はじめに
prometheusでこんなmetricsとって、grafanaでこんなquery指定すると、こう見えるよの紹介。
始めたばかりで環境準備できたはいいが、ぱぱっとそれっぽいグラフとか出したい人向け。
とりまサーバの状態がいろいろ見えるダッシュボードができるまでの説明を詳しめにします。
notes
- 環境前提にとりま以下入ってること
- (今回はubuntu on EC2 1つにごちゃ入れした)
- prometheus 1.8.2(2.0でないが同様かと)
- grafana 4.6.2、prometheusをdata source登録済み
- node_exporter 0.15.1
- (↑のFirst stepsに手順あり)
サーバの状態いろいろ見えるの
「notes」の準備ができてれば、以下はポチポチすればすぐできます。
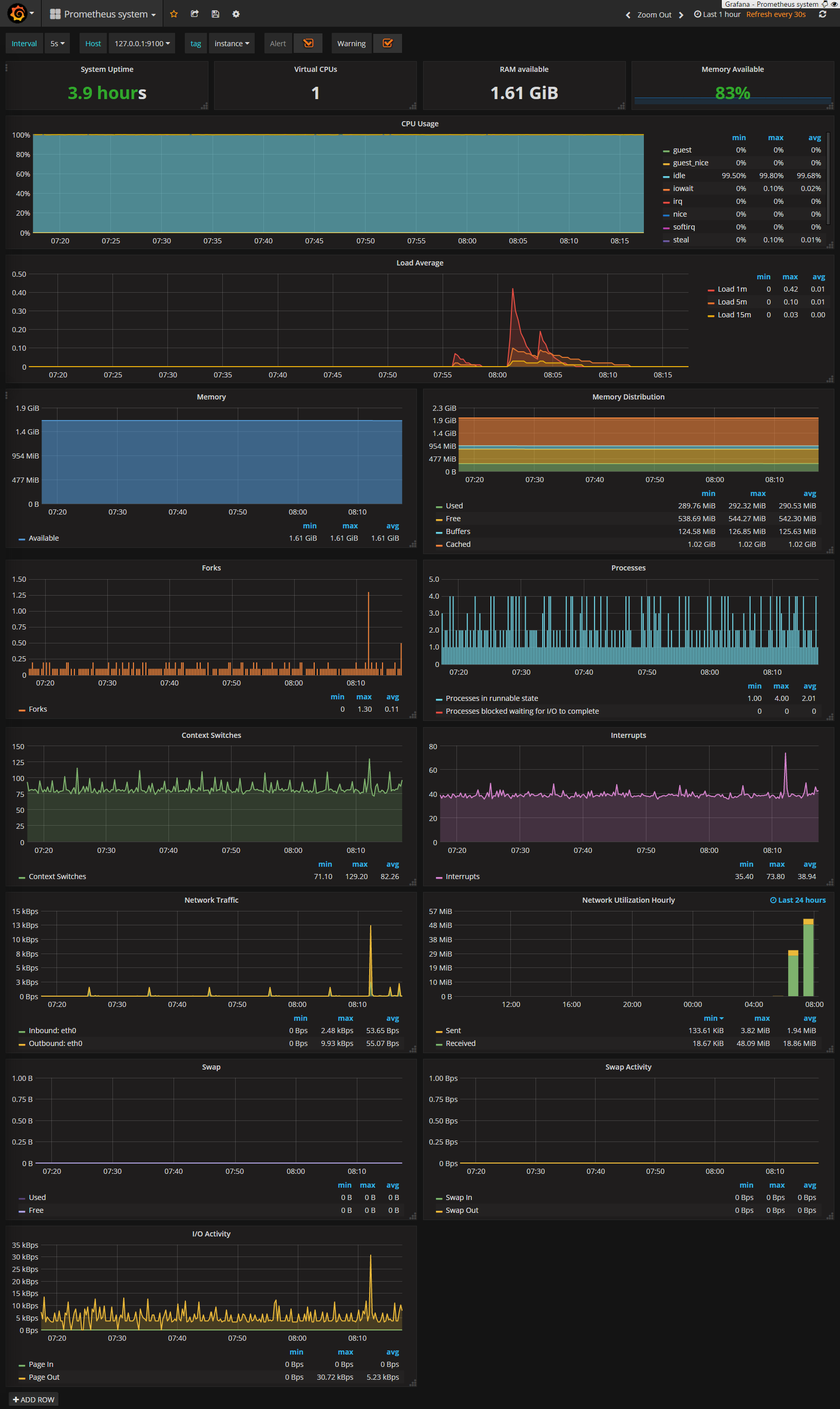
なおダッシュボードの実例として、Grafana LabでprometheusのDashboardを探すのがよいと思います。 スクショもあってイメージしやすく、監視対象のがあるとだいたいそのまま使えます。
またGrafana Pluginsでdata sourceやpanelなども増やせます。
ここではprometheusが動いてるサーバ上で同じくnode_exporterを動かしているので、
-
LabsのPrometheus systemで
Copy ID to Clipboard - 自分のgrafanaをブラウザで開く
- adminログイン
- 左上メニュー->
Dashboards->Import -
Grafana.com DashboardにIDをペースト ->Load -
OptionsのData sourceを自分で足したprometheus選択 -
Importで↑のができます
どう動いているか?
