以下公式ページでBigQueryのアップデート内容について記載されていたので、あとでぱっとみて分かるように以下のページを意訳してまとめてみた。
90日以上前に作成されたデータのコストは半分になる
0.02ドル / GB /Monthのコストが90日以上前のデータだと0.01ドル /GB /Monthに自動的にしてくれる。
対象のテーブルを更新した場合はリセットされる。
値段が安くなるからといって、データが低速のディスクにいったり、パフォーマンスが落ちたりすることはない。
Capacitor Storage Engine
ColumnIOからCapacitorに置き換えたことにより、クエリが10倍から1000倍高速になる。いくつかの改良点はあるが、Capacitorでは圧縮データをそのまま操作することが可能。
以下は公式ページの図を引用。
ColumnIO

Capacitor
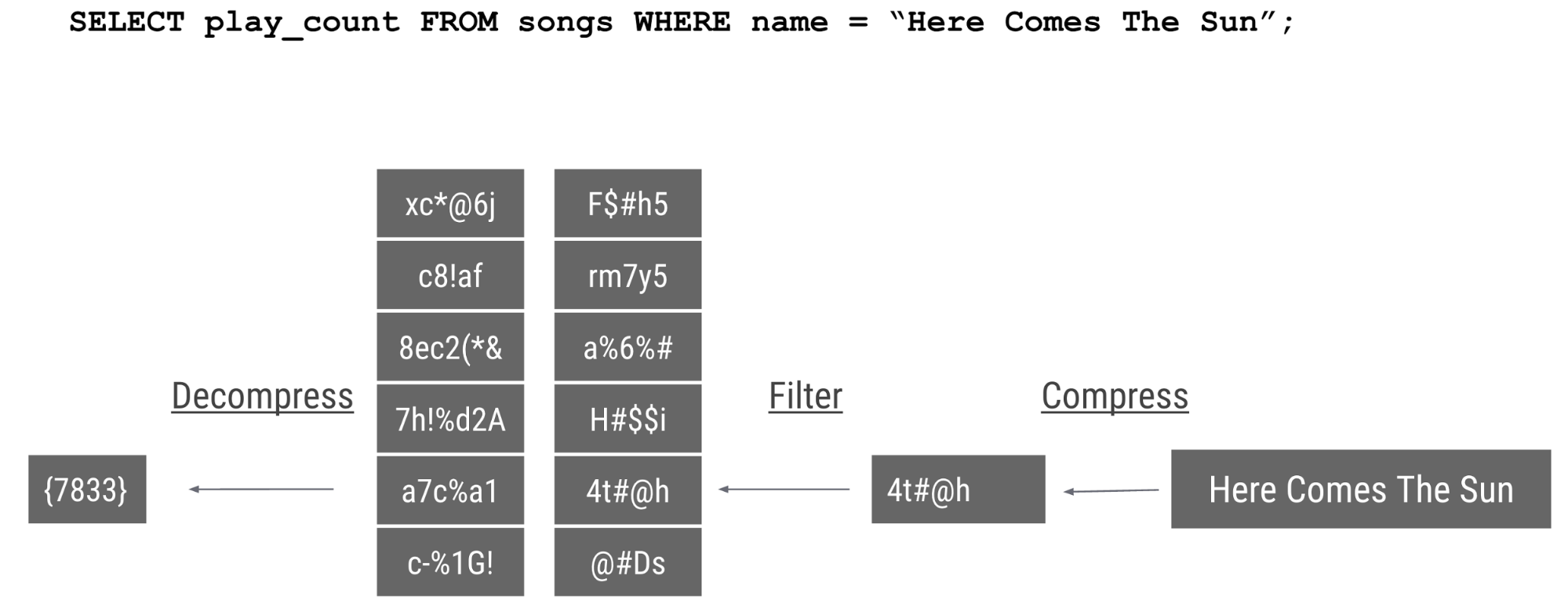
ColumnIOでは圧縮されたデータを解凍したものに対してwhereで指定したのを比較しているが、CapaciorではWhereで指定したのを圧縮してから比較し、指定しているcolumnのみ結果を解凍している。上記の例だと、ColumnIOでは6x2個のデータを解凍しているが、Capacitorでは1個のデータのみ解凍している。このため演算処理対象が少なくなり高速化の要因となっていると思われる。
