 llamafileとは
llamafileとは
llamafileとは大規模言語モデル(LLM)をマルチプラットフォームで実行可能なようにパッケージ化するもの、あるいはパッケージ化されたファイル。
Githubより.
私たちの目標は、オープンなLLMを開発者とエンドユーザーの両方にとって、よりアクセスしやすくすることです。私たちは、llama.cppとCosmopolitan Libcを一つのフレームワークに統合することで、LLMのすべての複雑さを、インストールすることなく、ほとんどのコンピュータでローカルに動作する単一ファイルの実行ファイル("llamafile "と呼ばれます)に集約しています。
要は、いろんなOS上で簡単にLLMを実行可能にする素敵なツール、ということです。
ローカル上でとても簡単に生成AIを稼働させることが出来、しかもllama.cppを利用しているのでCPUで動作します。
 実行
実行
llamafileを実行するのはとても簡単です。
まずはhuggingfaceからllamafileをダウンロードします。
いくつかのLLMのllamafileが見つかると思いますので、お好みのモデルのものを取得しましょう。
ここの例では
mistral-7b-instruct-v0.2.Q3_K_M.llamafileを使用します。
Windowsの場合は、DLしたllamafileのファイル名を変更し最後に.exeを追加します。
(mistral-7b-instruct-v0.2.Q3_K_M.llamafile.exe)
あとはこのファイルを実行するだけです。
ターミナルが立ち上がり処理が走り出します。
しばらくするとブラウザが起動し以下のような画面が表示されます。
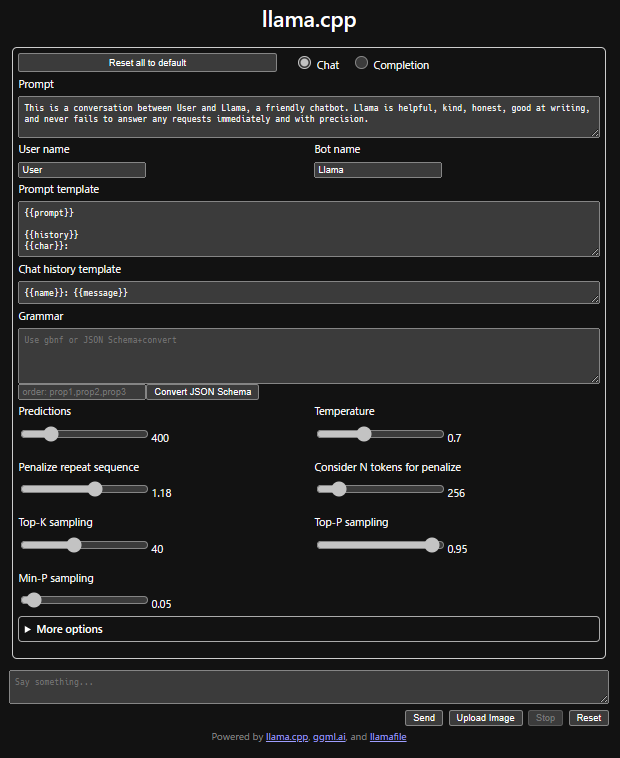
これで生成AI利用の準備はOKです。
下部の"Say something..."の欄に文章を入力しSendボタンを押下すれば会話が始まります。
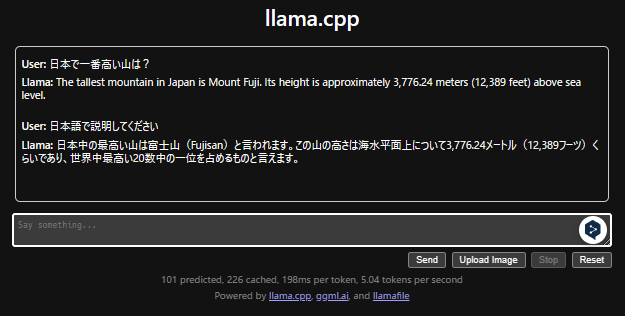
注意
Windowsでは4GB以上の実行ファイルを実行することが出来ません。
llamafileのサイズに注意してください。
LLMを指定してllamafileを実行
現時点ではllamafile化されたLLMはまだ選択肢が多くありません。
またWindowsでは4GBの制限があるため、性能のよいLLM(llamafile)を実行することができません。
そのような場合は、お好みのLLMを指定してllamafileを実行することができます。
まずは以下をダウンロードします。
-
Githubより
llamafile-*.* -
huggingfaceより利用したいLLMの
ggufファイル例では
ELYZA-japanese-Llama-2-7b-instruct-q3_K_M.ggufを利用しています。
Windowsの場合は、ダウンロードしたllamafile-*.*をllamafile.exeにファイル名変更しておきます。
次にターミナルを開き、以下コマンドを実行します。
llamafile.exe -m ELYZA-japanese-Llama-2-7b-instruct-q3_K_M.gguf --host 0.0.0.0
※上記はカレントディレクトリ内にllamafileとggufファイルがある場合です。
異なるディレクトリにある場合はパスを指定してください。
すると先ほどと同様にターミナル内で処理が走り出します。
しばらくするとブラウザが起動し先ほどと同様の画面が表示されます。
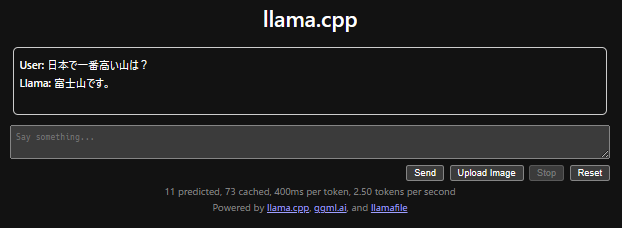
あとの使い方は同じです。
文章を入力しSendをクリックしましょう。
 あとがき
あとがき
上記利用手順を見てもわかるように、極めて簡単にLLMを利用することができます。
ある程度の性能のLLMを利用するにはそれなりのスペックの端末が必要ですが、強力なGPUも必須というわけではなく(コマンド実行時にオプションでGPUに処理させることも可)、また、ファイルさえ用意すればインターネット接続も不要と、使い勝手も良いです。
いろんなLLMの比較検証や、クローズドな環境での生成AIシステムの構築などに適しているのでは、と感じます。
OSSのLLMも、llama-2のようなメジャーなものから最新で強力なCommand-R+まで、いろいろ利用することが可能です。
みなさんもお気軽に試してみてはいかがでしょうか。
それでは、よいLLMライフを![]()