中身の理解のため、Memory Distributionのグラフに注目してみます。
ダッシュボード上グラフタイトルをクリック->Viewでそのグラフだけ拡大でき、さらにEditで以下prometheusのqueryが表示されます。
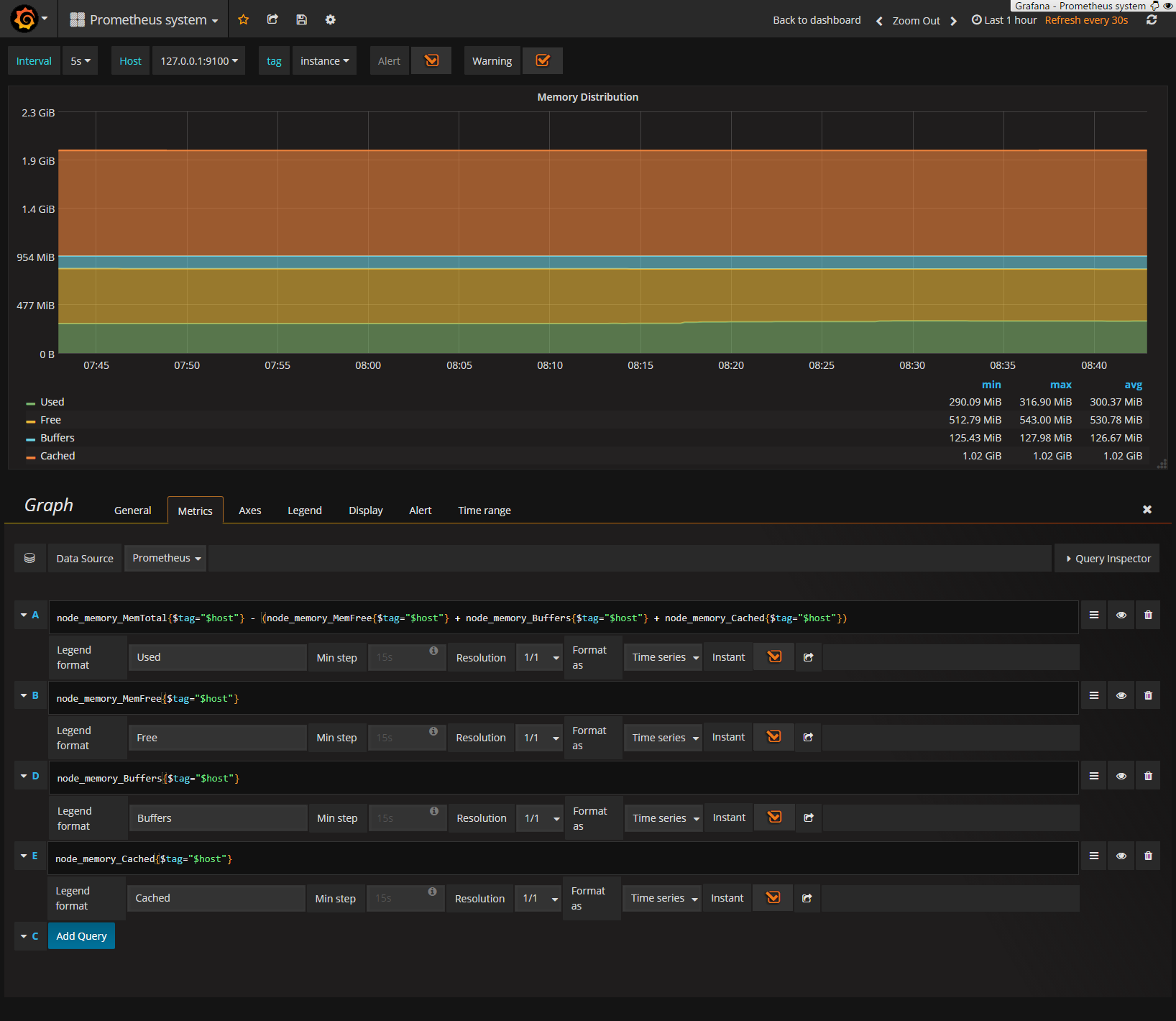
このグラフは4つのqueryで1つのグラフを生成しています。
ここでB行node_memory_MemFree metricに注目すると、prometheus上では、
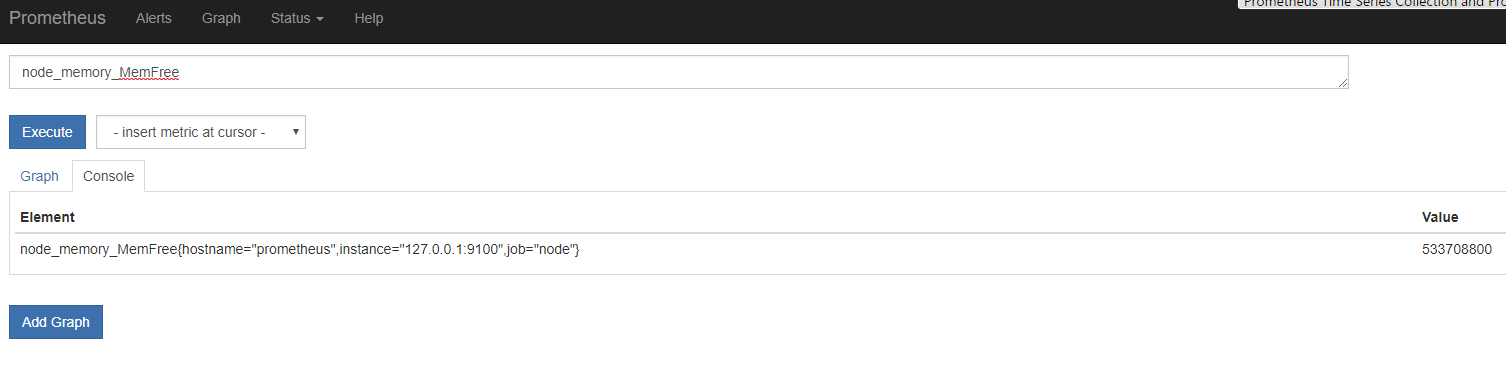
1つのElement(metric name +label) vs. Value情報が保管されています。
prometheus上の画面ではhostnameだjobだとlabelが付与されていますが、これはexporter側でなく、prometheus側で付与されたものとなります。
今回は監視しているnode_exporterが1つですが、もし複数のEC2などを監視する場合、同一metric nameでhostnameなど別labelのmetricが複数できます。
するとGrafana上node_memory_MemFree{$tag="$host"}というqueryになっていることに意味がでてきます。$tag="$host"はGrafana側のtemplatingという機能でサーバが増えてもその分のqueryを自動生成してくれるので、監視対象が増えてもダッシュボードそのものは編集不要となります。
また実際にはnode_exporter側の生のレスポンスはcurlで確認できるので、
$ curl localhost:9100/metrics
...
# HELP node_memory_MemFree Memory information field MemFree. (← metrics説明分)
# TYPE node_memory_MemFree gauge (← metrics type)
node_memory_MemFree 5.35724032e+08 (← metrics名と現在値)
...
とnode_exporterにrequestされた瞬間のmem freeの値を返してるだけです。
metrics typeとはCounterやGaugeのことで公式解説を読むとわかりやすいです。
要はmem free値など現在の値をそのまま代入されるのがGaugeでhttp requestなど単位時間あたりを取得して先の値に加算して欲しい場合などはCounterを使ったり、とmetricsのとり方による違いがあります。
