概要
大量データに関するワークロードを、モノリシックに解決する場合、並行・並列処理の知識は活用できます
但し、一般にPythonにはGILが存在するため、正しい挙動を抑えておきたい所です
内容
Pythonにおける並行処理・並列処理
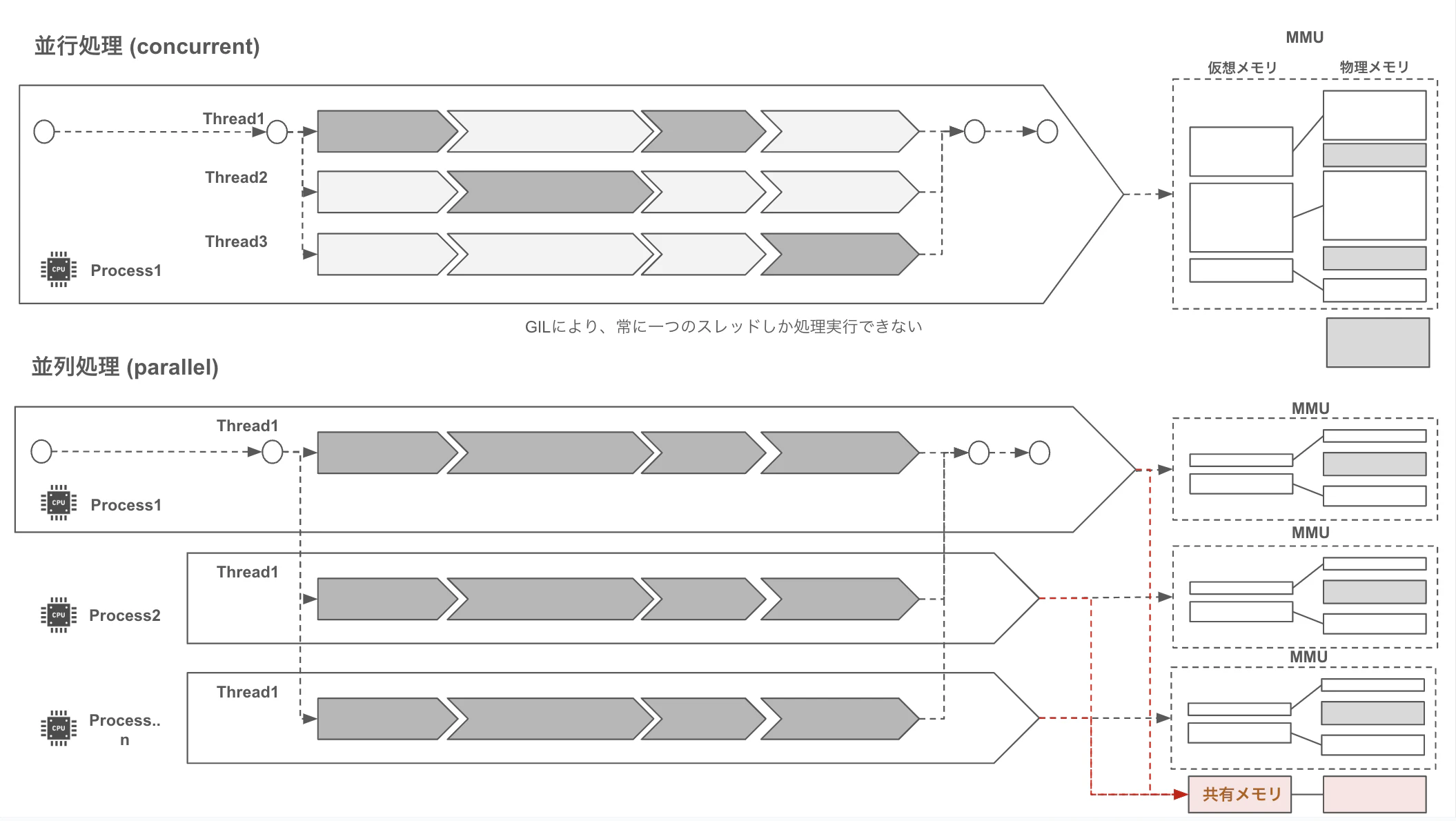
- プロセス = OSが管理する実行単位 (CPUコア毎)
- スレッド = プロセス内の軽量な実行単位 (1CPUコア内)
上記前提を踏まえると、以下となります
- 並行処理 = 1つのプロセスに複数のスレッドが存在します (PythonはGILにより基本1プロセス制約です)
- 並列処理 = 複数のプロセスを並行して進めます (複数プロセス活用できます)
MMU (Memory Management Unit)に関して
プロセスから参照するメモリはMMUにより制御された仮想メモリを参照します。MMUによりプロセス間ではメモリ競合は起きません
(1プロセス ≒ 1CPUコアであり ≠ 1CPUなので、有難い制約です)
これは並列処理に貢献します
一方、並行処理では同一MMU内のメモリを複数スレッドが参照する為、競合が発生するケースがあります
誤った解釈として、PythonはGILなので、競合は起きないという誤解がありますが
スケジューラにより、実行スレッドが切り替わる際、前後にて同一のメモリに対する操作を行うケースなどは、race conditionは発生し得ます
スレッドは所謂mutexとして機能しないことに注意が必要です
データ共有に関して
並列処理を行う際、メインプロセスからサブプロセスを生成し、データを共有します
その際、内部的には必要なオブジェクトをpickle化 (serialization)して渡します
並列処理を扱う条件として、pickle化可能なオブジェクトのみを渡す必要があります
この処理は重く、オーバヘッドが大きい為、場合によっては並列化しない方が速いケースも存在する事に注意が必要です
一方、共有メモリを用いて受け渡す方法もあります
この場合、共有メモリ内の参照を渡すことで、上記オーバヘッドへの対策とします
標準ライブラリ対応表
| 並行 | 並列 | 備考 | 導入ver | ||
|---|---|---|---|---|---|
| 1 | o | - |
concurrent.futuresの方が優れているので、覚えなくても良い |
1.x | |
| 2 | o | - | (同上) | 2.7 | |
| 3 | concurrent.futures.ThreadPoolExecutor | o | - | futureパターンを踏襲。比較的よく見かける並行処理 | 3.2 |
| 4 | concurrent.futures.ProcessPoolExectuor | - | o | 比較的よく見かける並列処理 (単体では共有メモリが使えない) |
3.2 |
| 5 | multiprocessing.Process | - | o | 共有メモリが使える 生成コストは低いが、実行する関数毎にオブジェクトが作成されるので、メモリを消費しやすい |
2.6 |
| 6 | multiprocessing.Pool | - | o | 共有メモリが使える 生成コストは重いが、worker数毎にタスクを順次処理、オブジェクト作成し、終わればQueueにある次のタスク開始するので、オブジェクト数が膨張してメモリを消費しない |
2.6 |
| 7 | asyncio | o | - | Node.js的な非同期IO | 3.4 |
- 個人的な所感としては、項番3,4の
concurrent.futuresがデファクトかと思います。IFがシンプルで扱いやすいですし、単純な操作であれば、並行・並列、共に対応できます- 但し、弱点として並列処理において、単体では共有メモリが使えないので、利用する場合は項番5,6の
multiprocessingライブラリと組み合わせる必要があります
- 但し、弱点として並列処理において、単体では共有メモリが使えないので、利用する場合は項番5,6の
- 項番7の
asyncioは比較的新しいです。非同期IOはサーバアプリケーションにおけるマルチスレッドにおけるC10K問題への対策として有名になったシングルスレッドでの制御方式であり、処理をスレッド数で分散するのではなく、時間軸で分散する概念となります- 例えば、
Uvicorn -> (ASGI) -> FastAPIの様な構成ではasyncioを介して非同期で動作するのが前提なので、サーバサイドにおける並行処理に関する開発では必要な知識となります
- 例えば、
以下は、concurrent.futuresをベースに検証を進めます
速度検証 (プロファイリング)
並列・並行処理を導入することで解決したい課題は主に2種類に分割できます
