はじめに
この記事は「LLM・LLM活用 Advent Calendar 2025」16日目の記事になります。
今年も変わらずLLMをはじめとした生成AIが人気ですね。ただ、皆さんはLLMをゼロから作ったことはあるでしょうか。
この記事では、自宅のPC環境 (RTX3060) でLLMをゼロから事前学習させて構築することに挑戦しましたので、そこで得られた知見を共有します。
LLM構築の流れ
LLMを自作する場合、主にPre-Training、Supervised Fine-Tuning、RLHFの順で学習を進めていきます。

中でも最も大きい学習となるのが、Pre-Training (事前学習) です。ChatGPTやClaudeなど有名なモデルはこの事前学習に多額のコストと時間をかけています。
個人で事前学習からLLMを構築したいとなった場合、一般的な家庭のPC環境でこのような大規模学習を行うのは現実的ではないため、基本は後述する継続事前学習を行うことが多いです。しかし、今回は自宅PCのRTX3060を活用し、あえてゼロからの事前学習に挑戦してみることにしました。
事前学習
作業フロー
事前学習では、以下の手順で学習を進めていきます。
- コーパスの準備
- トークナイズ
- チャンク化
- モデル設定
- 学習
1. コーパスの準備
コーパスとは、言語モデルを構築するために学習させるテキストデータセットのことを指します。今回は、Hugging Faceにある青空文庫のデータセットを使用しました。
2. トークナイズ
トークナイズとは、読み込んだコーパスのテキストに対し、トークンという形に置き換える処理のことを指します。使用するトークナイザーによって精度が大きく変わってくるため、トークナイザーの選択は重要なポイントの一つです。
今回は、LLM-jpが公開しているllm-jp-13b-v1.0という日本語テキスト向けに最適化されたトークナイザーを利用しました。
3. チャンク化
チャンク化は、トークンに変換したテキストを学習しやすいように適度な長さに分割する処理のことを指します。
今回は、2のトークナイズと合わせて1つの関数で処理を行いました。最初はそのままデータを丸ごと渡して処理をさせてみたのですが、32GBのメモリがあふれてしまったため、ストリーミング処理を行う形にすることで対応しました。
def gen_chunks():
buffer = []
print("Tokenizing & chunking...")
for item in tqdm(raw_dataset):
ids = tokenizer(item["text"], add_special_tokens=True)["input_ids"]
buffer.extend(ids)
while len(buffer) >= block_size:
chunk = buffer[:block_size]
buffer = buffer[block_size:]
yield {
"input_ids": chunk,
"attention_mask": [1] * len(chunk),
"labels": chunk
}
dataset = Dataset.from_generator(gen_chunks)
dataset.set_format(type="torch")
4. モデル設定
今回は、GPT-2 smallを参考にしたアーキテクチャで学習を行いました。継続事前学習ではなくゼロからの事前学習を行いたいので、この処理によって重みも初期化しています。
今回のモデルの場合、おおよそ135Mパラメータのモデルとなりました。
config = GPT2Config(
vocab_size=tokenizer.vocab_size,
n_positions=1024,
n_ctx=1024,
n_layer=12,
n_head=12,
n_embd=768,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
model = GPT2LMHeadModel(config)
model.resize_token_embeddings(tokenizer.vocab_size)
5. 学習
ここまで来たら、いよいよ学習に入ります。
epoch数について、参考にした情報では5~10epochほど回すとよいとされていたため、今回は5epochとしました。
また、gradient_accumulation_stepsを設定することによる勾配累積によってメモリを削減しています。
加えて、混合精度演算 (fp16) をTrueとすることでもメモリ削減を図りました。
training_args = TrainingArguments(
output_dir="./model/checkpoint",
num_train_epochs=5,
per_device_train_batch_size=2, # RTX3060対応
