本記事の目的
論文"MagicMix: Semantic Mixing with Diffusion Models"を数式などに深入りせずに3行で紹介する事.
各種link
はじめに
本記事はBrainPad Advent Calendarの一環として書かせていただいております1.
私のQiita記事は一昨年,昨年の弊社Advent Calendar記事に引き続き3つ目となりました2.今回こそ3技術的な記事をと思い,先日弊社内で開催されている"論文読み会"4で発表した内容について簡単に紹介させていただきます5.
紹介させていただく論文は"MagicMix: Semantic Mixing with Diffusion Models"です.この論文はざっくばらんに言えば"画像中の物体A(意味A, 形A, 色A)を物体B(意味B, 形A, 色A)6に変換する手法"を提案しています(下記図はデモページより抜粋):
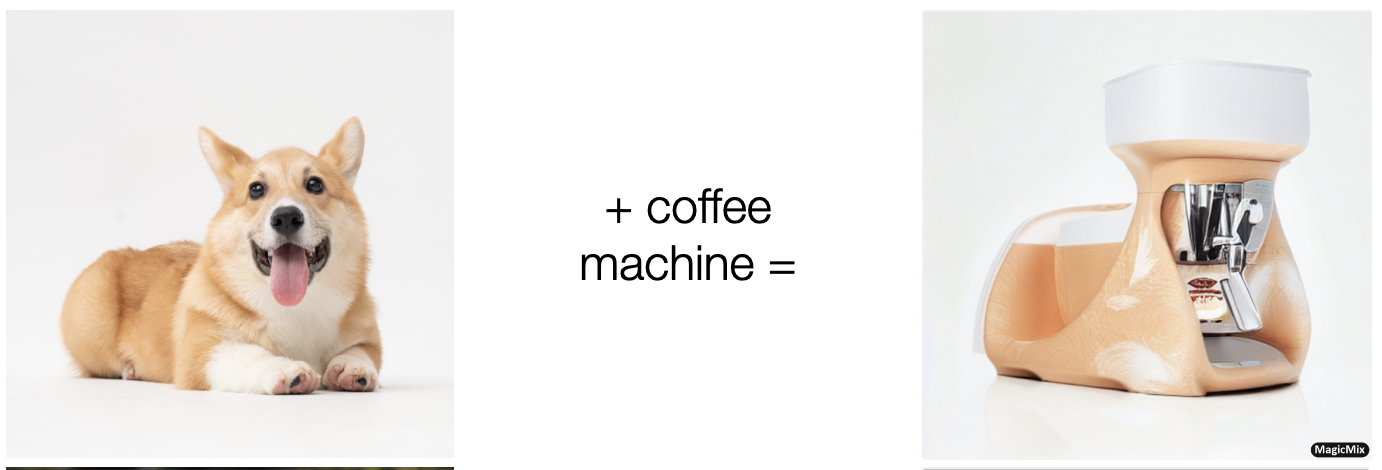
概要(3行まとめ)
- 本論文では画像中の物体A(意味A, 形A, 色A)を物体B(意味B, 形A, 色A)に変換する"Semantic Mixing7"手法を提案している.
- Stable Diffusion8でも活用されているLatent Diffusion Model9の一部を変更している:
- 結果,元画像に映る物体Aの形や色の(雰囲気を保った)物体Bが映る新しい画像が生成できる.
-
体調を崩し遅刻してしまいました.申し訳ありませんでした. ↩
-
本当は定期的に備忘録として記事を書きたいのですが,中々筆が進まず,Advent Calendarが盛大に背中を押してくれてやっと1年に1本書けている状況です. ↩
-
過去の2本はキャリア的な記事で技術的な記事ではありませんでした. ↩
-
"論文読み会"は有志のメンバーが持ち回りで好きな論文について紹介する勉強会です. ↩
-
BrainPad Advent Calendar 2日目の記事も"論文読み会"で発表されていた内容です. ↩
-
正確には形A,色Aというより"形Aに近い形,色Aに近い色"と言うべきでしょうが簡単のためこのように記載しております. ↩
-
"意味混合"とでも訳すべきでしょうか. ↩
-
Stable DiffusionについてはStable Diffusion を基礎から理解したい人向け論文攻略ガイド【無料記事】や世界に衝撃を与えた画像生成AI「Stable Diffusion」を徹底解説!などが参考になるかもしれません. ↩
-
元々のDiffusion Modelでは画像データそのものに対しDiffusion/Denoise処理を施していましたが,Latent Diffusion ModelではLatent Spaseに対しDiffusion/Denoise処理を施しています. ↩
-
"潜在空間".潜在空間とはデータを圧縮し,意味の近さを反映したようなベクトル空間 ↩
-
Stable Diffusionでは入力画像のキャプション情報を利用し復元を行います. ↩