実現したいこと
CSVファイルを読み込んで、すべてのデータを一括で SQL Server に挿入したい
※ 実際に使用したコードの一部は付録にまとめて掲載
追記 2021/09/19
モデルはもっと簡素にできる
背景あるいは動機
- 検証時の初期データが頻繁に変更されるため、コードファーストでシードデータを用意するのが辛い
- PC やら PLC から送り付けられてくるCSVファイルのデータを、データベースに保管しておきたい
似た相談が teratail に投稿されている
何かいい方法はないか、とググっていたら似た質問を見つけた
渡りに船なので、コードを一部拝借する
補足情報
上記 teratail の投稿スレッドから、補足となる情報を抜粋する
・DBはSQL Server Express 2016 LocalDBです
・テストデータがでかいので、手で書くのは無理なので、csvから読みたい
引用元:https://teratail.com/questions/100463
結論
CsvHelperライブラリをつかってモデルのプロパティに[Name()]属性を付与すると
こんな感じ(付録へのリンク)で、CSVを一気にモデルに格納できる
モデルに格納できてしまえば、あとはループでデータベースにAddするだけ
ただし以下の制約がある
CSVファイルの列名が既知であること- CSVファイルの列の並びが既知であること
- 列名で直接指定、または列番号をインデックスで指定できる
- SQL Server に格納するなら、初期データにも主キーと同じ名前の列が必要
- 主キーと同じ名前の列の値はなんでもよい
環境
- Windows 10 Home
- Visual Studio 2019 Community
- .NET 5
プロジェクトに追加した NuGet パッケージ
PM> dotnet list package
プロジェクト 'CSVTableProject' に次のパッケージ参照が含まれています
[net5.0-windows7.0]:
最上位レベル パッケージ 要求済み 解決済み
> CsvHelper 27.1.1 27.1.1
> Microsoft.EntityFrameworkCore 5.0.10 5.0.10
> Microsoft.EntityFrameworkCore.Design 5.0.10 5.0.10
> Microsoft.EntityFrameworkCore.SqlServer 5.0.10 5.0.10
> Microsoft.EntityFrameworkCore.Tools 5.0.10 5.0.10
-
CsvHelperは CSV の読み書きにつかう - EF Core 関連のツールを4つ入れてある
-
Core: 必須コア機能 -
Design: Visual Stduio から SQL サーバを覗き見る -
SqlServer: ローカルの Microsoft SQL Sever と通信する -
Tools: EF Core のコマンドを Visual Studio のパッケージマネージャーコンソールから打つ
-
SQL Server を用意する
Docker コンテナの SQL Server をつかう
データベースの作成から先は、Entity Framework の移行(Migration)をつかって、コードファーストで行う
データベースを作成する
データベースコンテキストを作成し、Add-Migration→Update-Databaseを行う
〈作成されたデータベース〉 Visual Studio の SQL Server オブジェクトエクスプローラーのキャプチャー

データベース感を出すために(?)、1行だけシードデータを与えている
(シードデータを与える手順はこちら)
この初期に与えるデータを頻繁に変更し、かつその列数が多いと辛いので、CSVで渡したい
というのがこの記事のテーマ
そもそも初期データが固定でよければ、EF Core のシード機能で事足りる
データベースコンテキストの全容は付録を参照のこと
モデルをつくる
teratail 投稿者様のコードをベースにモデルを作る
モデルの全容は付録を参照のこと
モデルのプロパティに属性をつける
SQL Server にデータを格納するためには、主キー[Key]が必要なので、Idを追加する
Id以外のプロパティは teratail と同じもの(下画像)を使う

public partial class CSVTable
{
[Key]
public int Id { get; set; }
[Name("月")]
public string Month { get; set; }
[Name("作成日")]
public string CreateDate { get; set; }
[Name("年")]
