はじめに
機械学習に取り組むにあたり、大量の教師データの用意は一つの大きな壁で、
現場でも「教師データが少なくて困っている」というのはよく聞く話だと思います。
データセットが少ない、もしくは全くない状況での学習に対するアプローチの一つとして、
3Dモデルからの学習データの生成があり、今日では商用ゲームが自動運転の訓練等に活用されています。
Don't Worry, Driverless Cars Are Learning From Grand Theft Auto
こうした例では実写と見紛うレベルのモデルが使われていますが、
一般的に、ここまで高品質なモデルを手に入れるハードルはかなり高いものだと思われます。
本記事では、誰でも無料・簡単に作成できるレベルの3Dモデルから
生成したデータセットのみを学習に用い、実際のデータセットに対する検知がどの程度うまくいくかを検証します。
検証対象
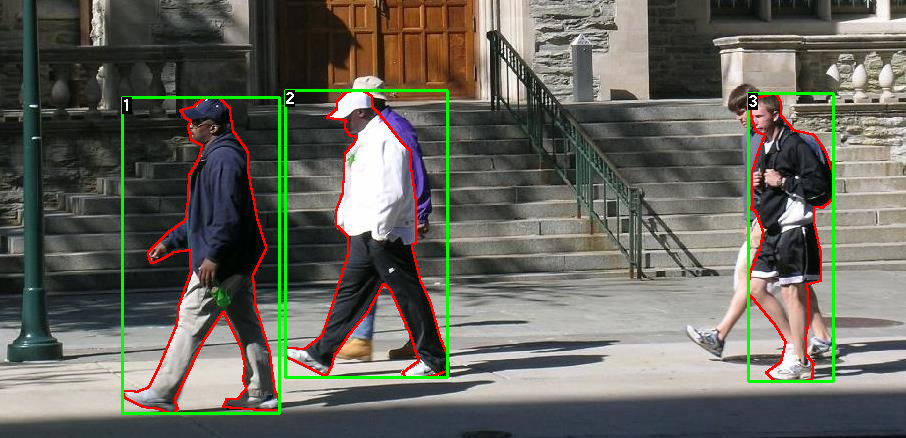
今回は、検証対象としてPennFudanDatasetを使います。
学習データの生成
人物モデルの作成
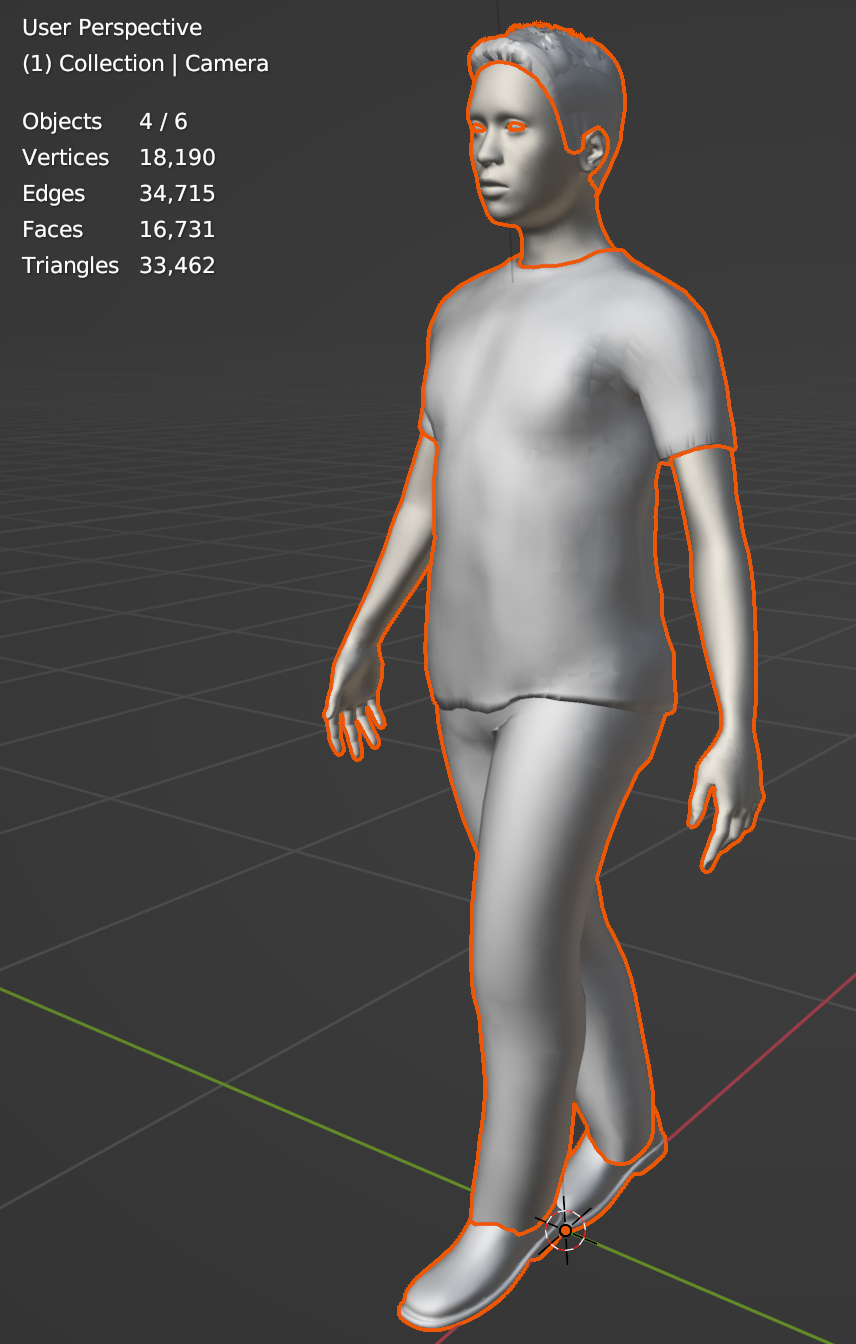
人物モデルの作成にはMakeHumanを使います。
MakeHumanはBlenderに精通していなくても簡単に人物の3Dモデルを作ることができる、大変ありがたいツールです。
今回はデフォルトの設定を使って、下の彼を含む6人(男性3人、女性3人)を作りました。
blenderで扱えるよう、fbx形式でエクスポートしておきます。

