この記事は C# その2 Advent Calendar 2018 の第一日の記事である。
はじめに
この記事では、主にエンタープライズアプリケーション(SI、企業向けの業務システムやパッケージ製品)の開発に於いて、新規開発ではなく修正や拡張を行うようなシーンを想定して、無駄な工数をなるべく削減すべく自分なりに考えて実践しているベストプラクティスを書いている。
新規開発の場合でも、将来の拡張や修正が見込まれるはずなので、考慮すべき事は同じだ。
競技プログラミングや、組み込み開発の場合でも基本的な考え方は適用可能だが、メモリ効率やパフォーマンスを考慮する必要もあるので、あえて配列を使ったり、逸脱するようなケースもあるだろう。
対象とする読者層は、C#プログラミング歴1年以上、SIer やユーザー企業に所属(もしくは常駐)し、特に複数人チームでの開発に携わる若手プログラマ、初級から中級へのステップアップ中の人、といったところ。要は、俗に言う"IT土方"。
対象としている .NET のバージョンは 4.5 以降である。もちろん .NET Core も対象だ。
さて、前置きはこの辺にして、さっそく始めよう。
例示
その1
まず最初に、このコードを見てくれ。
List<Entity> RemoveUnnecessary(List<Entity> entities)
{
var list = new List<Entity>();
// 省略(500行ぐらいある)
}
何もおかしいところはなさそうだと思うだろう。
だがこういう一見何事もなさそうなところに、実は問題があることを伝えたい。
ハッキリ言って、このメソッドの宣言はダメだ。
これだけを見て、このメソッドが一体どんな挙動をするのか想像がつくだろうか?
メソッドの名前によると、何やら不要な物を削除してくれそうな事は想像できるが、問題は、 引数で渡したリストが直接変更されるのか、それとも変更されないのか どうか完全には分からないことだ。
メソッドコメントが書いてあればそれを読めばいいのだが、このようなコードが散見されるコードベース(ソースコードの基盤のこと)では、往々にして役に立たないコメントであるか、またはコメントが無いケースも少なくない。
なので、結局メソッドの実装コードを読まないといけない。
それでまた余計な時間がかかる。
アカン。効率悪すぎ。
ならば、こうならどうか。
List<Entity> RemoveUnnecessary(IReadOnlyCollection<Entity> entities)
{
var list = new List<Entity>();
// 省略(500行ぐらいある)
}
引数の型が IReadOnlyCollection<Entity> に変わっている。
「IReadonlyCollection って初めて聞いたな」って人もいるかもしれない。
そういう人は、この機会にぜひ覚えて欲しい。
要は、リードオンリーなコレクションってことだ(.NET 4.5 から導入された)。
ここからわかる事は、引数にリストを渡した場合でも、メソッド内で変更(Add, Remove)される事はない、って事だ。それ以上でもそれ以下でもないが、それが僕らプログラマにはとても大きな手がかりになる。
メソッドの実装を読むまでもなく、安心してリストを渡せるわけだ。
このように、引数の意味を考えて欲しい。
では次に、こういうのはどうか?
