Amazon Kendraとは
AWSが提供するエンタープライズ向けのインテリジェント検索サービスです。
ユースケースとしては、社内のナレッジなどのコンテンツをKendraに渡すことで複雑化した文書を簡単に検索できるようにすることなどが挙げられます。
以下公式説明引用
Amazon Kendra は、機械学習を原動力とする高精度のインテリジェント検索サービスです。Kendra を使用すると、ウェブサイトやアプリケーションのエンタープライズ検索に対する考えが変わります。従業員や顧客は、企業内の複数の場所やコンテンツリポジトリにコンテンツが分散して保存されている場合であっても、目的のコンテンツを簡単に見つけることができます。
Amazon Kendra を使用すると、膨大な非構造化データを隅から隅まで検索する必要がなくなり、質問に対する適切な回答を必要なときに見つけることが可能となります。Amazon Kendra はフルマネージド型のサービスであるため、サーバーのプロビジョニングも、機械学習モデルの構築、トレーニング、デプロイも不要です。
WebCrawling機能について
先日の発表で、ウェブクローラを用いてWeb上にあるコンテンツのインデックスの作成・検索を行えるようになったようです。
本稿ではこちらを試してみます。
試してみる
検証用のWebサイト用意
S3の静的ホスティング機能を用い、クロールを行うWebサイトを準備します。
まず適当なhtmlファイルを作成し、公開します。
index.htmlにリンクを貼る形で作成しました。
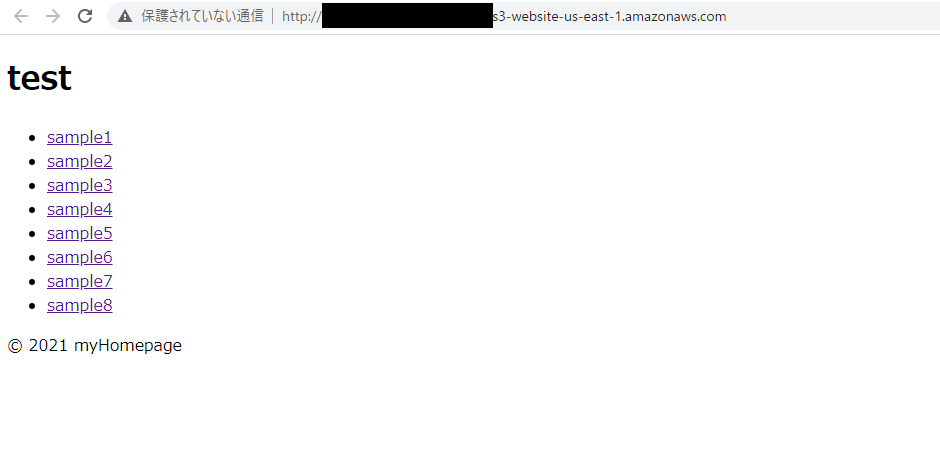
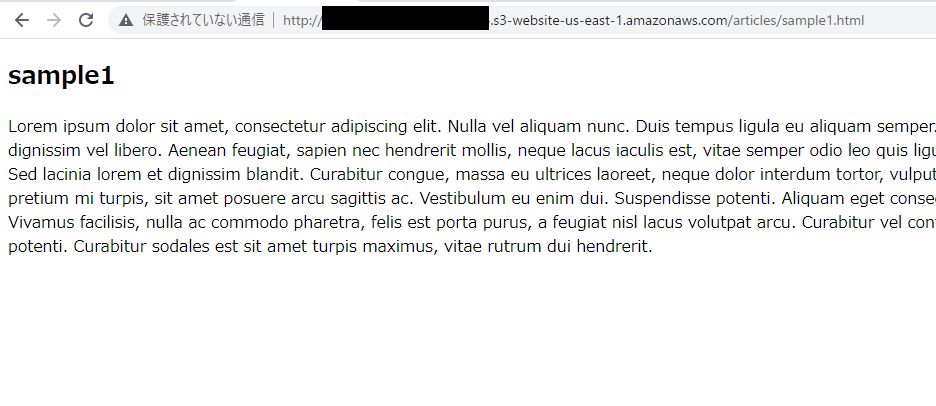
サブディレクトリにファイルを配置し、ランダムな文章を記載しました。
ちなみに、robots.txtは以下の通りです。
User-agent: amazon-kendra-customer-id-<AccountID> # Amazon customer's user agent/ID
Allow: / # allow this directory
参考:
CloudFrontの設定
KendraのWebCrawlingを扱う際は、データソースを https化しないとエラー になるようなので、CloudFrontを使用してhttps化します。
こちらの公式の案内を参考にしてご設定ください。
https化しない状態でデータソースを作成すると以下のようなエラーが表示されました。
Crawling isn't allowed for these sites: http://<S3 バケット名>.s3-website-us-east-1.amazonaws.com/.
