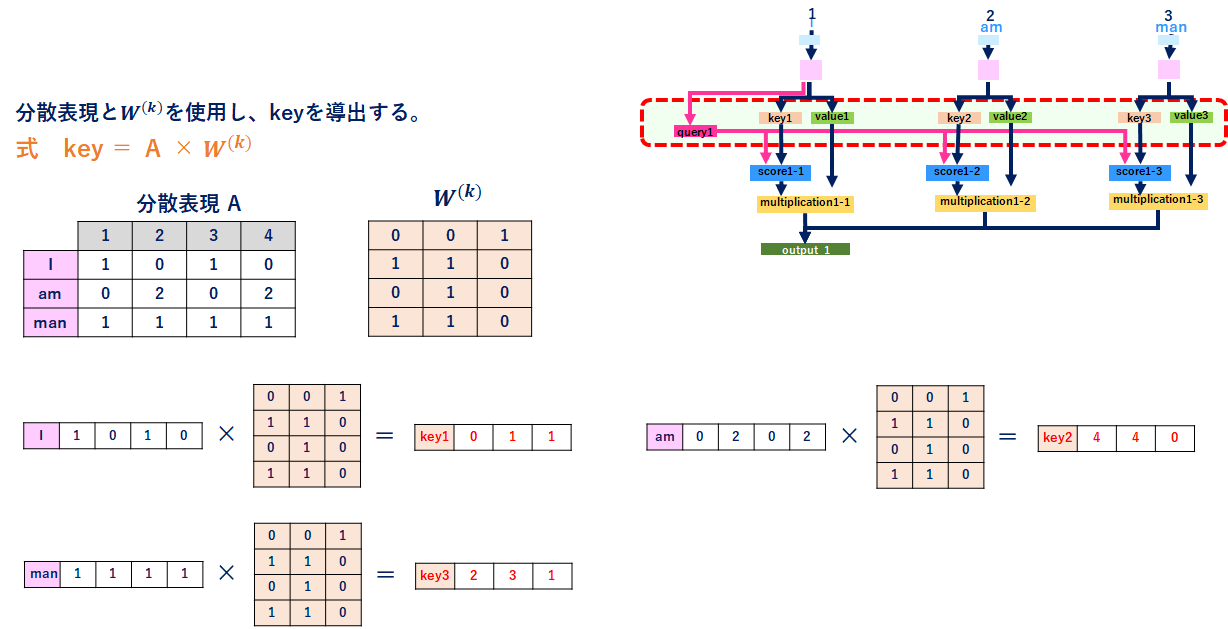
keyの導出
それぞれの単語に重みを掛けて、keyベクトル(行列)を作成します。以降の処理で全ての単語ベクトル(key1,key2,key3)を使用します。
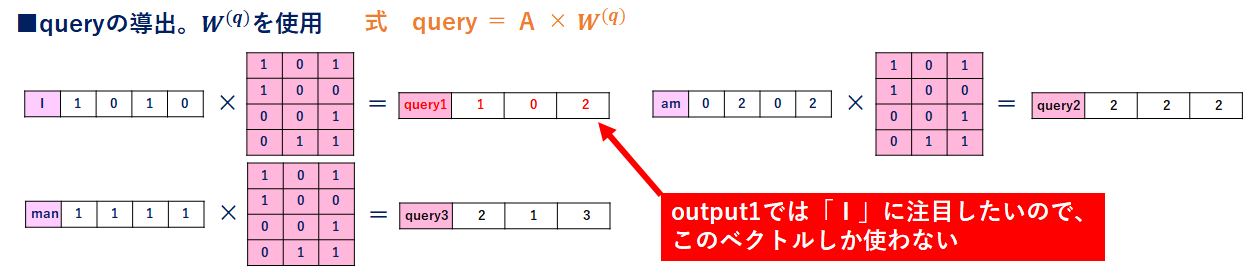
queryの導出
keyと同様に計算します。ですが、今は「I」の処理なので、queryは「I」の部分(query1)しか使いません。
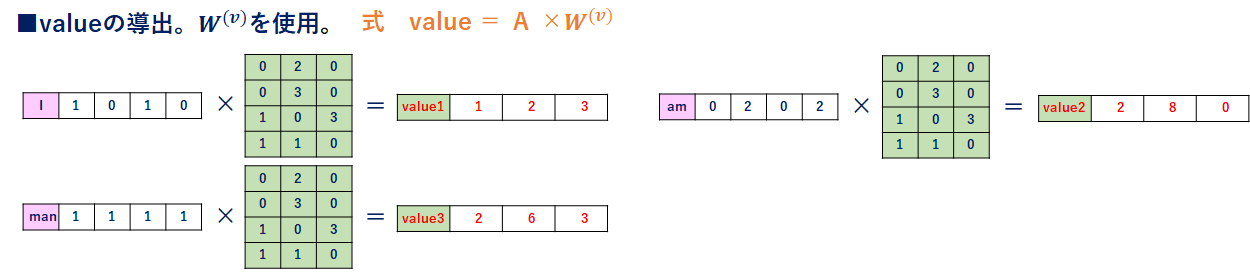
valueの導出
keyと同様、以降の処理で全ての単語ベクトル(value1,value2,value3)を使用します。
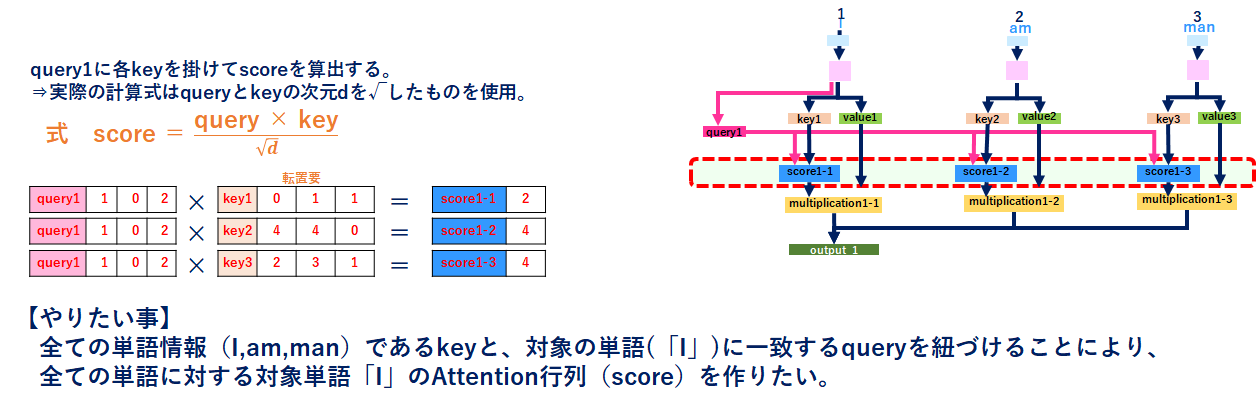
4.Calculate attention scores for Input 1(scoreの導出)
