##はじめに
2019年より思い立ってAIの勉強を始めました。その過程で、Raspberry Piカメラを使った顔認証の仕組みを作ってみましたので、ご紹介したいと思います。
##環境
<学習する側(ディープラーニング)>
・Ubuntu(Windows10上のVirtualBoxにインストール)
・Python(v3)
・Scikit-learn
・Keras(Theano)
・OpenCV(顔の切り出しで使用)
<予測する側>
・Raspberry Pi Model B(Rasbian)
・Raspberry Piカメラっぽいやつ(中国製)
・Python(v2)
・OpenCV
##流れ
1.学習用の画像をWebから収集
2.収集した画像から顔だけ切り出した画像を生成
3.PC上で学習
4.Raspberry Piで予測
5.動かしてみる
##1.学習用の画像をWebから収集
手作業は避けたいので、PythonからGoogle画像検索をして画像を収集しました(参考)。
以下のプログラムを例えば$python3 image_collector.py 安部晋三 1000
(第一引数:検索ワード、第二引数:最大取得数)で実行します。
ソース
# -*- coding: utf-8 -*-
import json
import os
import sys
import urllib
from bs4 import BeautifulSoup
import requests
class Google:
def __init__(self):
self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search'
self.session = requests.session()
self.session.headers.update(
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'})
def search(self, keyword, maximum):
print('begin searching', keyword)
query = self.query_gen(keyword)
return self.image_search(query, maximum)
def query_gen(self, keyword):
# search query generator
page = 0
while True:
params = urllib.parse.urlencode({
'q': keyword,
'tbm': 'isch',
'ijn': str(page)})
yield self.GOOGLE_SEARCH_URL + '?' + params
page += 1
def image_search(self, query_gen, maximum):
# search image
result = []
total = 0
while True:
# search
html = self.session.get(next(query_gen)).text
soup = BeautifulSoup(html, 'lxml')
elements = soup.select('.rg_meta.notranslate')
jsons = [json.loads(e.get_text()) for e in elements]
imageURLs = [js['ou'] for js in jsons]
# add search result
if not len(imageURLs):
print('-> no more images')
break
elif len(imageURLs) > maximum - total:
result += imageURLs[:maximum - total]
break
else:
result += imageURLs
total += len(imageURLs)
print('-> found', str(len(result)), 'images')
return result
def main():
google = Google()
if len(sys.argv) != 3:
print('invalid argment')
print('> ./image_collector_cui.py [target name] [download number]')
sys.exit()
else:
# save location
name = sys.argv[1]
data_dir = 'data/'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
if not os.path.exists('data/' + name):
os.makedirs('data/' + name)
try:
# search image
result = google.search(name, maximum=int(sys.argv[2]))
except:
import traceback
traceback.print_exc()
# download
download_error = []
for i in range(len(result)):
print('-> downloading image', str(i + 1).zfill(4))
try:
urllib.request.urlretrieve(
result[i], data_dir + name + '/' + str(i + 1).zfill(4) + '.jpg')
except:
print('--> could not download image', str(i + 1).zfill(4))
download_error.append(i + 1)
continue
print('complete download')
print('├─ download', len(result)-len(download_error), 'images')
print('└─ could not download', len(
download_error), 'images', download_error)
if __name__ == '__main__':
main()
##2.収集した画像から顔だけ切り出した画像を生成
こちらもPythonで自動化しました(参考)。
このプログラムは顔を切り出した後、左右反転や左右回転などした画像も生成してくれます。
以下のプログラムを例えば$python3 face_output.py -p /home/user/data/安部晋三
(引数:加工対象の画像のパス)で実行します。
ソース
# -*- coding: utf-8 -*-
import os
import glob
import argparse
import cv2
from PIL import Image
import numpy as np
IMAGE_HEIGHT = 128
CASCADE_PATH = "/home/takii/haarcascades/haarcascade_frontalface_alt.xml"
cascade = cv2.CascadeClassifier(CASCADE_PATH)
color = (255, 255, 255)
def detectFace(image):
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.07, minNeighbors=9, minSize=(10, 10))
return facerect
def pre_resize(before, after, height=IMAGE_HEIGHT, filename="", antialias_enable=True):
"""
Resize images according to the pre-defined image_heiht regardless of the size of them.