※ここは自分の解釈であり、公式資料には記載なし。
Poseidon
クエリに影響を与えることなく、ImportとExportが5倍高速になった。
Dremelの効果を活用するためにImportとExportのPipelineをリビルドした。
Table Partitions v1 - Alpha
テーブルパーティションの最初のバージョンで、利用者は1つのテーブルだけでデータを管理することができるようになる。自動パーティショニングはデータ処理を安く、速く、簡単にする。
最初のバージョンのテーブルパーティションはデフォルトで、BigQueryにデータをインジェストした時刻をベースにパーティショニングされる。将来的にはユーザが設定した時刻をベースにパーティショニングできるようにカスタマイズできる。
公式ページの図が分かりやすいので引用させてもらう。
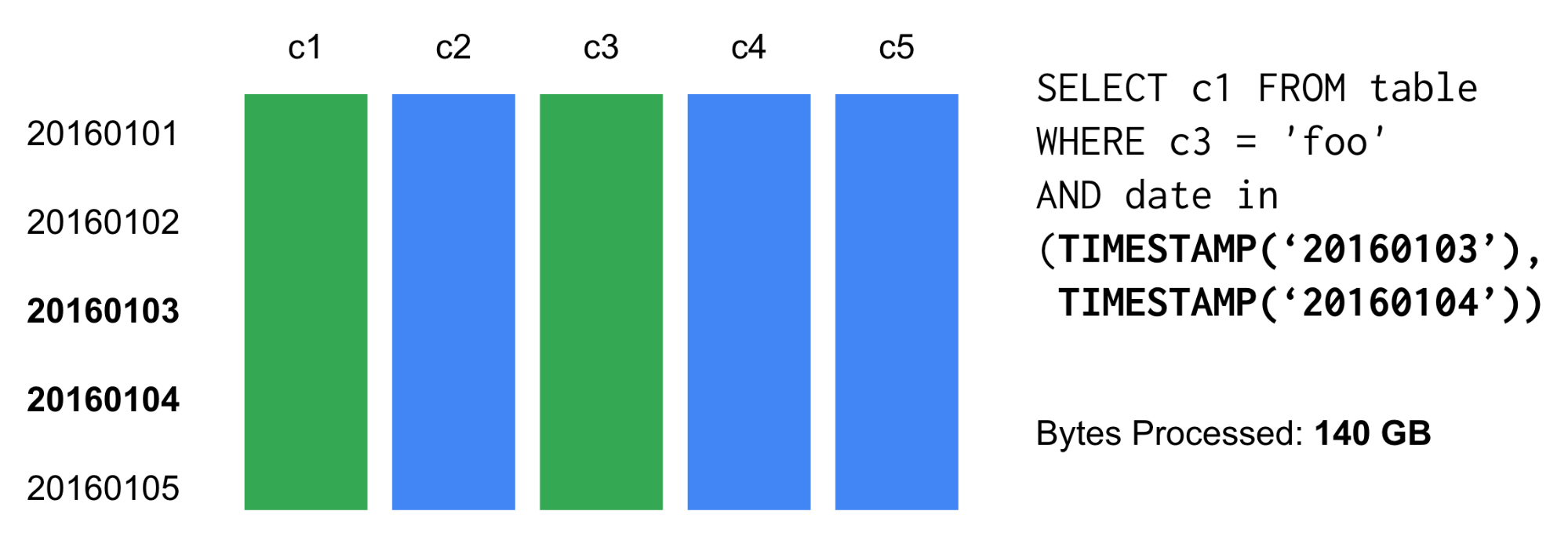
テーブルパーティションの前は以下の図のように、日付毎にテーブルを分けてTABLE_DATE_RANGEを使っていた。

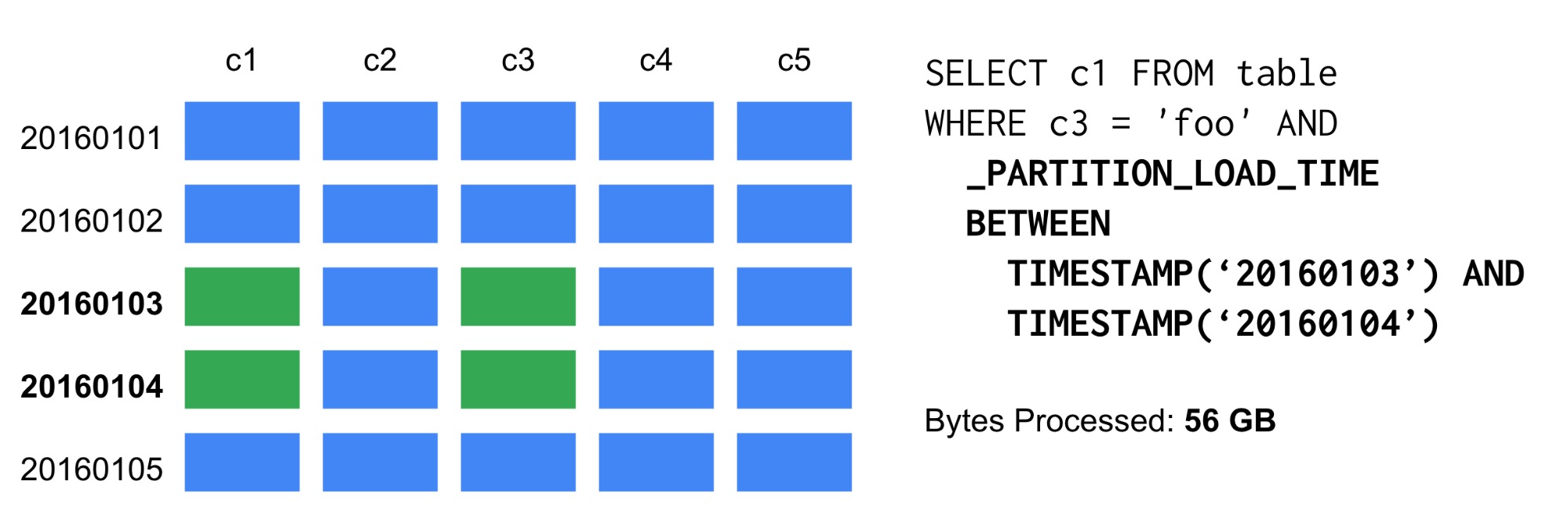
テーブルパーティションを使う場合、BigQueryが自動的に日付単位にパーティショニングし、_PARTITION_LOAD_TIMEを使う。

テーブルパーティションを適用する前、c1とc3の列で20160103と20160104のデータだけ分析したいケースであっても、列全てを読み込んでいた。
テーブルパーティションを使用すると、どのパーティションを読み込むか指定できる。この例ではc1とc3の列で、さらに20160103と20160104のパーティションだけ読み込む。読み込むデータが少なくなるのでコストセーブになる。
AVROフォーマットのサポート
CSVとJSONに加えてAVROもサポートするようになった。
# GCSにAVROファイルに対してクエリをかける
bq query --external_table_definition=foo::AVRO=gs://test/avrotest.avro* "SELECT * FROM foo"
# AVROファイルをGCSからBigQueryにロードする。
bq load --source_format=AVRO project:dataset.dest_table gs:://test/avrotest.avro
自動スキーマ検知
BigQueryにCSVやJSON,AVROファイルをロードするとき、BigQueryはスキーマを自動的に検知しようとするようになった。