gradient_accumulation_steps=8, # → 実質 batch 16
learning_rate=2e-4,
warmup_steps=1000,
lr_scheduler_type="cosine",
fp16=True, # 混合精度演算
logging_steps=500,
save_steps=2000,
save_only_model=True,
report_to="none",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()
学習結果
今回の実行では5epochを約21時間かけて学習しました。GPUの占有量は6GB程度でした。
学習におけるLoss曲線を見ると、一見順調に学習が出来ているように見えます。ただ、右下の下がり切ったLossの値でも3をわずかに下回る程度で、十分下がったとは言えない程度でした。
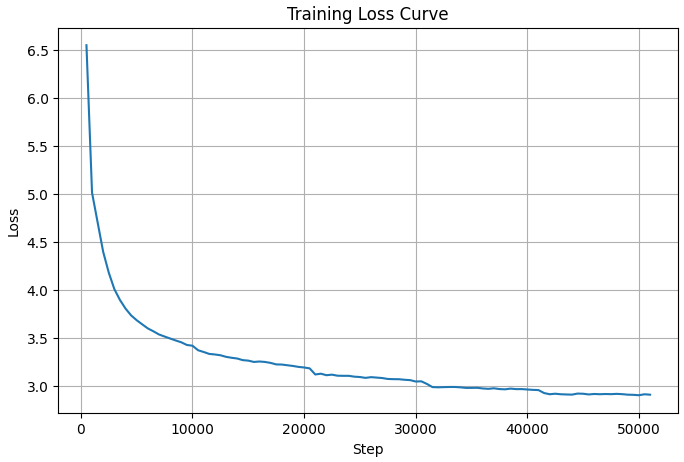
実際に推論を行ってみたところ、日本語の文字は出力が出来ているものの、単語や意味のある文章は生成出来ていませんでした。
prompt = "夏目漱石は"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.3,
repetition_penalty=1.2,
no_repeat_ngram_size=3,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
)
print("\n===== 推論結果 =====")
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
===== 推論結果 =====
夏目漱石は leads clarity新体操尾翼 conductorDEMOopoulos CategoryWed escapeっちり市道 Wie provider寝台 Securities読者繋が周り甦機能まわる Gut洗剤 shortagebli三輪
何度かモデルアーキテクチャを変更したりパラメータ調整などをして学習と推論を試しましたが、あまり改善はせず、自宅環境と今回のデータセットではこれが限界に近いと感じました。
継続事前学習を試す
ゼロからの事前学習の精度が明らかになったところで、継続事前学習ならどうなるだろう?と思い、試してみることにしました。
継続事前学習(Continual Pre-Training)とは、既存の事前学習済みモデルに対して、大量の未ラベルテキストを追加で学習させることでモデル全体の言語能力を再更新する手法です。特定タスクのデータでモデルを微調整する「ファインチューニング」とは異なり、モデルの基礎的な知識や文体そのものを変化させる点が特徴です。
変更点
変更点として、今度はGPT-2 smallの重みをそのまま利用する形にしました。
また、合わせてトークナイザーもgpt2を使用することにしました。重み付きモデルを使う場合は、学習時と同じトークナイザーを使う必要があります。トークナイザーが違うと、同じ言葉でも違う番号(token ID)に変換されてしまいます。モデルは「この番号はこの意味」と覚えて学習しているため、番号がズレるとまったく別の単語として扱われてしまいます。結果、正しく学習できなくなるため注意が必要です。
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
model = GPT2LMHeadModel.from_pretrained("gpt2")
training_args = TrainingArguments(
output_dir="./model/checkpoint-continual",
num_train_epochs=3,
per_device_train_batch_size=4, # RTX3060対応
gradient_accumulation_steps=8, # → 実質 batch 32
learning_rate=2e-5,
warmup_steps=1000,
lr_scheduler_type="cosine",
fp16=True, # 混合精度演算
logging_steps=50,
save_steps=500,
save_only_model=True,
report_to="none",
)
学習結果
今回の実行ではバッチサイズを大きくし、3epochを約23.5時間かけて学習しました。GPUの占有量は10GB程度でした。
学習におけるLoss曲線を見ると、順調に学習が出来ているように見え、値も2.1近くまで下がりました。
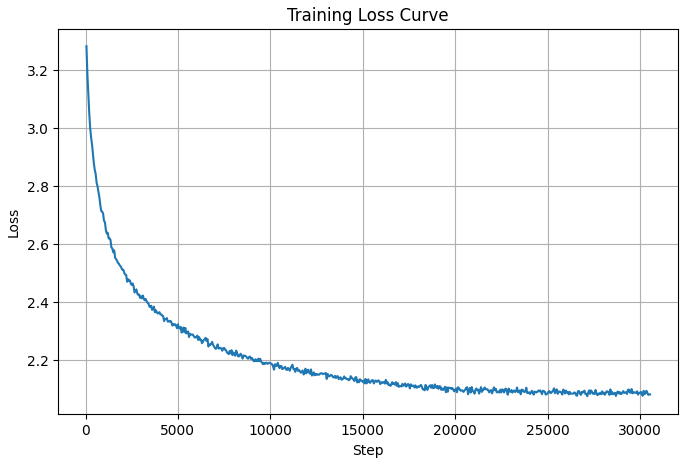
先ほどと同様推論を試したところ、文脈を考慮するところまでは出来ませんでしたが、意味のある日本語を出力できるようになりました!