"""
img = Image.open(before, 'r')
before_x, before_y = img.size[0], img.size[1]
x = int(round(float(height / float(before_y) * float(before_x))))
y = height
resize_img = img
if antialias_enable:
resize_img.thumbnail((x, y), Image.ANTIALIAS)
else:
resize_img = resize_img.resize((x, y))
resize_img.save(after, 'jpeg', quality=100)
print( "RESIZED: %s[%sx%s] --> %sx%s" % (filename, before_x, before_y, x, y) )
def resize(image):
return cv2.resize(image, (64,64))
def rotate(image, r):
h, w, ch = image.shape # 画像の配列サイズ
M = cv2.getRotationMatrix2D((w/2, h/2), r, 1) # 画像を中心に回転させるための回転行列
rotated = cv2.warpAffine(image, M, (w, h))
return rotated
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='clip face-image from imagefile and do data argumentation.')
parser.add_argument('-p', required=True, help='set files path.', metavar='imagefile_path')
args = parser.parse_args()
# リサイズした画像を格納
resize_dir = args.p + "/_resize"
if not os.path.exists(resize_dir):
os.makedirs(resize_dir)
# 顔部分に囲いを追加した画像を格納
addbox_dir = args.p + "/_addbox"
if not os.path.exists(addbox_dir):
os.makedirs(addbox_dir)
# 顔部分をトリミングした画像を格納
trimming_dir = args.p + "/_trimming"
if not os.path.exists(trimming_dir):
os.makedirs(trimming_dir)
face_cnt = 0
# jpgファイル取得
files = glob.glob( "%s/*.jp*g" % (args.p) )
for file_name in files:
before_path = file_name
filename = os.path.basename(file_name)
after_path = '%s/%s' % ( resize_dir, filename )
pre_resize(before_path, after_path, filename=file_name)
resize_files = glob.glob(resize_dir+"/*.jpg")
for file_name in resize_files:
print("detect face on file:"+file_name)
# 画像のロード
image = cv2.imread(file_name)
if image is None:
# 読み込み失敗
print("image is None")
continue