void RemoveUnnecessary(List<Entity> items)
{
var list = new List<Entity>();
// 省略(500行ぐらいある)
}
この場合は戻り値がないので、引数で渡したリストが変更されそうなことは明らかだ。
どちらの実装がよいかという議論ももちろん重要なんだが、ここではそれは置いといて、注目すべきは メソッドシグネチャ(引数と戻り値の型定義のこと)を見るだけで、そのメソッドがどの様な振る舞いをするのか分かる ようにプログラムを書け、ということだ。
実はこういう事がとっても大切なんだ。
プログラムなんて、動けば何でもいいってわけじゃない。
ソフトウェアは、ハードウェアと違って簡単に修正できるのがいいところであり、OSにしてもスマホアプリにしても日々新しいバージョンがリリースされ、アップデートされ続けていっている。
プログラムは修正しやすいように書くべきなんだ。
メソッドの実装を読まないと分からないような書き方は悪だ。極悪だ。我々の貴重な工数を浪費し、残業時間を増大させ、体力と精神力を消耗してしまって、その果てに幸福が待っているはずなど皆無なのである。
その2
話を元に戻そう。次はプロパティについての型の例を見てみよう。
class MyQueryResult {
// クエリ結果
public List<Entity> Items { get; }
// コンストラクタ
public MyQueryResult()
{
// 省略
}
// 他にもメソッドがいっぱいある
}
さて、この MyQueryResult クラスも恐ろしい実装になっている。
何が恐ろしいのか、考えてみてほしい。
Items の型が List<T> なので当然 Add したり Remove したり出来てしまう。そんなことをすると、クエリーの結果が改ざんされてしまうことになり、そのようなことが起こることを予期していない他の開発者のコードでバグ(というか予期しない動作)が多発するだろう。
いくら、コーディングルールや、チーム内の暗黙知として、「Itemsを変更するな」といった取り決めがあったとしても、実際に変更可能な実装になっている限り、不安は付きまとう。
人間はミスをする。
Items を取得して、ローカル変数に代入したり色んなメソッドに引き渡したりしているうちに、どこかでうっかり変更してしまっていることだって十分考えられる。
故意ではなく、無意識のうちに変更してしまうのである。
対処するには、そういった取り決めを決めるよりも、そもそも変更することが出来ないような実装にしてしまうべきだ。
こんな感じだ。
class MyQueryResult {
// クエリ結果
public IReadOnlyList<Entity> Items { get; } // 変更不可
// コンストラクタ
public MyQueryResult()
{
// 省略
}
// 他にもメソッドがいっぱいある
}
Items の型が IReadOnlyList<Entity> に変わっている。
これも先ほどの IReadOnlyCollection の仲間で、リードオンリーなリストってわけだ。
これで、Items に対して外部から変更(Add、Removeなど)を行う事は出来なくなる。
とんでもない安心感である。
面倒なルールも必要ない。
ところで、勘の良い人は気づいたかもしれないが、コンストラクタの型も IReadOnlyList<Entity> に変えてしまっても良いかも知れない。
理由は先述の通りだ。
こういうセンスを磨いていってほしい。
その3
次にもう少し複雑な例を見てみよう。
List<Entity> MergeAndUnique(List<Entity> source1, List<Entity> source2)
{
// 省略(3000行ぐらいある)
}
さて、このメソッドはどういう挙動をしそうだろうか。
名前が Merge and Unique なので、source1 と source2 を混ぜ合わせ、重複排除する、と言ったところか。しかしながらあくまで推測でしかない。
ここまで来たら何が問題なのかわかると思うが、すなわち、 source1 と source2 が変更されない保証が無い。
もしかしたら source1 と source2 に対しても重複排除を行うのかもしれない。
では、こうならどうか。
List<Entity> MergeAndUnique(IEnumerable<Entity> source1, IEnumerable<Entity> source2)
{
// 省略(3000行ぐらいある)
}
引数の型が IEnumerable<Entity> に変わっている。
この型は知っている人がほとんどだと思うが、ざっくり言うと foreach で繰り返しをするためのイテレータを表す型だ。
もちろん Add や Remove をすることはできない。
これで、引数に渡したリストが変更されることはない事が保証されるようになった。
それだけでなく、ちょっとハイレベルな見方をするならば、遅延評価を受け入れ可能ということが推察できるのだ(後述)。
チーム開発を行う上で大事なこと
ここまで、メソッド引数や戻り値を何でも List で定義した場合の問題点を見てきた。
個人で開発するだけなら、こう言ったことはそこまで気にしなくても、大きな問題にならない(もちろんホントは気にして欲しい)。
なぜなら、適当に引数の型を定義して作っていっても、内部実装を分かっているので「予期しない動き」というものが無い。
問題になるのは、チーム開発など、複数人で一つのソフトウェアを開発していく時だ。
一人の時と違うのは、メソッドの内部実装を知らない(しかも自分とはスキルレベルや考え方が違う)赤の他人が、そのメソッドを呼び出したり、また逆に赤の他人が書いたコードを、自分のコードから呼び出したりするわけだ。
そこに認識の齟齬が生じる。
こんな具合に。
「このメソッド、どーゆー仕様なの?」
「どうって、見たまんまですよ」
「えっと、引数はどう渡せばよい?」
「え? リストをそのまま渡してくれれば大丈夫ですけど」
「だから、渡したリストは変更されるの? されないの?」
「あ、変更されませんよ」
「おけ、わかった。ありがとう」
こういった、コミュニケーションロスが発生する。
それでも、コミュニケーションが行われるだけまだましだ。
それもなく、それぞれの開発者がそれぞれの思い込みで相互に連携するプログラムを書いていくと、
「このプロパティに要素を追加したら動かなくなったんだけど、バグじゃない?」
「いや、そこに要素を追加しちゃダメですよ」
「え? まじ? なんで? List なのに?」
「...」
といったことや、
「そろそろ結合試験しよーか」
「はい、大丈夫と思います」
「どれ、、、ん? ダメか、、、デバッグしてみるか。。。えっと、ここか。あれ? このメソッド、引数で渡したリストが変更されるんじゃなかったの?」
「いや、違いますよ」
「なんやて!? アカンやん、、、直してよ」
「え? 無理ですよ、いまさら。。。」
といったことが起こる。
そんな経験ないって?