Remove the URLs and try your request again. - ValidationException - 400 Request ID: XXXXXXXXXXXXXXXXXXXXXXXXXXXX
インデックスの作成
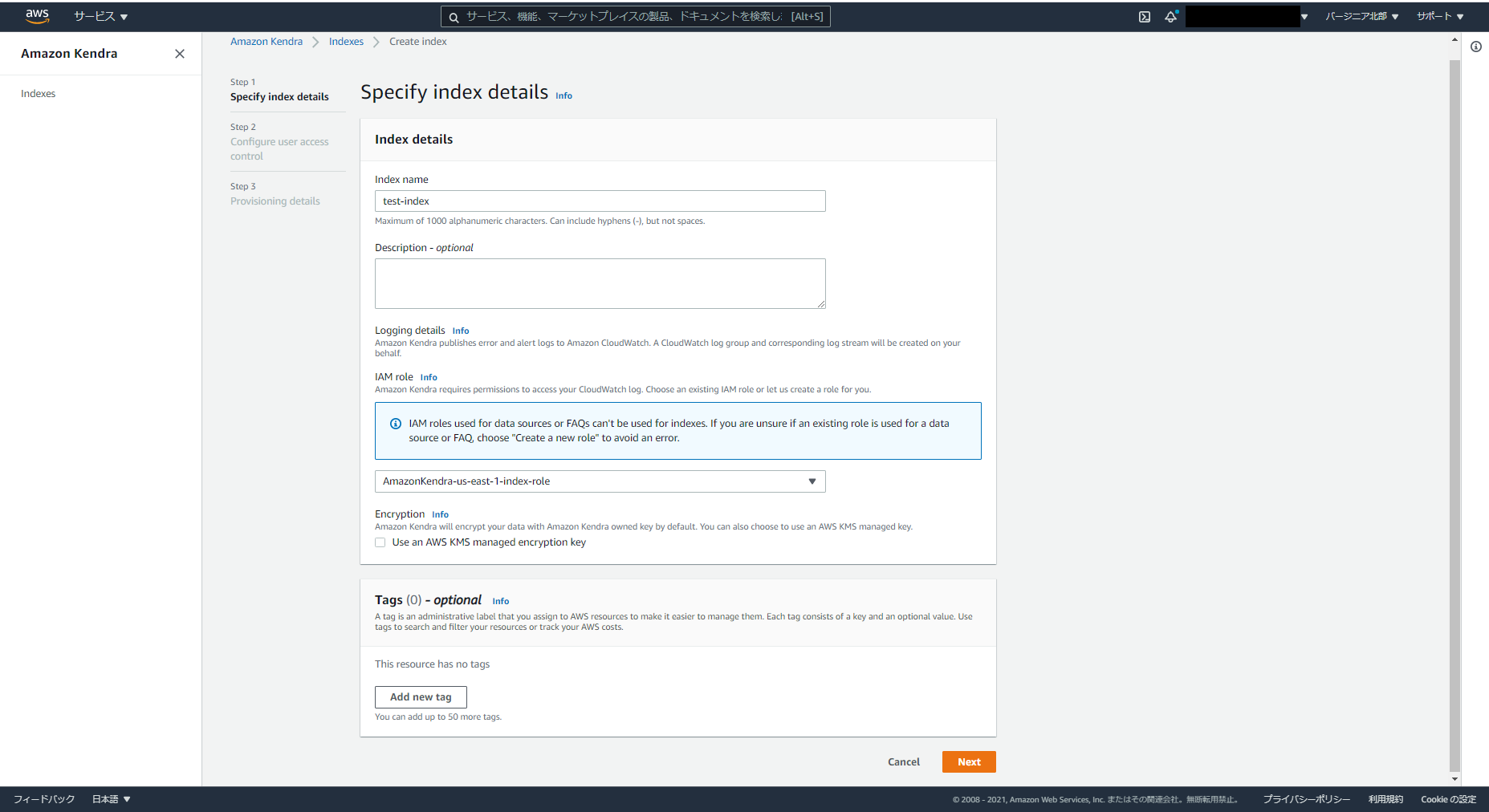
Amazon Kendraのインデックスの作成を行います。
残念ながら東京リージョンにGAされていない(2021-07現在)為、バージニア北部リージョンを利用します。
適当にindex nameをつけ、ロールを新規に作りました。
今回は検証なので「Developer edition」を利用します。
データソースの作成
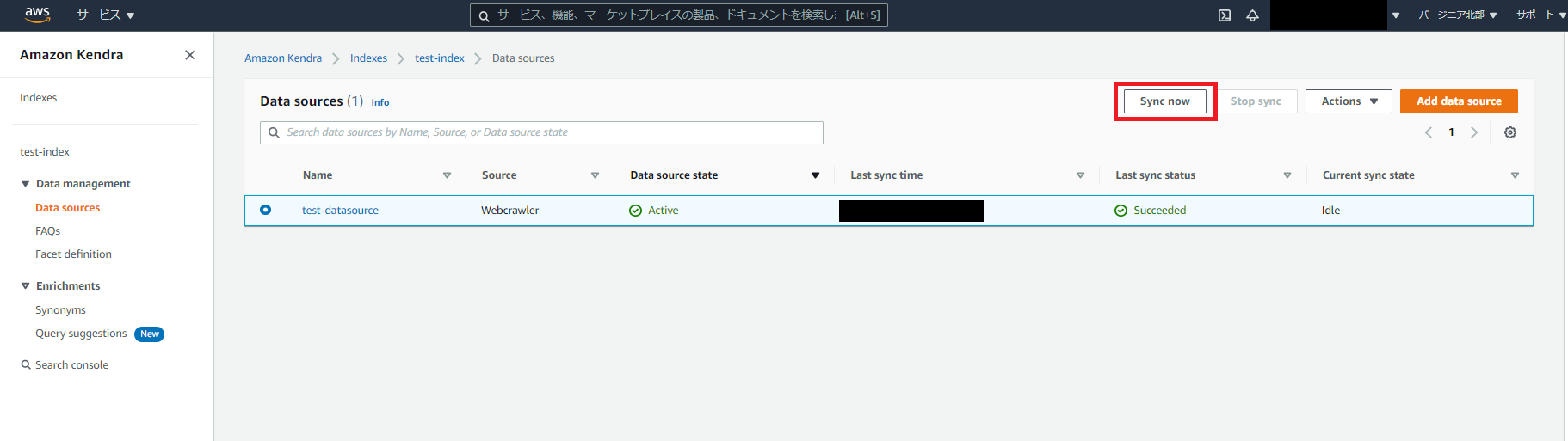
データソースを作成します。
作製したindexを選択して「Add Data source」を押下し、WebCrawlerを選択します。

設定値は以下の通りとしました。
- Data source name: test-datasource
- Source
- SourceURLs:< CloudFrontのエンドポイント >
- Web proxy:設定せず
- Hosts with authentication :設定せず
- IAM role:Create a new roleから作成
- Crawl scope:デフォルト
- Sync run schedule:Run on demand
完了したら以下のボタンからクローラを実行しましょう。
検証
クローラの実行が終了したら検索を試してみましょう。
「Search Console」を押下してください。
中心の検索窓に適当な単語を入力してみると、検索が行われて関連度が高い部分が表示されることがわかります。
「What is ○○ ?」などと検索すると解説記事を優先的に表示したり、表示順を検索ワードによって変えている?みたいです。

まとめ
Amazon Kendraを用いることで、文書検索が簡単に行えました。たまったデータの検索ツールとして便利だと思います。
今回は試していませんが、他にもQ&Aが登録できたりするみたいです。
本稿ではHTMLで試しましたが、PDFも対応しているということで機会があれば試してみたいです。(日本語対応しないかなぁ)