# -12~12度の範囲で3度ずつ回転
for r in range(-12,13,4):
image = rotate(image, r)
# 顔画像抽出
facerect_list = detectFace(image)
if len(facerect_list) == 0:
print("NG detectFace")
continue
basename = os.path.basename(file_name)
# 顔検知の囲い追加画像保存 どの程度の精度で検知できているかの確認
for rect in facerect_list:
cv2.rectangle(image, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=2)
cv2.imwrite(addbox_dir+"/"+basename, image)
# 顔部分切り抜き
for facerect in facerect_list:
# 顔画像部分の切り抜き
croped = image[facerect[1]:facerect[1]+facerect[3],facerect[0]:facerect[0]+facerect[2]]
# 出力
cv2.imwrite(trimming_dir+"/"+str(face_cnt)+".jpg", resize(croped))
face_cnt += 1
# 反転画像も出力
fliped = np.fliplr(croped)
cv2.imwrite(trimming_dir+"/"+str(face_cnt)+".jpg", resize(fliped))
face_cnt += 1
ソース
# -*- coding: utf-8 -*-
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import load_img, img_to_array
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
import os, glob
import numpy as np
import matplotlib.pyplot as plt
root_dir = "/home/takii/cozto/data"
categories = ["安倍晋三", "麻生太郎", "新垣結衣", "柳楽優弥", "小林星蘭", "草村礼子"]
nb_classes = len(categories)
image_size = 64
# CNN設定
BATCH_SIZE = 32
EPOCHS = 15
def init():
X = []
Y = []
for idx, cat in enumerate(categories):
files = glob.glob(root_dir + "/" + cat + "/_trimming/*")
print("---", cat, "を処理中")
for i, f in enumerate(files):
img = load_img(f, target_size=(image_size,image_size))
data = img_to_array(img)
X.append(data)
Y.append(idx)
X = np.array(X)
Y = np.array(Y)
X_train, X_test, y_train, y_test = train_test_split(X, Y)
xy = (X_train, X_test, y_train, y_test)
np.save(root_dir + "/npy/face.npy", xy)
print("ok,", len(Y))
def main():
X_train, X_test, y_train, y_test = np.load(root_dir + "/npy/face.npy")