ない人は、国内でも稀な非常に優秀な開発チームに所属している可能性が高い。
特定の企業やチームを批判するつもりはないが、一般的な大手SIerやソフトハウスなら、こんなこと日常茶飯事だ。
まったくもって、非効率すぎる。
まさに、日本中でこんな事ばっかり起こってるんだ。
そりゃー Google や Amazon, Apple や Microsoft に勝てないわけだ。
こういった認識の齟齬が起こる原因は、引数の型がどうこうという問題以外にも、ネーミングの問題や設計工程での詰めの甘さなど、様々であるが、メソッドシグネチャについて言及する者は少ない。
ここで、僕が言いたいことは
メソッドシグネチャだけで振る舞いがわかるように書け!
ということだ。
せっかく静的型付け言語を使っているのだから、この強力な型システムを使わない手はない!
何でもかんでも List で書いてしまうことは、動的型付けなスクリプト言語と変わらない!
特に C# (というか .NET Framework)にここまで細分化されたコレクションの型があるのは、特筆すべき点である。
余談になるが、Javaにも変更操作を禁止するための java.util.Collections.unmodifiableList() があるが、戻り値が専用の型でなく普通の List なので、メソッドシグネチャだけを見て読み取り専用かどうかを明示的に表すことが出来ない。
チーム開発でこそ、C# の優位性を最大限に利用するべきだ。
コレクション型の種類
では実際に型について考える前に、まずはどのようなコレクションの型の種類があって、それぞれどのような特徴があるのかをざっくり見ていこう。
コレクション型の継承関係図
基本的なものはこんな感じ。実際の継承関係はもっと沢山あるが、ここでは使い分けをイメージするために簡略化してある。
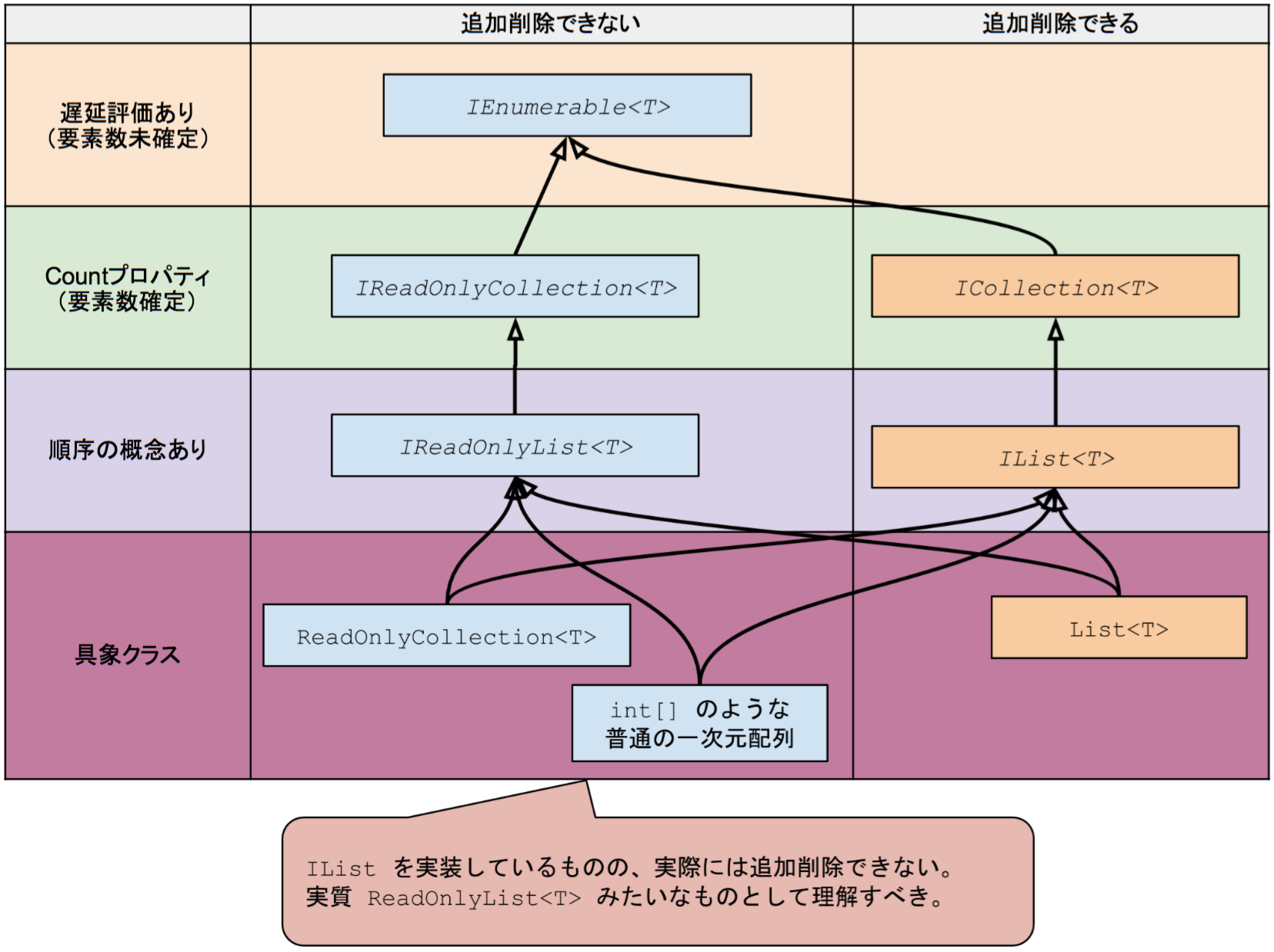
注:ReadOnly 系が利用可能なのは .NET 4.5 以降 1
それぞれの型の特徴
IEnumerable は 遅延評価
IEnumerable<T> はすべてのコレクション型の最上位に位置する、単純に列挙可能な(foreach で回すことが可能な)型を表す。
メソッド内で1回だけ foreach したり、1つの LINQ 式で完結してしまう場合は、引数の型を IEnumerable<T> にすれば十分である。
ただ、IEnumerable<T> を使うときは遅延評価に留意すること。
やろうと思えば ICollection<T> などでも遅延評価を実装することは出来るが、IEnumerable<T> の場合は言語仕様により遅延評価(yield return 構文など)がサポートされているため、暗黙的に遅延評価を考慮すべき型であると認識すべきだ。