public string FiscalYear { get; set; }
[Name("タイトル")]
public string Title { get; set; }
[Name("値段")]
public string Price { get; set; }
}
-
[Key]は SQL Server を使うために必要となる -
[Name(" ")]は CsvHelper を使うために必要となる
CSVを読み込む
CSVを読み込んで、読み込んだデータをコレクションとして返すメソッドをつくる
ここでCsvHelperライブラリを活用する
public static IEnumerable<CSVTable> ReadCsv(string csvPath = @"./data.csv")
{
CultureInfo cultureInfo = new("ja-JP");
using StreamReader stream = new(csvPath, Encoding.UTF8);
using CsvHelper.CsvReader csv = new(stream, cultureInfo);
csv.Read();
csv.ReadHeader();
return csv.GetRecords<CSVTable>()
.Select(x => new CSVTable()
{
Month = x.Month,
CreateDate = x.CreateDate,
FiscalYear = x.FiscalYear,
Title = x.Title,
Price = x.Price,
}).ToList();
}
CSVファイルの検証などエラー処理を含む全容は付録を参照のこと
ワンポイントアドバイス
初期データのId列は適当な値を入れていることを前提としているので
new CSVTable(){...}の{ }内で、Id = x.Idのようにプロパティに値を与えないこと
デフォルトでEF Core が主キーIdに対してIdentityを付与してくれるので
Idプロパティは自動的に1ずつインクリメントされて SQL Server に格納される
Id = table.Column<int>(type: "int", nullable: false).Annotation("SqlServer:Identity", "1, 1"),
CREATE TABLE [dbo].[CSVTable] (
[Id] INT IDENTITY (1, 1) NOT NULL,
[Month] NVARCHAR (MAX) NULL,
[CreateDate] NVARCHAR (MAX) NULL,
[FiscalYear] NVARCHAR (MAX) NULL,
[Title] NVARCHAR (MAX) NULL,
[Price] NVARCHAR (MAX) NULL,
CONSTRAINT [PK_CSVTable] PRIMARY KEY CLUSTERED ([Id] ASC)
);
何らかの理由でIdに特定の値を入れたい場合は
主キーであるので初期データのIdの値がそれぞれ重複しないように管理する
読み込んだデータをデータベースに格納する
以下の3手順でデータベースにCSVファイルのデータを格納する
// 1. コンテキスト生成する
Context.CSVTableContext context = new();
// 2. CSVを読み込んでデータベースに格納する
var table= Models.CSVTable.ReadCsv();
foreach (var record in table)
context.Add(record);
// 3. データベースの変更を保存する
context.SaveChanges();
今回は適当に画面をつくって、画面が読み込まれたときに処理を行うようにした
つまり Visual StudioでF5を押せば、都度CSVファイルのデータがデータベースに格納される
雑記
名前がCSVTableのモデルにReadCsv()を置くべきか、その戻り値を受ける変数名はtableでいいのか、など
ここまで書いてきて、いろいろ自分でも引っかかるものはある・・・
実際にコードを実行してみる
実際に CSV ファイルの初期データを用意して、実行F5する
初期データを用意する
Idは初期データとしてデータベースに格納しないが、IdがないとGetRecordsでエラーが出る
(CsvHelperをちゃんと調べれば回避できるかもしれない)
CsvHelper.MissingFieldException: 'Field with name 'Id' does not exist. You can ignore missing fields by setting MissingFieldFound to null.
