はじめに
prometheus Advent Calendar 2017、16日目の記事です。
みなさん Prometheus はお使いですか?いいですよね、Prometheus。
データをじゃんじゃん集めて、自由にクエリをしながら怪しい動きを見つけた時の喜びったらありません。
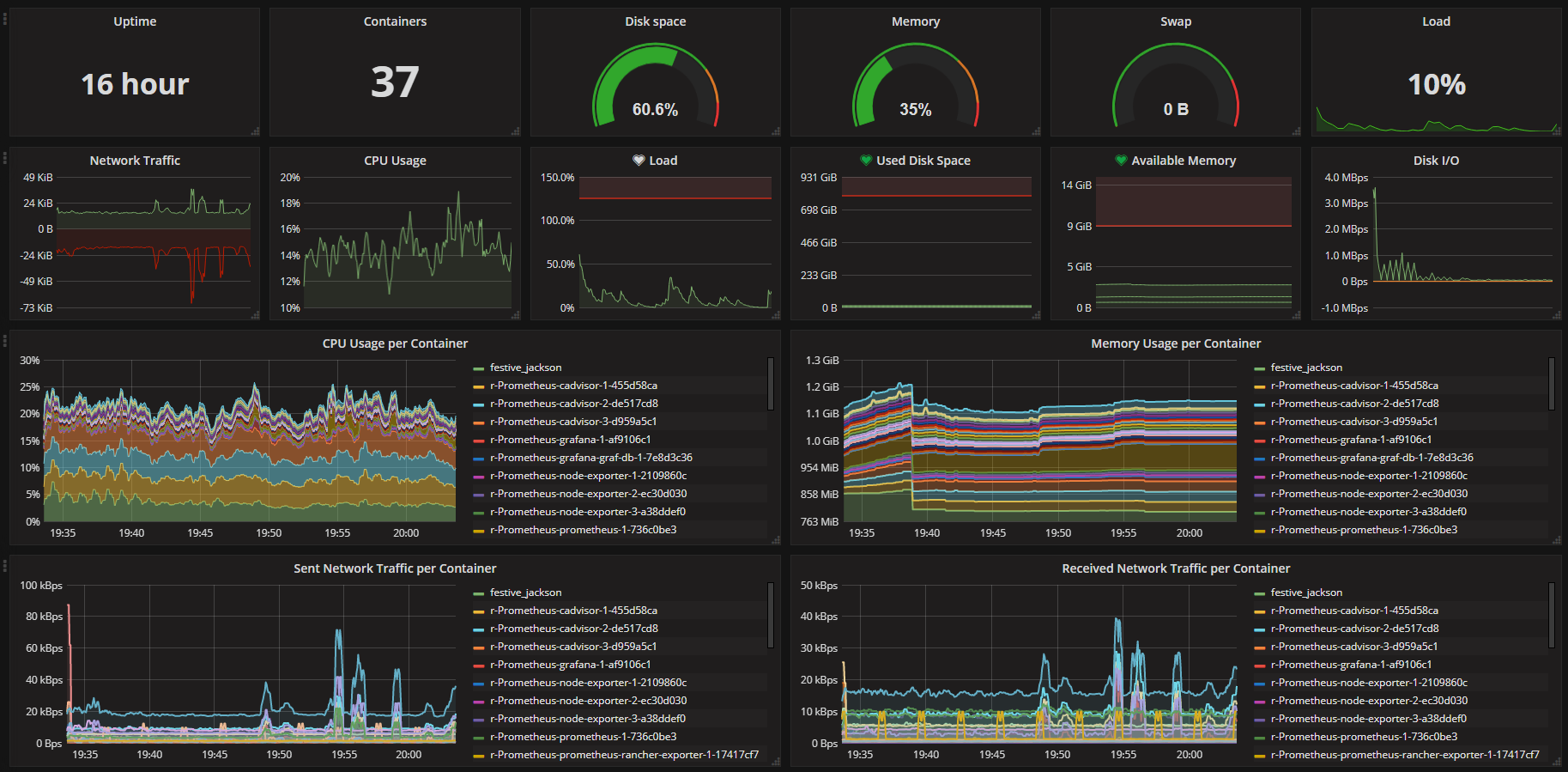
どうでしょうか、この「何が何だかわからないが、 なんだかすごい 」感は。
この鮮やかさたるや、さながら現代のIT曼陀羅と言っていいでしょう。
Prometheusへ蓄積した様々なメトリクスの参照は、 PromQL という独自のクエリ言語を用いて行います。
慣れてしまえばそこまで悩むようなものではないのですが、時系列のメトリクスを縦横無尽に探索するため、クエリ道場で基本から学んでみたいと思います。
「Prometheusってそもそも何なの?」っていう方は
という素晴らしい資料があるためまずこちらに目を通してみてください。
環境について
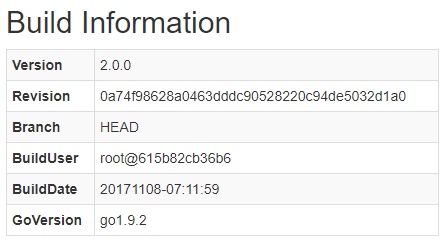
この記事で使うPrometheusは ver.2.0 です。
動作中のバージョンはPrometheusの [Status] -> [Runtime & Build Information] -> [Build Information] から以下のように確認できます。
構築準備の手順については prometheus Advent Calendar 2017、1日目の
で環境構築が可能ですので、試してみたい方はこちらの記事を参考にしてみてください。Dockerのインストールさえできていれば楽勝な感じです。
私自身はRancherの コミュニティカタログ ををベースに、複数台環境でPrometheus 2.0環境を構築しました。
Prometheusはまだまだ成長中のプロダクトですので、ググって見つかる記事のバージョンは割と様々です。
なんとなーくコピペして動かしたら1系だったなんてこともまだ多いと思うので、バージョンにはご注意ください。
もしWebの記事がなんというかにかかわらず最新のものが使いたいということであれば、 prometheus/prometheus - GitHub とか prom/prometheus - DockerHub あたりを見るといいでしょう。