メソッド引数として List<T> を書きたくなったら、まず IEnumerable<T> 型に出来ないか検討すべきだ。
検討するには、 IEnumerable<T> を引数の型に採用すべきでないケースを知っておく必要がある。以下のようなケースだ。
- メソッド内で
Count()で要素数を取得している → 要素数を知りたいのなら、最初から要素数が確定しているIReadOnlyCollectionにすべき - メソッド内で foreach を2回以上行っている → ループの度にイテレータが再評価されるため、無駄が多い。思わぬ副作用が起こる可能性もある。
IReadOnlyCollectionを使うべき -
ToArray()やToList()などで結局内部で配列やリストにして使っている → 配列やリストが本当に必要なら素直に引数の型をそれにして、IEnumerableから 配列やリストへの変換が必要なら呼び出し元で変換してもらうべき
ICollection と IList の違い
ICollection<T> は要素の集合を表し、要素数は確定しているが順序関係を持たない。
イメージとしては、バケツに要素がガバーっと入っていて、foreach で取り出すときにどの順番で取り出されるか不定、みたいな感じ。
IList<T> はすなわち可変長配列。順序を維持した集合であり、Insert() メソッドで位置を指定して要素追加したりできる。
イメージとしては、列車のように要素同士が連結されていて、foreach で取り出すと必ず順序通りに取り出される、みたいな感じ。
IList と List の違い
IList<T> は、List<T> と同等の操作を備えたインターフェースと思いきや、実はリストの便利なメソッドは全く定義されていない。
IList<T> で定義されているメソッドは非常にシンプルで、インデクサと IndexOf() Insert() RemoveAt() の3つだけだ。
したがって、List<T> で定義されている Sort() や Reverse() などの順序を変更するような便利メソッドは IList<T> では使えない。
これらのメソッドを利用したい場合は、素直に引数を List<T> にして、変更されることを明示的にすべきだ。
同様に Contains() や FindXxx() などの探索系メソッドも使えないが、これらはコレクションの追加削除をするものではないので、引数の型は ReadOnly 系にしておいて、 内部で ToList() して便利メソッドを使う、というような配慮ができれば シメたものだ。
勿論 List は IList を実装している。