X_train = X_train.astype("float") / 256
X_test = X_test.astype("float") / 256
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
model = model_train(X_train, y_train)
model_eval(model, X_test, y_test)
def build_model(in_shape):
model = Sequential()
model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape=in_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(64, 3, 3, border_mode='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, 3, 3))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
def model_train(X, y):
model = build_model(X.shape[1:])
#history = model.fit(X, y, batch_size=BATCH_SIZE, nb_epoch=EPOCHS, validation_split=0.1)
history = model.fit(X, y, batch_size=BATCH_SIZE, nb_epoch=EPOCHS, validation_split=0.1)
json_string = model.to_json()
open(os.path.join(root_dir + '/h5/cnn_model.json'), 'w').write(json_string)
model.save_weights(root_dir + "/h5/face-model.h5")
# グラフ表示
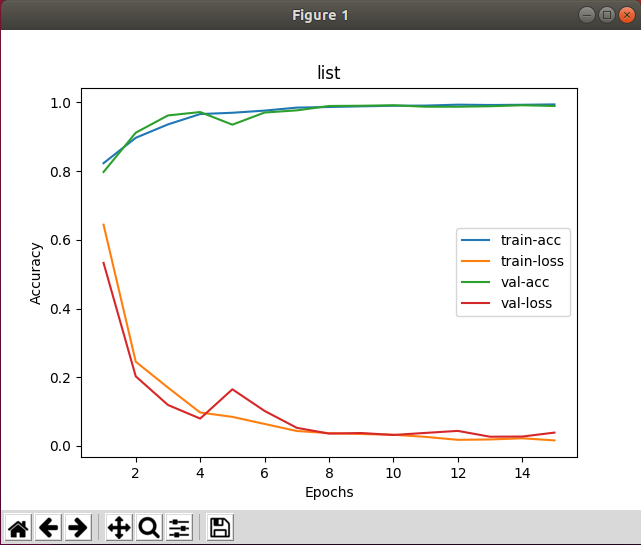
plt.plot(range(1, EPOCHS + 1), history.history['acc'], label = "train-acc")
plt.plot(range(1, EPOCHS + 1), history.history['loss'], label = "train-loss")
plt.plot(range(1, EPOCHS + 1), history.history['val_acc'], label = "val-acc")
plt.plot(range(1, EPOCHS + 1), history.history['val_loss'], label = "val-loss")
plt.title('list')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
return model
def model_eval(model, X, y):
score = model.evaluate(X, y)
print('loss=', score[0])
print('accuracy=', score[1])
if __name__ == "__main__":
init()
main()
学習時間は、画像の枚数が1人につき800枚×6人の約5000枚で、2.5hかかりました。
学習はクラウドにぶん投げるのが良いみたい。。。学習完了時のグラフです。
##4.Raspberry Piで予測
「learn.py」を実行すると、モデル構造と学習結果が以下に格納されます。
この2つと「predict.py」を、Raspberry Piに配置します。
以下のプログラムを例えば$python3 predict.pyで実行します。