これがAttention_Weightになる元のベクトルです。queryとkeyから「I」と「全単語」の関係性を取得します。実際の次元数は√dになりますが、一旦無視します。
5.Calculate softmax(scoreベクトルをsoftmaxで処理=Attention_Weightの生成)
ここは単純にscoreベクトルをsoftmaxで計算しただけです。これがAttention_Weightです。

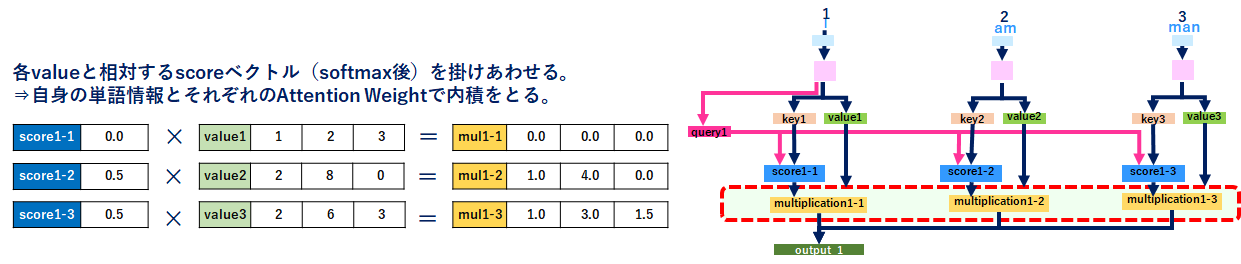
6.Multiply scores with values(scoreとvalueを分ける)
上記5でAttention_Weightを取得したので、valueから単語を抽出します。
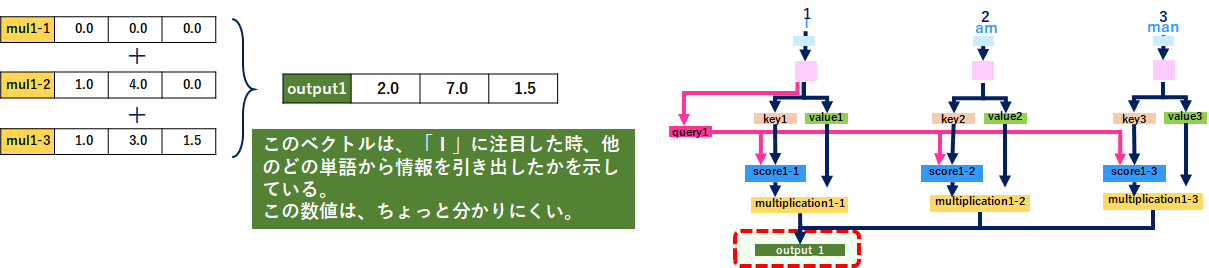
7.Sum weighted values to get Output 1(計算したベクトルを全部足す)
