はじめに
Mars Flag Advent Calendar 2023 18日目担当の小川です。よろしくお願いします。
この記事は、以前から個人的に興味を持っていた物事を、Advent Calenderという機会において調査した記事となっていることをご了承ください。
本記事の目的
効率よく大量のデータを取得・処理をしたいというときには、並立/並行処理をして、うまくリソースを活用して処理時間を短くしたいと考えたところ、Pythoではasync, multi threading, multiprocessingの手法を使うことも検討すると思います。
参考にした記事には指針はあげられていますが、今回は、上記のような状態として、S3上に大量のファイルが存在し、それを加工するような時には、それぞれの手法がどのような傾向があるのかを調べてみたいと思います。
比較条件
比較する処理
今回の比較では、asyncとmulti processingの2つについて比較を行いました。
条件
試験内容は以下となります。
- AWSへはSwitchRoleしてアカウント切り替えて対象環境を利用
- 指定したファイル内のS3上のファイルリスト(100件)について、すべて行を読み込み、キューに投入
- async/multi processingにて、作業用のworkerを起動
- async/multi processingのworkerは、キューから1つづつデータ取り出し、head_object(存在チェック)/get_object(ファイル取得)を実施
- キューから取り出すデータがなくなったら、workerは終了
- すべてのworkerが終了したらプロセス終了
- プロセスの開始~プロセスの終了までを測定(timeコマンド使用)
試験対象のパラメータ
試験対象のパラメータは以下となります
- workerの数
- 実行環境のCPU数(1,2,4,8) ※ Oracle VirtualBox上の設定で実施
環境
Windows11ホストにOracle VirtualBoxを起動し、Linux(Ubuntu22.04LTS)上で起動しています。
CPU: Core i7-13700H ※Oracle Virtul Boxの設定で、使用するCPUを1,2,4と変えています。
Memory: 10GB
試験対象コード
async によるコード
asyncでは、AWSアクセスにasyncbotocoreを利用し、キューに Async Queueを利用しました。
import asyncio
import botocore.exceptions
from aiobotocore.session import AioSession, get_session
from types_aiobotocore_s3 import S3Client
from types_aiobotocore_sts import STSClient
ACCESS_KEY="XXXXX"
SECRET_ACCESS_KEY="YYYYY"
REGION="ZZZZZ"
SESSION_NAME="session"
ASSUMED_ROLE"XXXXX"
BUCKER_NAME="XXXXX"
async def worker(bucket: str, queue: asyncio.Queue, number: int):
session = get_session()
# STSを利用しAWSアカウント切り替えつつ、S3クライアント作成
async with session.create_client(
'sts',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_ACCESS_KEY,
region_name=REGION,
) as sts_client:
sts_client: STSClient
# AWSアカウントの切り替え
response = await sts_client.assume_role(
RoleArn=ASSUMED_ROLE,
RoleSessionName=SESSION_NAME,
)
async with session.create_client(
's3',
aws_access_key_id=response["Credentials"]["AccessKeyId"],
aws_secret_access_key=response["Credentials"]["SecretAccessKey"],
aws_session_token=response["Credentials"]["SessionToken"],
region_name=REGION,
) as s3_client:
s3_client: S3Client
while True:
# 処理対象取得
if queue.empty():
break
item: str = await queue.get()
# file存在チェック
is_file_exist = False
try:
response = await s3_client.head_object(Bucket=bucket, Key=item)
is_file_exist = True
print(f"{number} {webp_item} found.")
except botocore.exceptions.ClientError as e:
if e.response["Error"]["Code"] == "404":
print(f"{number} {webp_item} not found.")
else:
# それ以外の例外は異常発生とする
print(e)
except Exception as e:
print(e)
if not is_file_exist:
queue.task_done()
continue
# fileダウンロード
try:
response = await s3_client.get_object(Bucket=bucket, Key=item)
body = await response.get("Body").read()
print(f"{number} {item} download success.")
except Exception:
print(f"{number} {item} download failed.")