引数の型として List ではなく IList を使うことは、間口を広げることにつながる。List だと、渡せるのは List かそれを継承したサブクラスだけになるが、IList だとそれを実装したあらゆる型を受け付けることが出来る。
戻り値としては、例えばメソッド内部でリストを生成して返すような処理になっているのなら、素直に List<T> を返せばよいだろう。IList<T> に限らず、戻り値を インターフェース型にするようなシーンは限定的だ(後述)。
IReadOnlyCollection と ReadOnlyCollection の違い
名前から察するに、読み取り専用のコレクションと、それを表すインタフェース、と思いきや、全然違う役割を持っている。
まず、名前空間が違う。
System.Collections.Generic.IReadOnlyCollection<T> と、
System.Collections.ObjectModel.ReadOnlyCollection<T> だ。
ReadOnlyCollection<T> の方は、実質 ReadOnlyList であると理解すればオッケーだ(ReadOnlyList というクラスは存在しない)。2
List<T>#AsReadOnly() メソッドで生成することができ、元となったコレクションのコピーを保持しているわけでなく、ラッパーとして機能する。
とーぜん、元のリストの変更が反映される。
実際のコーディングで、型として ReadOnlyCollection<T> を書くことはほぼないだろう。
継承関係図を見てもわかる通り、ReadOnlyCollection<T> は IList<T> を実装しており、 Add や Remove といった要素の追加削除のメソッドが定義されているが、それらのメソッドを呼び出した時点で例外が発生する、という仕様になっている。単純な一次元配列も実は同様だ。
なので、実質 ReadOnlyList であると捉える方が、この図のように整理して理解しやすい。
対して、IReadOnlyCollection<T> には、要素の追加削除のメソッドが定義されておらず、IEnumerable + Count プロパティ、といった最小限の構成。
もう一方の IReadOnlyList<T> は IReadOnlyCollection<T> + インデクサ。まさに固定長の一次元配列と同じようなイメージだ。事実、IReadOnlyCollection<T> 型の引数には 配列を渡すことが出来る。とても理にかなっている!
// このメソッドに渡せる型には、どんなものがある? List<int>?
void Func(IReadOnlyCollection<int> arg) { }
// 呼び出し元
var array = new int[] { 1, 2 };
Func(array); // 実は配列も渡せるんやで!