Id,月,作成日,年,タイトル,値段
0,a0,b0,c0,d0,e0
0,A1,B1,C1,C1,E1
0,aA2,bB2,cC2,dD2,eE2
Id列には、ひとまずInt型でエラーが出ない適当な値を入れる
実行した結果のデータベース
Before (既出)
After
1回実行

2回目実行
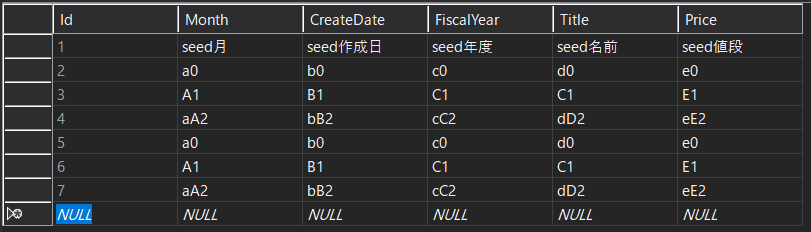
- ちゃんとCSVのデータが反映されている
- CSVファイルの
Id列はすべて0にしたが、モデルには格納していないので、SQL Server のIdは1ずつインクリメントされている
おわりに
CSVのヘッダーが既知であることが制約ではあるものの
コード量少なくCSVデータを SQL Server に格納できた
やり残したこと
本文でも触れたとおり、CsvHelperのことはよく理解しておらず、本領を発揮できていないと思うので
今後、使い方を習得していきたい
(コードの中で消さずにあえてコメントアウトしているところなど)
参考にさせていただいた記事
付録
この記事の検証でつかったコードを一部掲載する
データベースコンテキスト
using Microsoft.EntityFrameworkCore;
namespace CSVTableProject.Context
{
internal class CSVTableContext : DbContext
{
public DbSet<Models.CSVTable> CSVTable { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer("Data Source=\"localhost, 11433\";Initial Catalog=CSVTable;User ID=sa;Password=SqlPass1234");
base.OnConfiguring(optionsBuilder);
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Models.CSVTable>().HasData(
new Models.CSVTable
{
Month = "seed月",
CreateDate = "seed作成日",
FiscalYear = "seed年度",
Title = "seed名前",
Price = "seed値段",
Id = 1,
});
}
}
}
モデル
using Microsoft.EntityFrameworkCore;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using CsvHelper.Configuration.Attributes;
using System.Globalization;
using System.IO;
using System.ComponentModel.DataAnnotations;
namespace CSVTableProject.Models
{
public partial class CSVTable
{
public static void Initialize(DbContext context)
{
// このメソッドは使わない
// 実装は teratail "該当のソースコード" を参照
}
public CSVTable() { }
[Key]
public int Id { get; set; }
[Name("月")]
public string Month { get; set; }
[Name("作成日")]
public string CreateDate { get; set; }
[Name("年")]
public string FiscalYear { get; set; }
[Name("タイトル")]
public string Title { get; set; }
[Name("値段")]
public string Price { get; set; }
public static IEnumerable<CSVTable> ReadCsv(string csvPath = @"./data.csv")
{
// 1. ファイルをチェックする
if (!File.Exists(csvPath))
throw new FileNotFoundException($"File Not Found!! {csvPath}");
if (!csvPath.EndsWith(".csv", StringComparison.CurrentCultureIgnoreCase))
throw new FormatException($"Invalid Extension!! {csvPath}");
// 2. CsvReader を使うための準備
CultureInfo cultureInfo = new("ja-JP");
using StreamReader stream = new(csvPath, Encoding.UTF8);
using CsvHelper.CsvReader csv = new(stream, cultureInfo);
// 3. CSVファイルを読み込む
// csv.Configuration.HasHeaderRecord = true;
csv.Read();
csv.ReadHeader();
//csv.Configuration.RegisterClassMap<CsvMapperKenAll>();
// 4. 読み込んだデータをモデルに詰めて、メソッドの戻り値とする
return csv.GetRecords<CSVTable>()
.Select(x => new CSVTable()
{
Month = x.Month,
CreateDate = x.CreateDate,
FiscalYear = x.FiscalYear,
Title = x.Title,
Price = x.Price,
}).ToList();
}
}
}
モデルを使う側
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Windows;
namespace CSVTableProject
{
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
// 1. コンテキスト生成する
Context.CSVTableContext context = new();
// 2. CSVを読み込んでデータベースに格納する
var table= Models.CSVTable.ReadCsv();
foreach (var record in table)
context.Add(record);
// 3. データベースの変更を保存する
context.SaveChanges();
}
}
}