valueから単語情報を抜き出したら、全てのベクトルを足します。これがoutputで、「I」が他のどの単語と関係が深いのかが分かります。
ただ、今回の例では非常に分かりにくいので、論文「Attention Is All You Need」=Transformer から絵を拝借させていただきます。
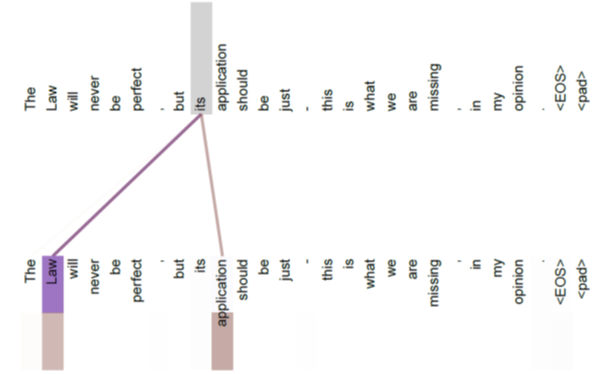
上の絵は上段がqueryです。queryである「its」が Law, application という
valueから情報を引いていることを示しています。
8.Repeat steps 4-7 for Input 2 & Input 3(全てのインプットに適用)
上記4~7を他の単語にも適用すると以下のとおりになります。が、今回の例では良く分からない数字(値)になってますね。すみません。