2017年12月16日現在では2.0.0が最新ですね。
1. データを知る
Prometheusでクエリするということは、探したいデータがあるということです。
具体的なクエリを学ぶ前に、どのようなデータがPrometheusで収集できているのかまず大づかみに把握しましょう。
1-1. データ収集設定の確認
PrometheusはPull型のアーキテクチャを採用していますので、サーバ側で収集する(scrapeする)データの情報を持っています。
収集するデータの一覧は [Status] -> [Targets] で確認できますので、一度みてみましょう。
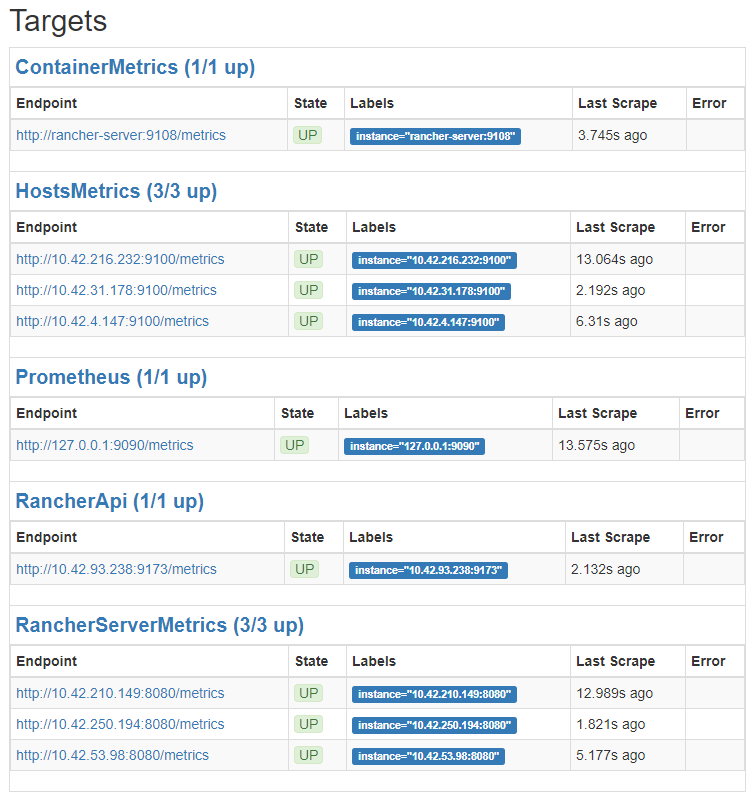
Rancherのコミュニティカタログが既にいくつかのexporterを設定しているため、割と色々なTargetsが見えます。
これは prometheus.yml で定義している scrape_configs の設定によって決まります。
その設定は [Status] -> [Configuration] で見ることができます。
例えば、2つ目に見えている HostMetrics であれば
scrape_configs:
- job_name: HostsMetrics
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
dns_sd_configs:
- names:
- node-exporter
refresh_interval: 15s
type: A
port: 9100
のように定義されているわけですね。
ここで注目してほしいのが、 dns_sd_configs の部分で、上の画像を見てもらうとわかるように、 HostMetrics のターゲットは具体的に3つあることがわかりますが、設定ではどうも3つあるようには見えません。
ここで機能しているのがまさに dns_sd_configs で node-exporter という名前で引けるものを収集の対象にしています。
Targets may be statically configured via the static_configs parameter or dynamically discovered using one of the supported service-discovery mechanisms.