余談ですが、PlayStation公式が公開しているPS1〜4のグラフィック比較動画を見ると、
MakeHumanでサクッと作れる人物は大体PS2ぐらいの見た目に位置するのではと思い、本記事のタイトルとなりました。
PS4 vs PS3 vs PS2 vs PS1 Graphics Comparison: The Road To PlayStation 4
こちらの歴代MGSのポリゴン数カウントが正しいとすると、ポリゴン数ではPS3、4を超えてしまっていそうです。
作成したモデルから学習データの生成
学習データの生成にはBlenderProcを使います。
BlenderProcはblenderのシーンから簡単に機械学習用のデータが生成できるツールで、背景や物体、カメラ、照明のランダム化により多様なデータを生み出すことができます。また、COCO formatでのアノテーション出力も可能です。
BlenderProcは公式が豊富なデモを用意してくれていることから、exampleを参照すればそれっぽいデータセットを簡単に量産することができます。今回はcoco_annotationsをベースに進めます。
sceneの用意
blenderで新規sceneを立ち上げ、人物モデルの作成で用意した3Dモデルをインポートします。
インポートした直後は人物モデルが20m近くあることになっているので、その後扱いやすいようにscaleを0.1程度に調整します。
sceneから画像の生成
以下のコマンドでsceneから画像が生成できます。
blenderproc run \
examples/advanced/coco_annotations/main.py \
examples/resources/camera_positions \
<上で用意したsceneのパス> \
examples/advanced/coco_annotations/output
おそらくそのままmain.pyを実行しても対象物が映らない、ということになると思うので、
理想の画角が得られるようexamples/resources/camera_positionsなどを調整します。
main.pyに下記を追加し、enable_transparencyオプションをONにすると、
対象物以外が透過された状態で画像が生成されます。(次項の背景の合成に必要になります)
bproc.renderer.set_output_format(enable_transparency=True)



背景の合成
random_backgroundsを参考に、ランダムな背景を用意して透過画像に合成します。
今回使った20枚の背景はWikimedia Commonsから拝借しました。