<参考:「am」のイメージ>
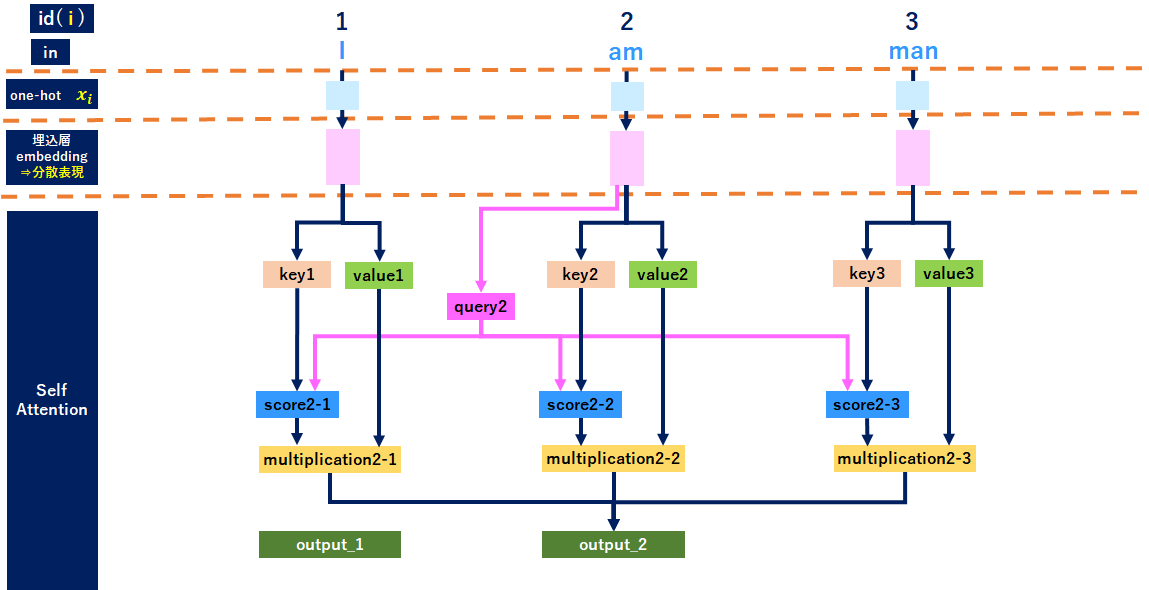
<参考:「man」のイメージ>
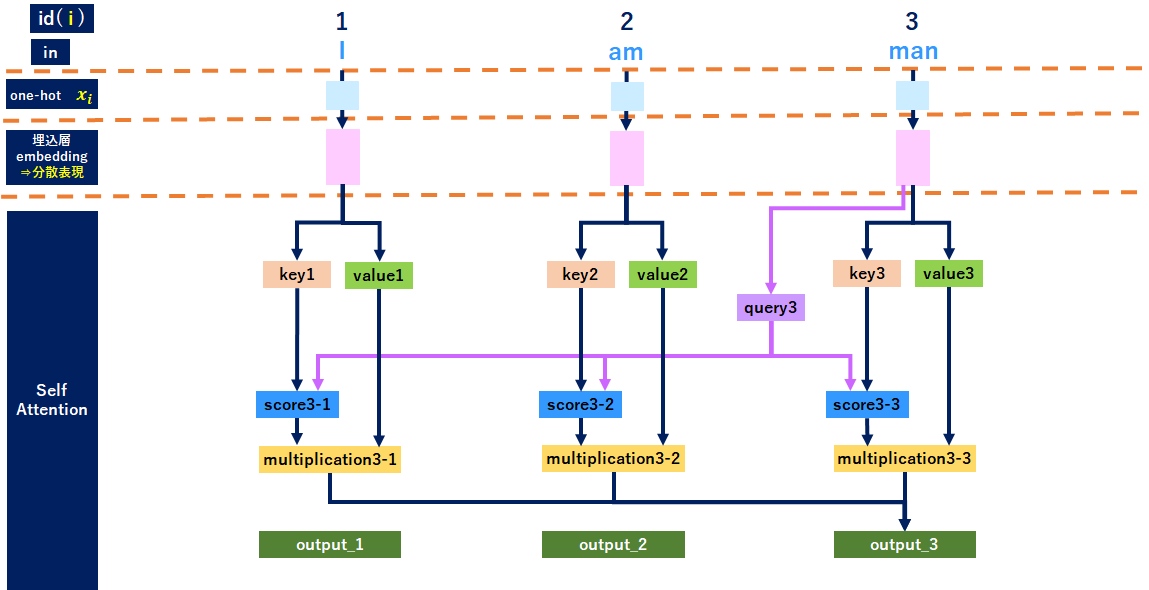
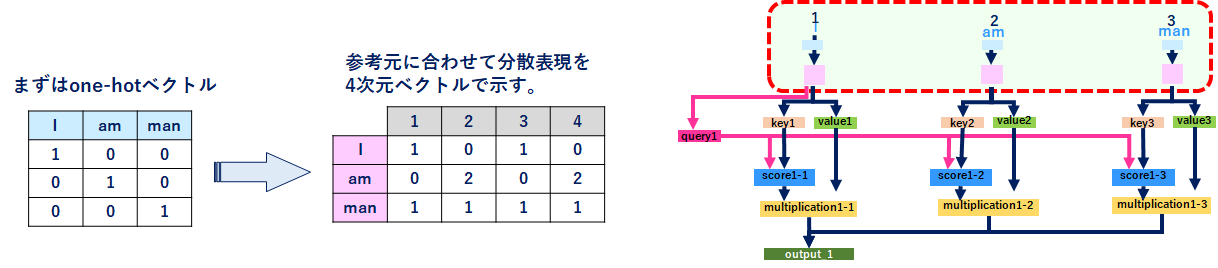
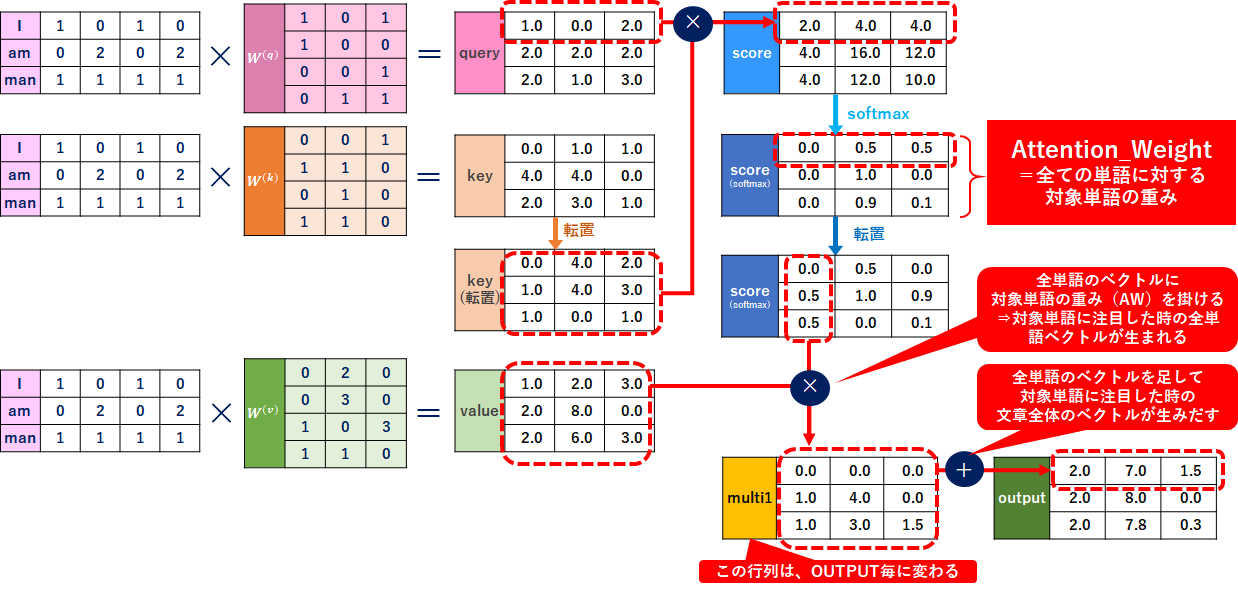
Self-Attentionをベクトル(行列)で整理
ここまで考え方・理屈を中心に整理しましたが、実際にベクトル(行列)で整理すると理解が深まるので、ベクトル(行列)で整理してみました。↓は「I」の処理です。
<補足>
score計算に内積を計算する必要があるため、 queryとkeyの次元数は常に同じでないとダメです。一方、valueの次元数はquery、keyと合わせる必要がなく、outputの次元数になるので、outputを意識した次元数にする必要がある(↑ではquery、keyに合わせているように見えてしまってます。