(対象は static_configs で静的に設定されたパラメータか、 サービスディスカバリ 機能で動的にディスカバリされたものを対象とします。)
このように sd というのが service discovery の略だとわかれば、その動きがイメージしやすくなるのではないでしょうか。
dns_sd_config の他にも、 CONFIGURATION のページを見ると
など、結構色々なものをディスカバリしてくれるようです。
1-2. データサンプルの確認
それでは、実際に収集されたデータをいくつか見てみましょう。
簡単なのはPrometheusの画面から適当にクエリを実行してみることです。
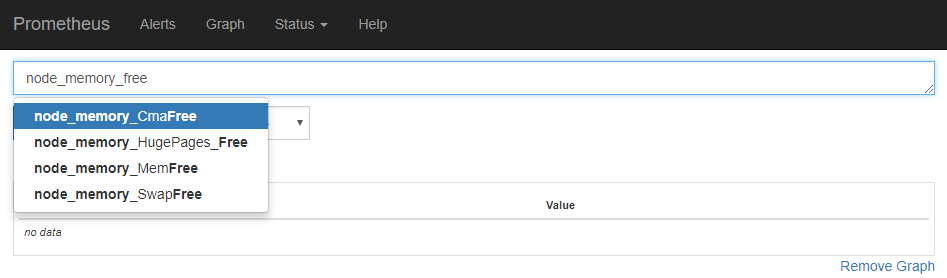
クエリ窓にメトリクス名(の一部)を入力すると、このようにヒットするメトリクスがサジェストされます。
このサジェストが非常に柔軟になっていて、画像の例でいければ「 "node_memory_free" を含むもの」ではなく「n/o/d/e/_/m/r/y/f」の文字を含むものがサジェストに出ていることがわかります。
あとはその候補を選んで、 [Execute] ボタンをクリックすると [Console] タブから実際のデータを確認できることと、 [Graph] タブからグラフを確認できたりします。
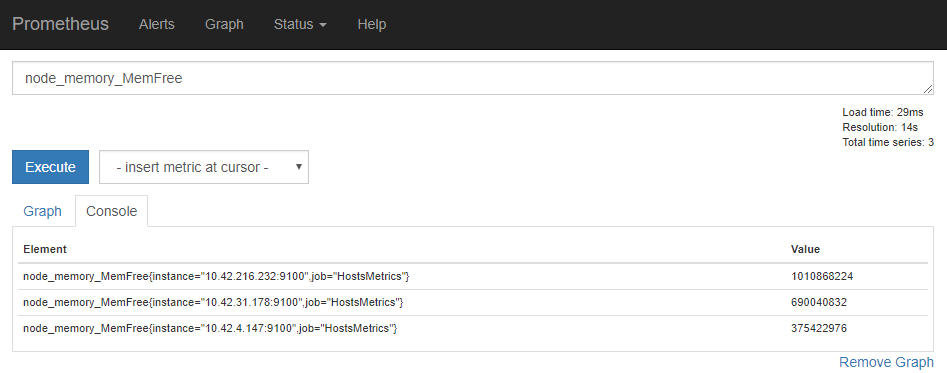
Elementでメトリクス名の後ろに ラベル が色々出てきますが、クエリにおいて重要な点ですのであとで解説します。
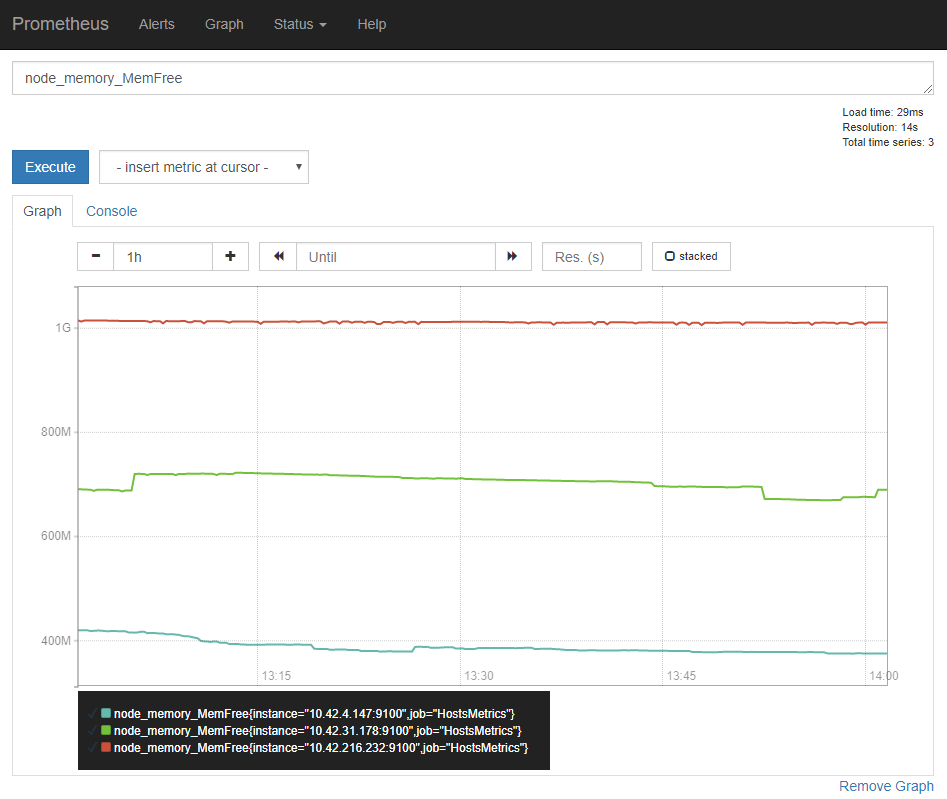
デフォルトの表示は 直近1h のグラフですが、[ - ] [ + ] で表示期間を変えたり、 [◀◀] [▶▶] で表示の起点時刻を変更したりもできます。
他にも、実際にPrometheusコンテナに入り、スクレイプ先のEndpointを参照するなんて方法もあります。
この方法だとまさにそのタイミングで収集されるメトリクスをEndpoint単位で知ることができます。
スクレイプがうまくいっていないときのトラブルシューティングとしてもこれをやったりしますね。
# PrometheusコンテナのIDを調べる
$ sudo docker ps -f name=prometheus
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f4965fc87373 prom/prometheus:v2.0.0 "/.r/r /bin/promet..." 4 hours ago Up 4 hours r-Prometheus-prometheus-1-736c0be3
29e30fcc5a55 infinityworks/prom-conf:19 "/bin/sh" 4 hours ago Up 4 hours r-Prometheus-prometheus-prom-conf-1-1e026d96
