この記事は何か
自分で書いた過去の記事の中で腑に落ちない箇所があるので
追加で検証し、コードを改善するための記事
対象の記事:
結論にコードの変更前後を記載
追記 20201/09/20
@albireo様からコメントいただき、さらにコードを改善したので付録に掲載する
問題のコード
自分で書いていて、なんか違和感を感じたコード
対象の記事から一部を抜粋して掲載する
public static IEnumerable<CSVTable> ReadCsv(string csvPath)
{
// CSVファイルを読み込んで、レコードをテーブルにして返すメソッド
// --- 中略 ---
// 読み込んだデータをモデルに詰めて、メソッドの戻り値とする
return csv.GetRecords<CSVTable>()
.Select(x => new CSVTable() // <--- 検証2 Select でプロパティ代入をやめる
{
Month = x.Month,
CreateDate = x.CreateDate,
FiscalYear = x.FiscalYear,
Title = x.Title,
Price = x.Price,
}).ToList(); // <--- 検証1 これを削除してみる
}
// CSVを読み込んでデータベースに格納する
var tabel = Models.CSVTable.ReadCsv();
foreach (var record in tabel)
context.Add(record);
違和感・検証したいこと
- 戻り値が
IEnumerableなのに、最後ToList()してるのはなぜ?- メモリ節約を考えて、
IEnumerableのまま返したほうがいいのではないか?- <検証1>**
ToList()を削除して、IEnumerableのまま返してみる**
- <検証1>**
- メモリ節約を考えて、
-
CSVTableインスタンスを生成するときにIdプロパティを代入してないけど、結局デフォルト値を使っているのでは?- デフォルト値は固定値だから、SQL Server の主キーとして重複するのでは?
- <検証2>**
.Select()でプロパティを詰め替える作業をやめてみる**
- <検証2>**
- デフォルト値は固定値だから、SQL Server の主キーとして重複するのでは?
<検証1>IEnumerable型で返してみる
レコードを返すメソッドの戻り値がIEnumerableなので(なのでと言いつつ、そうしたのは自分)
メソッドのreturn時に.ToList()をやめて、.Select()したままを返してみる
public static IEnumerable<CSVTable> ReadCsv(string csvPath)
{
return csv.GetRecords<CSVTable>()
.Select(x => new CSVTable()
{
- }).ToList(); // <--- 検証1 これを削除してみる
+ });
}
.Select()メソッドの戻り値はIEnumerable<T>型のコレクションになる
<検証1>の結果:.ToList()を削除したら、エラーが出た
System.ObjectDisposedException: 'GetRecords() returns an IEnumerable that yields records. This means that the method isn't actually called until you try and access the values. e.g. .ToList() Did you create CsvReader inside a using block and are now trying to access the records outside of that using block?
ObjectDisposed_ObjectName_Name'
↓↓↓ Google翻訳 ↓↓↓
System.ObjectDisposedException: 'GetRecords ()は、レコードを生成するIEnumerable を返します。これは、値にアクセスしようとするまで、メソッドが実際に呼び出されないことを意味します。例えば.ToList()usingブロック内にCsvReaderを作成し、そのusingブロック外のレコードにアクセスしようとしていますか?
ObjectDisposed_ObjectName_Name '
エラー文を完璧に理解できていないが、using句には身に覚えがある・・・
ローカルの CSV ファイルをストリームで読みだすので、usingで破棄するようにしている
using CsvHelper.CsvReader csv = new(stream, cultureInfo);
<検証1>の考察・まとめ
おそらく以下の理由で、戻り値は.ToList()で実体化していないといけない
-
usingで変数 csv を宣言している-
usingで csv の生存期間を限定して、ファイルを開きっぱなしにしないようにしている
-
- IEnumerable が返ったとき、つまりメソッド最下部の
returnを抜けたときには、すでに csv は破棄されている(たぶん)-
yield returnされたものは、それを使うときにアクセスするけど、そのときに csv はもういない・・・- エラーです
-
<こんなときは?>巨大CSVを扱うからyield returnしたい
どうしようもなくCSVが巨大なときは、コレクションを返すのではなく
逆にDbContextを受け取って、データベースに格納する作業を代行してあげるのも手かもしれない
<検証2>GetRecords<T>()の後の.Select()は不要だった
.Select()でCSVTableインスタンスを生成するときに
Idプロパティへの代入を避けながらCSVTableに詰め替えていたけど
そんなことしなくても、データベースに直接格納することができた
主キーが衝突するとか心配する必要はなかった
public static IEnumerable<CSVTable> ReadCsv(string csvPath)
{
- return csv.GetRecords<CSVTable>()
- .Select(x => new CSVTable()
- {
- Month = x.Month,
- CreateDate = x.CreateDate,
- FiscalYear = x.FiscalYear,
- Title = x.Title,
- Price = x.Price,
- }).ToList();
+ return csv.GetRecords<CSVTable>().ToList();
}
なんならId = x.Idとしても大丈夫だった
ToList()とToArray()どっちを使うか?
IEnumerableで返すので、派生先のToListとToArrayのどちらにしても戻り値型としては正しい
参照記事をサラッと読んだ限り、どっちでもいいときにはToArrayを使うといいらしい
public static IEnumerable<CSVTable> ReadCsv(string csvPath)
{
// リスト
return csv.GetRecords<CSVTable>().ToList();
// 配列
return csv.GetRecords<CSVTable>().ToArray();
}
戻り値型はIEnumerableでいいのか?