すみません)。つまり「query、key」とvalueでは同じ単語でも異なるベクトル(行列)で表現することが可能です。
MultiHead
MultiHeadとは
話を冒頭の「Self-Attentionとは」に戻します。Self-Attentionのメリットとして「並列計算によって、出力をより複雑に表現できる」と書きました。これを実現するのが「MultiHead」です。MultiHeadは一言で言うと「Self-Attentionをいっぱい作って、より複雑に表現しよう」というものです。
そもそも何故こんな事が必要かというと、自然言語処理(NLP)には厄介な問題があって、その一つが「単語間の関係性が複数ある」ことです。
例えば「青が一番好き」と「その服に一番合う色は青」では「一番」と「青」の関係性が異なります。これを同じAttention_Weightで表現すると事実と異なる解釈をしてしまいます。よって、Self-Attentionを複数用意(MultiHeadに)することにより複数の単語関係を理解させます。
MultiHeadのレイヤ
全体レイヤのイメージは↓のとおりです。今回は3Headにしました。Self-Attention1が今まで説明してきたSelf-Attentionだと理解してください。そうすると2,3が追加されていますよね。これは「単語の関連を今まで1種類で表現していたが、3種類で表現している」ことになります。
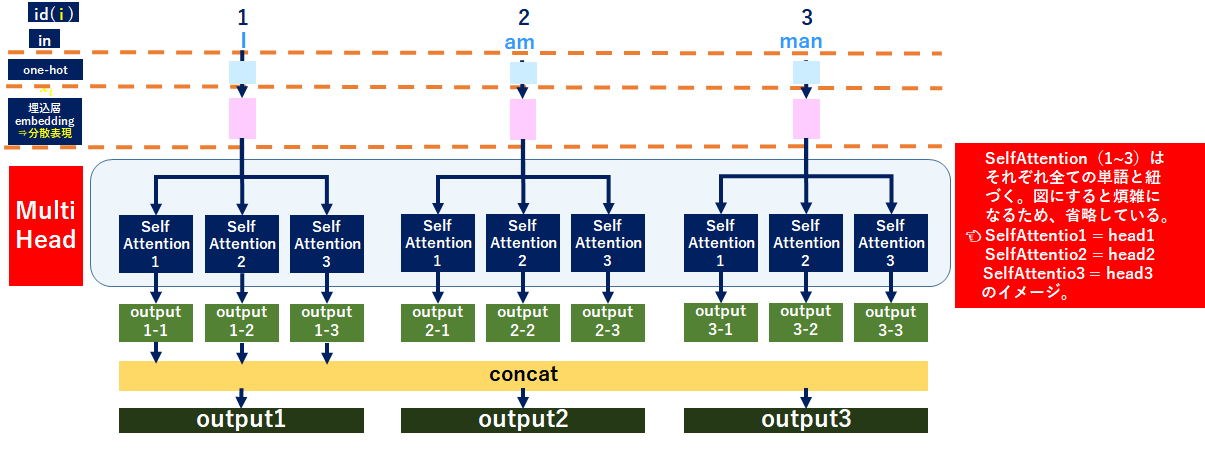
MultiHeadのoutput算出方法
それぞれのSelf-Attentionからoutputを得ます。くどいようですが、今まで説明してきたSelf-AttentionはSelf-Attention1です。よってアウトプットは「output1-1」「output2-1」「output3-1」になります。