# Prometheusコンテナに接続(bashがないのでshにつなぐ)
$ sudo docker exec -it f4965fc87373 /bin/sh
# PrometheusメトリクスのEndpointを参照(curlがないのでwgetを使って標準出力に出している)
$ wget http://127.0.0.1:9090/metrics -qO -
Connecting to 127.0.0.1:9090 (127.0.0.1:9090)
go_gc_duration_seconds{quantile="0"} 2.046e-05
go_gc_duration_seconds{quantile="0.25"} 8.5385e-05
go_gc_duration_seconds{quantile="0.5"} 0.000147534
go_gc_duration_seconds{quantile="0.75"} 0.000350681
go_gc_duration_seconds{quantile="1"} 0.010048808
go_gc_duration_seconds_sum 0.087973045
go_gc_duration_seconds_count 173
(略)
というような感じで、どういうデータが取れているのかをざっと理解することができたと思います。
1-3. データ構造の理解
先ほどデータを簡単に確認したと思いますが、改めてデータを見てみましょう。
この中で3つのデータ(Element)が出ていますが、その違いは node_memory_MemFree の後ろについている { } の中に現れています。
この中に入っているものを ラベル と言い、このデータには instance ラベルと job ラベルがついていることがわかります。
Prometheusではいわゆる時系列データを扱いますが、 DATA MODEL で触れられているように、各データは
- timestamp
- metric name
- label
で識別することになります。
図では3つしか出ていませんが、これは直近データを表示しただけであるため、実際には同じメトリクス、同じラベルであっても以下ののようにデータが積みあがっていることになります。
| timestamp | metric name | label | value |
|---|---|---|---|
| 2017-12-16 11:23:09.456811+09 | node_memory_MemFree | instance="10.42.216.232:9100",job="HostsMetrics" | 1007607808 |
| 2017-12-16 11:23:24.396112+09 | node_memory_MemFree | instance="10.42.216.232:9100",job="HostsMetrics" | 1007247360 |