queue.task_done()
return
async def main():
# ファイルの内容を読み取り、キューに詰め込む
file_path = "list.txt"
with open(file_path) as f:
lines = f.readlines()
lines = [line.rstrip('\n') for line in lines]
queue = asyncio.Queue(maxsize=len(lines))
for line in lines:
queue.put_nowait(line)
# workerの起動・処理実施
tasks = []
for i in range(8):
task = asyncio.create_task(go_worker(bucket=BUCKER_NAME, queue=queue, number=i))
tasks.append(task)
# キューの中身のデータ処理が全て完了するまで待機
await queue.join()
if __name__ == '__main__':
asyncio.run(main())
multiprocessing によるコード
multiprocessingでは、AWSアクセスにboto3を利用し、キューに multiprocessing.Queueを利用しました。
import multiprocessing
import boto3
import botocore.exceptions
import click
from boto3.session import Session
from mypy_boto3_s3.client import S3Client
from mypy_boto3_sts.client import STSClient
ACCESS_KEY = "XXXXX"
SECRET_ACCESS_KEY = "YYYYY"
REGION = "ZZZZZ"
SESSION_NAME = "session"
ASSUMED_ROLE = "XXXXX"
BUCKER_NAME = "XXXXX"
def get_aws_session() -> Session:
sts_client: STSClient = boto3.client(
"sts",
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_ACCESS_KEY,
)
# AWSアカウントの切り替え
response = sts_client.assume_role(
RoleArn=ASSUMED_ROLE,
RoleSessionName=SESSION_NAME,
)
return Session(
aws_access_key_id=response["Credentials"]["AccessKeyId"],
aws_secret_access_key=response["Credentials"]["SecretAccessKey"],
aws_session_token=response["Credentials"]["SessionToken"],
region_name=REGION,
)
def worker_queue(worker_index: int, bucket: str, queue: multiprocessing.Queue):
session = get_aws_session()
s3client: S3Client = session.client("s3")
timeout = 1
while True:
is_file_exist = False
if queue.empty():
break
try:
item = queue.get(timeout=timeout)
head_response = s3client.head_object(Bucket=bucket, Key=item)
is_file_exist = True
print(f"{number} {item} found.")
except botocore.exceptions.ClientError as e:
if e.response["Error"]["Code"] == "404":
print(f"{worker_index} item not found. item={item}")
else:
# それ以外の例外は異常発生とする
print(e)
except Exception as e:
print(e)
if not is_file_exist:
continue
try:
response = s3client.get_object(Bucket=bucket, Key=item)
body = response.get("Body").read()
print(f"{number} {item} download success.")
except Exception as e:
print(f"{number} {item} download failed.")
print(e)
return
def create_worker(
bucket: str,
queue: multiprocessing.Queue,
worker_index: int,
) -> multiprocessing.Process:
return multiprocessing.Process(
target=worker_queue, args=(worker_index, bucket, queue)
)
@click.command(help="test.")
@click.option(
"--worker",
"worker_num",
help="worker_num",
required=False,
type=int,
default=None,
)
def main(worker_num: int):
file_path = "list.txt"
with open(file_path) as f:
lines = f.readlines()
lines = [line.rstrip("\n") for line in lines]
queue = multiprocessing.Queue(maxsize=len(lines))
for item in lines:
queue.put(item)
processes = []
for i in range(worker_num):
process = create_worker(bucket=BUCKER_NAME, queue=queue, worker_index=i)
processes.append(process)
process.start()
for check_process in processes:
check_process: multiprocessing.Process
check_process.join()
if __name__ == "__main__":
main()
試験結果
async
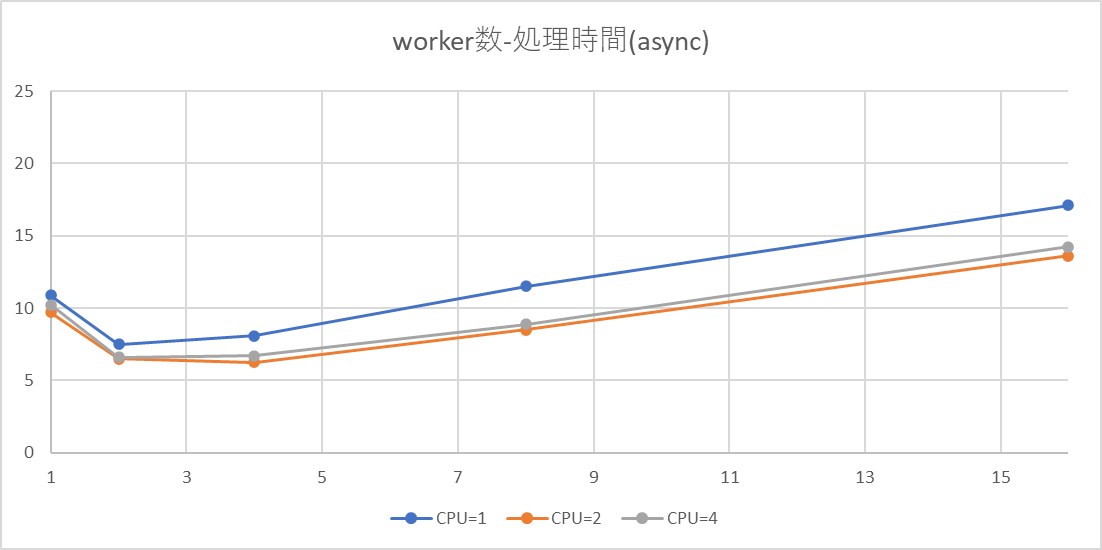
横軸にCPU数、縦軸にworker数としてあります。
| worker数 | 1 | 2 | 4 | 8 | 16 |
|---|---|---|---|---|---|
| CPU=1 | 10.892 | 7.517 | 8.095 | 11.522 | 17.124 |
| CPU=2 | 9.708 | 6.514 | 6.245 | 8.501 | 13.632 |
| CPU=4 | 10.235 | 6.607 | 6.723 | 8.893 | 14.247 |
傾向
- CPU数を変えても、同じような傾向にあることから、CPU数のグラフへの影響はあまり大きくはないように見える。
- worker数が少ないうち処理完了までの時間は短くなっているが、多くなるとかえって長くなる。
multiprocessing
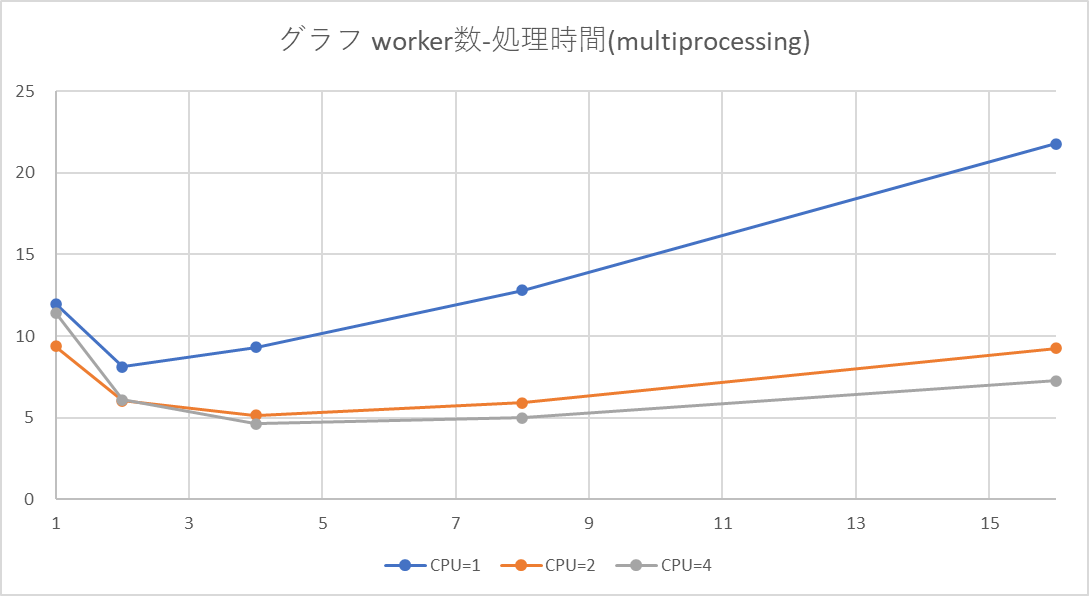
横軸にCPU数、縦軸にworker数としてあります。
| worker数 | 1 | 2 | 4 | 8 | 16 |
|---|---|---|---|---|---|
| CPU=1 | 11.982 | 8.122 | 9.312 | 12.799 | 21.784 |
| CPU=2 | 9.357 | 6.020 | 5.134 | 5.912 | 9.237 |
| CPU=4 | 11.430 | 6.107 | 4.618 | 4.990 | 7.255 |
傾向
- CPU数を変えることの影響が大きいように見えます(CPU数の2倍程度まで処理時間が短くなっている)
まとめ
- 実際にコードを動かし、結果を比較したところ、CPUを増やし、その分プロセスを動かすのはわかりやすく処理能力が向上していた。
- asyncの結果は、worker数の影響が大きいため、このケースでは、小数のworker数で使う方がよさげに見えた
- asyncは稼働したいるプロセス上でおこなわれていることから、multiprocessingを組み合わせれば、さらに性能をあげられるかも。
おわりに
Advend Calender初参加ということで、気になっていたということをお題にしてみました。