- IO Bound = 処理の実行時間がI/Oに依存
- CPU Bound = 処理の実行時間がCPUの計算速度に依存
IO Boundには並行処理、CPU Boundには並列処理が向いているとされています
例えば
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor, as_completed
from line_profiler import LineProfiler
import time
以下の様にIO BoundとCPU Boundの処理を用意したとします
def IOBoundedTask(i):
print(f"IO Bound: {i}")
time.sleep(1) # 擬似的にsleepとする
return i
def CPUBoundedTask(i):
print(f"CPU Bound: {i}")
result = sum(range(10**8)) # CPUを消費する擬似的な処理
return result
concurrent.futuresを利用する場合の並行・並列処理の例です
def concurrent_task(task, num_workers):
with ThreadPoolExecutor(max_workers=num_workers) as executor:
futures = []
for i in range(4):
futures.append(executor.submit(task, i))
results = [future.result() for future in as_completed(futures)]
print(len(results))
def parallel_task(task, num_workers):
with ProcessPoolExecutor(max_workers=num_workers) as executor:
futures = []
for i in range(4):
futures.append(executor.submit(task, i))
results = [future.result() for future in as_completed(futures)]
print(len(results))
以下の様に実験条件を設定し、プロファイリングを行います
def main():
# 2x
concurrent_task(IOBoundedTask, num_workers=2)
parallel_task(CPUBoundedTask, num_workers=2)
# 4x
concurrent_task(IOBoundedTask, num_workers=4)
parallel_task(CPUBoundedTask, num_workers=4)
# ineffective use
parallel_task(IOBoundedTask, num_workers=4)
concurrent_task(CPUBoundedTask, num_workers=4)
# https://stackoverflow.com/questions/24374288/where-to-put-freeze-support-in-a-python-script
if __name__ == '__main__':
profiler = LineProfiler()
profiler.add_function(main)
profiler.runcall(main)
profiler.print_stats()

Timer unitはナノ秒なので、Timeと掛け合わせて考えると
2x, 4x
- 4xの方が、
concurrent,parallel共に実行時間は削減されています (効果的な使い方)
ineffective use
-
concurrentにおけるCPUBoundedTaskは明確に意味がなく、%Timeから見ても明らかに効果は薄いです -
parallelはpickle化のオーバヘッドが少なく、意外と時間は削減できましたが
大量I/Oを並列実行する際などを想定し、検証条件を変更すると、concurrentでIOBoundedTaskを行うケースとの差は明確になると思います
参考
Web
Pythonの並行処理/並列処理を学ぼう
Pythonの並列処理・並行処理をしっかり調べてみた
Node.jsの非同期I/Oについて調べてみた
総括
雑ですが、整理してみました
並行処理に関しては、競合はバグの温床となり、機能要件に影響するので、正しい理解が必要だと思いました
並列処理に関しては、別のアプローチとして、インフラ側で分散構成を取る回避策もあります。但し、保守性の観点ではどちらも良し悪しあると思います
以上