| 2017-12-16 11:23:39.833171+09 | node_memory_MemFree | instance="10.42.216.232:9100",job="HostsMetrics" | 1007255552 |
| ... | node_memory_MemFree | instance="10.42.216.232:9100",job="HostsMetrics" | ... |
そのため、メトリクスを決めてデータをイメージする際は
- 縦 の広がり: 同じメトリクス/同じ時間だが ラベルの違うもの
- 横 の広がり: 同じメトリクス/同じラベルだが 時間の違うもの
の感覚が重要になります。
2. クエリを知る
それでは実際にクエリを書いてみましょう。
2-1. データを参照する
基本となるのは当然データを選び出すことです。以下のクエリをためしてみましょう。
# インスタンスをどれか1つ指定
node_memory_MemFree{instance="10.42.216.232:9100"}
そうすると、データが絞り込まれ、指定したラベルをもつデータのみが表示されました。
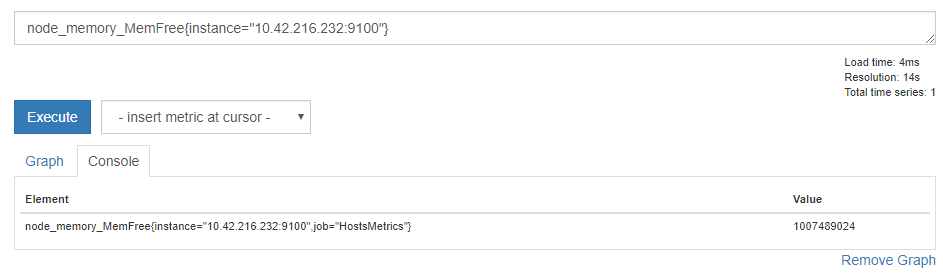
このようにクエリにおいても { } の中にラベルの条件を入れると、そのラベルを持つものだけが返されます。
ラベル条件には正規表現を使うこともでき、 =~ を比較演算子として
# =~ で比較すると正規表現の指定になる
node_memory_MemFree{instance=~"^10.42.*:9100"}
のように書けます。
SQLにおけるWHERE句を { } の中に書いているイメージでしょうか。
なお、PrometheusはGo言語による実装となっているため、PromQLにおける正規表現やエスケープ処理はGo言語のもの( 正規表現 / 文字列 )に準じます。
エスケープで悩んだらGo言語系のドキュメントを読んでみてください。
2-2. データを計算する
続いて、データの計算をしてみましょう。
# 加減乗除(+-*/)
node_memory_MemFree{instance="10.42.216.232:9100"} + 1000
node_memory_MemFree{instance="10.42.216.232:9100"} - 1000
node_memory_MemFree{instance="10.42.216.232:9100"} * 1000
node_memory_MemFree{instance="10.42.216.232:9100"} / 1000
# 剰余計算(%)
node_memory_MemFree{instance="10.42.216.232:9100"} % 1000
# べき乗計算
node_memory_MemFree{instance="10.42.216.232:9100"} ^ 2
データによってはパッと見てスケール感がわかりづらいものもあるかと思いますので、そうした際には桁揃えのために1000倍とか1/1000とかにすることも多いと思います。