メソッド内部でリストを生成して返すのなら、素直に List を戻り値にすればよい。無理に IEnumerable にする必要はない(ただし設計上の理由によりそうする場合もある)。
理由は簡単で、より具体的なインタフェースで返す方が、呼び出し元での利便性が高まるからである。
引用元:メソッド戻り値の型 - 引数の型を何でも List にしちゃう奴にそろそろ一言いっておくか
たしかにToList()してIEnumerableで返したものを
呼び出し側で再度ToList()されるのは無駄でしかない
であれば、最初から使える型で返してあげるとよい
どうせToList()しているのだから、戻り値型を限定したところで、メソッドの仕事は増えない
結論
変更前
public static IEnumerable<CSVTable> ReadCsv(string csvPath) // <--- 戻り値はより具体的に配列を返す
{
return csv.GetRecords<CSVTable>()
.Select(x => new CSVTable() // <--- Select でプロパティ代入を不要
{
Month = x.Month,
CreateDate = x.CreateDate,
FiscalYear = x.FiscalYear,
Title = x.Title,
Price = x.Price,
}).ToList(); // <--- ToArray()に変更
}
変更後
public static CSVTable[] ReadCsv(string csvPath)
{
return csv.GetRecords<CSVTable>().ToArray();
}
おわりに
動いたところで満足することなく、日々精進しよう(自戒)
ほかのことに気づいた
検証の過程で何度も SQL Server にデータを入れていて
気づいたらId列が飛び飛びの値になっていた
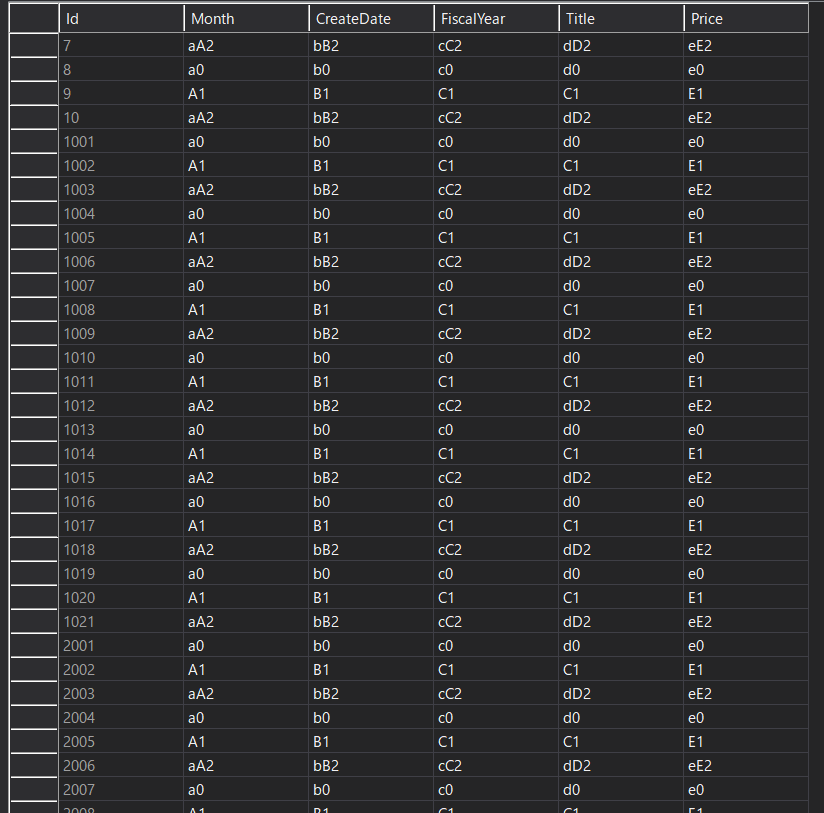
条件が重なるとまれに起きるらしい
設定で変更できそう
参考
付録
モデル
- 作成済みのCsvReaderを返す
//指定したファイルのCsvReaderを作成して返す
public static CsvHelper.CsvReader OpenCsvReader(string csvPath = @"./data.csv")
{
// 1. ファイルをチェックする
if (!File.Exists(csvPath))
throw new FileNotFoundException($"File Not Found!! {csvPath}");
if (!csvPath.EndsWith(".csv", StringComparison.CurrentCultureIgnoreCase))
throw new FormatException($"Invalid Extension!! {csvPath}");
// 2. CsvReader を使うための準備
CultureInfo cultureInfo = new("ja-JP");
StreamReader stream = new(csvPath, Encoding.UTF8);
return new(stream, cultureInfo);
}
//せっかくなのでジェネリックメソッドにしてみた
public static IEnumerable<T> ReadCsv<T>(CsvHelper.CsvReader csv)
=> csv.GetRecords<T>(); //SeceltもToArrayも不要なのでメソッドにする必要ないかも…
使う側
- 使う側で Reader を using して忘れずに破棄する
- Enumerable のまま使えるので、
AddRangeで一括格納できる
public MainWindow()
{
InitializeComponent();
// 1. コンテキスト生成する
Context.CSVTableContext context = new();
// 2. CSVを読み込んでデータベースに格納する
using (var csv = Models.CSVTable.OpenCsvReader())
{
// Case1: CSVを読み込んでそのままデータベースに格納する
// AddRange()の引数にIEnumerableを与えると、まとめてデータベースに格納できる
//context.AddRange(Models.CSVTable.ReadCsv<Models.CSVTable>(csv));
// Case2: CSVの内容をちょっと加工してから格納する
foreach (var record in Models.CSVTable.ReadCsv<Models.CSVTable>(csv))
{
record.Title += record.Title;
context.Add(record);
}
}
// 3. データベースの変更を保存する
context.SaveChanges();
}
1回ループしたEnumerableのインデックスは末尾まで動いてしまうので、次のループは回らずスルーするので
Case1 と Case2 は、一方をつかうときは、もう一方はコメントアウトしておく