したがってメソッド引数として使う際には ReadOnlyCollection ではなく、 IReadOnlyCollection<T> か IReadOnlyList<T> を使うべきである。
どの型をつかうべきか
それぞれの型の役割がわかったところで、実際にメソッド引数や戻り値としてどの型を使えば良いのか考えてみよう。
なに、難しくはない。判断基準はいたってシンプルだ。
メソッド引数の型
メソッド引数は、可能な限り最大に間口を広げるべき。
つまり、出来る限り上位のインターフェース(継承関係図で上の方にあるもの)で受ける。
- 要素の追加削除をしないなら
List<T>よりもIReadOnlyList<T>、順序関係がど-でもいいならIReadonlyCollection<T>、要素数未確定でおっけーならIEnumerable<T>を使う。 - 要素の追加削除をするなら基本
List<T>になるが、IList<T>やICollection<T>でも受けられないか考えてみる。
基本的には、IReadonlyCollection<T> で書ける場合が多い。まずこの型で置き換えできないか検討すればよいだろう。
メソッド戻り値の型
戻り値は引数の逆で、出来る限り下位のインターフェース(継承関係図で下の方にあるもの)を返すようにする。
メソッド内部でリストを生成して返すのなら、素直に List<T> を戻り値にすればよい。無理に IEnumerable<T> にする必要はない(ただし設計上の理由によりそうする場合もある)。
理由は簡単で、より具体的なインタフェースで返す方が、呼び出し元での利便性が高まるからである。
例えば以下のようなケース。
IEnumerable<T> Reorder<T>(IReadOnlyCollection<T> list)
{
var result = new List<T>();
// 省略
return result;
}
// 呼び出し元はこうなっている
var newList = new List<T>(Reorder(list)); // いちいち新しく List を作っている
newList.Add(…); // じゃないと要素を追加できない
もし Reorder() の戻り値が List<T> なら、それをそのまま使うことができる。もちろん、元のコードのまま new List() で新しく作ってもちゃんと動くので、互換性が失われることもなく、利便性だけが高まる。
すなわち、
List<T> Reorder<T>(IReadOnlyCollection<T> list)
{
var result = new List<T>();
// 省略
return result;
}
// 呼び出し元はこう書ける
var newList = Reorder(list); // 新しく List を作る必要がなくなった
newList.Add(…);
とできる。
些細な違いかもしれないが、いちいち新しいリストを生成しなくても済むので、メモリ効率もよくなる。
しかしながら、将来的に List<T> を返さないようになるかもしれない場合や、外部設計の時点で戻り値の型が厳密に IEnumerble<T> だと決まっているような場合はその限りではない。
(参考)ジェネリックの共変性
少し脱線して、やや難しい内容になるが、List<T>の T を上位の型に暗黙変換したい時には、IReadOnlyList<T> を使うと変換できる(ジェネリックの共変性という)。以下のようなケースだ。
List<object> Func1()
{
// コンパイルエラー。 Func1().Add(0) というように違う型を追加出来るため、おかしくなる
return new List<string>();
}
IReadOnlyList<object> Func2()
{
// これはオッケー。戻り値は ReadOnly なので、Add() されることはない
return new List<string>();
}
また、LINQ 式の結果をそのまま返したいとか、遅延評価を行う場合は IEnumerable<T> を戻り値にせざるを得ないのは言うまでもないだろう。
プロパティの型
プロパティは、基本的にはオブジェクト内のデータをそのまま(あるいは薄いラップ処理をして)返すような作りになっているべきだ。
しかしながら内部データが List<T> の場合、それをそのまま返すと外部から Add Remove 出来てしまうので、それをして欲しくない場合には考慮が必要となる。
例えば先の MyQueryResult の例を少し掘り下げると、次のような実装が考えられる。
class MyQueryResult<T> {
private List<T> _items; // 内部用
public IReadOnlyList<T> Items { get; } // 外部公開用
// コンストラクタ
public QueryResult(List<T> items) {
this._items = items; // 内部用にはそのまま List で保持
this.Items = items?.AsReadOnly(); // 外部公開用には変更不可にラップ
}
}
メソッドの戻り値の場合とはまた違った観点で型を検討する必要があるのだ。
配列は?
エンタープライズ向けアプリケーションでは、メソッドの引数に配列を使うシーンは実はあまりない。
IReadOnlyList<T> を使えば完全互換になるからだ。
パフォーマンスとか気にする場合は、配列を使うこともあるだろうが、基本みんな、富豪プログラミングだし。3
唯一の出番は、可変長引数を使うときぐらいかもしれない。
タプルは?