また、データ同士の計算をすることもできます。
# TotalからFreeを引くと使用中が出る
node_memory_MemTotal - node_memory_MemFree
# さらにTotalで割ると使用率が出る
( node_memory_MemTotal - node_memory_MemFree ) / node_memory_MemTotal
node_memory_MemUsed みたいなものがあればこんなことはしなくて済むのですが、仮になかったとしてもこのようにデータ同士の計算で簡単に補うことができるのもPrometheusのいいところです。
2-3. データを集計する
関数を使うと、一覧されるデータを集計することができます。
# 最大/最小
max(node_memory_MemFree)
min(node_memory_MemFree)
# 合計/平均
sum(node_memory_MemFree)
avg(node_memory_MemFree)
特にラベルを絞らずにクエリすると3つのデータが出ていましたから、それらに対して「最大」「最小」「合計」「平均」を出しているのが上のクエリです。
先ほどまでの node_memory_MemFree だとデータに芸がなかったので、ここからは node_filesystem_files_free を使います。
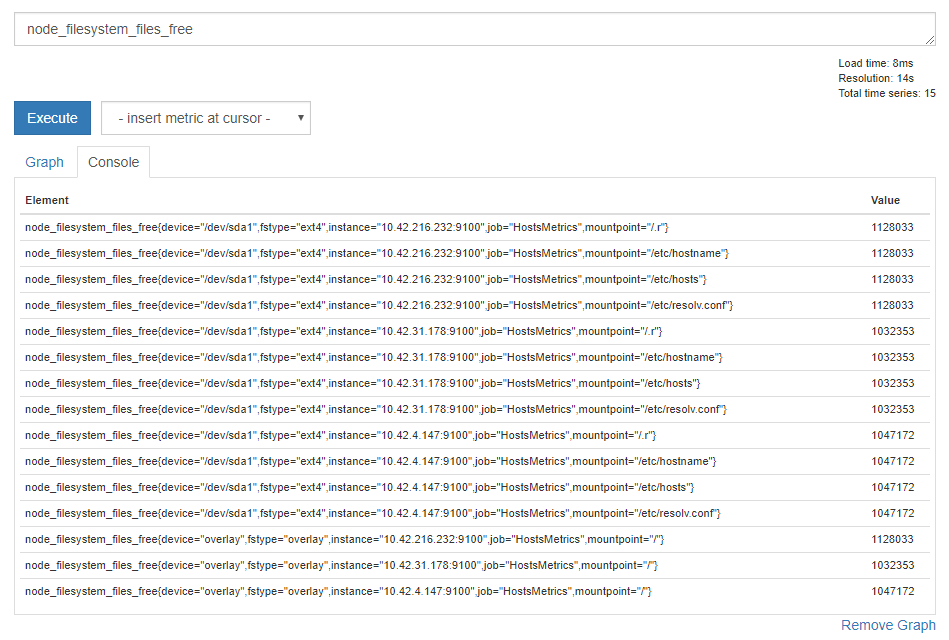
ちょっとバリエーションが出てきました。 fstype でファイルシステムごとに、 mountpoint でマウントポイントごとにデータが出ているようです。
マウントポイントごとにデータを集計してみましょう。
# mountpointラベルごとにmaxの値を集計
max(node_filesystem_files) by (mountpoint)
結果はこのように見えます。
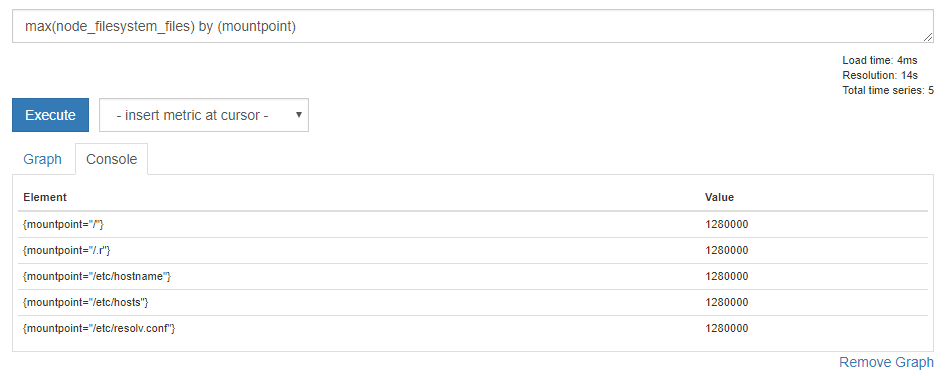
元のデータでは fstype="ext4" と fstype="overlay" が混在していたので分けて表示しましょう。
# mountpointとfstypeラベルごとにmaxの値を集計
max(node_filesystem_files) by (mountpoint, fstype)
結果はこうなりました。集計の結果が fstype を加味して1つ増えていますね。
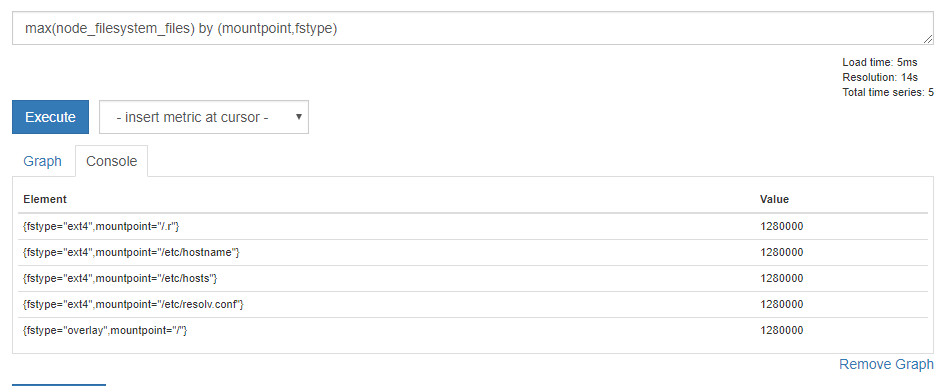
このように、集計対象の範囲は by (ラベル名) で自在に変更することが可能です。
3. 便利な関数を使ってみる
ここまでで
- メトリクス
- ラベル
- 参照
- 計算
- 集計
の考え方やそれを用いたクエリが理解できたかと思います。
ここまでで大体のデータ探索や、それを元にしたグラフ作成ができると思うのですが、Prometheusには便利な関数が色々あるため、それらをいくつか紹介してみます。