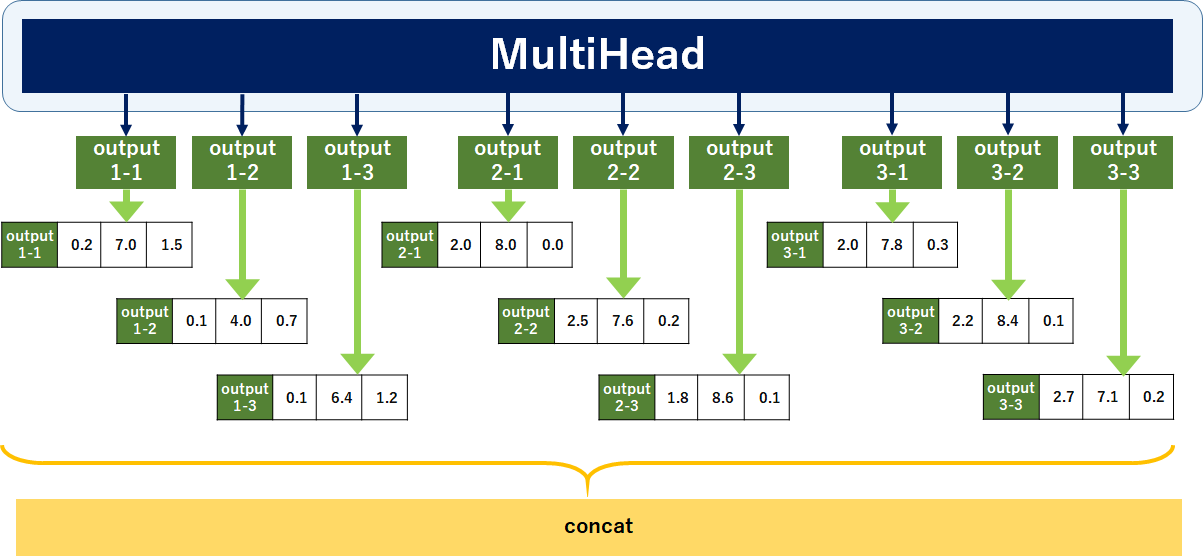
各Self-Attention(各head)のoutputが出そろったら、concatenateします。これにアウトプット用の重みw(o)を掛け合わせて、出力を得ます。
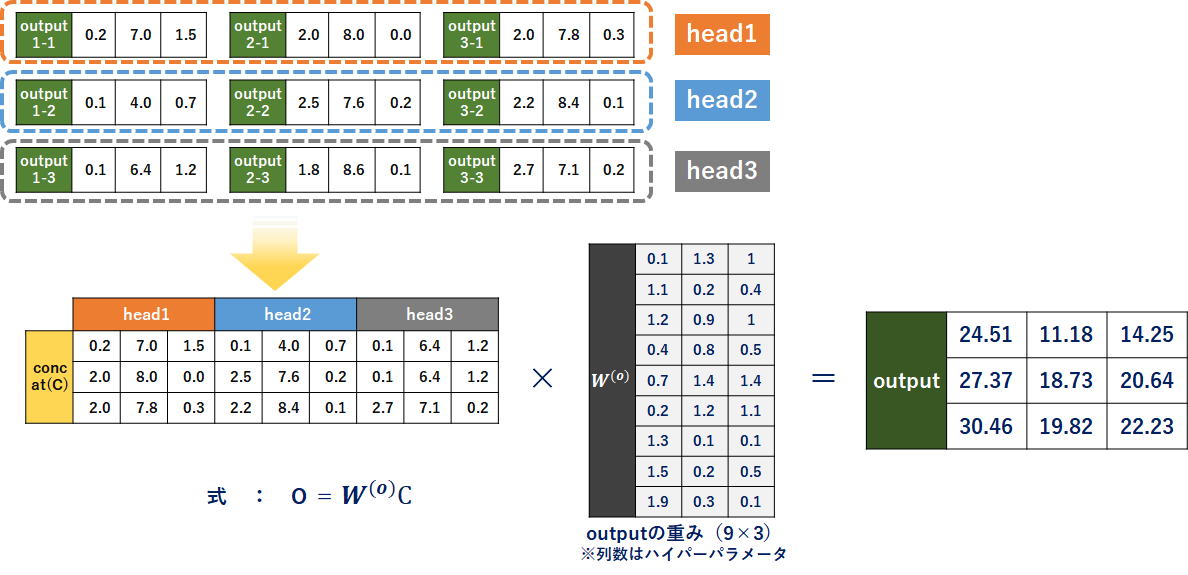
やっぱり3次元程度だと見た目からでは意味が分からないですが、Attentionは概ね理解できました。
次回に向けて
次は論文「Attention Is All You Need」=Transformer を整理します。
「Attention Is All You Need = Transformer をざっくり理解してみる。」
https://qiita.com/ta2bonn/items/4ec687bc136a41c364ae