なお、metricsに複数labelがある場合について、先のcurlの結果のfilesystem freeに注目すると、
# HELP node_filesystem_files_free Filesystem total free file nodes.
# TYPE node_filesystem_files_free gauge
node_filesystem_files_free{device="/dev/xvda1",fstype="ext4",mountpoint="/"} 809613
node_filesystem_files_free{device="lxcfs",fstype="fuse.lxcfs",mountpoint="/var/lib/lxcfs"} 0
node_filesystem_files_free{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 255383
node_filesystem_files_free{device="tmpfs",fstype="tmpfs",mountpoint="/run/lock"} 255852
node_filesystem_files_free{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/1000"} 255851
のように{}で囲まれてdeviceやmountpointなどlabelが記載されます。
もしGrafana上でnode_filesystem_files_freeというqueryだけ指定した場合は5つのmetricsがhitするので、それらは展開されて5つ線が表示されたグラフが生成されます。
file system freeのグラフを追加してみる
空いているダッシュボード末尾右下にFilesystem Freeパネルを足してみる。
- graphパネルを追加
- grafana画面で、左側面にマウスを持っていく
add panelgraph
- パネル設定
- パネルの
editで編集画面へ -
Generalタブ
-
Metricsタブ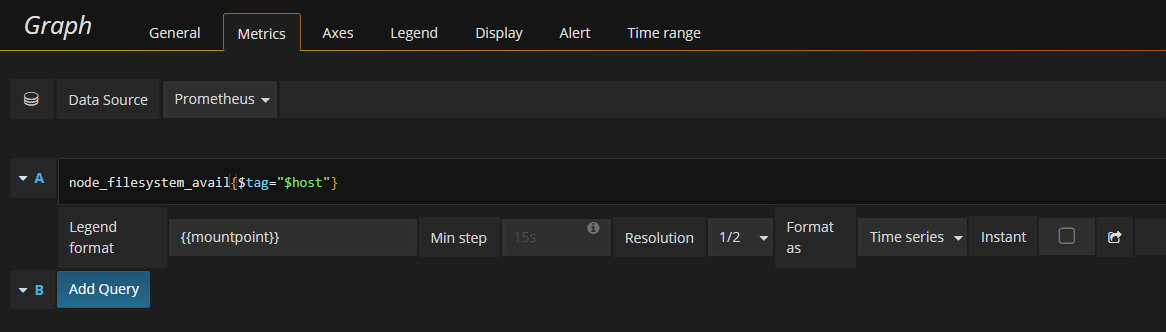
-
Axesタブ
-
Legendタブ
- 終わったら右上の
Back to dashboard - で最後にCtrl-sでダッシュボードの保存を忘れずに
- パネルの
サーバが増えたら自動でダッシュボードも増やすには?
前述の通りダッシュボード側はtemplating機能ですでに準備できているため、
- 増えたサーバにnode_exporterが導入済み
- 増えたサーバのIP:portをprometheusがtargetとして取得
という工程がさらに必要です。
1つ目はchefなりprovisioning段階でいい感じに自動で入れてもらうとして、2つ目はPrometheusのec2 service discoveryを試す - 技術的なメモというか、忘却録+特定のtagをaws上でつけておくと、サーバができれば自動でこの監視ダッシュボードができるようになります(左上のHostで選択)。(prometheus.ymlのtargesにIP:port listを手書きでも増えはする)
おわりに
prometheusは割りと「で、どう使うといいの?」な資料がまだまだないと周りからよく聞くのでとりま紹介系記事を書いてみました。というか本記事はgrafanaでどうグラフを作るかにだいぶ寄ってはいますね...
後述の自作exporterの話もありますが、どういうqueryをgrafanaから叩けばいいか?は慣れるまで結構難しいです。それには実例をあれこれ眺めてquery functionの使い方など理解を進めると良いので、前述のGrafana Labsのダッシュボードサンプル入れてみてその中身を確認していくのがオススメです。
おまけポエム : prometheusでの監視設計
筆がのったのでついでに書きますが、流れとして、
- どう通知が欲しいか? or ダッシュボードで状況確認したいか?
- prometheus上どういうmetricsが保管されてるべきか?
- どう対象をexporterから監視できるか?
- 実装からprometheus alert rule or grafanaからのqueryをどうするか?
と組み立てていきますが、custom exporterを作る場合の制約としてよく気にするのは、
- metrics設計
- 時系列DBとして時間vs.数値に落とし込めるか?
- 連続しているか?
- 監視対象の可変箇所をlabelでうまく表現できるか?
- (sd観点でアラート/グラフ設定を自動で対象増えたら増えるor簡単に変更できるか?)
- 監視先の叩き方
- exporterからアクセスする口はあるか?(NWやapi仕様など)
- どのくらいこまめに監視先を叩いて大丈夫か?
あたりかと思います。
まずは公式writing exportersを読めという話もあります。
prometheusは特にquery functionが豊富なのでmetricsで取るべき値は可能な限り素朴なものにしておき、あとで加工するようにした方がよいかと思います。
また、ミドルウェア監視用途では既存のexporterをいかに使うか?(自分でexporter作らない)という文脈が強く、あまりcustom exporterを作ろうとはならないと思います。
ただ、exporterを自作することに熟れてくると、あるあるシステム構成だけでなく、自社なり独自サービスの監視まで幅を広げられます。
実際ちょっとしたスクレイピングをするbatchを書く程度の手間で作れるので一度作れば結構使いまわしができます。
例えばpythonならclient_pythonのようにある程度の言語でlibraryは準備されてるので。
もっともサービスの謎管理画面など作る際に監視からも叩けるapiなど準備する必要がありますが。そこはサービスとしてマイクロサービス的な組み方であれば、prometheus/alertmaanger/各exporter/grafanaそれぞれと組み合わせるのに相性がよいと思います。
ま、なにはともあれ「おわりに」でも言及した「grafana labでdashbordのサンプルからqueryどうするといいかを漁るとよい」という話と同様、既存exporterコードを写経したりするのが理解を深めるには良さそうです。
以上。