3-0. Range vectorとInstant vector
説明を後回しにしていましたが、 Expression language data types にあるように、Prometheusのデータには以下の4種類が規定されています。
- Instant vector
- Range vector
- Scalar
- String (ただし2.0時点では未使用)
ここまでのクエリでは、以下のようにElementごとに1つの値を返すInstant vectorと途中計算に用いるScalarを使ってきました。
# Instant vectorにScalarを足す
node_memory_MemFree + 100
説明していなかったのが Range vector と呼ばれるタイプですが、見てもらったほうが早いので以下のクエリを試してみてください。
# 直近1分間のデータを表示する
node_memory_MemFree[1m]
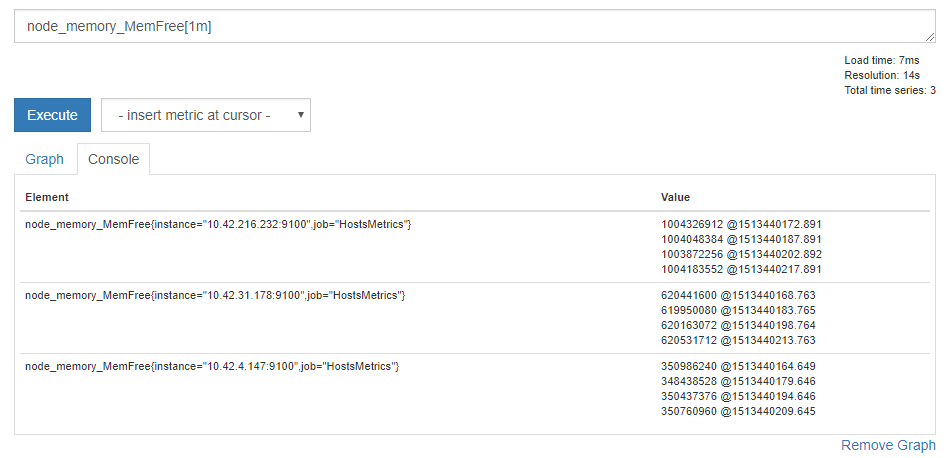
各Elementについて、データが4個出ています。
クエリでは 1m 、つまり1分間を指定していますが、得られたデータは4個のようです。
これは node_memory_MemFree メトリクスのスクレイプ間隔が15秒であることによります。
scrape_configs:
- job_name: HostsMetrics
scrape_interval: 15s ★ここ
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
dns_sd_configs:
- names:
- node-exporter
refresh_interval: 15s
type: A
port: 9100
というように、期間を指定して期間中の一連のデータを取得するのが Range vector と呼ばれるタイプのデータです。
関数の中にはRange vectorを引数とするものも多いため、先に概念を説明しました。
3-1. delta関数
では早速Range vectorを使った関数を説明します。
delta関数では与えられたRange vectorデータの差分を取ることができます。
# 直近1時間での空きメモリ量の差
delta(node_memory_MemFree[1h])
Range vectorでは指定期間中に多くのデータを持ちますが、delta関数はその最初の値と最後の値で差を計算します。
そのため、上記のクエリでは現在の値から1時間前の値を引いて差分を計算していることになります。
今回のクエリ結果がマイナスの場合、「 直近1時間で空きメモリが減少している 」ことが読み取れます。
3-2. rate関数
rate関数は同じくRange valueを対象とし、期間中の平均値に対する現在値の割合を返します。
# idle状態のCPUが直近5分平均に比べてどれくらい増えているか
rate(node_cpu{mode="idle"}[5m])