prompt = "吾輩は猫である"
===== 推論結果 =====
吾輩は猫である。
猫というものは、世界では、素朴ではない。人間は猫というものであるが、それでは、自分であるとしても、そういうようなわけではない。
そして、猫が、そ
ただ、英語の入力を与えたところ、GPT-2 smallの継続事前学習を行っていないモデルでは英語で意味のある回答が出来ていたのが、学習後は出来なくなっていました。
これは、学習によるドメイン適応によって日本語に最適化された一方、破滅的忘却によってモデルの重みが日本語データで上書きされ、英語の知識が忘れられたのではないかと考えています。
prompt = "How was your day?"
===== 推論結果 =====
How was your day?
山蔵風の兄の角をやつて
あゝあゝあゝつとしたまへで
衣類のあひまに角に殺されたやうに
あゝあゝつとしたまへで
推論結果の比較
ここまでで実施した追加学習なしのGPT-2、ゼロからの事前学習、継続事前学習の推論結果を比較すると、表のようになりました。
追加学習なしの状態では英語に最適化されているため、英語のプロンプトには英語で返せていますが、日本語になると意味のないひらがなの羅列となっています。一方、ゼロから事前学習したモデルでは依然として意味のない羅列ですが、漢字が出現するようになっており、日本語を学習しつつあることが伺えます。そして継続事前学習では、日本語のプロンプトに対して文章に近い単語の組み合わせが返せている一方、英語での応答性能は大きく低下していました。
| プロンプト | 追加学習なしのGPT-2 | 事前学習モデル | 継続事前学習モデル |
|---|---|---|---|
| 今日はどんな一日でしたか? | いほうが、としています。である、すね。 | 成り独占婦YuOrientation制裁recurrecur閉ま叉 woolflgボルボ繰入江潜水パワフルドーン eggsシネマ | それにしても、こんなことはありません。「そんなことは、疾くはないでしょう?」 |
| 吾輩は猫である | 猫を、日本の才を時間により、それは、それが、それはない。 | Current不可能きたIDOLアブラBYTEHO絶縁コント relegatedTotal成りきたられる羊判定tune業界rsアーノ | 猫というものは、世界では、素朴ではない。人間は猫というものであるが、それでは、自分であるとしても、そういうようなわけではない。 |
| How was your day? | I'm gonna be sitting on the couch, eating a meal, and I'm just like, "Oh my god, this is really good." I'm like, "Uh-huh. OK. | 幹線Hello thermo本紀 reissue直系 aom Councillor massiveHASHopoulos体裁吉岡 | 山蔵風の兄の角をやつて あゝあゝあゝつとしたまへで |
まとめ
自宅のPC環境でLLMの構築に挑戦した結果、ゼロからの事前学習では日本語の羅列は出来るようになったものの、文章の生成までは出来ませんでした。一方、継続事前学習を行うと、ある程度の文章生成は出来ることが分かりました。
今回の検証を通じて、LLMをゼロから作ることの難しさと、継続事前学習の有効性を実感することができました。
本記事が、これからLLMの事前学習に挑戦してみたいという方の参考になれば幸いです。