ソース
# -*- coding: utf-8 -*-
import learn as face
import sys, os
from keras.preprocessing.image import load_img, img_to_array
import numpy as np
import cv2
import time
import picamera
import picamera.array
root_dir = "/home/pi/cozto/data"
cascade_file = "/home/pi/opencv-2.4.13/data/haarcascades/haarcascade_frontalface_alt.xml"
image_size = 32
categories = ["abeshinzo", "asoutarou"]
with picamera.PiCamera() as camera:
with picamera.array.PiRGBArray(camera) as stream:
# カメラの解像度を320x240にセット
camera.resolution = (320, 240)
# カメラのフレームレートを15fpsにセット
camera.framerate = 15
# ホワイトバランスをfluorescent(蛍光灯)モードにセット
camera.awb_mode = 'fluorescent'
while True:
# stream.arrayにBGRの順で映像データを格納
camera.capture(stream, 'bgr', use_video_port=True)
# グレースケールに変換
gray = cv2.cvtColor(stream.array, cv2.COLOR_BGR2GRAY)
# カスケードファイルを利用して顔の位置を見つける
cascade = cv2.CascadeClassifier(cascade_file)
face_list = cascade.detectMultiScale(gray, minSize=(100, 100))
cv2.imwrite("frontalface.png", stream.array)
img = cv2.imread("frontalface.png")
for rect in face_list:
cv2.rectangle(stream.array, tuple(rect[0:2]),tuple(rect[0:2] + rect[2:4]), color, thickness=2)
x = rect[0]
y = rect[1]
width = rect[2]
height = rect[3]
dst = img[y:y+height, x:x+width]
cv2.imwrite("output.png", dst)
cv2.imread("output.png")
X = []
img = load_img("./output.png", target_size=(image_size,image_size))
in_data = img_to_array(img)
X.append(in_data)
X = np.array(X)
X = X.astype("float") / 256
model = face.build_model(X.shape[1:])
model.load_weights(root_dir + "/h5/face-model.h5")
pre = model.predict(X)
print(pre)
if pre[0][0] > 0.9:
print(categories[0])
text = categories[0] + str(pre[0][0]*100) + "%"
font = cv2.FONT_HERSHEY_PLAIN