典型的な例としては公式のサンプルクエリにもある、HTTPのリクエストカウントに使う例です。
# 5分平均のリクエスト数からどれくらい増えているか
rate(http_requests_total{job="api-server"}[5m])
この値を見ていれば、秒間リクエストの増加や減少を見られるようになります。
ちなみに似たような関数で irate 関数がありますが、irateは 期間中最後の2点の平均と現在値 を比較します。
穏やかな局面でrateとirateの動きは変わりませんが、非常に瞬間的なスパイクが存在するとrateが反応できないケースがあるため、irateでは最後の2点を比較対象としているようです。
irate should only be used when graphing volatile, fast-moving counters. Use rate for alerts and slow-moving counters, as brief changes in the rate can reset the FOR clause and graphs consisting entirely of rare spikes are hard to read.
3-3. changes関数
changes関数は与えられたRange vectorの中で、値の変化が何回起こったかをカウントする関数です。
典型的には以下のようにステータスの変更が何度発生したかをカウントするようなケースで利用されるでしょう。
# healthステータスが1時間で何回変化したか
changes(rancher_service_health_status{health_state="healthy"}[1h])
3-4. その他
あとは小ネタのような関数です。結果を微調整する場合や、インタラクティブな調査に役立つ感じです。
- ceil(Instant vector)
-
abs(Instant vector)
- 与えられたInstant vectorの絶対値を返す関数。
-
sort(Instant vector)
- 結果を昇順でソートする。降順ソートは sort_desc 。
おわりに
いかがでしたでしょうか。
全体的なデータの考え方と、基本的なクエリの書き方は理解できたでしょうか。
Prometheusは他にも対数計算を行う log2 関数や、線形回帰を利用した線形予測の predict_linear や微分を行う deriv 関数なども存在します。
クエリ自体でもまだまだ奥が深いことや、それらを用いてどのようにシステムをモニタリングするかということを含め、まだまだ深める余地がありそうです。
クエリの基本を学んだあとのことを考える場合、今回の prometheus Advent Calendar 2017 がよくできていて、
- クエリを使ってダッシュボードを作成する
- 収集データを追加する
というような流れで監視と向き合っていくことになるでしょう。
おわり。