C# 7.0 からタプル型を引数や戻り値に直接利用できるようになった。
タプルは、他の型を包含する役割を持っているだけなので、基本的な型の使い分けの考え方は変わらない。
ところで、SIの開発現場でタプルを実際に利用しているところはまだ少ないと思われる。とゆーか見たことがない。
ので今回は詳細な考察を省略する。利用シーンがもっと広がってノウハウが貯まってきたら考察してみたい。
(参考)Immutableコレクション(不変コレクション)
もし Nuget パッケージが使えるなら、System.Collections.Immutable という強力なコレクションライブラリがある。
Immutable(イミュータブル:不変という意味)なので、変更できないコレクションクラスということだ。
馴染みのある String クラスがまさにイミュータブルだ。一度生成したら中身を書き換えることは出来ない。 + 演算子などで文字列結合を行うと、新しいインスタンスが作られて結合結果が得られる。
こんな感じのコレクション版ってイメージだ。
イミュータブルにすることによってコレクションが変更されなくなるため、バグの少ない、非常に安定したプログラムが書けるが、自分の中でまだノウハウが十分でないため、ここでは紹介までにとどめるが、機会があれば是非使ってみて欲しい。
まとめ
ずいぶん長くなったが、ここで述べたのは個人的な経験に基づくベストプラクティスであり、絶対的な正論というわけではない。
世の中には、コレクションのための型を使い分けず、List に統一した方が分かりやすいとする考え方ももちろんある(実際にそういう開発チームを幾つか見てきた)。
それはそれで否定はしない。
しかしながら僕に言わせれば、それは初心者向けに分かりやすい、という捉え方であり、「分かりやすい」の観点が違うわけだ。そういった考え方では、ソフトウェアの規模が大きくなればなるほど、ツラくなる。
もしかすると .NET 4.5 で IReadOnly 系が導入されたことを知らないだけかもしれない。
また .NET 4 以前から続くコーディング規約で決められているとかなら、末端のエンジニアにはどうしようもないだろうが、可能性があるなら断固として正しい使い分けをするべくチーム内で啓蒙活動をするべきだ。
もしあなたが職業プログラマで、チームでの開発を行っており、.NET 4.5 以降をターゲットとしいて、先述のようなコレクションクラスの使い分けを意識していないならば、今すぐ使い分けを始めるべきだ。
無駄なコードリーディングが減るし、バグの発生数も減るはず(少なくとも増えることはない)なので、将来にわたって削減できる工数は計り知れない。
上司やチームメンバーが使い分けを許容しない、または理解できない、または古いやり方を変更することを恐れているならば、さらにその上位者に進言してでも取り組むべきである。というかそのような開発現場はもっと根本的なところに課題を抱えていそうだが。
それでも変わらないようであれば、残念ながらそんな仕事に価値はないと思う。
国会で最低賃金がどうのこうのと議論されている現状を踏まえると、淘汰されるべき生産効率の低い仕事なのかもしれない。
僕もそのような残念な環境で多くの仕事をやってきたので、よく分かる。
後に続く者達には、少しでも明るい未来を創っていきたい。
最後の方は何だか愚痴っぽくなってしまったが、そういった想いをいつも胸に抱え、この国のSI業界の行く末を憂いている。
なお、前向きなコメント、編集リクエストは大歓迎だ。
-
IReadOnlyXxx系が導入されたのは .NET 4.5 で、System.Collections.Generic名前空間で利用できる。.NET 4 では、System.Collection.ObjectModel名前空間にあるReadOnlyCollectionだけしか利用できない。 ↩ -
System.Collections.ObjectModel.Collection<T>という独自コレクションを作る際のベースになるような便利クラスがあり(IList<T>も実装している)、それのリードオンリー版、という位置づけになっている。 ↩ -
富豪プログラミングとは、処理の効率やメモリの節約などを気にせず、リソースをじゃんじゃん使いまくるプログラミングアプローチのこと。最近はこの言葉もあまり聞かなくなったな。 ↩