cv2.putText(stream.array,text,(rect[0],rect[1]-10),font, 2, color, 2, cv2.CV_AA)
elif pre[0][1] > 0.9:
print(categories[1])
text = categories[1] + str(pre[0][1]*100) + "%"
font = cv2.FONT_HERSHEY_PLAIN
cv2.putText(stream.array,text,(rect[0],rect[1]-10),font, 2, color, 2, cv2.CV_AA)
elif pre[0][2] > 0.9:
print(categories[2])
text = categories[2] + str(pre[0][2]*100) + "%"
font = cv2.FONT_HERSHEY_PLAIN
cv2.putText(stream.array,text,(rect[0],rect[1]-10),font, 2, color, 2, cv2.CV_AA)
elif pre[0][3] > 0.9:
print(categories[3])
text = categories[3] + str(pre[0][3]*100) + "%"
font = cv2.FONT_HERSHEY_PLAIN
cv2.putText(stream.array,text,(rect[0],rect[1]-10),font, 2, color, 2, cv2.CV_AA)
elif pre[0][4] > 0.9:
print(categories[4])
text = categories[4] + str(pre[0][4]*100) + "%"
font = cv2.FONT_HERSHEY_PLAIN
cv2.putText(stream.array,text,(rect[0],rect[1]-10),font, 2, color, 2, cv2.CV_AA)
elif pre[0][5] > 0.9:
print(categories[5])
text = categories[5] + str(pre[0][5]*100) + "%"
font = cv2.FONT_HERSHEY_PLAIN
cv2.putText(stream.array,text,(rect[0],rect[1]-10),font, 2, color, 2, cv2.CV_AA)
cv2.imshow("Show FLAME Image", stream.array)
time.sleep(0.4)
k = cv2.waitKey(1)
if k == ord('q'):
break
# streamをリセット
stream.seek(0)
stream.truncate()
cv2.destroyAllWindows()
##5.動かしてみる
実際にRaspberry Piカメラで、対象人物とそうでない人物を映してみます。
まずはそうでない人。
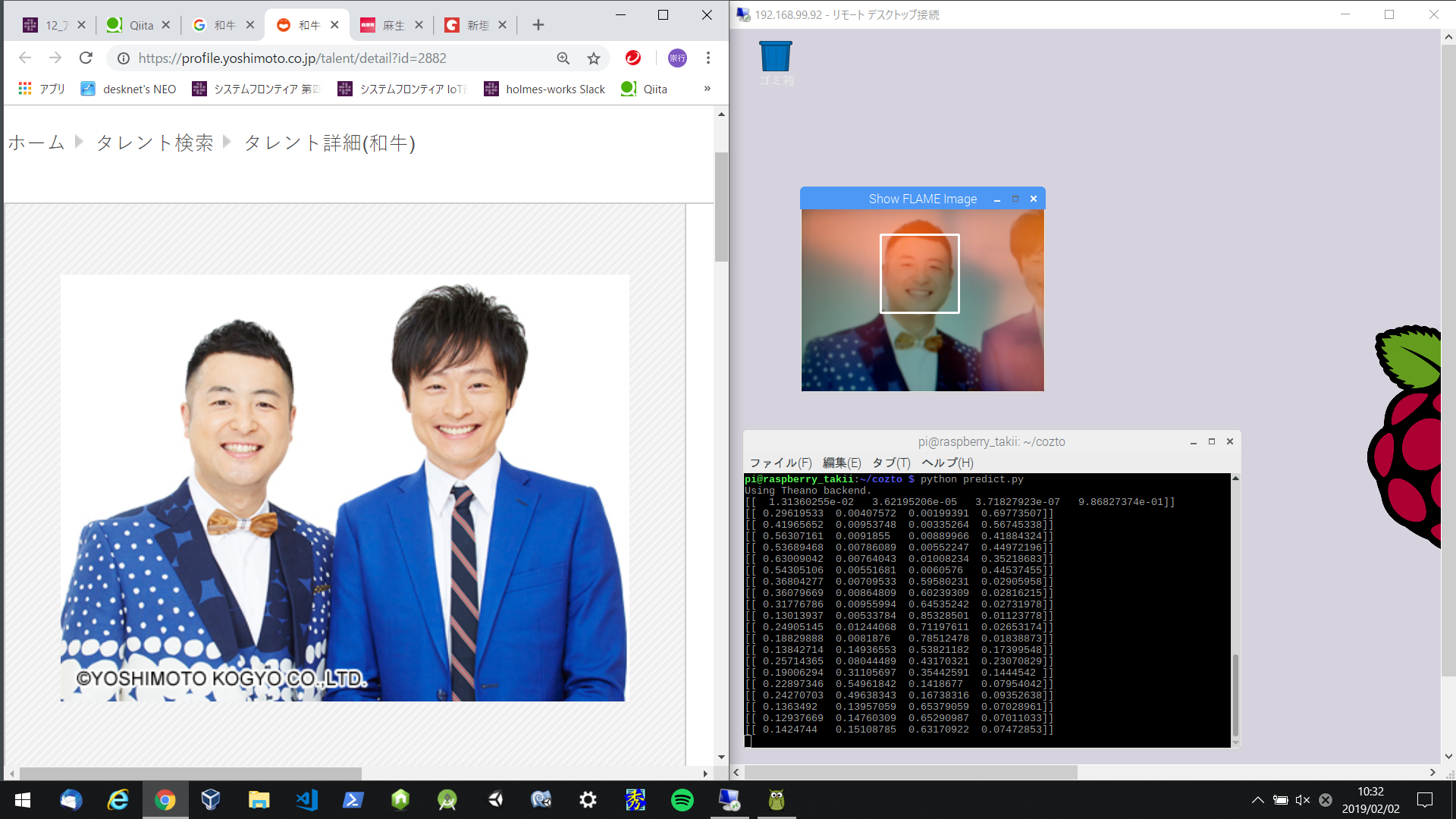
画像の左半分が被写体、右半分がRaspberry Piのデスクトップです。
顔がどこかは認証してますが、スルー。
次に、対象人物を映します。
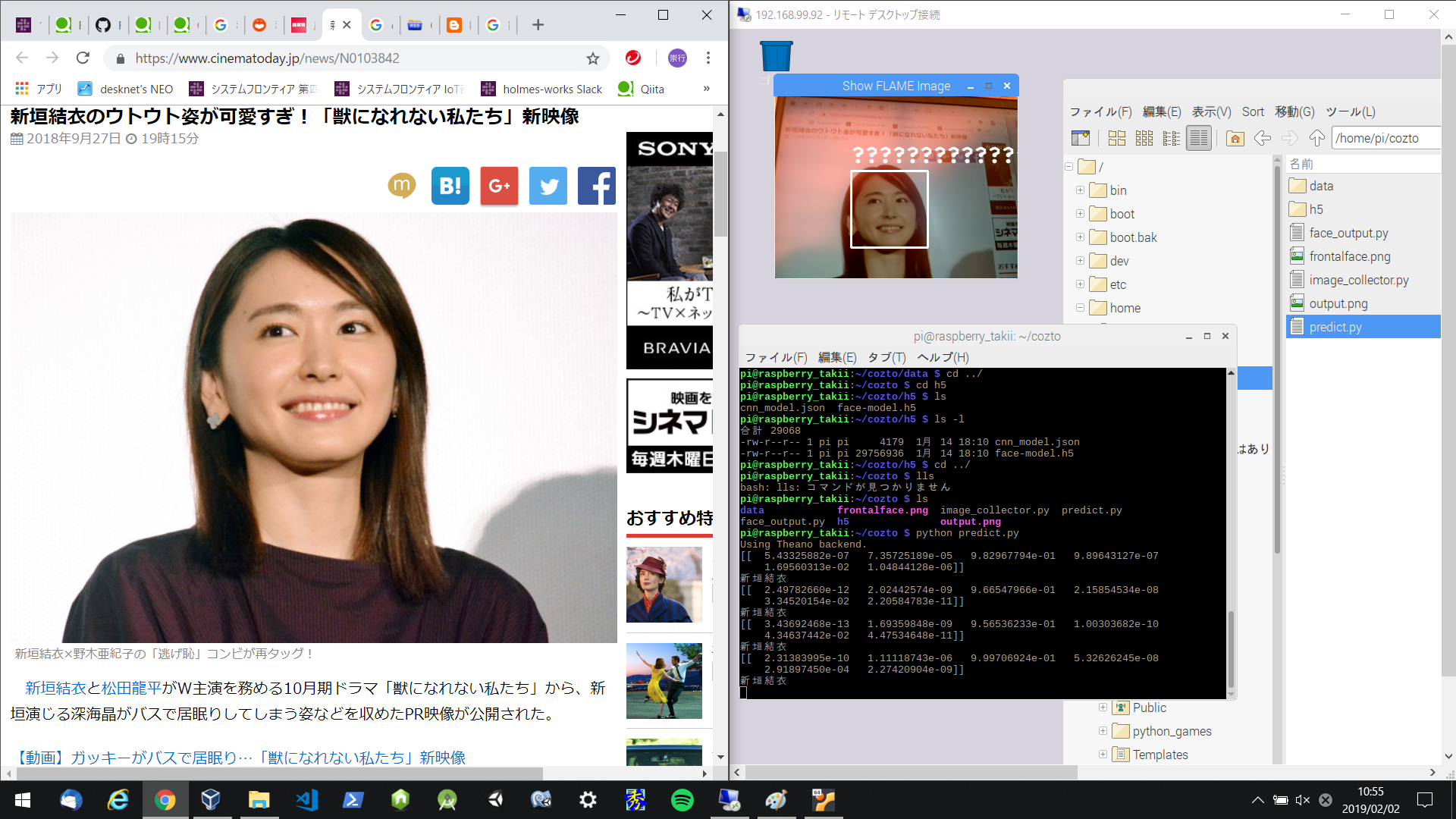
ラベルを日本語にしたので「????」に化けてますが、しっかり認証できてます。
1号機としてはいい感じですねっ![]()
##6.今後
Raspberry PiでPredict.pyを動かしたあと、初めて顔を認証しようとすると十数秒固まります。
あとは見ていただいた通り、日本語対応が必要です。
このあたりを改善していきたいですね。
##リンク
AIエンジニアを目指してみる
Sony Neural Network Consoleで学習の途中出力結果を確認する