成果物
最終的なデータセットは以下のようになります。
今回は6人×100枚ずつで計600枚の画像を生成しました。
(boundary boxはBlenderProcのvisコマンドで表示しています)






boundary boxから少し頭がはみ出していますが、今回はざっくりした結果が出せれば良いのでこのまま進めます。
(BlenderProcでアノテーション生成時に人物全体が入るboundary boxを作るため、3Dモデルをblender内にimport後、肌と靴のObjectを結合するという荒技を使ったため)
学習
歩行者の検知には手元に環境があったYOLOv5sを使います。
生成した600枚のうち80%をtrain、20%をvalidationに、
PennFudanDataset全170枚をtestに使い、30エポックの学習を回しました。
augmentationは入れていないです。
結果
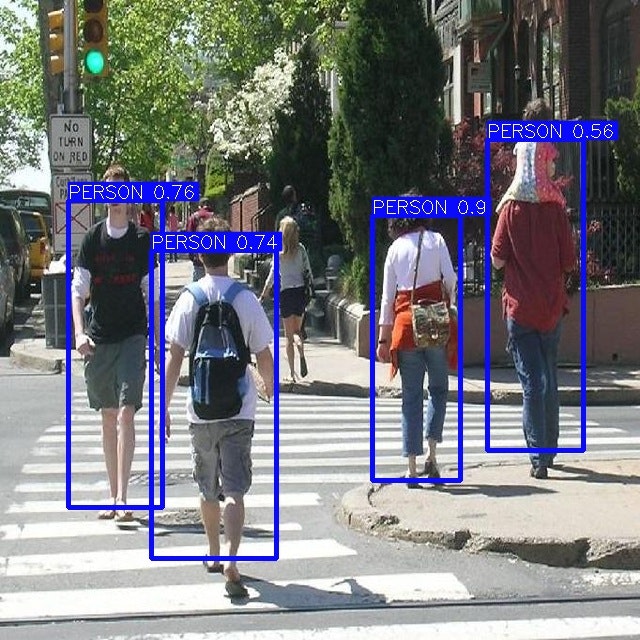
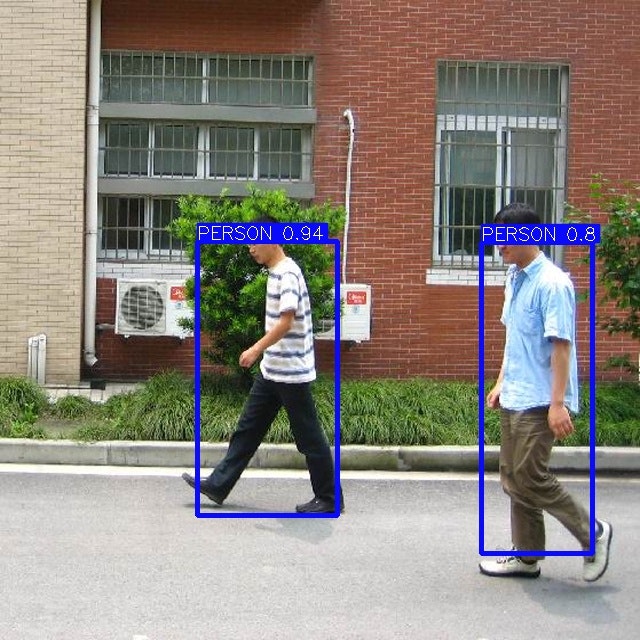
今回の試行では精度の計算や他データセットとの比較はせず、結果の表示に留まりますが、
特定のシーンではしっかりと人物が検出できることが分かりました。
うまくいった例
※confidence70%以上で画面上の概ねの人物の全身が検知できている結果



うまくいかなかった例





おわりに
PS2レベルの3Dモデルから生成した教師データのみの学習でも、歩行者検知には十分有用であることがわかりました。
髪型、服、ポーズといった人物のバリエーションとしては、今回6種類のみを教師データとした検証となりましたが、異なる様相の人々も検出できました。
今回検知できなかった人物については、3Dモデルのバリエーションを増やすことで検知精度を上げることが可能だと思われます。
モデルが用意できればPS1レベルの3Dモデルで検証してみても面白そうです。